nD-RoPE: A Generalized RoPE for n-Dimensional Position Embedding
Pith reviewed 2026-06-27 10:31 UTC · model grok-4.3
The pith
nD-RoPE generalizes rotary position embeddings to arbitrary dimensions by coupling positions and frequencies as n-dimensional vectors to enforce isotropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
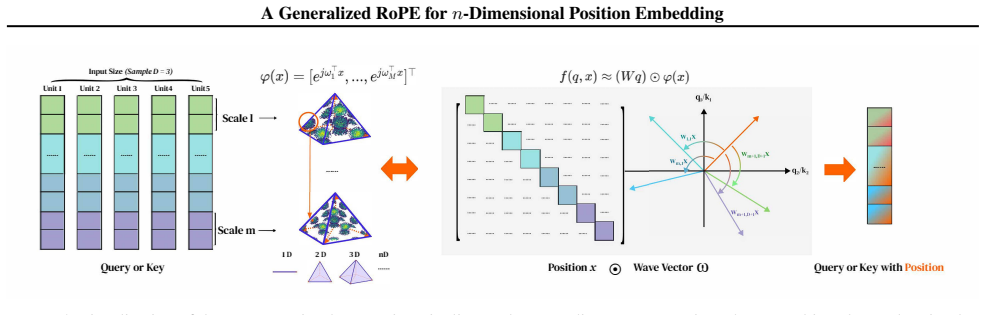
From a translation-invariant formulation in continuous Hilbert space, we derive a spectral condition for isotropy that requires treating positions and frequencies as coupled n-dimensional vectors. We instantiate this formulation with a multi-scale regular-simplex wave-vector design, which provides non-degenerate spatial coverage and a symmetric, directionally balanced second-order response.
What carries the argument
The spectral condition for isotropy obtained from the translation-invariant formulation in continuous Hilbert space, realized by a multi-scale regular-simplex wave-vector design.
Load-bearing premise
The translation-invariant formulation in continuous Hilbert space produces a spectral condition for isotropy that is both necessary and sufficient when positions and frequencies are treated as coupled n-dimensional vectors.
What would settle it
Compute the directional variance of the second-order response across many random directions in three or higher dimensions; if the variance stays large when the coupled-vector design is used, the claimed isotropy condition does not hold.
