How Low Can You Go? Active Learning for Sparse Model Discovery in the Ultra-Low-Data Limit
Pith reviewed 2026-06-27 10:28 UTC · model grok-4.3
The pith
Active learning with ensemble uncertainty recovers governing equations using far fewer data samples than random sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
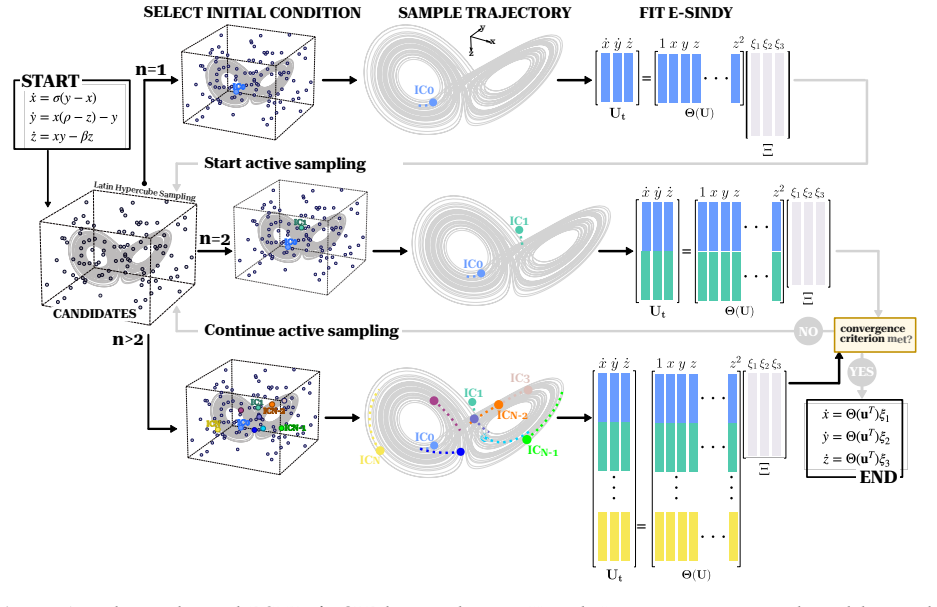
The authors claim that an active learning loop driven by epistemic uncertainty estimates from E-SINDy ensembles allows accurate recovery of the true sparse dynamics for both ODEs and PDEs in the ultra-low-data regime, outperforming random sampling across tested systems and noise levels.
What carries the argument
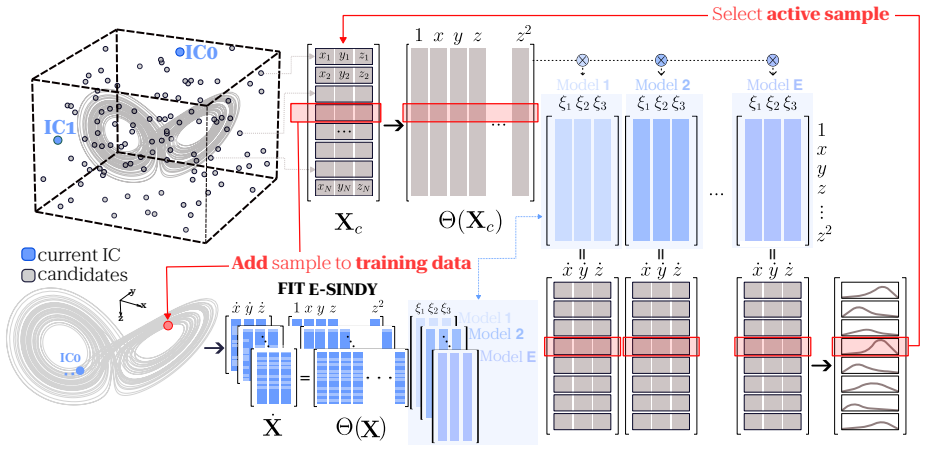
The E-SINDy ensemble, which generates multiple SINDy models to quantify epistemic uncertainty and thereby directs the selection of subsequent measurement locations.
