PAWS: Preference Learning with Advantage-Weighted Segments
Pith reviewed 2026-06-27 10:20 UTC · model grok-4.3
The pith
PAWS resolves the training-inference mismatch in preference-based RL by using segment-level advantage functions for policy updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that aligning utility training with policy optimization through segment-based advantage functions preserves trajectory-level preference information and avoids the distribution shift that degrades temporal credit assignment in existing preference-based reinforcement learning methods.
What carries the argument
Segment-level advantage functions that directly inform policy updates from preference comparisons.
If this is right
- Policy learning benefits from consistent use of segment-level signals rather than per-step estimates.
- Temporal credit assignment improves because full preference information is preserved during optimization.
- Robotic manipulation and locomotion tasks show consistent performance gains over existing PbRL approaches.
- The approach highlights the importance of distribution-consistent preference learning.
Where Pith is reading between the lines
- This alignment technique could apply to other sequential decision settings that rely on human trajectory feedback.
- Similar consistency fixes might improve scaling of preference learning to longer or more complex tasks.
- If the mismatch drives the performance gap, then variants of PbRL could adopt segment-level updates as a standard fix.
Load-bearing premise
The assumption that the training and inference mismatch in existing methods is the primary cause of degraded temporal credit assignment and limits policy learning.
What would settle it
A controlled experiment where existing PbRL methods are modified to use consistent segment-level signals and still underperform PAWS, or where PAWS is tested with artificial per-step mismatches and performance drops.
Figures


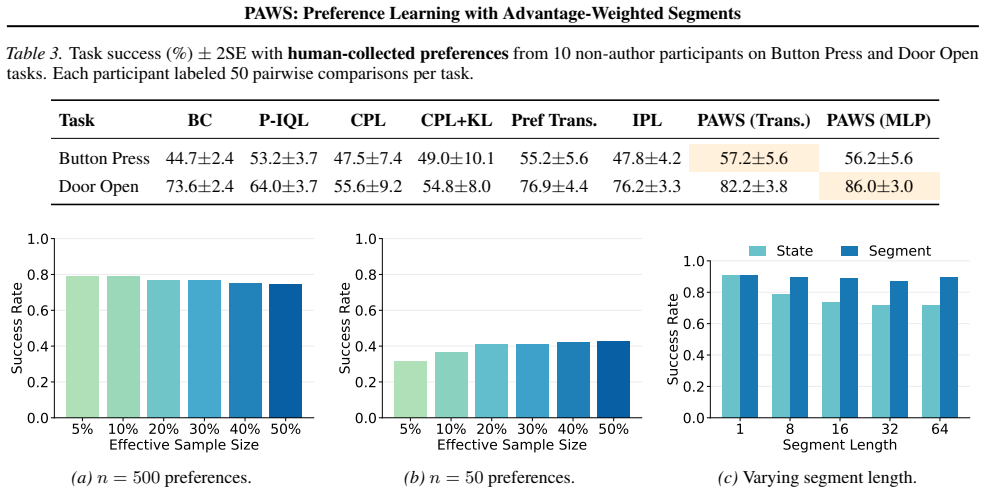
read the original abstract
Preference-based reinforcement learning (PbRL) learns policies from human trajectory-level comparisons, avoiding explicit reward design and expert demonstrations. Existing methods typically train utility functions on trajectory or segment-level preferences while relying on per-step utility estimates during policy optimization. This training and inference mismatch induces a distribution shift that severely degrades temporal credit assignment and limits policy learning. We analyze this issue and propose PAWS, a segment-based preference learning method that performs policy updates directly using segment-level advantage functions. By aligning utility training with policy optimization, PAWS preserves trajectory-level preference information and avoids unreliable per-step learning signals. Experiments on simulated robotic manipulation and locomotion tasks demonstrate that PAWS consistently outperforms existing PbRL approaches, highlighting the importance of distribution-consistent preference learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing PbRL methods suffer from a training-inference mismatch: utility functions are trained on trajectory/segment-level preferences, yet per-step utility estimates are used during policy optimization. This induces a distribution shift that severely degrades temporal credit assignment. PAWS addresses this by performing policy updates directly with segment-level advantage functions, thereby aligning the phases, preserving trajectory-level preference information, and avoiding unreliable per-step signals. Experiments on simulated robotic manipulation and locomotion tasks show consistent outperformance over prior PbRL methods.
Significance. If the central claim and experimental results hold, PAWS would constitute a targeted and practical advance in PbRL by identifying and correcting a previously under-analyzed source of error in credit assignment. The emphasis on distribution-consistent learning could influence subsequent work on preference-based methods, particularly in robotics domains where explicit rewards are difficult to specify.
major comments (1)
- [Abstract] Abstract: the claim that the training/inference mismatch 'induces a distribution shift that severely degrades temporal credit assignment' is presented as the primary motivation and is load-bearing for the contribution, yet the abstract (and the provided text) contains no derivation, formal characterization, or quantitative demonstration of this degradation. The full manuscript must supply this analysis in a dedicated section with concrete evidence before the motivation can be accepted as established.
minor comments (1)
- The abstract would be clearer if it named the specific robotic environments or task suites used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the evidentiary basis for our central motivation. We address the concern below and will revise the manuscript to include the requested analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the training/inference mismatch 'induces a distribution shift that severely degrades temporal credit assignment' is presented as the primary motivation and is load-bearing for the contribution, yet the abstract (and the provided text) contains no derivation, formal characterization, or quantitative demonstration of this degradation. The full manuscript must supply this analysis in a dedicated section with concrete evidence before the motivation can be accepted as established.
