MLT-Dedup: Efficient Large-Scale Online Video Deduplication via Multi-Level Representations and Spatial-Temporal Matching
Pith reviewed 2026-06-27 09:41 UTC · model grok-4.3
The pith
MLT-Dedup uses multi-level video embeddings and temporal matching to cut online repetition rates by 91% at 90% precision while expanding indexing capacity fivefold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Multi-Level Video Encoder combined with the Differential Feature-enhanced Similarity Module enables efficient candidate retrieval at scale and supplies accurate similarity evidence for duplicated temporal segments, producing a measured 91% drop in online repetition rates at 90% precision and a fivefold gain in indexing capacity on a real-world large-scale platform.
What carries the argument
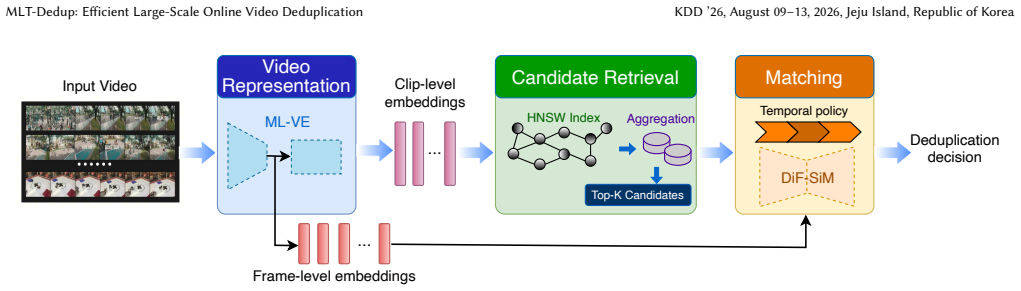
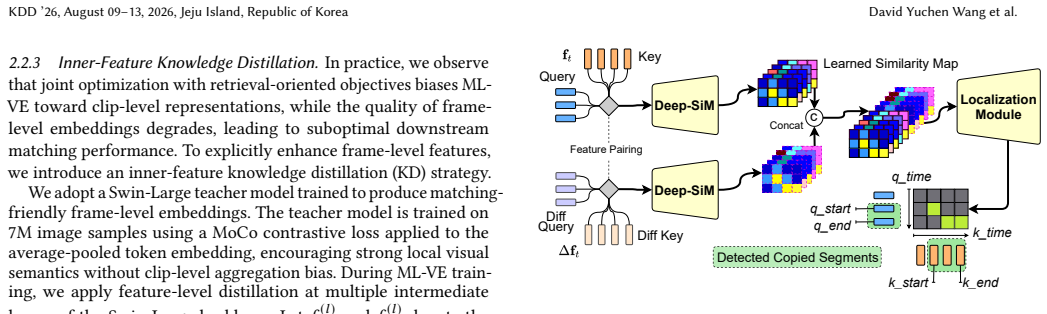
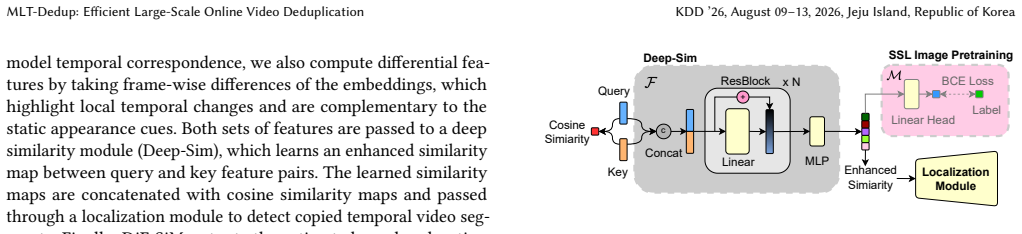
The Multi-Level Video Encoder that generates both sparse clip-level embeddings for fast retrieval and fine-grained frame-level embeddings for detailed matching, together with the Differential Feature-enhanced Similarity Module that locates duplicated temporal segments.
Load-bearing premise
The multi-level embeddings and similarity module produce similarity scores and candidate sets that remain reliable enough at full platform scale to deliver the reported repetition reduction without large numbers of missed or false duplicates.
What would settle it
An independent test on a held-out corpus of millions of real platform videos that measures the actual repetition-rate reduction when the full pipeline runs at the claimed 90% precision threshold.
