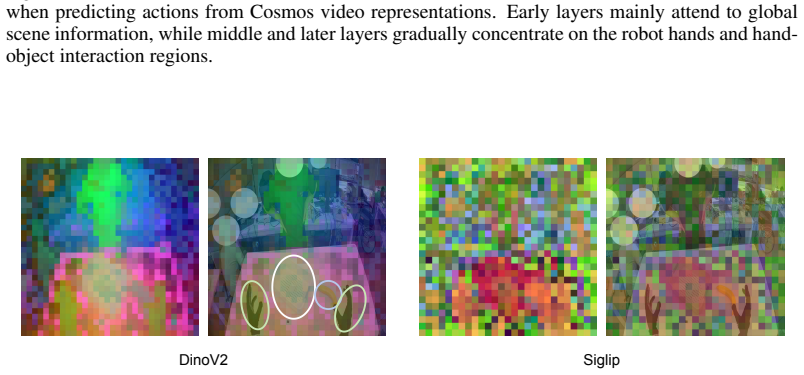
Making Foresight Actionable: Repurposing Representation Alignment in World Action Models
Pith reviewed 2026-06-27 09:39 UTC · model grok-4.3
The pith
Aligning diffusion features to semantic representations makes world action model states useful for control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
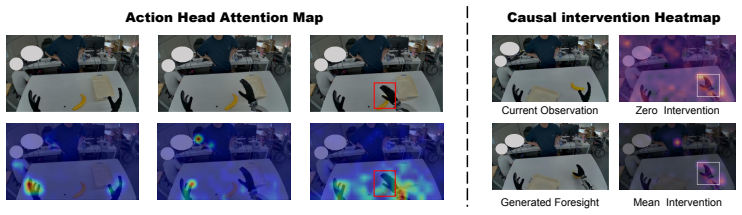
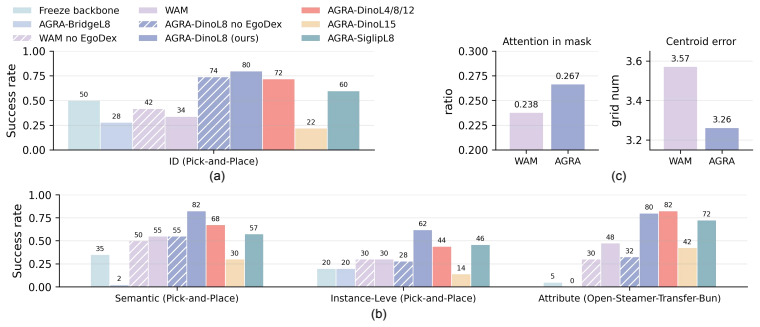
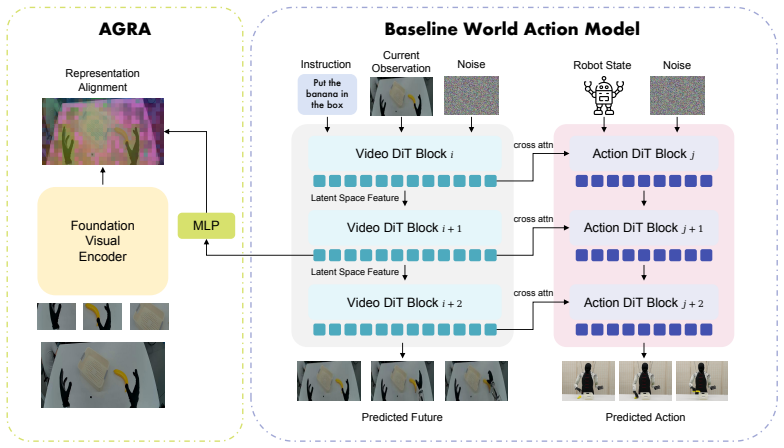
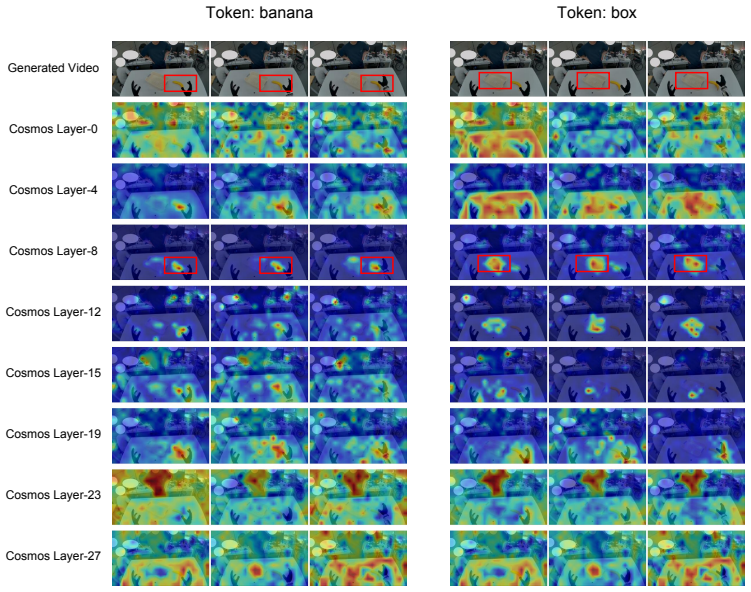
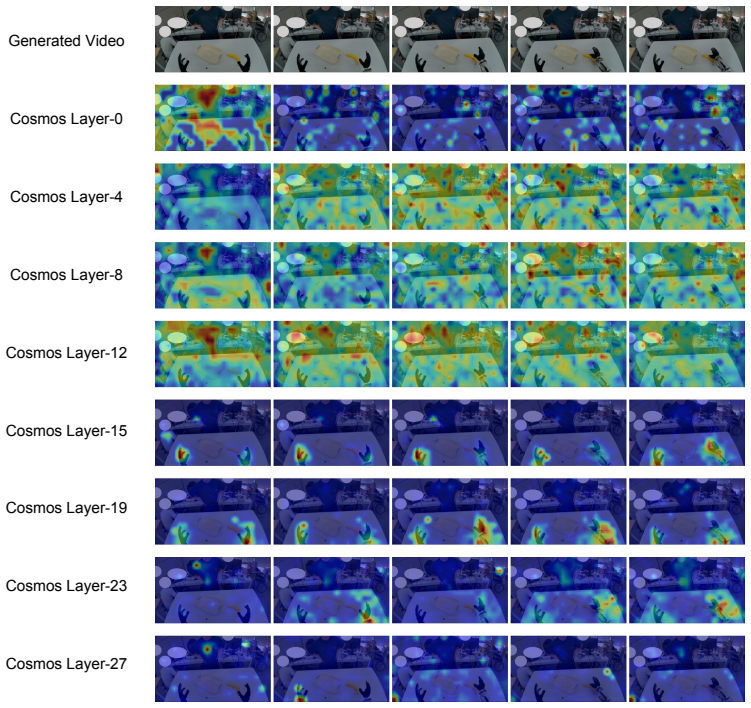
The central claim is that a representation mismatch exists between visual reconstruction objectives and action control needs, and that an Action-Grounded Representation Alignment objective resolves it by regularizing the interface between the world model and the action decoder, producing more reliable actions on real manipulation tasks.
What carries the argument
AGRA, the Action-Grounded Representation Alignment objective that matches intermediate video diffusion features to spatially coherent semantic representations from a foundation visual encoder.
If this is right
- The action decoder focuses attention on correct interaction regions instead of task-irrelevant areas.
- Object localization accuracy and affordance understanding both increase.
- The resulting policy becomes more robust to perturbations outside the task-relevant zones.
- Both in-distribution task success and out-of-distribution generalization improve over the unaligned baseline.
Where Pith is reading between the lines
- The same alignment principle could be tested on other video-prediction controllers that currently separate generation from control.
- If the foundation encoder's semantics prove too coarse for fine manipulation, the method would need a more action-specific reference representation.
- The approach implies that pure next-frame prediction is insufficient scaffolding for control and that an explicit grounding step is required.
Load-bearing premise
Aligning the diffusion model's intermediate features to a foundation visual encoder's representations will reorganize those features into a form that supports accurate low-level action decoding.
What would settle it
If the action decoder's attention maps remain unchanged or task performance fails to rise after the alignment is added, while visual prediction quality stays the same.
