On The Effectiveness-Fluency Trade-Off In LLM Conditioning: A Systematic Study
Pith reviewed 2026-06-27 09:39 UTC · model grok-4.3
The pith
Efficient steering methods for controlling LLM concepts often degrade fluency, and activation steering works far worse on instruction-tuned models than base ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
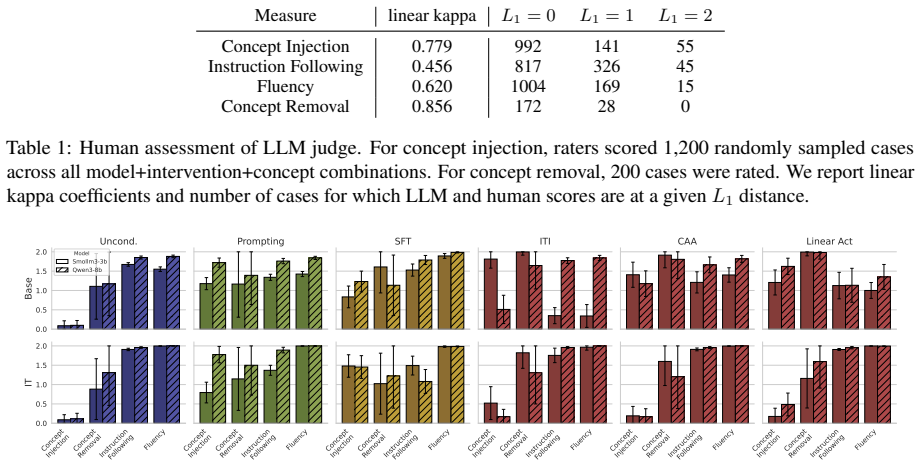
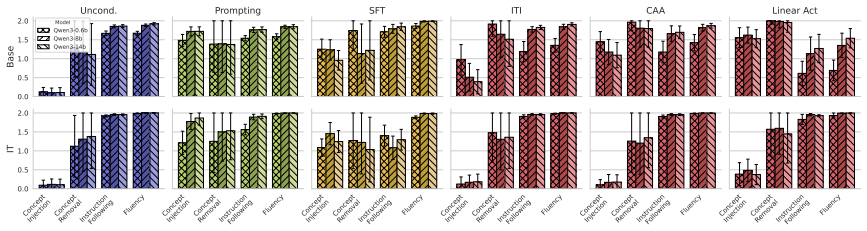
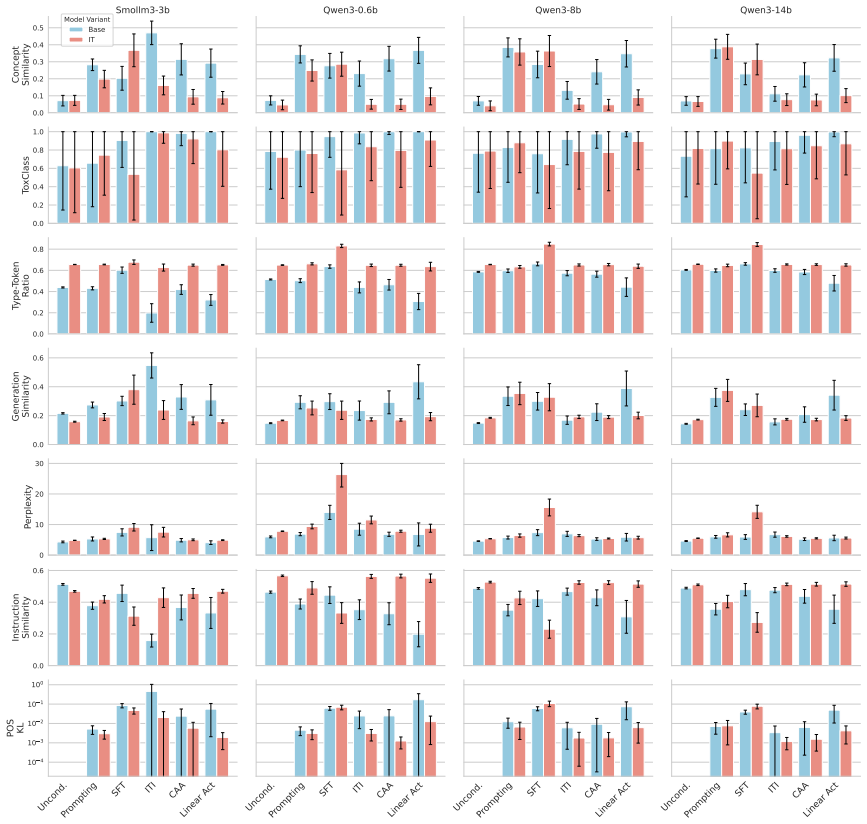
Efficient conditioning methods achieve target-concept control at a steep cost to fluency; activation steering in particular is far less effective on instruction-tuned models than on their base counterparts, while prompting and full supervised fine-tuning remain viable mainly for injection rather than removal.
