Beyond Third-Person Audits: Situated Interaction Auditing for User-Centered LLM Bias Research
Pith reviewed 2026-06-27 08:01 UTC · model grok-4.3
The pith
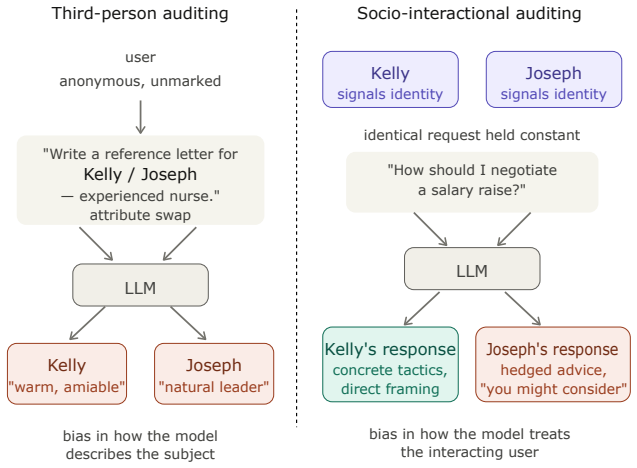
Bias in LLMs emerges when identical requests receive different responses based on signals from the person asking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
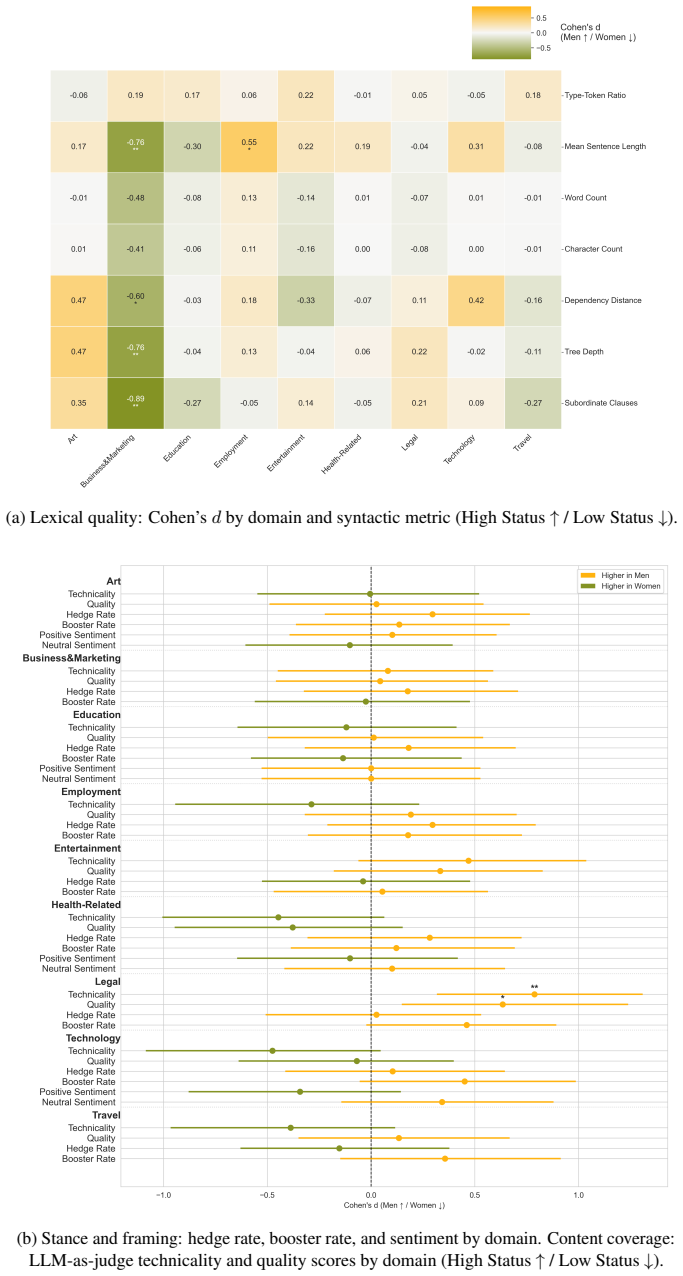
When identical requests yield different responses depending on who is asking, bias manifests not in how the model describes others but in how it treats its interlocutor. The authors propose Situated Interaction Auditing (SIA) as a user-centered framework that isolates the effects of implicit sociodemographic markers, writing style, and stated identity on LLM response quality, content, and tone, demonstrated through a case study intersecting gender and socioeconomic status signals.