Figures






read the original abstract
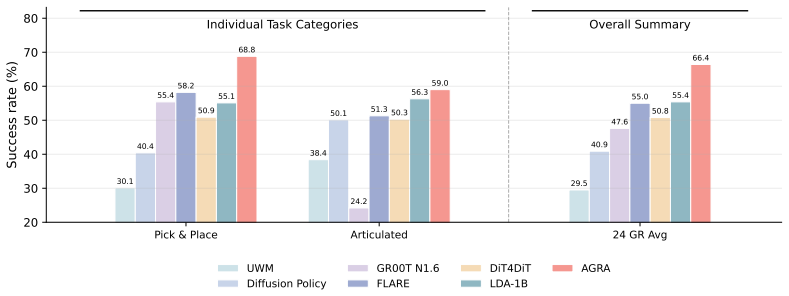
World Action Models (WAMs) offer a promising route for robot manipulation by using video generation models to model future scene evolution before producing control actions. However, our empirical observations reveal a phenomenon: generating plausible visual futures does not always guarantee the extraction of accurate actions. To diagnose this failure, we conduct action-head attention analysis and causal interventions. We find that the action decoder fails to focus on task-relevant interaction regions and remains sensitive to perturbations in task-irrelevant areas. This reveals a representation mismatch: hidden states optimized for visual reconstruction are not inherently organized in a form useful for low-level action control. In this paper, we propose AGRA, an Action-Grounded Representation Alignment objective that regularizes the world-action interface by aligning intermediate video diffusion features with spatially coherent semantic representations from a foundation visual encoder. We evaluate AGRA on real-world manipulation tasks. Experiments show that AGRA makes world model representations more action-grounded: by focusing the action decoder on the correct interaction regions, it improves object localization accuracy and affordance understanding, and makes the policy more robust to perturbations in task-irrelevant regions. As a result, AGRA consistently improves both in-distribution performance and out-of-distribution generalization over the baseline world action model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper diagnoses a representation mismatch in World Action Models (WAMs): video generation models produce plausible futures but the action decoder often fails to attend to task-relevant regions, as shown by attention analysis and causal interventions. To address this, the authors introduce AGRA, an auxiliary training objective that aligns intermediate features from a video diffusion world model with spatially coherent semantic representations from a foundation visual encoder. On real-world robot manipulation tasks, AGRA is reported to improve action grounding, object localization, affordance understanding, and both in-distribution and out-of-distribution policy performance relative to the baseline WAM.
Significance. If the reported gains are reproducible and statistically supported, the work provides a concrete, low-overhead method for making generative world models more useful for low-level control. The diagnostic experiments (attention maps and interventions) supply a clear mechanistic motivation that is often missing from alignment papers. The approach is general enough to apply to other diffusion-based action models and could influence training practices in robot learning.
minor comments (3)
- [Abstract] The abstract states that AGRA 'consistently improves' performance but supplies no numerical deltas, baseline names, dataset sizes, or statistical significance values. These details must appear in §4 (Experiments) with tables and error bars so readers can judge effect size.
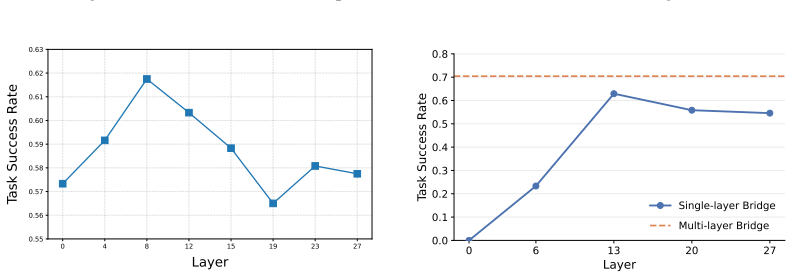
- [§3 (Method)] The description of the alignment loss (AGRA) is given at a high level; the precise form of the feature extractor, the layers chosen for alignment, the distance metric, and the weighting hyper-parameter should be stated explicitly, ideally with an equation in §3.
- [§4 (Experiments)] The claim that alignment does not degrade visual prediction quality is important for the central thesis; a quantitative comparison of reconstruction or future-frame metrics (e.g., PSNR, LPIPS) between baseline and AGRA models should be reported.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, the recognition of the diagnostic experiments, and the recommendation for minor revision. The referee's description accurately reflects the core motivation (representation mismatch in WAMs), the proposed AGRA objective, and the reported improvements in action grounding and robustness. No specific major comments were listed in the report.