Authors: We agree that a dedicated formal analysis with quantitative evidence would make the motivation more robust. The current manuscript states that we analyze the issue and that the mismatch induces the described degradation, but does not yet contain an explicit derivation or controlled demonstration. In the revised version we will add a new subsection (placed after the background on PbRL) that (i) formally characterizes the distribution shift between segment-level preference data and per-step utility estimates used at optimization time, (ii) derives how this shift produces unreliable temporal credit assignment, and (iii) reports quantitative results on a synthetic MDP that isolate the performance drop attributable to the mismatch versus segment-consistent updates. revision: yes
Circularity Check
No significant circularity
full rationale
The paper identifies a training-inference mismatch in PbRL methods as causing distribution shift and degraded credit assignment, then proposes PAWS as a segment-based method that aligns utility training with policy optimization via segment-level advantages. This is presented as a methodological design choice whose benefit is validated empirically on robotic tasks. No equations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems are invoked in the provided text that would reduce the central claim to its own inputs by construction. The argument remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NeurIPS Datasets and Benchmarks Track , year =
B-Pref: Benchmarking Preference-Based Reinforcement Learning , author =. NeurIPS Datasets and Benchmarks Track , year =
-
[2]
Journal of Machine Learning Research , volume =
A Survey of Preference-Based Reinforcement Learning Methods , author =. Journal of Machine Learning Research , volume =
-
[3]
Proceedings of the 37th International Conference on Neural Information Processing Systems , year =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Proceedings of the 37th International Conference on Neural Information Processing Systems , year =
-
[4]
International Conference on Learning Representations (ICLR) , year =
Contrastive Preference Learning: Learning from Human Feedback without Reinforcement Learning , author =. International Conference on Learning Representations (ICLR) , year =
-
[5]
Proceedings of the 41st International Conference on Machine Learning , year =
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study , author =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[6]
Advances in Neural Information Processing Systems , volume =
Deep Reinforcement Learning from Human Preferences , author =. Advances in Neural Information Processing Systems , volume =
-
[7]
Proceedings of the 34th International Conference on Neural Information Processing Systems , year =
Learning to Summarize from Human Feedback , author =. Proceedings of the 34th International Conference on Neural Information Processing Systems , year =
-
[8]
Fine-Tuning Language Models from Human Preferences
Fine-Tuning Language Models from Human Preferences , author =. arXiv preprint arXiv:1909.08593 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[9]
Preference Transformer: Modeling Human Preferences using Transformers for
Changyeon Kim and Jongjin Park and Jinwoo Shin and Honglak Lee and Pieter Abbeel and Kimin Lee , booktitle =. Preference Transformer: Modeling Human Preferences using Transformers for
-
[10]
Nature , year =
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author =. Nature , year =
-
[11]
International Conference on Learning Representations , year =
Learning from negative feedback, or positive feedback or both , author =. International Conference on Learning Representations , year =
-
[12]
Transactions on Machine Learning Research , year =
Models of human preference for learning reward functions , author =. Transactions on Machine Learning Research , year =
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Relative entropy policy search , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[14]
Journal of Machine Learning Research , volume =
Hierarchical relative entropy policy search , author =. Journal of Machine Learning Research , volume =
-
[15]
Advances in neural information processing systems , volume =
Fitted q-iteration by advantage weighted regression , author =. Advances in neural information processing systems , volume =
-
[16]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Awac: Accelerating online reinforcement learning with offline datasets , author =. arXiv preprint arXiv:2006.09359 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[17]
2004 , publisher =
Convex optimization , author =. 2004 , publisher =
2004
-
[18]
International Conference on Learning Representations , year =
Maximum a Posteriori Policy Optimisation , author =. International Conference on Learning Representations , year =
-
[19]
Proceedings of the 24th international conference on Machine learning , pages =
Reinforcement learning by reward-weighted regression for operational space control , author =. Proceedings of the 24th international conference on Machine learning , pages =
-
[20]
Advances in neural information processing systems , volume =
Policy search for motor primitives in robotics , author =. Advances in neural information processing systems , volume =
-
[21]
Advances in Neural Information Processing Systems , volume =
Model-based relative entropy stochastic search , author =. Advances in Neural Information Processing Systems , volume =
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Training language models to follow instructions with human feedback , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[23]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
International Conference on Machine Learning (ICML) , year =