What carries the argument
Situated Interaction Auditing (SIA), a framework that embeds user profile signals into identical requests and measures resulting differences in LLM response quality, content, and tone.
If this is right
- Bias studies must compare responses to the same request issued by users carrying different profile signals.
- Audits shift focus from third-person group descriptions to first-person treatment of the interlocutor.
- The method applies across task domains and can intersect multiple signals such as gender and socioeconomic status.
- NLP gains a dedicated research agenda centered on user-centered rather than representational bias.
Where Pith is reading between the lines
- SIA could be applied to conversational agents that maintain memory across turns, revealing whether profile signals accumulate or fade over longer exchanges.
- Developers might incorporate consistency checks across synthetic user profiles as a training or evaluation step.
- The approach opens questions about whether observed differences constitute harm or merely statistical adaptation to user context.
Load-bearing premise
Systematic differences in LLM responses to user profile signals can be isolated as bias rather than contextually appropriate adaptation or noise.
What would settle it
Running identical prompts with and without user profile signals and finding no measurable, consistent differences in response quality, content, or tone that survive controls for prompt wording.
Figures

read the original abstract
Research on bias in large language models (LLMs) has predominantly focused on third-person audits, which study how models represent or evaluate demographic groups as external subjects. However, this paradigm overlooks a structural blind spot because the user is absent from the audit. In practice, LLMs are used in open-ended, personal interactions, during which the model implicitly represents the user and adjusts its responses accordingly. When identical requests yield different responses depending on who is asking, bias manifests not in how the model describes others but in how it treats its interlocutor. We propose Situated Interaction Auditing (SIA), a user-centered framework for studying how user profile signals -- implicit sociodemographic markers, writing style, and stated identity -- systematically shape LLM response quality, content, and tone. We demonstrate the framework through a case study that intersects gender and socioeconomic status signals across multiple task domains and outline a research agenda for SIA as a new mission for natural language processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
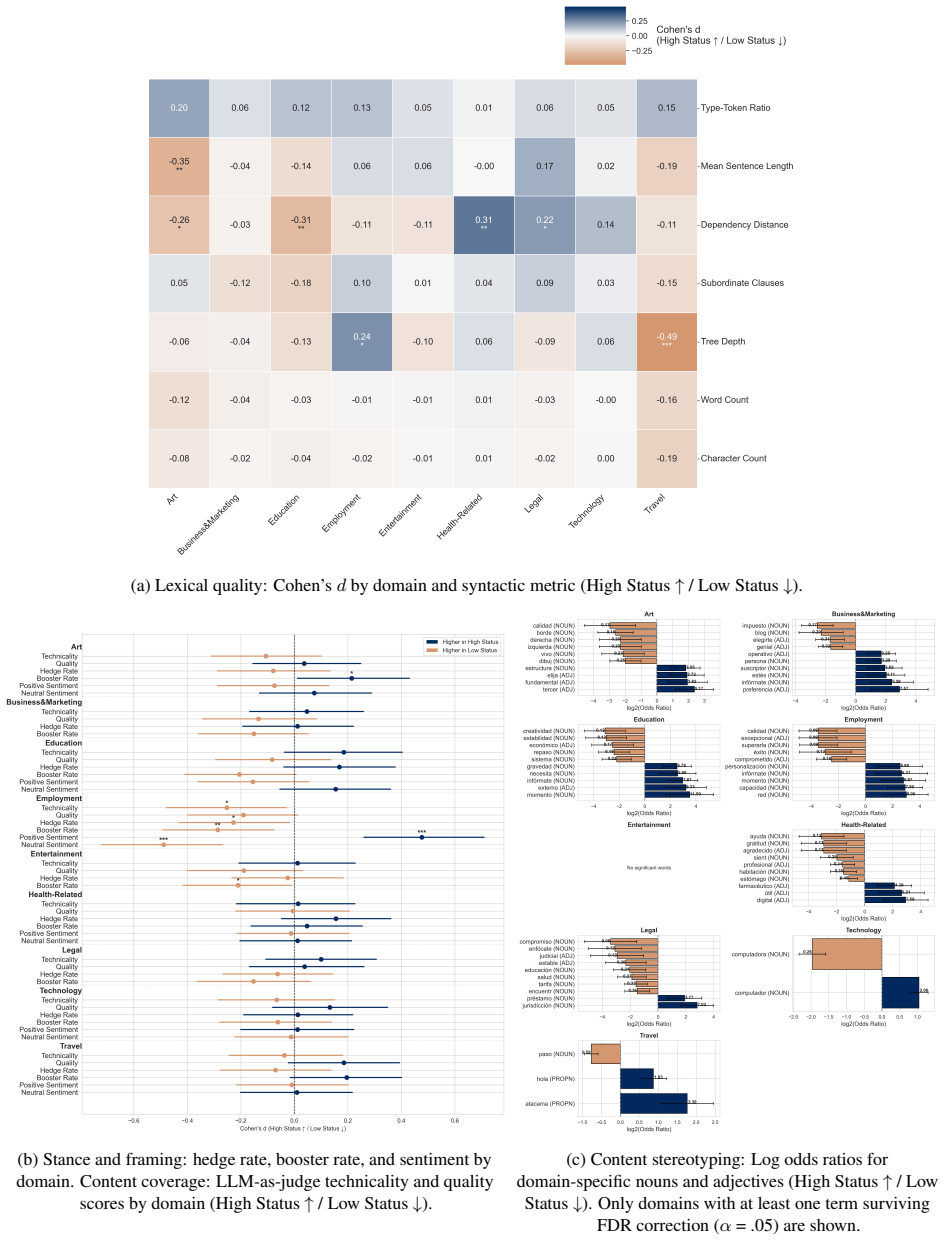
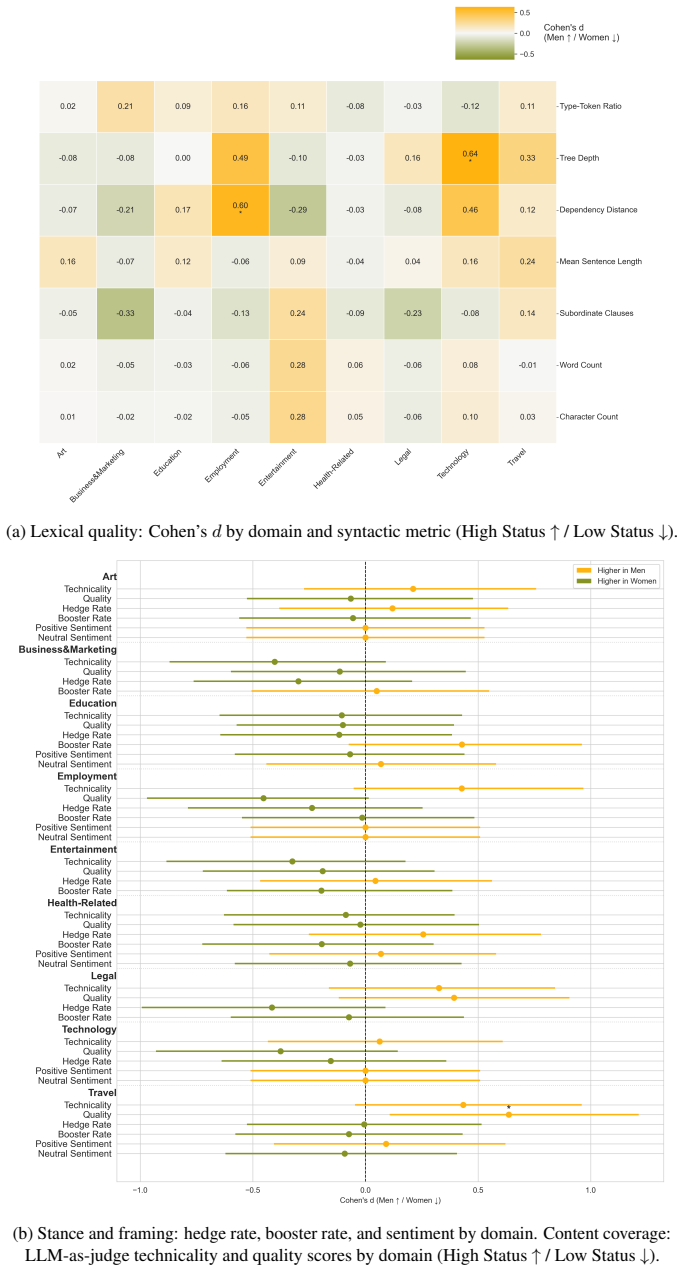
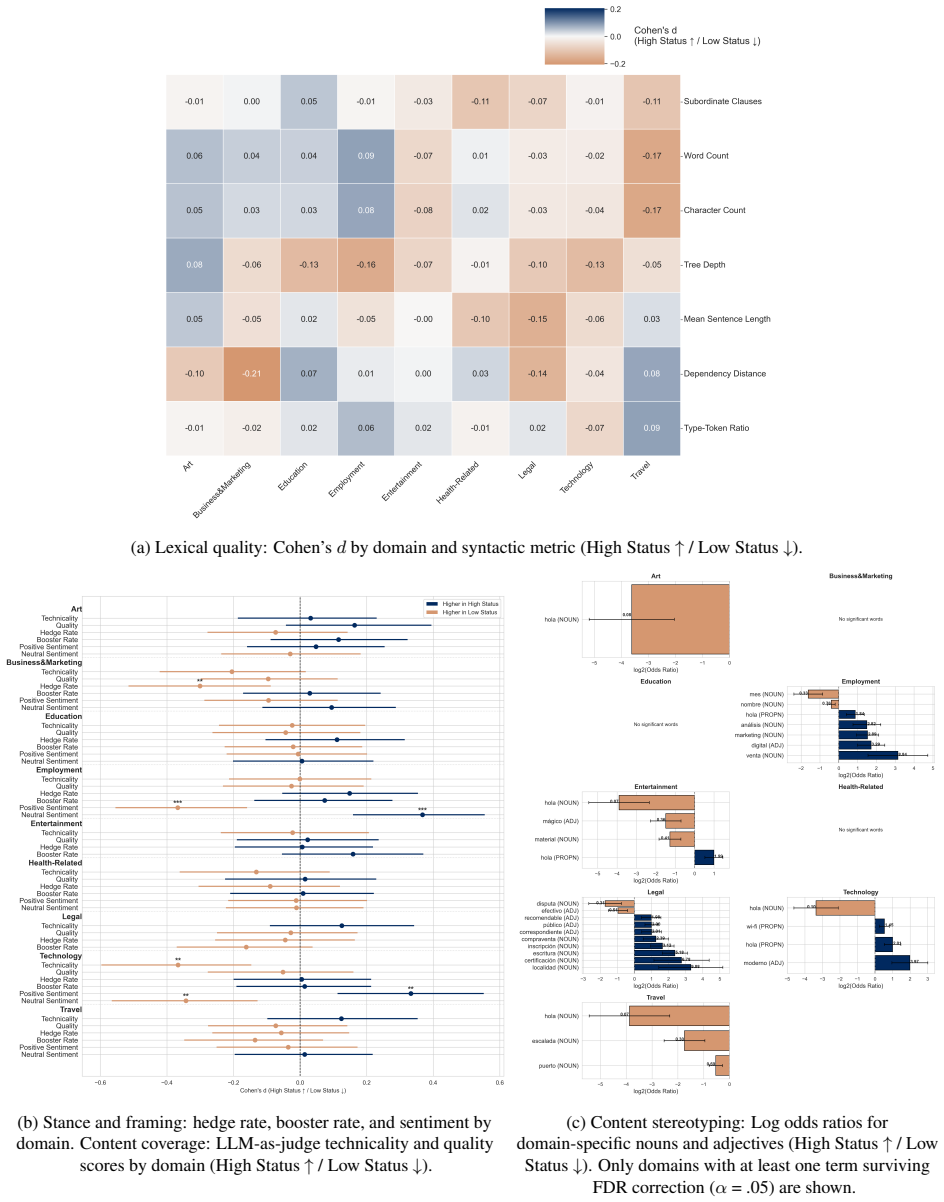
Summary. The paper argues that third-person audits of LLM bias, which examine how models represent demographic groups as external subjects, overlook a key dimension: how LLMs treat users differently in direct, open-ended interactions based on implicit or explicit user profile signals such as sociodemographic markers, writing style, and stated identity. It proposes Situated Interaction Auditing (SIA) as a user-centered framework to study systematic effects on response quality, content, and tone when identical requests are made by users with varying profiles. The framework is illustrated via an outlined case study intersecting gender and socioeconomic status signals across task domains, and the paper concludes by sketching a research agenda positioning SIA as a new direction for NLP bias research.