Figures
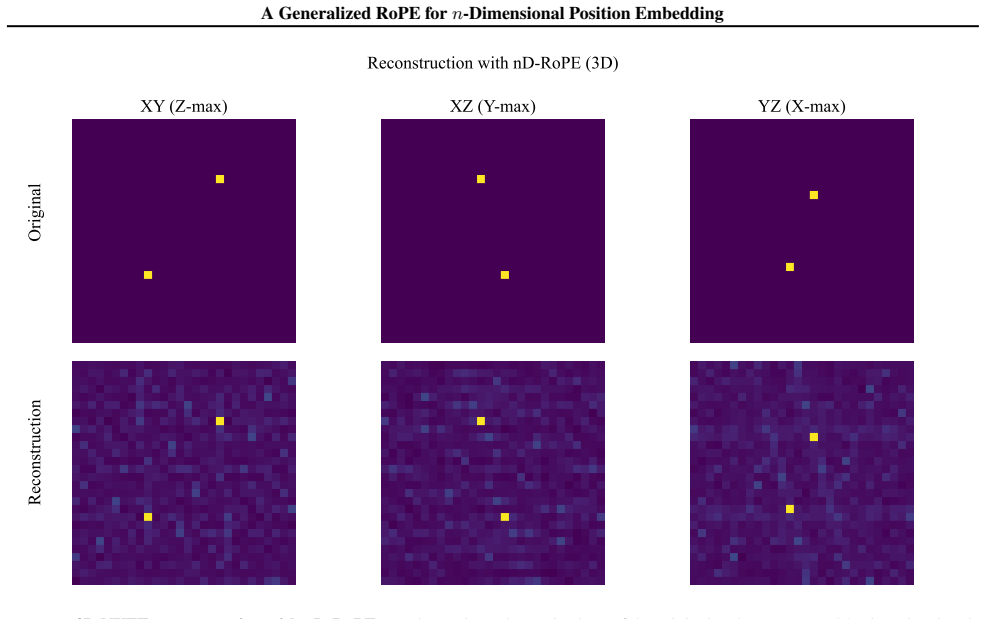
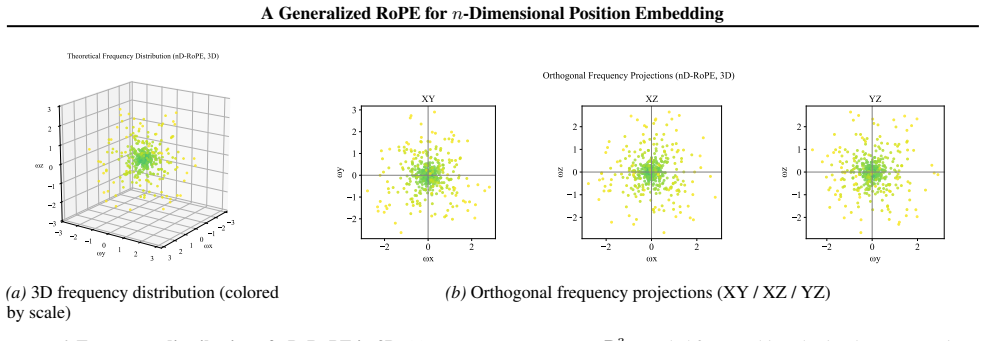
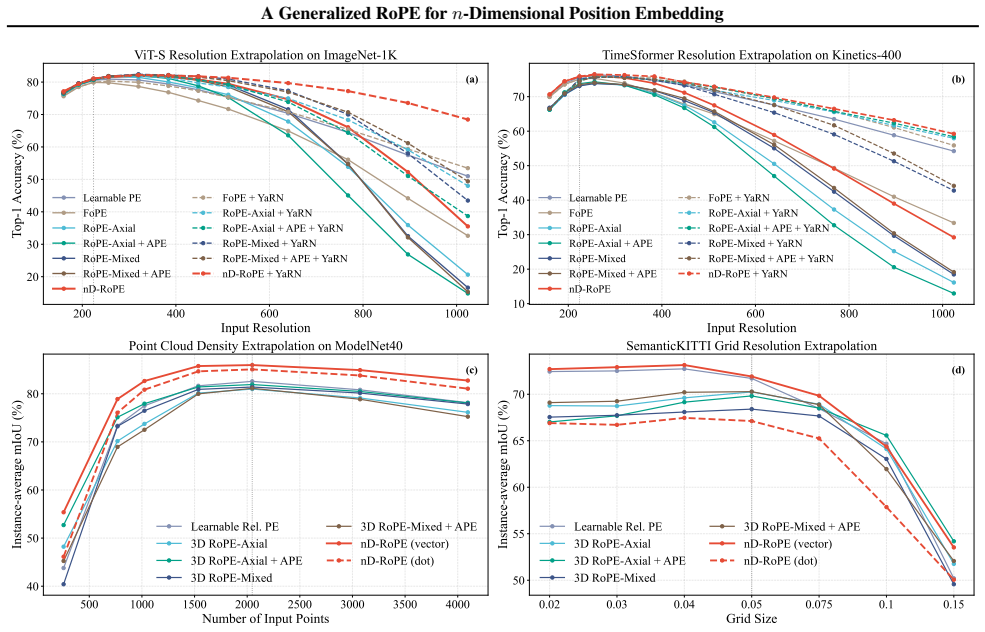
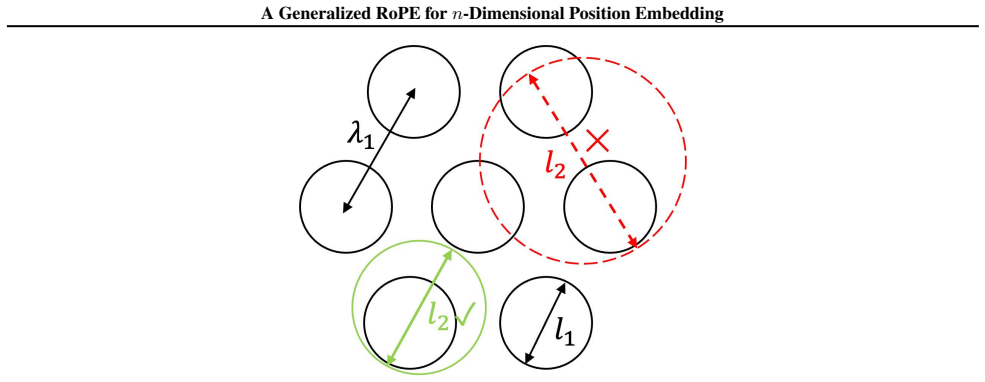
read the original abstract
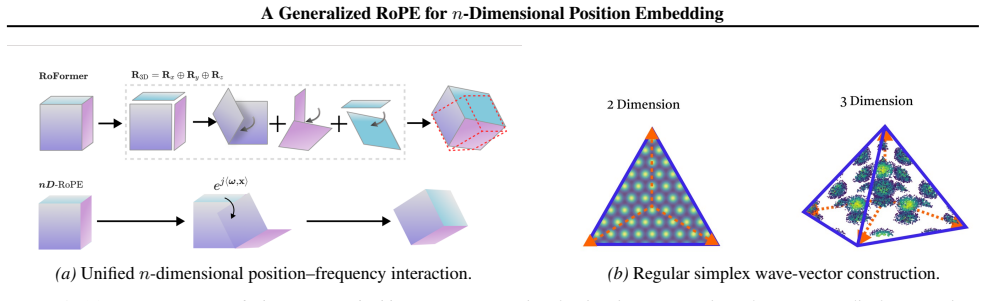
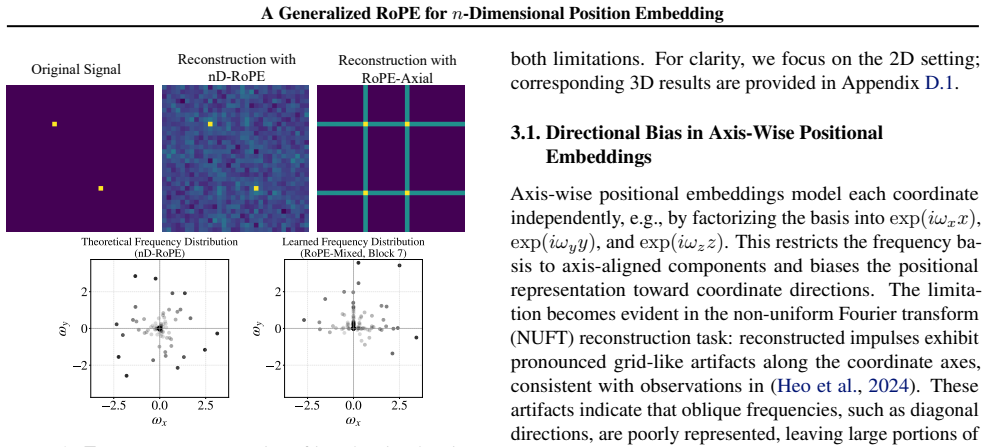
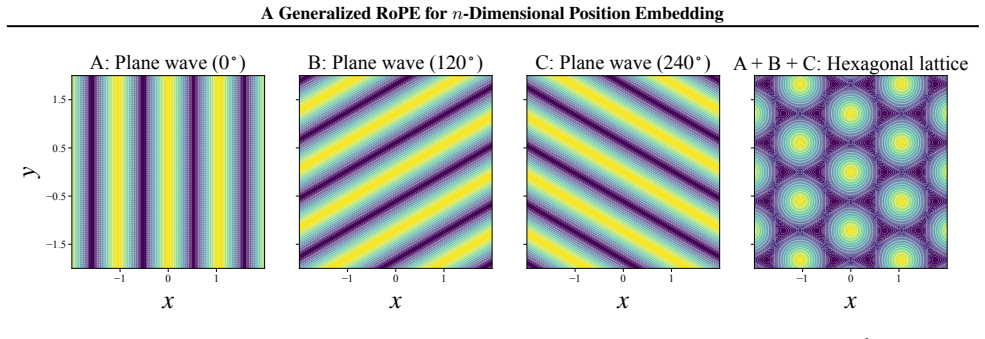
Rotary Position Embedding (RoPE) is widely adopted in Transformer models, yet its extension to high-dimensional domains lacks a unified theoretical formulation. Most existing approaches either apply rotations independently along each axis or empirically mix frequencies, which limits cross-dimensional interactions and yields direction-dependent representations. To address these limitations, we propose nD-RoPE, a decomposition-free generalization of RoPE to arbitrary dimensions. From a translation-invariant formulation in continuous Hilbert space, we derive a spectral condition for isotropy that requires treating positions and frequencies as coupled \(n\)-dimensional vectors. We instantiate this formulation with a multi-scale regular-simplex wave-vector design, which provides non-degenerate spatial coverage and a symmetric, directionally balanced second-order response. Experiments across images, videos, and point clouds demonstrate consistent performance gains and improved generalization in high-dimensional settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes nD-RoPE as a decomposition-free generalization of Rotary Position Embedding (RoPE) to arbitrary dimensions. From a translation-invariant formulation in continuous Hilbert space, it derives a spectral condition for isotropy that requires treating positions and frequencies as coupled n-dimensional vectors; this is instantiated via a multi-scale regular-simplex wave-vector design claimed to yield non-degenerate spatial coverage and symmetric second-order response. Experiments on images, videos, and point clouds are reported to show consistent gains and improved generalization.
Significance. If the derivation is correct and the gains are robust, the work supplies a principled route to directionally balanced position embeddings in high-dimensional domains, addressing the cross-dimensional interaction limitations of axis-wise or empirically mixed alternatives.
major comments (2)
- [Abstract] Abstract, paragraph 2: the necessity and sufficiency of the spectral isotropy condition for directionally balanced representations is asserted as following from the translation-invariant Hilbert-space formulation, yet the provided text supplies neither the explicit spectral condition nor the derivation steps that would allow verification that the condition is independent of the subsequent simplex-vector choice.