If this is right
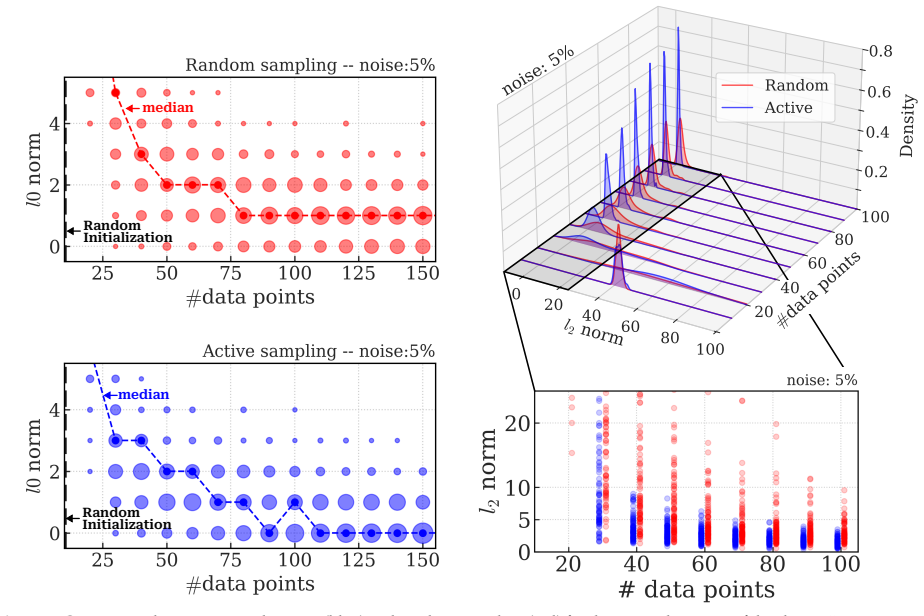
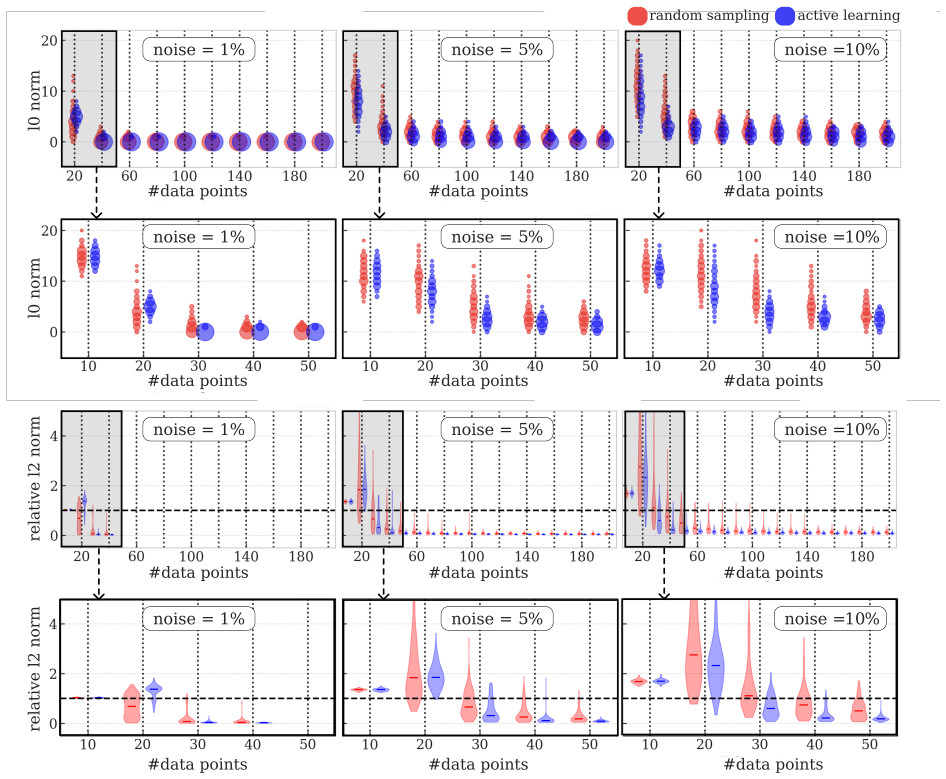
- The method identifies correct governing equations for the Lorenz system with fewer points at different noise levels.
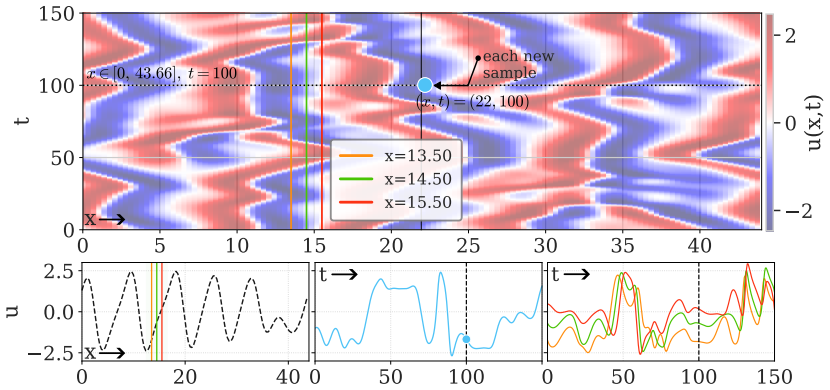
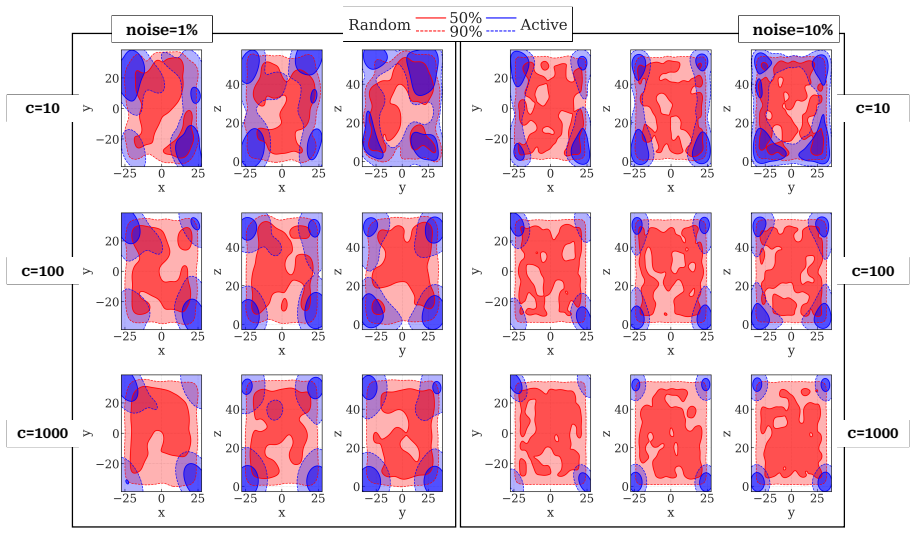
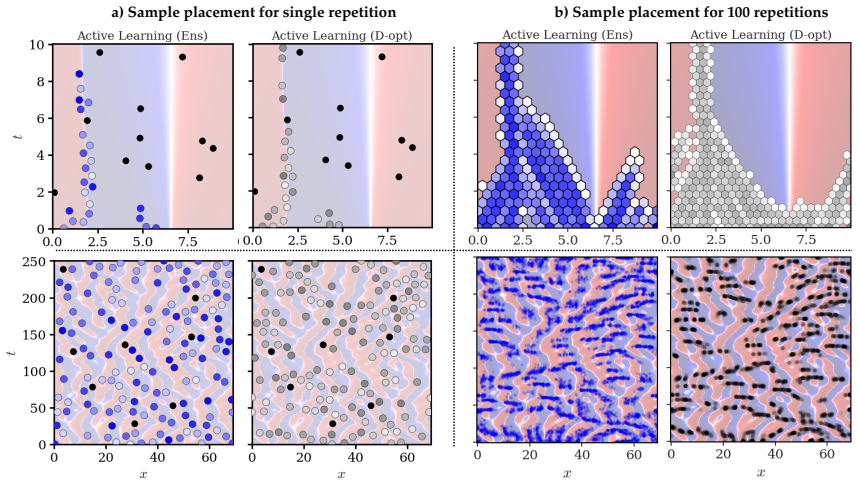
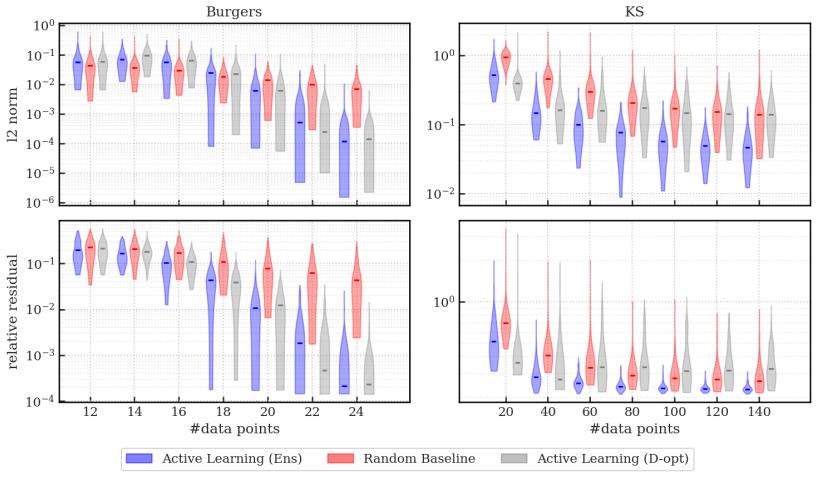