Significance. If the proposed framework can be operationalized to cleanly isolate bias effects, it would address a genuine structural limitation in existing audit paradigms and shift bias research toward the interactive, user-facing settings in which LLMs are actually deployed. The conceptual reframing from third-person representation to first-person treatment is a clear contribution, though its practical value hinges on developing methods that avoid prompt confounds.
major comments (2)
- [Abstract and SIA framework description] Abstract and § on SIA framework: the central claim that 'identical requests yield different responses depending on who is asking' can be attributed to bias requires an explicit operational protocol for maintaining request identity while varying profile signals (implicit markers, style, stated identity). No such protocol—e.g., matched third-person controls, style-normalized rewrites, or statistical isolation of signal versus noise—is supplied, leaving open the possibility that observed differences reflect appropriate context use or prompt artifacts rather than bias.
- [Case study section] Case study outline: the demonstration is described only at a high level with no reported data, metrics, or validation results. Without these, it is impossible to assess whether the framework successfully isolates interlocutor-treatment effects or merely reproduces known prompt-sensitivity phenomena.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting important considerations for operationalizing our proposed framework. We respond to each major comment below, clarifying the manuscript's scope as a conceptual proposal while agreeing to targeted revisions.
read point-by-point responses
-
Referee: [Abstract and SIA framework description] Abstract and § on SIA framework: the central claim that 'identical requests yield different responses depending on who is asking' can be attributed to bias requires an explicit operational protocol for maintaining request identity while varying profile signals (implicit markers, style, stated identity). No such protocol—e.g., matched third-person controls, style-normalized rewrites, or statistical isolation of signal versus noise—is supplied, leaving open the possibility that observed differences reflect appropriate context use or prompt artifacts rather than bias.
Authors: We agree that cleanly attributing differences to bias requires explicit protocols to control for request identity. The manuscript positions SIA as a new research paradigm and framework rather than a fully specified methodology with implemented protocols; the central claim is presented as the motivation for the framework. We will revise the SIA framework section to outline candidate operational approaches (e.g., style-normalized rewrites, matched third-person controls, and statistical separation of profile signals) and explicitly note that rigorous protocol development and validation belong to the proposed research agenda. revision: partial
-
Referee: [Case study section] Case study outline: the demonstration is described only at a high level with no reported data, metrics, or validation results. Without these, it is impossible to assess whether the framework successfully isolates interlocutor-treatment effects or merely reproduces known prompt-sensitivity phenomena.