What carries the argument
Systematic comparison of conditioning techniques (activation steering, prompting, supervised fine-tuning) on effectiveness versus fluency metrics, measured separately on base and instruction-tuned models for both injection and removal.
If this is right
- Activation steering should be applied with caution or replaced when the target model has been instruction-tuned.
- Prompting and supervised fine-tuning can be preferred for concept injection but require additional techniques for reliable removal.
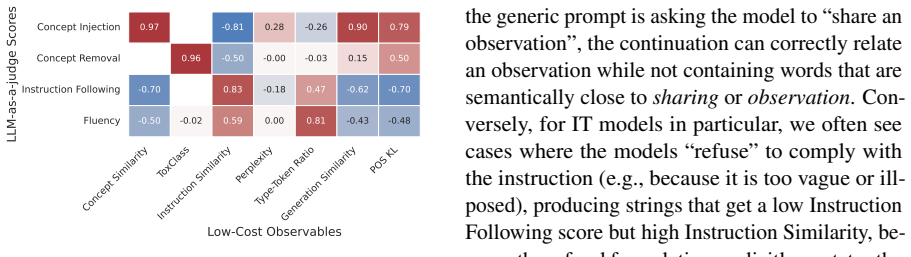
- Textual metrics can substitute for LLM-as-judge evaluation in rapid iteration over conditioning methods.
- Any deployment that relies on conditioning must budget for fluency degradation rather than assume it can be avoided at low cost.
Where Pith is reading between the lines
- The training paradigm appears to alter how internal activations encode steerable concepts, suggesting future work on methods that operate after the instruction-tuning stage.
- The observed metric correlation opens the possibility of fully automated, low-cost benchmarking loops for new conditioning algorithms.
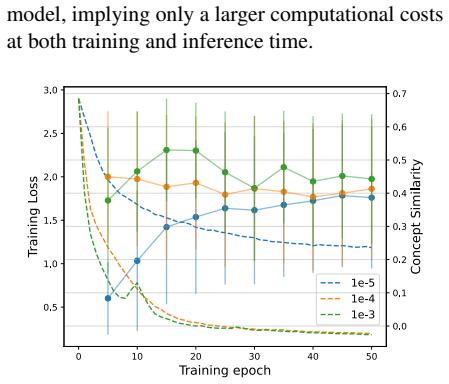
- If the fluency cost scales with model size or domain, conditioning may become impractical for the largest deployed systems without new architectures.
Load-bearing premise
The chosen textual and LLM-judge metrics plus the specific models and concepts tested stand in for the broader space of LLM conditioning tasks.
What would settle it
An experiment in which activation steering on several instruction-tuned models achieves high concept control scores with no measurable fluency drop, using the same metrics and a wider range of concepts, would falsify the reported interaction.
Figures
read the original abstract
Controlling the output of Large Language Models (LLMs) is a central challenge for their reliable deployment, yet a clear understanding of the involved trade-offs remains elusive. Current approaches to conditioning are often evaluated with a narrow focus on their effectiveness at injecting or removing a target concept, neglecting generation quality. We systematically investigate a range of conditioning methods in both injection and removal scenarios. We find that efficient steering methods frequently achieve conditioning at a steep cost to fluency. Furthermore, we identify a critical yet previously overlooked interaction with the training paradigm: activation steering methods are far less effective on instruction-tuned models than on their base counterparts. Simple prompting and full-fledged supervised fine-tuning, on the other hand, are viable options for concept injection, but are not as good at concept removal. Finally, cheaply computed textual metrics highly correlate to costly LLM-as-judge scores, and provide insights on the behavior of conditioning methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper systematically compares a range of LLM conditioning methods (steering, prompting, SFT) across concept injection and removal tasks. It reports an effectiveness-fluency trade-off in which efficient steering methods succeed at conditioning but degrade fluency, an interaction whereby activation steering is markedly less effective on instruction-tuned models than base models, prompting/SFT being stronger for injection than removal, and cheap textual metrics correlating highly with LLM-as-judge scores.
