MSUE: Multi-Modal Soccer Understanding Expert
Pith reviewed 2026-06-27 10:05 UTC · model grok-4.3
The pith
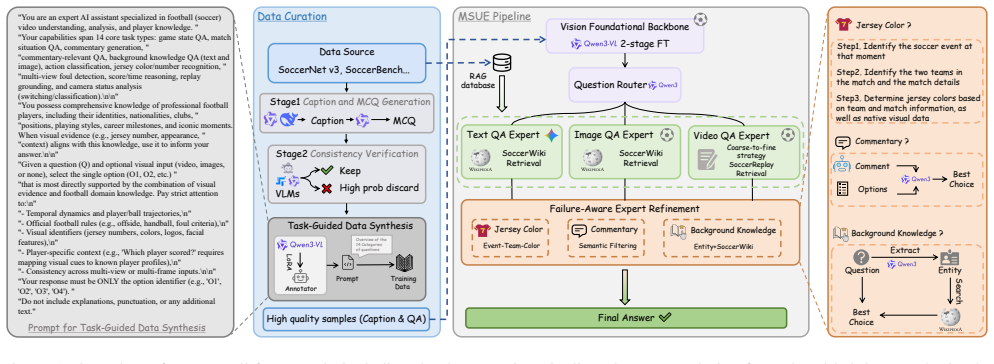
A multi-expert system routes soccer video questions to text, image, and video specialists to reach 0.95 accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors state that their MSUE multi-expert architecture, which uses an LLM to dispatch questions to a text baseline (Gemini3-Flash), a fine-tuned Qwen3-VL image expert, and an external knowledge base video expert, together with VLM-driven synthesis of both concise and long-form VQA samples, produces 0.95 accuracy on the challenge benchmark and third place on the leaderboard.
What carries the argument
MSUE, the multi-expert question-answering architecture in which an LLM dynamically assigns each question to the most suitable modality-specific expert.
If this is right
- Each question receives the expert best matched to its modality needs.
- Collaboration among the three experts raises overall accuracy beyond any single expert.
- VLM synthesis supplies both short and long-form training examples without manual labeling.
- The same dispatch pattern can be reused for other domain-specific video QA tasks.
Where Pith is reading between the lines
- The routing idea could be tested on other sports or general video understanding benchmarks.
- Replacing the external knowledge base with retrieval from a larger corpus might further improve long-form answers.
- The cost of fine-tuning only one expert while keeping the others frozen suggests a scalable pattern for new domains.
- Real-time deployment would require measuring latency of the LLM dispatcher plus the three experts.
Load-bearing premise
The VLM-driven pipeline produces VQA samples diverse and high-quality enough for the multi-expert system to reach the reported accuracy.
What would settle it
Replace the multi-expert routing with a single general model and measure accuracy on the same benchmark; a result below 0.85 would indicate that the expert collaboration is required for the claimed performance.
Figures
read the original abstract
This paper presents our solution to the 2026 SoccerNet VQA Challenge. We first develop a cost-effective data synthesis pipeline driven by a Vision-Language Model (VLM), which systematically restructures raw domain data into diverse VQA samples, including concise answers and long-form responses. Second, we propose MSUE, a multi-expert question answering architecture that employs a Large Language Model (LLM) to dynamically dispatch questions to text, image, and video experts. These experts are instantiated as a strong text baseline Gemini3-Flash, a fine-tuned Qwen3-VL, and an external knowledge base, respectively, working collaboratively to enhance VQA performance. MSUE achieves an accuracy of \textbf{0.95} on the challenge benchmark, securing third place in the leaderboard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a VLM-driven pipeline to synthesize diverse VQA samples (concise and long-form) from raw soccer domain data, followed by MSUE: an LLM-based dispatcher that routes questions to three experts (text: Gemini3-Flash baseline; image: fine-tuned Qwen3-VL; video: external knowledge base). The system reports 0.95 accuracy on the SoccerNet VQA challenge benchmark and third place on the leaderboard.
Significance. If the accuracy result is reproducible, the combination of synthetic data generation with dynamic multi-expert dispatching offers a practical route to strong performance on domain-specific multi-modal QA without requiring massive manual annotation. The externally verifiable leaderboard placement provides a concrete, falsifiable outcome that strengthens the empirical contribution.
major comments (2)
- [Abstract] Abstract: The central claim of 0.95 accuracy is stated without any description of the test-set size, evaluation protocol, baseline comparisons, or error analysis. This absence directly undermines verification of the reported performance and the assumption that the VLM synthesis pipeline produced sufficiently high-quality data.
- [Abstract] The manuscript supplies no details on the LLM dispatch mechanism (prompting strategy, routing criteria, or output fusion), the fine-tuning procedure and data used for Qwen3-VL, or the construction and retrieval method of the external knowledge base. These elements are load-bearing for the multi-expert architecture claim.
minor comments (1)
- [Abstract] The abstract refers to 'Gemini3-Flash' and 'Qwen3-VL' without clarifying whether these are the exact model versions or variants used; consistent naming and version numbers would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We agree that the abstract requires expansion to support verification of the reported results and to better highlight the key technical components of the multi-expert system. We will revise the abstract and, where necessary, strengthen the corresponding sections in the body.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 0.95 accuracy is stated without any description of the test-set size, evaluation protocol, baseline comparisons, or error analysis. This absence directly undermines verification of the reported performance and the assumption that the VLM synthesis pipeline produced sufficiently high-quality data.