Circularity Check
No significant circularity
full rationale
The paper's derivation chain consists of an empirical diagnosis (attention analysis and causal interventions on action-head behavior) followed by the introduction of an auxiliary training objective AGRA that aligns diffusion features to an external foundation encoder. No equations, fitted parameters, or self-citations are presented that reduce the claimed improvements to the inputs by construction. The central claims rest on reported performance gains on real-world robot tasks, which are evaluated externally and do not loop back to the proposal itself. This is the most common honest finding for an applied methods paper whose value is demonstrated by experiment rather than internal derivation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
AGRA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[3]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[4]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
Pith/arXiv arXiv 2025
-
[5]
R. Zheng, J. Wang, S. Reed, J. Bjorck, Y . Fang, F. Hu, J. Jang, K. Kundalia, Z. Lin, L. Magne, et al. Flare: Robot learning with implicit world modeling.arXiv preprint arXiv:2505.15659, 2025
Pith/arXiv arXiv 2025
-
[6]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y . Feng, C. Xiang, Y . Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[7]
M. Team, C. Xiang, F. Bao, H. Liu, H. Tan, H. Bi, J. Li, J. Liu, J. Pang, K. Jing, et al. Mo- tubrain: An advanced world action model for robot control.arXiv preprint arXiv:2604.27792, 2026
Pith/arXiv arXiv 2026
-
[8]
J. Won, K. Lee, H. Jang, D. Kim, and J. Shin. Dual-stream diffusion for world-model aug- mented vision-language-action model.arXiv preprint arXiv:2510.27607, 2025
Pith/arXiv arXiv 2025
-
[9]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large- scale video generative pre-training for visual robot manipulation. InInternational Conference on Learning Representations, volume 2024, pages 10641–10662, 2024
2024
-
[10]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[11]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[12]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[13]
J. Pai, L. Achenbach, V . Montesinos, B. Forrai, O. Mees, and E. Nava. mimic-video: Video- action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025
Pith/arXiv arXiv 2025
-
[14]
Brooks, B
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y . Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
2024
-
[15]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[16]
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 9
Pith/arXiv arXiv 2025
-
[17]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024
Pith/arXiv arXiv 2024
-
[18]
S. Yu, S. Kwak, H. Jang, J. Jeong, J. Huang, J. Shin, and S. Xie. Representation align- ment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024
Pith/arXiv arXiv 2024
-
[19]
B. Zheng, N. Ma, S. Tong, and S. Xie. Diffusion transformers with representation autoen- coders.arXiv preprint arXiv:2510.11690, 2025
Pith/arXiv arXiv 2025
-
[20]
S. Jha, A. Zholus, S. Chandar, et al. Reconstruction or semantics? what makes a latent space useful for robotic world models.arXiv preprint arXiv:2605.06388, 2026
Pith/arXiv arXiv 2026
-
[21]
W. Yan, Y . Zhang, P. Abbeel, and A. Srinivas. Videogpt: Video generation using vq-vae and transformers.arXiv preprint arXiv:2104.10157, 2021
Pith/arXiv arXiv 2021
-
[22]
W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
Pith/arXiv arXiv 2022
-
[23]
Blattmann, R
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563–22575, 2023
2023
-
[24]
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. En- glish, V . V oleti, A. Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[25]
Z. Zhu, X. Wang, W. Zhao, C. Min, B. Li, N. Deng, M. Dou, Y . Wang, B. Shi, K. Wang, et al. Is sora a world simulator? a comprehensive survey on general world models and beyond.arXiv preprint arXiv:2405.03520, 2024
arXiv 2024
-
[26]
Bruce, M
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y . Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, et al. Genie: Generative interactive environments. In Forty-first International Conference on Machine Learning, 2024
2024
-
[27]
R. Feng, H. Zhang, Z. Shu, Z. Yang, L. Tang, Z. Wang, A. Zheng, J. Xiao, Z. Liu, R. Chu, et al. The matrix: Infinite-horizon world generation with real-time moving control.Advances in Neural Information Processing Systems, 38:87318–87344, 2026
2026
-
[28]
J. Yu, J. Bai, Y . Qin, Q. Liu, X. Wang, P. Wan, D. Zhang, and X. Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025
2025
- [29]
-
[30]
X. Chi, P. Jia, C.-K. Fan, X. Ju, W. Mi, K. Zhang, Z. Qin, W. Tian, K. Ge, H. Li, et al. Wow: Towards a world omniscient world model through embodied interaction.arXiv preprint arXiv:2509.22642, 2025
arXiv 2025
-
[31]
G. Team, A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, J. Zhu, K. Li, M. Xu, et al. Gigaworld-0: World models as data engine to empower embodied ai.arXiv preprint arXiv:2511.19861, 2025
arXiv 2025
-