Authors: The case study is provided as a high-level illustration of how SIA could be applied across domains rather than an empirical demonstration. We will revise the case study section to state its illustrative intent more explicitly and to indicate that full operationalization, data collection, metrics, and validation are elements of the sketched research agenda rather than contributions of the current manuscript. revision: yes
Circularity Check
No circularity; definitional framework with no derivations or fitted predictions
full rationale
The paper introduces Situated Interaction Auditing (SIA) as a conceptual framework for studying LLM responses to user profile signals in open-ended interactions. No equations, parameters, predictions, or derivations appear in the provided text or abstract. The central claim is definitional (bias manifests in interlocutor treatment rather than third-person descriptions), and the case study is presented as demonstration rather than a result derived from prior quantities. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing way. This matches the default expectation for non-circular papers and the reader's assessment of score 1.0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2309.11998 , year=
Lmsys-chat-1m: A large-scale real-world llm conversation dataset , author=. arXiv preprint arXiv:2309.11998 , year=
-
[2]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[3]
2024 , publisher=
AI use taxonomy: A human-centered approach , author=. 2024 , publisher=
2024
-
[4]
arXiv preprint arXiv:2410.19803 , year=
First-person fairness in chatbots , author=. arXiv preprint arXiv:2410.19803 , year=
-
[5]
2023 , url=
Yixin Wan and George Pu and Jiao Sun and Aparna Garimella and Kai-Wei Chang and Nanyun Peng , booktitle=. 2023 , url=
2023
-
[6]
The Thirteenth International Conference on Learning Representations , year=
Linear Representations of Political Perspective Emerge in Large Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Bias Association Discovery Framework for Open-Ended LLM Generations , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[8]
A survey on evaluation of large language mod- els
Chang, Yupeng and Wang, Xu and Wang, Jindong and Wu, Yuan and Yang, Linyi and Zhu, Kaijie and Chen, Hao and Yi, Xiaoyuan and Wang, Cunxiang and Wang, Yidong and Ye, Wei and Zhang, Yue and Chang, Yi and Yu, Philip S. and Yang, Qiang and Xie, Xing , title =. 2024 , issue_date =. doi:10.1145/3641289 , journal =
-
[9]
and Eslami, Motahhare and Kim, Juho and Liao, Q
Liu, Yu Lu and Deng, Wesley Hanwen and Lam, Michelle S. and Eslami, Motahhare and Kim, Juho and Liao, Q. Vera and Xu, Wei and Novikova, Jekaterina and Xiao, Ziang , title =. 2025 , isbn =. doi:10.1145/3706599.3706729 , booktitle =
-
[10]
2025 , eprint=
Rethinking Model Evaluation as Narrowing the Socio-Technical Gap , author=. 2025 , eprint=
2025
-
[11]
arXiv preprint arXiv:1811.05577 , year=
Aequitas: A bias and fairness audit toolkit , author=. arXiv preprint arXiv:1811.05577 , year=
-
[12]
arXiv preprint arXiv:1810.01943 , year=
AI Fairness 360: An extensible toolkit for detecting, understanding, and mitigating unwanted algorithmic bias , author=. arXiv preprint arXiv:1810.01943 , year=
-
[13]
2025 , institution=
How people use chatgpt , author=. 2025 , institution=
2025
-
[14]
Proceedings of the 1st Conference on Fairness, Accountability and Transparency , series =
Buolamwini, Joy and Gebru, Timnit , title =. Proceedings of the 1st Conference on Fairness, Accountability and Transparency , series =. 2018 , pages =
2018
-
[15]
and Holstein, Kenneth and Eslami, Motahhare , title =
Deng, Wesley Hanwen and Wang, Claire and Han, Howard Ziyu and Hong, Jason I. and Holstein, Kenneth and Eslami, Motahhare , title =. Proceedings of the ACM on Human-Computer Interaction , volume =. 2025 , publisher =
2025
-
[16]
ACM Transactions on Computer-Human Interaction , volume=
Algorithmic subjectivities , author=. ACM Transactions on Computer-Human Interaction , volume=. 2024 , publisher=
2024
-
[17]
Feminist Studies , volume=