Authors: We accept the point. The SoccerNet VQA challenge uses a fixed, hidden test set whose size is defined by the organizers; our reported 0.95 accuracy follows the official accuracy metric on that set. The third-place leaderboard position provides an external, verifiable baseline comparison. We will revise the abstract to state the evaluation protocol explicitly and note the leaderboard result. A concise error analysis will be added to the experiments section (and referenced in the abstract) to address the quality of the synthesized data. revision: yes
-
Referee: [Abstract] The manuscript supplies no details on the LLM dispatch mechanism (prompting strategy, routing criteria, or output fusion), the fine-tuning procedure and data used for Qwen3-VL, or the construction and retrieval method of the external knowledge base. These elements are load-bearing for the multi-expert architecture claim.
Authors: We acknowledge that the current abstract is too terse on these points. The body of the manuscript contains dedicated subsections describing the LLM dispatcher (including prompt templates and routing logic), the fine-tuning dataset and procedure for Qwen3-VL, and the KB construction plus retrieval pipeline. To make the abstract self-contained, we will insert concise descriptions of each component. If the referee finds the existing body descriptions insufficiently detailed, we will expand those sections as well. revision: yes
Circularity Check
No significant circularity: empirical benchmark result
full rationale
The paper describes an empirical system for the SoccerNet VQA Challenge consisting of a VLM-driven data synthesis pipeline followed by a multi-expert architecture (LLM dispatcher plus text/image/video experts). The central claim is a measured accuracy of 0.95 on a fixed external benchmark, with leaderboard placement as external verification. No equations, derivations, fitted parameters presented as predictions, or self-citation load-bearing steps appear in the provided text. The result is self-contained against the benchmark and does not reduce to any input by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhao- hai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Jun- yang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shix...
2025
-
[2]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025. 2
2025
-
[3]
Scaling up soccer- net with multi-view spatial localization and re-identification
Anthony Cioppa, Adrien Deliège, Silvio Giancola, Bernard Ghanem, and Marc Van Droogenbroeck. Scaling up soccer- net with multi-view spatial localization and re-identification. Scientific Data, 9(1):355, 2022. 1
2022
-
[4]
Soccernet-tracking: Multiple object track- ing dataset and benchmark in soccer videos, 2022
Anthony Cioppa, Silvio Giancola, Adrien Deliege, Le Kang, Xin Zhou, Zhiyu Cheng, Bernard Ghanem, and Marc Van Droogenbroeck. Soccernet-tracking: Multiple object track- ing dataset and benchmark in soccer videos, 2022. 1
2022
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Seikavandi, Jacob V
Adrien Deliège, Anthony Cioppa, Silvio Giancola, Meisam J. Seikavandi, Jacob V . Dueholm, Kamal Nas- rollahi, Bernard Ghanem, Thomas B. Moeslund, and Marc Van Droogenbroeck. Soccernet-v2: A dataset and benchmarks for holistic understanding of broadcast soccer videos, 2021. 1
2021
-
[7]
Riegler, Pål Halvorsen, and Mubarak Shah
Sushant Gautam, Cise Midoglu, Vajira Thambawita, Michael A. Riegler, Pål Halvorsen, and Mubarak Shah. Soc- cerchat: Integrating multimodal data for enhanced soccer game understanding.ArXiv e-prints, 2025. 1
2025
-
[8]
Soccernet: A scalable dataset for ac- tion spotting in soccer videos
Silvio Giancola, Mohieddine Amine, Tarek Dghaily, and Bernard Ghanem. Soccernet: A scalable dataset for ac- tion spotting in soccer videos. In2018 IEEE/CVF Con- 4 ference on Computer Vision and Pattern Recognition Work- shops (CVPRW). IEEE, 2018. 1
2018
-
[9]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3, 2022. 1
2022
-
[10]
Step3- vl-10b technical report, 2026
Ailin Huang, Chengyuan Yao, Chunrui Han, Fanqi Wan, Hangyu Guo, Haoran Lv, Hongyu Zhou, Jia Wang, Jian Zhou, Jianjian Sun, Jingcheng Hu, Kangheng Lin, Liang Zhao, Mitt Huang, Song Yuan, Wenwen Qu, Xiangfeng Wang, Yanlin Lai, Yingxiu Zhao, Yinmin Zhang, Yukang Shi, Yuyang Chen, Zejia Weng, Ziyang Meng, Ang Li, Aobo Kong, Bo Dong, Changyi Wan, David Wang, D...
2026
-
[11]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chao- fan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Soccernet- caption: Dense video captioning for soccer broadcasts com- mentaries
Hassan Mkhallati, Anthony Cioppa, Silvio Giancola, Bernard Ghanem, and Marc Van Droogenbroeck. Soccernet- caption: Dense video captioning for soccer broadcasts com- mentaries. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5074– 5085, 2023. 1
2023
-
[13]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander M ˛ adry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kir- illov, Alexi Christakis,...
-
[14]
Multi-agent system for comprehensive soccer understanding
Jiayuan Rao, Zifeng Li, Haoning Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie. Multi-agent system for comprehensive soccer understanding. InACM Multimedia 2025, 2025. 1, 2
2025
-
[15]
Towards universal soccer video un- derstanding
Jiayuan Rao, Haoning Wu, Hao Jiang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Towards universal soccer video un- derstanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 1, 2
2025
-
[16]
Internvl3.5: Advanc- ing open-source multimodal models in versatility, reasoning, and efficiency, 2025
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Sheng- long Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, Jingjing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Zhi Ho...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.