PEBBLE: Feedback-Efficient Interactive Reinforcement Learning via Relabeling Experience and Unsupervised Pre-training , author =. International Conference on Machine Learning (ICML) , year =
-
[25]
Offline Reinforcement Learning with Implicit Q-Learning
Offline reinforcement learning with implicit q-learning , author =. arXiv preprint arXiv:2110.06169 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Proceedings of the 32nd International Conference on Machine Learning (ICML) , series =
Trust Region Policy Optimization , author =. Proceedings of the 32nd International Conference on Machine Learning (ICML) , series =. 2015 , publisher =
2015
-
[27]
The Twelfth International Conference on Learning Representations , year =
Open the Black Box: Step-based Policy Updates for Temporally-Correlated Episodic Reinforcement Learning , author =. The Twelfth International Conference on Learning Representations , year =
-
[28]
The Thirteenth International Conference on Learning Representations , year =
TOP-ERL: Transformer-based Off-Policy Episodic Reinforcement Learning , author =. The Thirteenth International Conference on Learning Representations , year =
-
[29]
Geometry-aware
Tai Hoang and Huy Le and Philipp Becker and Vien Anh Ngo and Gerhard Neumann , booktitle =. Geometry-aware
-
[30]
, title =
Bradley, Ralph Allan and Terry, Milton E. , title =. Biometrika , year =
-
[31]
Cognition , volume =
Action understanding as inverse planning , author =. Cognition , volume =. 2009 , publisher =
2009
-
[32]
Unpacking
Ivison, Hamish and Wang, Yizhong and Liu, Jiacheng and Wu, Zeqiu and Pyatkin, Valentina and Lambert, Nathan and Smith, Noah A and Choi, Yejin and Hajishirzi, Hanna , journal =. Unpacking
-
[33]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
High-dimensional continuous control using generalized advantage estimation , author =. arXiv preprint arXiv:1506.02438 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
, author =
Algorithms for inverse reinforcement learning. , author =. ICML , volume =
-
[35]
WebGPT: Browser-assisted question-answering with human feedback
Webgpt: Browser-assisted question-answering with human feedback , author =. arXiv preprint arXiv:2112.09332 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
International Conference on Machine Learning , pages =
Scaling laws for reward model overoptimization , author =. International Conference on Machine Learning , pages =. 2023 , organization =
2023
-
[37]
arXiv preprint arXiv:2409.13683 , year =
Prefmmt: Modeling human preferences in preference-based reinforcement learning with multimodal transformers , author =. arXiv preprint arXiv:2409.13683 , year =
-
[38]
Conference on Robot Learning , pages =
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning , author =. Conference on Robot Learning , pages =. 2020 , volume =
2020
-
[39]
Advances in Neural Information Processing Systems , pages =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , pages =
-
[40]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
Policy-labeled Preference Learning: Is Preference Enough for RLHF? , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
-
[41]
Proceedings of the 35th International Conference on Machine Learning (ICML) , year =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. Proceedings of the 35th International Conference on Machine Learning (ICML) , year =
-
[42]
International Conference on Learning Representations (ICLR) , year =
Adversarial Imitation Learning with Preferences , author =. International Conference on Learning Representations (ICLR) , year =
-
[43]
The International Journal of Robotics Research (IJRR) , year =
Learning Reward Functions from Diverse Sources of Human Feedback: Optimally Integrating Demonstrations and Preferences , author =. The International Journal of Robotics Research (IJRR) , year =
-
[44]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Reward learning from human preferences and demonstrations in Atari , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[45]
Proceedings of the 5th Conference on Robot Learning (CoRL) , year =
Learning Multimodal Rewards from Rankings , author =. Proceedings of the 5th Conference on Robot Learning (CoRL) , year =
-
[46]
Advances in Neural Information Processing Systems , year =
Direct Preference-based Policy Optimization without Reward Modeling , author =. Advances in Neural Information Processing Systems , year =
-
[47]
36th Conference on Neural Information Processing Systems (NeurIPS 2023) , year =
Inverse Preference Learning: Preference-based RL without a Reward Function , author =. 36th Conference on Neural Information Processing Systems (NeurIPS 2023) , year =
2023
-
[48]
arXiv preprint arXiv:2407.04451 , year =
Hindsight Preference Learning for Offline Preference-based Reinforcement Learning , author =. arXiv preprint arXiv:2407.04451 , year =
-
[49]
Hindsight
Mudit Verma and Katherine Metcalf , booktitle =. Hindsight
-
[50]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Gymnasium: A Standard Interface for Reinforcement Learning Environments , author =. arXiv preprint arXiv:2407.17032 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
International conference on machine learning , pages =
Reinforcement learning with deep energy-based policies , author =. International conference on machine learning , pages =. 2017 , organization =
2017
-
[52]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
D4rl: Datasets for deep data-driven reinforcement learning , author =. arXiv preprint arXiv:2004.07219 , year =
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[53]
International Conference on Learning Representations , year=
Differentiable Trust Region Layers for Deep Reinforcement Learning , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.