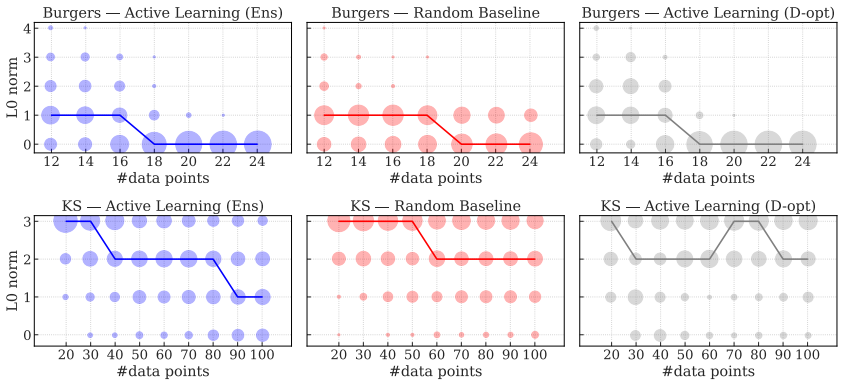
- It distinguishes informative regions near shocks in Burgers' equation from less useful areas.
- It navigates complex spatial patterns in the Kuramoto-Sivashinsky equation to find good sampling locations.
- Overall accuracy in model discovery improves significantly compared to uniform random sampling.