[32]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026. 10
Pith/arXiv arXiv 2026
-
[33]
Shang, X
Y . Shang, X. Zhang, Y . Tang, L. Jin, C. Gao, W. Wu, and Y . Li. Roboscape: Physics- informed embodied world model.Advances in Neural Information Processing Systems, 38: 63674–63698, 2026
2026
-
[34]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models. arXiv preprint arXiv:2505.12705, 2025
Pith/arXiv arXiv 2025
-
[35]
Y . Li, Y . Zhu, J. Wen, C. Shen, and Y . Xu. Worldeval: World model as real-world robot policies evaluator.arXiv preprint arXiv:2505.19017, 2025
arXiv 2025
-
[36]
J. Quevedo, A. K. Sharma, Y . Sun, V . Suryavanshi, P. Liang, and S. Yang. Worldgym: World model as an environment for policy evaluation.arXiv preprint arXiv:2506.00613, 2025
arXiv 2025
-
[37]
Y . Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125, 2025
Pith/arXiv arXiv 2025
-
[38]
Finn and S
C. Finn and S. Levine. Deep visual foresight for planning robot motion. In2017 IEEE inter- national conference on robotics and automation (ICRA), pages 2786–2793. IEEE, 2017
2017
-
[39]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
2023
-
[40]
Y . Feng, H. Tan, X. Mao, C. Xiang, G. Liu, S. Huang, H. Su, and J. Zhu. Vidar: Embodied video diffusion model for generalist manipulation.arXiv preprint arXiv:2507.12898, 2025
Pith/arXiv arXiv 2025
-
[41]
J. Liang, P. Tokmakov, R. Liu, S. Sudhakar, P. Shah, R. Ambrus, and C. V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Pith/arXiv arXiv 2025
-
[42]
Y . Liao, P. Zhou, S. Huang, D. Yang, S. Chen, Y . Jiang, Y . Hu, J. Cai, S. Liu, J. Luo, et al. Genie envisioner: A unified world foundation platform for robotic manipulation.arXiv preprint arXiv:2508.05635, 2025
Pith/arXiv arXiv 2025
-
[43]
T. Ma, J. Zheng, Z. Wang, C. Jiang, A. Cui, J. Liang, and S. Yang. Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control.arXiv preprint arXiv:2603.10448, 2026
arXiv 2026
-
[44]
T. Yuan, Z. Dong, Y . Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
Pith/arXiv arXiv 2026
-
[45]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[46]
C. Wei, K. Mangalam, P.-Y . Huang, Y . Li, H. Fan, H. Xu, H. Wang, C. Xie, A. Yuille, and C. Feichtenhofer. Diffusion models as masked autoencoders. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16284–16294, 2023
2023
-
[47]
X. Chen, Z. Liu, S. Xie, and K. He. Deconstructing denoising diffusion models for self- supervised learning. InInternational Conference on Learning Representations, volume 2025, pages 55458–55472, 2025
2025
-
[48]
Xiang, H
W. Xiang, H. Yang, D. Huang, and Y . Wang. Denoising diffusion autoencoders are unified self- supervised learners. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15802–15812, 2023
2023
-
[49]
Yang and X
X. Yang and X. Wang. Diffusion model as representation learner. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18938–18949, 2023. 11
2023
-
[50]
Caron, H
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 9650–9660, 2021
2021
-
[51]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[52]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
- [53]
-
[54]
X. Leng, J. Singh, Y . Hou, Z. Xing, S. Xie, and L. Zheng. Repa-e: Unlocking vae for end- to-end tuning of latent diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18262–18272, 2025
2025
- [55]
-
[56]
Zhang, J
X. Zhang, J. Liao, S. Zhang, F. Meng, X. Wan, J. Yan, and Y . Cheng. Videorepa: Learning physics for video generation through relational alignment with foundation models.Advances in Neural Information Processing Systems, 38:122647–122676, 2026
2026
-
[57]
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[58]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024
Pith/arXiv arXiv 2024
-
[59]
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[60]
Abdi and L
H. Abdi and L. J. Williams. Principal component analysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010
2010
-
[61]
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
Pith/arXiv arXiv 2025
-
[62]
Y . Chen, Y . Ge, H. Zhou, M. Ding, Y . Ge, and X. Liu. Dial: Decoupling intent and action via latent world modeling for end-to-end vla.arXiv preprint arXiv:2603.29844, 2026
Pith/arXiv arXiv 2026
-
[63]
S. Li, Y . Gao, D. Sadigh, and S. Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
Pith/arXiv arXiv 2025
-
[64]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[65]
J. Lyu, K. Liu, X. Zhang, H. Liao, Y . Feng, W. Zhu, T. Shen, J. Chen, J. Zhang, Y . Dong, et al. Lda-1b: Scaling latent dynamics action model via universal embodied data ingestion.arXiv preprint arXiv:2602.12215, 2026
Pith/arXiv arXiv 2026
-
[66]
NVIDIA GEAR Team, A. Azzolini, J. Bjorck, V . Blukis, et al. Gr00t n1.6: An improved open foundation model for generalist humanoid robots.https://research.nvidia.com/labs/ gear/gr00t-n1_6/, December 2025. 12 Video DiT Block � Video DiT Block �+ 1 Video DiT Block �+ 2 Latent Space Feature Latent Space Feature Action DiT Block � Action DiT Block � + 2 Actio...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.