Significance. If the empirical patterns hold, the work supplies actionable guidance on method selection for controlled generation and flags a previously under-examined dependence on training paradigm. The textual-metric correlation result is practically useful for lowering evaluation cost.
major comments (1)
- [Abstract and §3] Abstract and §3 (Experimental Setup): the central claims rest on comparisons across models and methods, yet the provided text supplies no information on the exact models, number of runs, statistical tests, or controls for prompt length / decoding hyperparameters; without these the reported base-vs-instruction-tuned interaction and fluency trade-off cannot be verified or reproduced.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence stating the number of conditioning methods and model families examined.
Simulated Author's Rebuttal
We thank the referee for their detailed feedback on the experimental reporting. We address the concern point by point below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Experimental Setup): the central claims rest on comparisons across models and methods, yet the provided text supplies no information on the exact models, number of runs, statistical tests, or controls for prompt length / decoding hyperparameters; without these the reported base-vs-instruction-tuned interaction and fluency trade-off cannot be verified or reproduced.
Authors: We agree that the manuscript as currently written does not supply the requested experimental details in §3 or the abstract. This is a genuine omission that limits reproducibility of the base-vs-instruction-tuned interaction and the fluency trade-off. In the revised manuscript we will expand §3 with the precise model names and sizes (including both base and instruction-tuned variants), the number of independent runs and random seeds, the statistical tests performed, and the fixed controls applied to prompt length and decoding hyperparameters (temperature, top-p, max new tokens, etc.). These additions will be summarized concisely in the abstract as well. revision: yes
Circularity Check
No significant circularity detected
full rationale
This is an empirical study reporting experimental comparisons of conditioning methods on LLMs, with results derived from direct measurements of effectiveness and fluency metrics across base and instruction-tuned models. No mathematical derivations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described methodology; claims rest on observed data patterns rather than reducing to inputs by construction. The work is self-contained against external benchmarks via its systematic experimental design.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs respond to conditioning methods such as activation steering, prompting, and supervised fine-tuning in measurable ways.
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights , author=. 2025 , eprint=
2025
-
[2]
Proceedings of the 16th International Natural Language Generation Conference , pages=
Fine-tuning GPT-3 for synthetic Danish news generation , author=. Proceedings of the 16th International Natural Language Generation Conference , pages=
-
[3]
International conference on data intelligence and cognitive informatics , pages=
Prompt engineering in large language models , author=. International conference on data intelligence and cognitive informatics , pages=. 2023 , organization=
2023
-
[4]
Perceiver
Andrew Jaegle and Sebastian Borgeaud and Jean-Baptiste Alayrac and Carl Doersch and Catalin Ionescu and David Ding and Skanda Koppula and Daniel Zoran and Andrew Brock and Evan Shelhamer and Olivier J Henaff and Matthew Botvinick and Andrew Zisserman and Oriol Vinyals and Joao Carreira , booktitle =. Perceiver. 2022 , url =
2022
-
[5]
2025 , eprint =
End-to-end Learning of Sparse Interventions on Activations to Steer Generation , author =. 2025 , eprint =
2025
-
[6]
The Thirteenth International Conference on Learning Representations , year =
Controlling Language and Diffusion Models by Transporting Activations , author =. The Thirteenth International Conference on Learning Representations , year =
-
[7]
Text-to-Lo
Rujikorn Charakorn and Edoardo Cetin and Yujin Tang and Robert Tjarko Lange , booktitle =. Text-to-Lo. 2025 , url =
2025
-
[8]
2025 , eprint =
Transferring Features Across Language Models With Model Stitching , author =. 2025 , eprint =
2025
-
[9]