Where Pith is reading between the lines
- This sampling strategy could be adapted to guide sensor placement in real-world experiments with limited measurement budgets.
- If the uncertainty signal proves robust, similar active learning could apply to other equation discovery techniques.
- Performance may depend on the diversity of the initial ensemble models, suggesting a need to study initialization effects.
Load-bearing premise
The uncertainty scores produced by the E-SINDy ensemble point to data points that advance recovery of the actual governing equations rather than just areas of current model disagreement.
What would settle it
A direct comparison on the Lorenz system where, after the same number of actively chosen samples, the identified equations match the true ones no better than those from randomly selected samples.
Figures
read the original abstract
Identifying the governing equations of complex dynamical systems remains a fundamental challenge across science and engineering. While early approaches relied on empirical data and heuristics, modern data-driven methods offer greater flexibility and fewer assumptions. However, data acquisition in real-world settings is often expensive. This work addresses this challenge by introducing an active learning strategy for dynamics discovery in the ultra-low data limit. Rather than sampling randomly, our method iteratively prioritizes regions that are most informative for model identification. This approach builds on Sparse Identification of Nonlinear Dynamics (SINDy), and utilizes an ensemble extension, E-SINDy, to estimate epistemic uncertainty and guide the sampling for both ordinary and partial differential equations (ODEs/PDEs). For ODEs, an exhaustive analysis is conducted on the Lorenz system across varying data budgets and noise levels. For PDEs, two systems with contrasting dynamical characteristics are examined: the Burgers' equation, where a sharp shock front creates a distinction between informative and uninformative regions, and the Kuramoto-Sivashinsky equation, which presents a more spatially complex sampling landscape. Across all scenarios, the proposed method accurately identifies the governing dynamics with significantly fewer data samples than random sampling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an active learning strategy for sparse model discovery using an ensemble extension of SINDy (E-SINDy) to estimate epistemic uncertainty and prioritize informative data points in the ultra-low-data regime. It claims that this approach identifies governing dynamics for ODEs (Lorenz system) and PDEs (Burgers' and Kuramoto-Sivashinsky equations) with significantly fewer samples than random sampling, across varying data budgets and noise levels.
Significance. If the uncertainty-guided sampling is shown to preferentially advance recovery of the true sparse coefficients (rather than merely reducing ensemble variance), the method could meaningfully lower data requirements for equation discovery in settings where measurements are expensive. The extension of established SINDy frameworks with an explicit sampling loop is a natural direction, but its value hinges on empirical validation of the acquisition function's alignment with ground-truth term recovery.
major comments (2)
- [Abstract] Abstract: the central claim that the method 'accurately identifies the governing dynamics with significantly fewer data samples than random sampling' across all scenarios rests on the unverified assumption that E-SINDy epistemic uncertainty selects points whose addition enables sparse regression to recover the exact governing terms. No derivation, ablation, or quantitative comparison is provided showing that the acquisition function reduces coefficient error to the ground-truth model rather than simply shrinking spread among incorrect library models; high ensemble disagreement can arise from under-determined estimation or noise without supplying information about missing nonlinear terms.
- [Abstract] The manuscript provides no explicit sampling criteria, hyperparameter settings for the ensemble, or quantitative results tables that would allow verification of the exhaustive testing asserted in the abstract; without these, the support for superior performance over random sampling cannot be assessed and may involve unstated post-hoc choices.
minor comments (2)
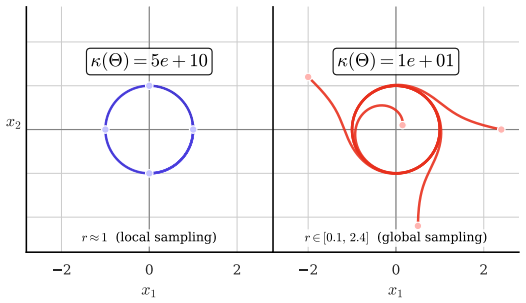
- Notation for the acquisition function and how it is computed from the E-SINDy ensemble variance should be clarified with an explicit equation.
- The description of the Lorenz, Burgers', and Kuramoto-Sivashinsky test cases would benefit from a table summarizing the exact data budgets, noise levels, and performance metrics (e.g., term recovery rate or coefficient error) for active vs. random sampling.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation and validation of our active learning approach for sparse model discovery. We address each major comment below and commit to revisions that strengthen the empirical support for the method's claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'accurately identifies the governing dynamics with significantly fewer data samples than random sampling' across all scenarios rests on the unverified assumption that E-SINDy epistemic uncertainty selects points whose addition enables sparse regression to recover the exact governing terms. No derivation, ablation, or quantitative comparison is provided showing that the acquisition function reduces coefficient error to the ground-truth model rather than simply shrinking spread among incorrect library models; high ensemble disagreement can arise from under-determined estimation or noise without supplying information about missing nonlinear terms.