- [Abstract] Abstract: the central experimental claim of 'consistent performance gains' is stated without dataset names, model sizes, baselines, or error bars, rendering the claim impossible to evaluate for statistical or practical significance.
minor comments (1)
- The phrase 'decomposition-free' is used without an explicit contrast to the 'apply rotations independently along each axis' methods mentioned earlier; a short clarifying sentence would help.
Simulated Author's Rebuttal
We thank the referee for the comments. We respond point-by-point to the two major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 2: the necessity and sufficiency of the spectral isotropy condition for directionally balanced representations is asserted as following from the translation-invariant Hilbert-space formulation, yet the provided text supplies neither the explicit spectral condition nor the derivation steps that would allow verification that the condition is independent of the subsequent simplex-vector choice.
Authors: The abstract is a concise summary and therefore omits the explicit math. The full manuscript derives the spectral isotropy condition (the second-moment tensor of the n-dimensional wave vectors must equal a positive scalar times the identity) directly from the translation-invariant Hilbert-space kernel in Section 2.2; Theorems 1 and 2 then prove necessity and sufficiency of this condition and its independence from any particular choice of simplex vectors. The claims in the abstract follow from these sections. revision: no
-
Referee: [Abstract] Abstract: the central experimental claim of 'consistent performance gains' is stated without dataset names, model sizes, baselines, or error bars, rendering the claim impossible to evaluate for statistical or practical significance.
Authors: Abstracts are length-limited and conventionally omit granular experimental metadata. Section 4 and the appendix supply the missing details: datasets (CIFAR-10, ImageNet, Kinetics-400, ModelNet40), model scales, exact baselines (axis-wise RoPE and frequency-mixing variants), and error bars from multiple runs. The abstract claim is therefore supported by the reported evaluations. revision: no
Circularity Check
No significant circularity
full rationale
The paper's derivation begins from an explicit translation-invariant formulation in continuous Hilbert space and derives a spectral isotropy condition as a necessary consequence before instantiating it with the regular-simplex wave-vector design. No equation or step reduces by construction to a fitted parameter, self-citation, or renamed input; the isotropy condition is presented as independently obtained from the Hilbert-space premise rather than defined by the final vector choice. The central claim therefore retains independent theoretical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[2]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[3]
Ji, H., Ni, T., Huang, X., Luo, T., Zhan, X., and Chen, J. Ropetr: Improving temporal camera-only 3d detection by integrating enhanced rotary position embedding.arXiv preprint arXiv:2504.12643,
-
[4]
The kinetics human action video dataset
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., et al. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950,
-
[5]
Liu, H. and Zhou, H. Rethinking rope: A mathematical blueprint for n-dimensional positional encoding.arXiv preprint arXiv:2504.06308,
-
[6]
Persformer: A transformer architecture for topological machine learning
Reinauer, R., Caorsi, M., and Berkouk, N. Persformer: A transformer architecture for topological machine learning. arXiv preprint arXiv:2112.15210,
-
[7]
Self-attention with relative position representations
Shaw, P., Uszkoreit, J., and Vaswani, A. Self-attention with relative position representations. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pp. 464–468,
2018
-
[8]
doi: 10.1016/j.neucom.2023.127063. Tancik, M., Srinivasan, P., Mildenhall, B., Fridovich-Keil, S., Raghavan, N., Singhal, U., Ramamoorthi, R., Barron, J., and Ng, R. Fourier features let networks learn high fre- quency functions in low dimensional domains.Advances in neural information processing systems, 33:7537–7547,
-
[9]
Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
-
[10]
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
-
[11]
3d shapenets: A deep representation for volumetric shapes
Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X., and Xiao, J. 3d shapenets: A deep representation for volumetric shapes. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 1912– 1920,
1912
-
[12]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[13]
Length extrapolation of transformers: A survey from the perspective of positional encoding
Zhao, L., Feng, X., Feng, X., Zhong, W., Xu, D., Yang, Q., Liu, H., Qin, B., and Liu, T. Length extrapolation of transformers: A survey from the perspective of positional encoding. InFindings of the Association for Computa- tional Linguistics: EMNLP 2024, pp. 9959–9977,
2024
-
[14]
Under this setting, the total number of positional channels remains constant
For 2D inputs, each scale uses three simplex wave vectors, each represented by a cosine–sine pair, resulting in six embedding dimensions per scale. Under this setting, the total number of positional channels remains constant. Only the allocation of scales across attention heads is varied, while all other training and architectural settings are kept identi...
arXiv 2000
-
[15]
This prediction is consistent with Table 7, where θ= 100 achieves the strongest and most stable performance across all point densities. D.4. Computational Complexity Analysis Table 8 summarizes the computational cost of nD-RoPE across ViT and point cloud Transformer architectures. For image and video Transformers, nD-RoPE only modifies the frequency const...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.