Figures
read the original abstract
The explosive growth of user-generated video content on online platforms is accompanied by the emergence of numerous near-duplicate videos--videos that are identical or highly similar but differ by partial edits. These duplicates degrade user experience and increase storage and bandwidth costs, making large-scale video deduplication a critical task. Existing video deduplication frameworks face a fundamental challenge in retrieving sufficient high-quality candidates under a limited index budget, as well as trade-offs between efficiency and precision. To address these issues, we propose MLT-Dedup, an efficient large-scale online video deduplication framework with Multi-Level representations and spatial-Temporal matching. Our approach employs a Multi-Level Video Encoder (ML-VE) to extract both fine-grained frame-level and sparse clip-level embeddings: sparse embeddings support efficient candidate retrieval, while fine-grained embeddings are loaded for precise pairwise matching. During matching, we introduce DiF-SiM, a Differential Feature-enhanced Similarity Module capable of locating duplicated temporal segments and providing reliable similarity evidence to support policy-driven deduplication decisions. Extensive experiments on a real-world large-scale platform demonstrate that MLT-Dedup reduces online repetition rates by 91% at 90% precision. Furthermore, our sparse retrieval design achieves a 5x increase in indexing capacity, enabling broader candidate coverage in real-world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MLT-Dedup, an efficient large-scale online video deduplication framework. It employs a Multi-Level Video Encoder (ML-VE) to produce both fine-grained frame-level and sparse clip-level embeddings for retrieval and matching, and introduces the DiF-SiM module for differential feature-enhanced similarity to identify duplicated temporal segments. The central claims are a 91% reduction in online repetition rates at 90% precision and a 5x increase in indexing capacity, demonstrated via experiments on a real-world large-scale platform.
Significance. If the reported gains can be independently validated, the multi-level sparse retrieval design offers a practical solution to the efficiency-precision trade-off in video deduplication, with potential impact on storage and bandwidth costs for large user-generated content platforms.
major comments (2)
- [Abstract] Abstract: the central performance claims (91% repetition-rate reduction at 90% precision; 5x indexing-capacity gain) are stated as direct outcomes of the ML-VE and DiF-SiM modules with no reference to an experimental section, table, dataset description, baseline, or error analysis. This absence is load-bearing because the abstract presents these numbers without any supporting implementation or validation details.
- [Abstract] Abstract: the claim that DiF-SiM provides 'reliable similarity evidence' to support policy-driven decisions lacks any quantitative ablation, precision-recall breakdown, or comparison showing how the differential features translate into the stated 91% reduction; without this, the contribution of the proposed matching process cannot be assessed.
minor comments (1)
- [Abstract] Acronyms ML-VE and DiF-SiM are introduced without expansion on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We will revise the abstract to better contextualize the reported performance claims while preserving its summary nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (91% repetition-rate reduction at 90% precision; 5x indexing-capacity gain) are stated as direct outcomes of the ML-VE and DiF-SiM modules with no reference to an experimental section, table, dataset description, baseline, or error analysis. This absence is load-bearing because the abstract presents these numbers without any supporting implementation or validation details.
Authors: The abstract already states that the claims are demonstrated via 'extensive experiments on a real-world large-scale platform.' We agree that explicit linkage to the evaluation setup would strengthen the presentation. In the revised version we will update the abstract to note that the 91% reduction and 5x capacity gains are obtained from comparisons against baselines on the deployed platform, with full dataset description, tables, and analysis appearing in the Experiments section. revision: yes
-
Referee: [Abstract] Abstract: the claim that DiF-SiM provides 'reliable similarity evidence' to support policy-driven decisions lacks any quantitative ablation, precision-recall breakdown, or comparison showing how the differential features translate into the stated 91% reduction; without this, the contribution of the proposed matching process cannot be assessed.