Authors: We agree that distinguishing between uncertainty reduction and true term recovery is critical for validating the acquisition function. Our reported results on the Lorenz, Burgers', and Kuramoto-Sivashinsky systems show that the active sampling strategy recovers the exact ground-truth sparse coefficients (i.e., the correct library terms with accurate values) at lower data budgets than random sampling, across noise levels. This is quantified via successful model identification rates and coefficient error metrics relative to the known governing equations. However, to more explicitly demonstrate that the epistemic uncertainty from E-SINDy preferentially selects points that advance recovery of the true terms (rather than merely reducing ensemble variance among incorrect models), we will add a new ablation analysis. This will include plots and tables tracking coefficient error to ground truth versus ensemble disagreement as a function of selected samples, confirming alignment with term recovery. revision: yes
-
Referee: [Abstract] The manuscript provides no explicit sampling criteria, hyperparameter settings for the ensemble, or quantitative results tables that would allow verification of the exhaustive testing asserted in the abstract; without these, the support for superior performance over random sampling cannot be assessed and may involve unstated post-hoc choices.
Authors: The full manuscript details the sampling criteria (prioritizing points with highest epistemic uncertainty estimated via E-SINDy ensemble disagreement), ensemble hyperparameters (e.g., number of models, bootstrap variations, and library construction), and quantitative results (success rates, coefficient errors, and comparisons to random sampling) in the methods and results sections, with figures and tables for the Lorenz system across budgets/noise and the two PDEs. To address the concern about verifiability in support of the abstract claims, we will add an explicit summary table of all hyperparameters and sampling criteria, along with consolidated quantitative result tables, ensuring all experimental settings are fully specified without post-hoc adjustments. revision: yes
Circularity Check
No significant circularity; method extends prior frameworks with independent empirical validation
full rationale
The paper proposes an active learning loop that uses E-SINDy ensemble uncertainty to select new samples for SINDy regression. Performance claims rest on numerical experiments (Lorenz, Burgers, Kuramoto-Sivashinsky) comparing active vs. random sampling, not on any derivation that reduces by construction to fitted parameters or self-referential definitions. Prior SINDy/E-SINDy citations supply the base regressor but are not invoked as a uniqueness theorem or ansatz that forces the new result; the active sampling strategy is evaluated separately against ground-truth recovery metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- SINDy sparsity threshold
axioms (1)
- domain assumption The candidate function library contains the true terms of the governing equations.
Reference graph
Works this paper leans on
-
[1]
Brunton and J
Steven L. Brunton and J. Nathan Kutz.Data-Driven Science and Engineering: Machine Learning, Dynami- cal Systems, and Control. Cambridge University Press, 2019
2019
-
[2]
When is a system discoverable from data? discovery requires chaos, 2025
Zakhar Shumaylov, Peter Zaika, Philipp Scholl, Gitta Kutyniok, Lior Horesh, and Carola-Bibiane Schönlieb. When is a system discoverable from data? discovery requires chaos, 2025. URLhttps: //arxiv.org/abs/2511.08860
arXiv 2025
-
[3]
Steven L. Brunton, Joshua L. Proctor, and J. Nathan Kutz. Discovering governing equations from data by sparse identification of nonlinear dynamical systems.Proceedings of the National Academy of Sciences, 113(15):3932–3937, 2016. doi: 10.1073/pnas.1517384113
-
[4]
Learning from noisy examples.Machine Learning, 2(4):343–370, 1988
Dana Angluin and Philip Laird. Learning from noisy examples.Machine Learning, 2(4):343–370, 1988. ISSN 1573-0565. doi: 10.1007/BF00116829
-
[5]
Cheeseman, Ivo F
Suryanarayana Maddu, Bevan L. Cheeseman, Ivo F. Sbalzarini, and Christian L. Müller. Stability selection enables robust learning of differential equations from limited noisy data.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 478(2262):20210916, 06 2022. ISSN 1364-
2022
-
[6]
doi: 10.1098/rspa.2021.0916
-
[7]
Nghiem, Thomas Beckers, Mahyar Fazlyab, Enrique Mallada, Colin Jones, Dra- guna Vrabie, Steven L