Thirty-seventh Conference on Neural Information Processing Systems , year =
Antonio Norelli and Marco Fumero and Valentino Maiorca and Luca Moschella and Emanuele Rodol. Thirty-seventh Conference on Neural Information Processing Systems , year =
-
[10]
Cross-model Transferability among Large Language Models on the Platonic Representations of Concepts , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =. doi:10.18653/v1/2025.acl-long.185 , pages =
-
[11]
2025 , eprint =
Activation Space Interventions Can Be Transferred Between Large Language Models , author =. 2025 , eprint =
2025
-
[12]
2025 , eprint =
Linear Representation Transferability Hypothesis: Leveraging Small Models to Steer Large Models , author =. 2025 , eprint =
2025
-
[13]
2025 , eprint =
HyperSteer: Activation Steering at Scale with Hypernetworks , author =. 2025 , eprint =
2025
-
[14]
The Eleventh International Conference on Learning Representations , year =
Relative representations enable zero-shot latent space communication , author =. The Eleventh International Conference on Learning Representations , year =
-
[15]
Thirty-seventh Conference on Neural Information Processing Systems , year =
Latent Space Translation via Semantic Alignment , author =. Thirty-seventh Conference on Neural Information Processing Systems , year =
-
[16]
Proceedings of the 41st International Conference on Machine Learning , pages =
Position: The Platonic Representation Hypothesis , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[17]
The Journal of Machine Learning Research , volume =
Exploring the limits of transfer learning with a unified text-to-text transformer , author =. The Journal of Machine Learning Research , volume =. 2020 , publisher =
2020
-
[18]
Journal of computational and graphical statistics , volume =
A sparse-group lasso , author =. Journal of computational and graphical statistics , volume =. 2013 , publisher =
2013
-
[19]
Bernoulli , volume =
On Lasso refitting strategies , author =. Bernoulli , volume =
-
[20]
2022 , address =
Logacheva, Varvara and Dementieva, Daryna and Ustyantsev, Sergey and Moskovskiy, Daniil and Dale, David and Krotova, Irina and Semenov, Nikita and Panchenko, Alexander , booktitle =. 2022 , address =
2022
-
[21]
arXiv preprint arXiv:2410.13025 , year =
Lora soups: Merging loras for practical skill composition tasks , author =. arXiv preprint arXiv:2410.13025 , year =
-
[22]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year =
Stylus: Automatic Adapter Selection for Diffusion Models , author =. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year =
-
[23]
arXiv preprint arXiv:2207.12598 , year =
Classifier-free diffusion guidance , author =. arXiv preprint arXiv:2207.12598 , year =
-
[24]
Least squares after model selection in high-dimensional sparse models , author =
-
[25]
Scale Space and Variational Methods in Computer Vision: Third International Conference, SSVM 2011, Ein-Gedi, Israel, May 29--June 2, 2011, Revised Selected Papers 3 , pages =
Wasserstein barycenter and its application to texture mixing , author =. Scale Space and Variational Methods in Computer Vision: Third International Conference, SSVM 2011, Ein-Gedi, Israel, May 29--June 2, 2011, Revised Selected Papers 3 , pages =. 2012 , organization =
2011
-
[26]
arXiv preprint arXiv:2311.06668 , year =
In-context vectors: Making in context learning more effective and controllable through latent space steering , author =. arXiv preprint arXiv:2311.06668 , year =
-
[27]
arXiv preprint arXiv:2501.05764 , year =
Controlling Large Language Models Through Concept Activation Vectors , author =. arXiv preprint arXiv:2501.05764 , year =
-
[28]
arXiv preprint arXiv:2406.17563 , year =
Multi-property steering of large language models with dynamic activation composition , author =. arXiv preprint arXiv:2406.17563 , year =
-
[29]
Proceedings of the 34th International Conference on Machine Learning , pages =
Combined Group and Exclusive Sparsity for Deep Neural Networks , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
2017
-
[30]
Bakouch, Elie and Ben Allal, Loubna and Lozhkov, Anton and Tazi, Nouamane and Tunstall, Lewis and Patiño, Carlos Miguel and Beeching, Edward and Roucher, Aymeric and Reedi, Aksel Joonas and Gallouédec, Quentin and Rasul, Kashif and Habib, Nathan and Fourrier, Clémentine and Kydlicek, Hynek and Penedo, Guilherme and Larcher, Hugo and Morlon, Mathieu and Sr...