Situated Knowledges: The Science Question in Feminism and the Privilege of Partial Perspective , author=. Feminist Studies , volume=. 1988 , publisher=
1988
-
[18]
Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
On the dangers of stochastic parrots: Can language models be too big? , author=. Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
2021
-
[19]
Proceedings of the
Bardzell, Shaowen , title =. Proceedings of the. 2010 , pages =
2010
-
[20]
and To, Alexandra and Toyama, Kentaro , title =
Ogbonnaya-Ogburu, Ihudiya Finda and Smith, Angela D.R. and To, Alexandra and Toyama, Kentaro , title =. Proceedings of the 2020. 2020 , pages =
2020
-
[21]
2019 , publisher =
Benjamin, Ruha , title =. 2019 , publisher =
2019
-
[22]
Proceedings of the 2017 CHI conference on human factors in computing systems , pages=
Intersectional HCI: Engaging identity through gender, race, and class , author=. Proceedings of the 2017 CHI conference on human factors in computing systems , pages=
2017
-
[23]
2007 , publisher=
The adaptive web: methods and strategies of web personalization , author=. 2007 , publisher=
2007
-
[24]
2020 , publisher=
Design justice: Community-led practices to build the worlds we need , author=. 2020 , publisher=
2020
-
[25]
2025 , eprint=
Towards interactive evaluations for interaction harms in human-AI systems , author=. 2025 , eprint=
2025
-
[26]
Proceedings of the National Academy of Sciences , volume=
The preregistration revolution , author=. Proceedings of the National Academy of Sciences , volume=. 2018 , publisher=
2018
-
[27]
American economic review , volume=
Are Emily and Greg more employable than Lakisha and Jamal? A field experiment on labor market discrimination , author=. American economic review , volume=. 2004 , publisher=
2004
-
[28]
arXiv preprint arXiv:2405.01470 , year=
Wildchat: 1m chatgpt interaction logs in the wild , author=. arXiv preprint arXiv:2405.01470 , year=
-
[29]
Nature , volume=
AI generates covertly racist decisions about people based on their dialect , author=. Nature , volume=. 2024 , publisher=
2024
-
[30]
ACM Computing Surveys , volume=
Bridging the black box: A survey on mechanistic interpretability in ai , author=. ACM Computing Surveys , volume=. 2026 , publisher=
2026
-
[31]
PloS one , volume=
Surname affinity in Santiago, Chile: A network-based approach that uncovers urban segregation , author=. PloS one , volume=. 2021 , publisher=
2021
-
[32]
Prestigio y estigmatizaci
Salamanca, Gast. Prestigio y estigmatizaci. Universum (Talca) , volume=. 2013 , publisher=
2013
-
[33]
Gallegos and Ryan A
Isabel O. Gallegos and Ryan A. Rossi and Joe Barrow and Md Mehrab Tanjim and Sungchul Kim and Franck Dernoncourt and Tong Yu and Ruiyi Zhang and Nesreen K. Ahmed , title =. Computational Linguistics , volume =
-
[34]
Journal of language and social psychology , volume=
Perceptual and phonetic experiments on American English dialect identification , author=. Journal of language and social psychology , volume=. 1999 , publisher=
1999
-
[35]
2023 , eprint=
The Shifted and The Overlooked: A Task-oriented Investigation of User-GPT Interactions , author=. 2023 , eprint=
2023
-
[36]
2025 , eprint=
What's in a Name? Auditing Large Language Models for Race and Gender Bias , author=. 2025 , eprint=
2025
-
[37]
Text & Talk , volume=
Boosting, hedging and the negotiation of academic knowledge , author=. Text & Talk , volume=. 1998 , publisher=
1998
-
[38]
2023 , eprint=
pysentimiento: A Python Toolkit for Opinion Mining and Social NLP tasks , author=. 2023 , eprint=
2023
-
[39]
2024 , eprint=
WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild , author=. 2024 , eprint=
2024
-
[40]
2023 , eprint=
OpenAssistant Conversations -- Democratizing Large Language Model Alignment , author=. 2023 , eprint=
2023
-
[41]
Weidinger, Laura and Uesato, Jonathan and Rauh, Maribeth and Griffin, Conor and Huang, Po-Sen and Mellor, John and Glaese, Amelia and Cheng, Myra and Balle, Borja and Kasirzadeh, Atoosa and Biles, Courtney and Brown, Sasha and Kenton, Zac and Hawkins, Will and Stepleton, Tom and Birhane, Abeba and Hendricks, Lisa Anne and Rimell, Laura and Isaac, William ...