Jan Drgo ˇ na, Truong X. Nghiem, Thomas Beckers, Mahyar Fazlyab, Enrique Mallada, Colin Jones, Dra- guna Vrabie, Steven L. Brunton, and Rolf Findeisen. Safe physics-informed machine learning for dy- namics and control, 2025. URLhttps://arxiv.org/abs/2504.12952
arXiv 2025
-
[8]
Kathleen Champion, Bethany Lusch, J. Nathan Kutz, and Steven L. Brunton. Data-driven discovery of coordinates and governing equations.Proceedings of the National Academy of Sciences, 116(45):22445– 22451, 2019. doi: 10.1073/pnas.1906995116
-
[9]
Andrew Wagenmaker.A Theory of Active Learning in Dynamic Environments. Ph.d. thesis, University of Washington, 2024. URLhttps://digital.lib.washington.edu/researchworks/items/ 8800ffc0-a15a-4817-aa05-2c173d1f098c/full. University of Washington ResearchWorks
2024
-
[10]
Adaptive sampling methods for learning dynamical systems
Zichen Zhao and Qianxiao Li. Adaptive sampling methods for learning dynamical systems. InPro- ceedings of Mathematical and Scientific Machine Learning, volume 190 ofProceedings of Machine Learning Research, pages 335–350. PMLR, 2022
2022
-
[11]
Small data machine learning in materials science
Pengcheng Xu, Xiaobo Ji, Minjie Li, and Wencong Lu. Small data machine learning in materials science. npj Computational Materials, 9(1):42, 2023. ISSN 2057-3960. doi: 10.1038/s41524-023-01000-z
-
[12]
Ethan Pickering, Stephen Guth, George Em Karniadakis, and Themistoklis P . Sapsis. Discovering and forecasting extreme events via active learning in neural operators.Nature Computational Science, 2(12): 823–833, 2022. doi: 10.1038/s43588-022-00376-0
-
[13]
A. Hu, Enrico Camporeale, and B. Swiger. Multi-hour-ahead Dst index prediction using multi-fidelity boosted neural networks.Space Weather, 21(4):e2022SW003286, 2023. doi: 10.1029/2022SW003286. 16
-
[14]
Jared Willard, Xiaowei Jia, Shaoming Xu, Michael Steinbach, and Vipin Kumar. Integrating scientific knowledge with machine learning for engineering and environmental systems.ACM Comput. Surv., 55(4), 2022. ISSN 0360-0300. doi: 10.1145/3514228
-
[15]
Learning latent representations in high-dimensional state spaces using polynomial manifold constructions, 2023
Rudy Geelen, Laura Balzano, and Karen Willcox. Learning latent representations in high-dimensional state spaces using polynomial manifold constructions, 2023. URLhttps://arxiv.org/abs/2306. 13748
2023
-
[16]
Patsatzis, Lucia Russo, and Constantinos Siettos
Alessandro Della Pia, Dimitrios G. Patsatzis, Lucia Russo, and Constantinos Siettos. Learning the latent dynamics of fluid flows from high-fidelity numerical simulations using parsimonious diffusion maps.Physics of Fluids, 36(10):105187, 10 2024. ISSN 1070-6631. doi: 10.1063/5.0232378
-
[17]
Active learning for neural PDE solvers, 2024
Daniel Musekamp, Marimuthu Kalimuthu, David Holzmüller, Makoto Takamoto, and Mathias Niepert. Active learning for neural PDE solvers, 2024. URLhttps://arxiv.org/abs/2408. 01536
2024
-
[18]
Dongrui Wu. Pool-based sequential active learning for regression.IEEE Transactions on Neural Networks and Learning Systems, 30(5):1348–1359, 2019. doi: 10.1109/TNNLS.2018.2868649
-
[19]
Hayden Schaeffer, Giang Tran, Rachel Ward, and Linan Zhang. Extracting structured dynamical sys- tems using sparse optimization with very few samples.Multiscale Modeling & Simulation, 18(4):1435– 1461, 2020. doi: 10.1137/18M1194730
-
[20]
Hyunjune Sebastian Seung, Manfred Opper, and Haim Sompolinsky. Query by committee. InPro- ceedings of the Fifth Annual Workshop on Computational Learning Theory, pages 287–294. ACM, 1992. doi: 10.1145/130385.130417
-
[21]
Urban Fasel, J. Nathan Kutz, Bingni W. Brunton, and Steven L. Brunton. Ensemble-SINDy: Robust sparse model discovery in the low-data, high-noise limit, with active learning and control.Proceedings of the Royal Society A, 478(2260):20210904, 2022. doi: 10.1098/rspa.2021.0904
-
[22]
Fisher.The Design of Experiments
Ronald A. Fisher.The Design of Experiments. Oliver and Boyd, 1937. URLhttps://books.google. com/books?id=IMrtAAAAMAAJ
1937
-
[23]
Loudon.The Quantum Theory of Light
Anthony Curtis Atkinson and Alexander Nikolaev Donev.Optimum Experimental Designs. Oxford University Press, 08 1992. ISBN 9780198522546. doi: 10.1093/oso/9780198522546.001.0001
-
[24]
Optimum designs in regression problems.The annals of mathematical statistics, 30(2):271–294, 1959
Jack Kiefer and Jacob Wolfowitz. Optimum designs in regression problems.The annals of mathematical statistics, 30(2):271–294, 1959
1959
-
[25]
2006.Decision Modelling For Health Economic Evaluation