-
[31]
Optimal transport for applied mathematicians , author =. Birk. 2015 , publisher =
2015
-
[32]
arXiv preprint arXiv:1909.05858 , year =
Ctrl: A conditional transformer language model for controllable generation , author =. arXiv preprint arXiv:1909.05858 , year =
Pith/arXiv arXiv 1909
-
[33]
Advances in Neural Information Processing Systems , volume =
Training language models to follow instructions with human feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[34]
arXiv preprint arXiv:2112.11446 , year =
Scaling language models: Methods, analysis & insights from training gopher , author =. arXiv preprint arXiv:2112.11446 , year =
-
[35]
arXiv preprint arXiv:2212.08061 , year =
On Second Thought, Let's Not Think Step by Step! Bias and Toxicity in Zero-Shot Reasoning , author =. arXiv preprint arXiv:2212.08061 , year =
-
[36]
arXiv preprint arXiv:1912.02164 , year =
Plug and play language models: A simple approach to controlled text generation , author =. arXiv preprint arXiv:1912.02164 , year =
arXiv 1912
-
[37]
arXiv preprint arXiv:2201.05337 , year =
A survey of controllable text generation using transformer-based pre-trained language models , author =. arXiv preprint arXiv:2201.05337 , year =
-
[38]
arXiv preprint arXiv:2304.11082 , year =
Fundamental limitations of alignment in large language models , author =. arXiv preprint arXiv:2304.11082 , year =
-
[39]
Advances in mathematics , volume =
A convexity principle for interacting gases , author =. Advances in mathematics , volume =. 1997 , publisher =
1997
-
[40]
Foundations and Trends in Machine Learning , publisher =
Peyré, Gabriel and Cuturi, Marco , year =. Foundations and Trends in Machine Learning , publisher =
-
[41]
Advances in neural information processing systems , volume =
Language models are few-shot learners , author =. Advances in neural information processing systems , volume =
-
[42]
arXiv preprint arXiv:2302.13971 , year =
Llama: Open and efficient foundation language models , author =. arXiv preprint arXiv:2302.13971 , year =
-
[43]
arXiv preprint arXiv:2205.01068 , year =
Opt: Open pre-trained transformer language models , author =. arXiv preprint arXiv:2205.01068 , year =
-
[44]
The Woman Worked as a Babysitter: On Biases in Language Generation , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages =
2019
-
[45]
Findings of the Association for Computational Linguistics: EMNLP 2021 , pages =
Challenges in Detoxifying Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2021 , pages =
2021
-
[46]
International Conference on Machine Learning , pages =
Self-conditioning pre-trained language models , author =. International Conference on Machine Learning , pages =. 2022 , organization =
2022
-
[47]
Causal Learning and Reasoning , pages =
Finding alignments between interpretable causal variables and distributed neural representations , author =. Causal Learning and Reasoning , pages =. 2024 , organization =
2024
-
[48]
CEUR Workshop proceedings , volume =
Hurtlex: A multilingual lexicon of words to hurt , author =. CEUR Workshop proceedings , volume =. 2018 , organization =
2018
-
[49]
arXiv preprint arXiv:2407.18163 , year =
Statistical optimal transport , author =. arXiv preprint arXiv:2407.18163 , year =
-
[50]
International conference on machine learning , pages =
Parameter-efficient transfer learning for NLP , author =. International conference on machine learning , pages =. 2019 , organization =
2019
-
[51]
International Conference on Learning Representations , year =
Plug and Play Language Models: A Simple Approach to Controlled Text Generation , author =. International Conference on Learning Representations , year =
-
[52]
Proceedings of the international AAAI conference on web and social media , volume =
Automated hate speech detection and the problem of offensive language , author =. Proceedings of the international AAAI conference on web and social media , volume =
-
[53]
Proceedings of the international AAAI conference on web and social media , volume =
Large scale crowdsourcing and characterization of twitter abusive behavior , author =. Proceedings of the international AAAI conference on web and social media , volume =
-
[54]
arXiv preprint arXiv:1704.01444 , year =
Learning to generate reviews and discovering sentiment , author =. arXiv preprint arXiv:1704.01444 , year =
-
[55]
arXiv preprint arXiv:1908.07125 , year =
Universal adversarial triggers for attacking and analyzing NLP , author =. arXiv preprint arXiv:1908.07125 , year =
arXiv 1908
-
[56]
arXiv preprint arXiv:2009.11462 , year =