Authors: Quantitative support for DiF-SiM (ablations, precision-recall curves, and its contribution to the overall 91% reduction) is presented in the Experiments section. We will revise the abstract wording to indicate that the 'reliable similarity evidence' is validated by those experimental results rather than asserted without context. revision: yes
Circularity Check
No significant circularity; empirical claims rest on platform experiments
full rationale
The paper presents an engineering system (ML-VE encoder + DiF-SiM matcher) whose central claims are measured repetition-rate reduction (91% at 90% precision) and indexing-capacity gain (5x) obtained on a real-world production platform. No equations, fitted parameters, or first-principles derivations are described that could reduce to self-definition or to a self-citation chain. The reported numbers are external empirical outcomes, not quantities defined inside the method itself. Self-citations, if present, are not load-bearing for the performance claims. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
ML-VE
no independent evidence
-
DiF-SiM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
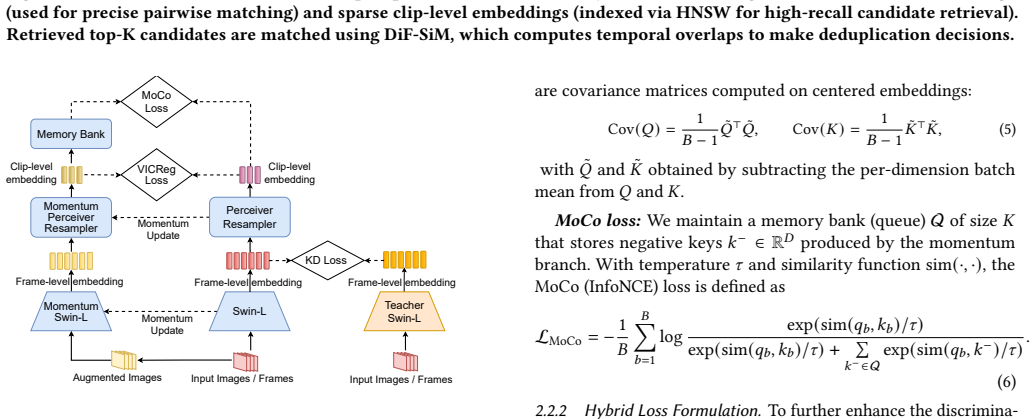
Adrien Bardes, Jean Ponce, and Yann LeCun. 2022. VICReg: Variance-Invariance- Covariance Regularization For Self-Supervised Learning. InICLR
2022
-
[2]
Berndt and James Clifford
Donald J. Berndt and James Clifford. 1994. Using Dynamic Time Warping to Find Patterns in Time Series. InKDD Workshop. https://api.semanticscholar.org/ CorpusID:929893
1994
-
[3]
Alexander Black, Simon Jenni, Tu Bui, Md Mehrab Tanjim, Stefano Petrangeli, Ritwik Sinha, Viswanathan Swaminathan, and John Collomosse. 2023. Vader: Video alignment differencing and retrieval. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision. 22357–22367. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea David Yuchen W...
2023
-
[4]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. InInterna- tional conference on machine learning. PmLR, 1597–1607
2020
-
[5]
Chien-Li Chou, Hua-Tsung Chen, and Suh-Yin Lee. 2015. Pattern-Based Near- Duplicate Video Retrieval and Localization on Web-Scale Videos.IEEE Transac- tions on Multimedia17, 3 (2015), 382–395. doi:10.1109/TMM.2015.2391674
-
[6]
Virginia R. de Sa. 1993. Learning Classification with Unlabeled Data. InNeural In- formation Processing Systems. https://api.semanticscholar.org/CorpusID:9890353
1993
-
[7]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929 [cs.CV] https://arxiv.org/abs/2010.11929
Pith/arXiv arXiv 2021
-
[8]
Matthijs Douze, Hervé Jégou, Cordelia Schmid, and Patrick Pérez. 2010. Compact Video Description for Copy Detection with Precise Temporal Alignment. In Computer Vision – ECCV 2010, Kostas Daniilidis, Petros Maragos, and Nikos Paragios (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 522–535
2010
-
[9]
David Fan, Shengbang Tong, Jiachen Zhu, Koustuv Sinha, Zhuang Liu, Xinlei Chen, Michael Rabbat, Nicolas Ballas, Yann LeCun, Amir Bar, and Saining Xie. 2025. Scaling Language-Free Visual Representation Learning. arXiv:2504.01017 [cs.CV] https://arxiv.org/abs/2504.01017
arXiv 2025
-
[10]
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. 2021. YOLOX: Exceeding YOLO Series in 2021. arXiv:2107.08430 [cs.CV] https://arxiv.org/abs/ 2107.08430
Pith/arXiv arXiv 2021
-
[11]
Jie Gui, Tuo Chen, Jing Zhang, Qiong Cao, Zhenan Sun, Hao Luo, and Dacheng Tao. 2024. A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends. arXiv:2301.05712 [cs.LG] https://arxiv.org/abs/2301.05712
arXiv 2024
-
[12]
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. 2020. Momentum Contrast for Unsupervised Visual Representation Learning. arXiv:1911.05722 [cs.CV] https://arxiv.org/abs/1911.05722
arXiv 2020
-
[13]
Sifeng He, Yue He, Minlong Lu, Chen Jiang, Xudong Yang, Feng Qian, Xi- aobo Zhang, Lei Yang, and Jiandong Zhang. 2022. TransVCL: Attention- enhanced Video Copy Localization Network with Flexible Supervision. arXiv:2211.13090 [cs.CV] https://arxiv.org/abs/2211.13090
arXiv 2022
-
[14]
Sifeng He, Xudong Yang, Chen Jiang, et al. 2022. A Large-scale Comprehensive Dataset and Copy-overlap Aware Evaluation Protocol for Segment-level Video Copy Detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21086–21095
2022
-
[15]
Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and Joao Carreira. 2021. Perceiver: General Perception with Iterative Attention. arXiv:2103.03206 [cs.CV] https://arxiv.org/abs/2103.03206
arXiv 2021
-
[16]
Chen Jiang, Kaiming Huang, Sifeng He, Xudong Yang, Wei Zhang, Xiaobo Zhang, Yuan Cheng, Lei Yang, Qing Wang, Furong Xu, Tan Pan, and Wei Chu. 2021. Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval. InProceedings of the 29th ACM International Conference on Multimedia. ACM, 1618–1626. doi:10.1145/3474085.3475301
-
[17]
Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, and Fuzhen Zhuang. 2024. E5-V: Universal Embeddings with Multimodal Large Language Models. arXiv:2407.12580 [cs.CL] https://arxiv. org/abs/2407.12580
Pith/arXiv arXiv 2024
-
[18]
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen
-
[19]
arXiv:2410.05160 [cs.CV] https://arxiv.org/abs/2410.05160
VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks. arXiv:2410.05160 [cs.CV] https://arxiv.org/abs/2410.05160
-
[20]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2017. Billion-scale similarity search with GPUs. arXiv:1702.08734 [cs.CV] https://arxiv.org/abs/1702.08734
Pith/arXiv arXiv 2017
-
[21]
Giorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and Ioannis Kompatsiaris. 2019. Finding near-duplicate videos in large-scale collections. In Video Verification in the Fake News Era. Springer, 91–126
2019
-
[22]
Giorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and Yiannis Kompatsiaris. 2016. Near-duplicate video retrieval by aggregating intermediate cnn layers. InInternational conference on multimedia modeling. Springer, 251–263
2016
-
[23]
Giorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and Yiannis Kompatsiaris. 2017. Near-Duplicate Video Retrieval With Deep Metric Learning. InProceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops
2017
-
[24]
Giorgos Kordopatis-Zilos, Christos Tzelepis, Symeon Papadopoulos, Ioannis Kompatsiaris, and Ioannis Patras. 2022. DnS: Distill-and-select for efficient and accurate video indexing and retrieval.International Journal of Computer Vision 130, 10 (2022), 2385–2407
2022
-
[25]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2025. NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models. arXiv:2405.17428 [cs.CL] https: //arxiv.org/abs/2405.17428
Pith/arXiv arXiv 2025
-
[26]
Sheng-Chieh Lin, Chankyu Lee, Mohammad Shoeybi, Jimmy Lin, Bryan Catan- zaro, and Wei Ping. 2025. MM-Embed: Universal Multimodal Retrieval with Multimodal LLMs. arXiv:2411.02571 [cs.CL] https://arxiv.org/abs/2411.02571
arXiv 2025
-
[27]
Jiajun Liu, Zi Huang, Hongyun Cai, Heng Tao Shen, Chong Wah Ngo, and Wei Wang. 2013. Near-duplicate video retrieval: Current research and future trends. ACM Computing Surveys (CSUR)45, 4 (2013), 1–23
2013
-
[28]
Yao Liu, Sam Blasiak, Weijun Xiao, Zhenhua Li, and Songqing Chen. 2015. A Quantitative Study of Video Duplicate Levels in YouTube. InInternational Con- ference on Passive and Active Network Measurement. Springer, 235–248
2015
-
[29]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv:2103.14030 [cs.CV] https://arxiv.org/abs/2103.14030
Pith/arXiv arXiv 2021
-
[30]
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu
-
[31]
arXiv:2106.13230 [cs.CV] https://arxiv.org/abs/ 2106.13230
Video Swin Transformer. arXiv:2106.13230 [cs.CV] https://arxiv.org/abs/ 2106.13230
-
[32]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. arXiv:1711.05101 [cs.LG] https://arxiv.org/abs/1711.05101
Pith/arXiv arXiv 2019
-
[33]
Minlong Lu, Yichen Lu, Siwei Nie, Xudong Yang, and Xiaobo Zhang. 2025. Self- supervised Video Copy Localization with Regional Token Representation. In Computer Vision – ECCV 2024, Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol (Eds.). Springer Nature Switzerland, Cham, 18–35
2025
-
[34]
Yu. A. Malkov and D. A. Yashunin. 2018. Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. arXiv:1603.09320 [cs.DS] https://arxiv.org/abs/1603.09320
Pith/arXiv arXiv 2018
-
[35]
Niklas Muennighoff, Hongjin Su, Liang Wang, Nan Yang, Furu Wei, Tao Yu, Aman- preet Singh, and Douwe Kiela. 2025. Generative Representational Instruction Tuning. arXiv:2402.09906 [cs.CL] https://arxiv.org/abs/2402.09906
arXiv 2025
-
[36]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Lab...