Anthony C. Atkinson, Alexander Nikolaev Donev, and Randall D. Tobias.Optimum Experimental Designs, with SAS. Oxford University Press, 05 2007. ISBN 9780199296590. doi: 10.1093/oso/ 9780199296590.001.0001
-
[26]
George E. P . Box.Sequential Experimentation and Sequential Assembly of Designs. Report (University of Wisconsin–Madison. Center for Quality and Productivity Improvement). Center for Quality and Productivity Improvement, University of Wisconsin-Madison, 1992. URLhttps://books.google. com/books?id=UWnDNAAACAAJ
1992
-
[27]
Xukuan Xu, Donghui Li, Jinghou Bi, and Michael Moeckel. Automl based workflow for design of ex- periments (doe) selection: benchmarking data acquisition strategies with simulation models.Scientific Reports, 14(1):32170, 2024. doi: 10.1038/s41598-024-83581-3
-
[28]
Synthesis Lectures on Artificial Intelligence and Machine Learning
Burr Settles.Active Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning. Springer, Cham, 2012. doi: 10.1007/978-3-031-01560-1. 17
-
[29]
A framework and bench- mark for deep batch active learning for regression, 2023
David Holzmüller, Viktor Zaverkin, Johannes Kästner, and Ingo Steinwart. A framework and bench- mark for deep batch active learning for regression, 2023. URLhttps://arxiv.org/abs/2203. 09410
2023
-
[30]
Yifan Fu, Xingquan Zhu, and Bin Li. A survey on instance selection for active learning.Knowledge and Information Systems, 35(2):249–283, 2013. doi: 10.1007/s10115-012-0507-8
-
[31]
Cardenas, and Nick Dexter
Ben Adcock, Juan M. Cardenas, and Nick Dexter. CS4ML: A general framework for active learning with arbitrary data based on christoffel functions, 2023. URLhttps://arxiv.org/abs/2306. 00945
2023
-
[32]
Active learning for nonlinear system identifica- tion with guarantees.Journal of Machine Learning Research, 23(1), 2022
Horia Mania, Michael I Jordan, and Benjamin Recht. Active learning for nonlinear system identifica- tion with guarantees.Journal of Machine Learning Research, 23(1), 2022
2022
-
[33]
Shields, Kurtis Gurley, Ryan Catarelli, Mohit Chauhan, Mariel Ojeda-Tuz, and Forrest J
Michael D. Shields, Kurtis Gurley, Ryan Catarelli, Mohit Chauhan, Mariel Ojeda-Tuz, and Forrest J. Masters. Active learning applied to automated physical systems increases the rate of discovery.Scien- tific Reports, 13(1):8402, 2023. doi: 10.1038/s41598-023-35257-7
-
[34]
Deep active learning for nonlinear system identification, 2023
Erlend Torje Berg Lundby, Adil Rasheed, Ivar Johan Halvorsen, Dirk Reinhardt, Sebastien Gros, and Jan Tommy Gravdahl. Deep active learning for nonlinear system identification, 2023. URLhttps: //arxiv.org/abs/2302.12667
arXiv 2023
-
[35]
Hypergraph reconstruc- tion from dynamics.Nature Communications, 16(1):2691, 2025
Robin Delabays, Giulia De Pasquale, Florian Dörfler, and Yuanzhao Zhang. Hypergraph reconstruc- tion from dynamics.Nature Communications, 16(1):2691, 2025. doi: 10.1038/s41467-025-57664-2. URL https://doi.org/10.1038/s41467-025-57664-2
-
[36]
Jonathan Horrocks and Chris T. Bauch. Algorithmic discovery of dynamic models from infectious disease data.Scientific Reports, 10(1):7061, 2020. doi: 10.1038/s41598-020-63877-w. URLhttps: //doi.org/10.1038/s41598-020-63877-w
-
[37]
Eurika Kaiser, J. Nathan Kutz, and Steven L. Brunton. Sparse identification of nonlinear dynamics for model predictive control in the low-data limit.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 474(2219):20180335, 11 2018. ISSN 1364-5021. doi: 10.1098/rspa.2018.0335
-
[38]
Nicholas Zolman, Christian Lagemann, Urban Fasel, J. Nathan Kutz, and Steven L. Brunton. SINDy- RL for interpretable and efficient model-based reinforcement learning.Nature Communications, 16(1): 10714, 2025. doi: 10.1038/s41467-025-65738-4
-
[39]
Francesco Di Fiore, Michela Nardelli, and Laura Mainini. Active learning and bayesian optimization: A unified perspective to learn with a goal.Archives of Computational Methods in Engineering, 31(5): 2985–3013, 2024. doi: 10.1007/s11831-024-10064-z
-
[40]
Consi, Luca Bonfiglio, Yue Ma, Lena R
Dixia Fan, Grégoire Jodin, Thomas R. Consi, Luca Bonfiglio, Yue Ma, Lena R. Keyes, George E. Kar- niadakis, and Michael S. Triantafyllou. A robotic intelligent towing tank for learning complex fluid- structure dynamics.Science Robotics, 4(36):eaay5063, 2019. doi: 10.1126/scirobotics.aay5063
-
[41]
Neural network ensembles, cross validation, and active learning
Anders Krogh and Jesper Vedelsby. Neural network ensembles, cross validation, and active learning. In G. Tesauro, D. Touretzky, and T. Leen, editors,Advances in Neural Information Processing Systems, volume 7. MIT Press, 1994
1994
-
[42]
Springer-Verlag, 2005