Realtoxicityprompts: Evaluating neural toxic degeneration in language models , author =. arXiv preprint arXiv:2009.11462 , year =
Pith/arXiv arXiv 2009
-
[57]
The Singularity Institute, San Francisco, USA , year =
Creating friendly AI 1.0: The analysis and design of benevolent goal architectures , author =. The Singularity Institute, San Francisco, USA , year =
-
[58]
Ethics of Artificial Intelligence , pages =
Alignment for advanced machine learning systems , author =. Ethics of Artificial Intelligence , pages =. 2016 , publisher =
2016
-
[59]
arXiv preprint arXiv:2006.16823 , year =
Technical report: Auxiliary tuning and its application to conditional text generation , author =. arXiv preprint arXiv:2006.16823 , year =
arXiv 2006
-
[60]
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages =
-
[61]
arXiv preprint arXiv:1909.08593 , year =
Fine-tuning language models from human preferences , author =. arXiv preprint arXiv:1909.08593 , year =
Pith/arXiv arXiv 1909
-
[62]
arXiv preprint arXiv:2210.11416 , year =
Scaling instruction-finetuned language models , author =. arXiv preprint arXiv:2210.11416 , year =
-
[63]
arXiv preprint arXiv:2006.03535 , year =
Cocon: A self-supervised approach for controlled text generation , author =. arXiv preprint arXiv:2006.03535 , year =
arXiv 2006
-
[64]
arXiv preprint arXiv:2009.06367 , year =
Gedi: Generative discriminator guided sequence generation , author =. arXiv preprint arXiv:2009.06367 , year =
arXiv 2009
-
[65]
arXiv preprint arXiv:2004.11714 , year =
Residual energy-based models for text generation , author =. arXiv preprint arXiv:2004.11714 , year =
arXiv 2004
-
[66]
arXiv preprint arXiv:2104.05218 , year =
FUDGE: Controlled text generation with future discriminators , author =. arXiv preprint arXiv:2104.05218 , year =
-
[67]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages =
P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages =
-
[68]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
Network dissection: Quantifying interpretability of deep visual representations , author =. Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
-
[69]
International Conference on Learning Representations , year =
GAN Dissection: Visualizing and Understanding Generative Adversarial Networks , author =. International Conference on Learning Representations , year =
-
[70]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
Net2vec: Quantifying and explaining how concepts are encoded by filters in deep neural networks , author =. Proceedings of the IEEE conference on computer vision and pattern recognition , pages =
-
[71]
Neural computation , volume =
Long short-term memory , author =. Neural computation , volume =. 1997 , publisher =
1997
-
[72]
Advances in neural information processing systems , volume =
Attention is all you need , author =. Advances in neural information processing systems , volume =
-
[73]
International Conference on Machine Learning , pages =
Pretraining language models with human preferences , author =. International Conference on Machine Learning , pages =. 2023 , organization =
2023
-
[74]
NeurIPS ML Safety Workshop , year =
Ignore Previous Prompt: Attack Techniques For Language Models , author =. NeurIPS ML Safety Workshop , year =
-
[75]
arXiv preprint arXiv:1903.10561 , year =
On measuring social biases in sentence encoders , author =. arXiv preprint arXiv:1903.10561 , year =
Pith/arXiv arXiv 1903
-
[76]
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , volume =
Gender Bias in Contextualized Word Embeddings , author =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , volume =
2019
-
[77]
Almazrouei, Ebtesam and Alobeidli, Hamza and Alshamsi, Abdulaziz and Cappelli, Alessandro and Cojocaru, Ruxandra and Debbah, Merouane and Goffinet, Etienne and Heslow, Daniel and Launay, Julien and Malartic, Quentin and Noune, Badreddine and Pannier, Baptiste and Penedo, Guilherme , year =
-
[78]
Prompting
Chenglei Si and Zhe Gan and Zhengyuan Yang and Shuohang Wang and Jianfeng Wang and Jordan Lee Boyd-Graber and Lijuan Wang , booktitle =. Prompting. 2023 , url =
2023
-
[79]
Evaluating the underlying gender bias in contextualized word embeddings , author =. The 2019 Conferenceof the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: NAACL HLT 2019: Proceedings of the Conference: June 2-June 7, 2019 , pages =. 2019 , organization =
2019
-
[80]
Proceedings of the First Workshop on Gender Bias in Natural Language Processing , pages =
Measuring Bias in Contextualized Word Representations , author =. Proceedings of the First Workshop on Gender Bias in Natural Language Processing , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.