Pith/arXiv arXiv 2024
-
[37]
Dhanashree A Phalke, Sunita Jahirabadkar, and SPPU Pune. 2018. A systematic review of near duplicate video retrieval techniques.International Journal of Pure and Applied Mathematics118, 24 (2018), 1–11
2018
-
[38]
Tiago Rodrigues, Fabrício Benevenuto, Virgílio Almeida, Jussara Almeida, and Marcos Gonçalves. 2010. Equal but different: a contextual analysis of duplicated videos on YouTube.Journal of the Brazilian Computer Society16, 3 (2010), 201– 214
2010
-
[39]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. 2022. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems 35 (2022), 25278–25294
2022
-
[40]
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. 2018. Concep- tual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning. InProceedings of ACL
2018
-
[41]
Ling Shen, Richang Hong, and Yanbin Hao. 2020. Advance on large scale near- duplicate video retrieval.Frontiers of Computer Science14, 5 (2020), 145702
2020
-
[42]
Hung-Khoon Tan, Chong-Wah Ngo, Richard Hong, and Tat-Seng Chua. 2009. Scalable detection of partial near-duplicate videos by visual-temporal consistency. InProceedings of the 17th ACM International Conference on Multimedia(Beijing, China)(MM ’09). Association for Computing Machinery, New York, NY, USA, 145–154. doi:10.1145/1631272.1631295
-
[43]
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, Conghui He, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, and Yu Qiao. 2024. InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation. arXiv:2307.06942 [cs.CV] https://arxiv.org/abs/2307.06942
Pith/arXiv arXiv 2024
-
[44]
Xiao Wu, Alexander G. Hauptmann, and Chong-Wah Ngo. 2007. Practical elimination of near-duplicates from web video search. InProceedings of the 15th ACM International Conference on Multimedia(Augsburg, Germany)(MM ’07). Association for Computing Machinery, New York, NY, USA, 218–227. doi:10.1145/1291233.1291280
-
[45]
Wei Chee Yew, Hailun Xu, Sanjay Saha, Xiaotian Fan, Hiok Hian Ong, David Yuchen Wang, Kanchan Sarkar, Zhenheng Yang, and Danhui Guan. 2025. Dynamic Content Moderation in Livestreams: Combining Supervised Classifica- tion with MLLM-Boosted Similarity Matching.arXiv preprint arXiv:2512.03553 (2025)
Pith/arXiv arXiv 2025
-
[46]
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. 2025. GME: Improving Universal Multimodal Retrieval by Multimodal LLMs. arXiv:2412.16855 [cs.CL] https://arxiv.org/abs/2412.16855
Pith/arXiv arXiv 2025
-
[47]
Zirui Zhu, Hailun Xu, Yang Luo, Yong Liu, Kanchan Sarkar, Kun Xu, and Yang You. 2026. CAMEL: Confidence-Gated Reflection for Reward Modeling.arXiv preprint arXiv:2602.20670(2026)
Pith/arXiv arXiv 2026
-
[48]
Zirui Zhu, Hailun Xu, Yang Luo, Yong Liu, Kanchan Sarkar, Zhenheng Yang, and Yang You. 2026. FOCUS: Efficient Keyframe Selection for Long Video Under- standing. InInternational Conference on Learning Representations. MLT-Dedup: Efficient Large-Scale Online Video Deduplication KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Appendix A Different...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.