Vladimir Vovk, Alex Gammerman, and Glenn Shafer.Algorithmic Learning in a Random World. Springer-Verlag, 2005. ISBN 0387001522
2005
-
[43]
Sparse identification of nonlinear dynamics with conformal prediction, 2025
Urban Fasel. Sparse identification of nonlinear dynamics with conformal prediction, 2025. URL https://arxiv.org/abs/2507.11739. 18
arXiv 2025
-
[44]
Lloyd Fung, Urban Fasel, and Matthew Juniper. Rapid bayesian identification of sparse nonlinear dynamics from scarce and noisy data.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 481(2307):20240200, 2025. ISSN 1364-5021. doi: 10.1098/rspa.2024.0200
-
[45]
Samuel H. Rudy, Steven L. Brunton, Joshua L. Proctor, and J. Nathan Kutz. Data-driven discovery of partial differential equations.Science Advances, 3(4):e1602614, 2017. doi: 10.1126/sciadv.1602614
-
[46]
Jean-Christophe Loiseau, Bernd R. Noack, and Steven L. Brunton. Sparse reduced-order modelling: sensor-based dynamics to full-state estimation.Journal of Fluid Mechanics, 844:459–490, 2018. doi: 10.1017/jfm.2018.147
-
[47]
Daniel A. Messenger and David M. Bortz. Weak sindy: Galerkin-based data-driven model selection. Multiscale Modeling & Simulation, 19(3):1474–1497, 2021. doi: 10.1137/20M1343166
-
[48]
Patrick A. K. Reinbold, Daniel R. Gurevich, and Roman O. Grigoriev. Using noisy or incomplete data to discover models of spatiotemporal dynamics.Phys. Rev. E, 101:010203, 2020. doi: 10.1103/PhysRevE. 101.010203
-
[49]
Hayden Schaeffer and Scott G. McCalla. Sparse model selection via integral terms.Phys. Rev. E, 96: 023302, Aug 2017. doi: 10.1103/PhysRevE.96.023302
-
[50]
Alan A. Kaptanoglu, Jared L. Callaham, Aleksandr Aravkin, Christopher J. Hansen, and Steven L. Brunton. Promoting global stability in data-driven models of quadratic nonlinear dynamics.Phys. Rev. Fluids, 6:094401, 2021. doi: 10.1103/PhysRevFluids.6.094401
-
[51]
A robust sindy approach by combining neural net- works and an integral form, 2023
Ali Forootani, Pawan Goyal, and Peter Benner. A robust sindy approach by combining neural net- works and an integral form, 2023. URLhttps://arxiv.org/abs/2309.07193
arXiv 2023
-
[52]
Diverse ensembles for active learning
Prem Melville and Raymond J Mooney. Diverse ensembles for active learning. InProceedings of the twenty-first international conference on Machine learning, page 74, 2004
2004
-
[53]
An Entropy Stable High-Order Discontinuous Galerkin Method on Cut Meshes
Wenhan Gao and Chunmei Wang. Active learning based sampling for high-dimensional nonlinear partial differential equations.Journal of Computational Physics, 475:111848, 2023. doi: 10.1016/j.jcp. 2022.111848
-
[54]
Mustafa A. Mohamad and Themistoklis P . Sapsis. Sequential sampling strategy for extreme event statistics in nonlinear dynamical systems.Proceedings of the National Academy of Sciences, 115(44):11138– 11143, 2018. doi: 10.1073/pnas.1813263115
-
[55]
On fast leverage score sampling and optimal learning
Alessandro Rudi, Daniele Calandriello, Luigi Carratino, and Lorenzo Rosasco. On fast leverage score sampling and optimal learning. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Asso- ciates, Inc., 2018
2018
-
[56]
Society for Industrial and Applied Mathematics,
Friedrich Pukelsheim.Optimal Design of Experiments. Society for Industrial and Applied Mathematics,
-
[57]
doi: 10.1137/1.9780898719109
-
[58]
Krithika Manohar, Bingni W. Brunton, J. Nathan Kutz, and Steven L. Brunton. Data-driven sparse sensor placement for reconstruction: Demonstrating the benefits of exploiting known patterns.IEEE Control Systems Magazine, 38(3):63–86, 2018. doi: 10.1109/MCS.2018.2810460
-
[59]
A mathematical model illustrating the theory of turbulence
Johannes Martinus Burgers. A mathematical model illustrating the theory of turbulence. In Richard Von Mises and Theodore Von Kármán, editors,Advances in Applied Mechanics, volume 1, pages 171–199. Elsevier, 1948. doi: 10.1016/S0065-2156(08)70100-5
-
[60]
Sivashinsky
Grigory I. Sivashinsky. Nonlinear analysis of hydrodynamic instability in laminar flames—I. Deriva- tion of basic equations.Acta Astronautica, 4:1177–1206, 1977. 19
1977
-
[61]
Diffusion-induced chaos in reaction systems.Progress of Theoretical Physics Supple- ment, 64:346–367, 1978
Yoshiki Kuramoto. Diffusion-induced chaos in reaction systems.Progress of Theoretical Physics Supple- ment, 64:346–367, 1978
1978
-
[62]
Hyman and Basil Nicolaenko
James M. Hyman and Basil Nicolaenko. The Kuramoto–Sivashinsky equation: A bridge between PDEs and dynamical systems.Physica D, 18:113–126, 1986. 20
1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.