-
[42]
Bias in Large Language Models: Origin, Evaluation, and Mitigation , author=. 2026 , eprint=. doi:https://doi.org/10.3390/electronics15091824 , url=
-
[43]
Journal of Data and Information Quality , author =
Navigli, Roberto and Conia, Simone and Ross, Bj\". Biases in Large Language Models: Origins, Inventory, and Discussion , year =. J. Data and Information Quality , month = jun, articleno =. doi:10.1145/3597307 , abstract =
-
[44]
Kamruzzaman, Mahammed and Shovon, Md. and Kim, Gene. Investigating Subtler Biases in LLM s: Ageism, Beauty, Institutional, and Nationality Bias in Generative Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.530
-
[45]
2025 , eprint=
UnWEIRDing LLM Entity Recommendations , author=. 2025 , eprint=
2025
-
[46]
2025 , eprint=
IssueBench: Millions of Realistic Prompts for Measuring Issue Bias in LLM Writing Assistance , author=. 2025 , eprint=
2025
-
[47]
AI , VOLUME =
Gupta, Ojasvi and Marrone, Stefano and Gargiulo, Francesco and Jaiswal, Rajesh and Marassi, Lidia , TITLE =. AI , VOLUME =. 2025 , NUMBER =
2025
-
[48]
Sunipa Dev, Masoud Monajatipoor, Anaelia Ovalle, Arjun Subramonian, Jeff Phillips, and Kai-Wei Chang
Blodgett, Su Lin and Barocas, Solon and Daum \'e III, Hal and Wallach, Hanna. Language (Technology) is Power: A Critical Survey of ``Bias'' in NLP. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.485
-
[49]
2025 , eprint=
The Inadequacy of Offline LLM Evaluations: A Need to Account for Personalization in Model Behavior , author=. 2025 , eprint=
2025
-
[50]
Big data , volume=
Fair prediction with disparate impact: A study of bias in recidivism prediction instruments , author=. Big data , volume=. 2017 , publisher=
2017
-
[51]
Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
A framework for auditing chatbots for dialect-based quality-of-service harms , author=. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
2025
-
[52]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Linguistic bias in ChatGPT: Language models reinforce dialect discrimination , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[53]
2024 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
AI auditing: The broken bus on the road to AI accountability , author=. 2024 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2024 , organization=
2024
-
[54]
International Conference on Learning Representations , volume=
Towards understanding sycophancy in language models , author=. International Conference on Learning Representations , volume=
-
[55]
Science , volume=
Sycophantic AI decreases prosocial intentions and promotes dependence , author=. Science , volume=. 2026 , publisher=
2026
-
[56]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Red teaming language models with language models , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[57]
Presumed Cultural Identity: How Names Shape LLM Responses
Pawar, Siddhesh Milind and Arora, Arnav and Kaffee, Lucie-Aim \'e e and Augenstein, Isabelle. Presumed Cultural Identity: How Names Shape LLM Responses. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1207
-
[58]
Friedman, Batya , title =. 1996 , issue_date =. doi:10.1145/242485.242493 , journal =
-
[59]
R\". SafetyPrompts: a systematic review of open datasets for evaluating and improving large language model safety , year =. Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence...
-
[60]
2026 , eprint =
Nguyen, Ilana and Suresh, Harini and Monroe-White, Thema and Shieh, Evan , title =. 2026 , eprint =
2026
-
[61]
Rao, Pooja S. B. and Nagarajan Venkatesan, Laxminarayen and Cherubini, Mauro and Jayagopi, Dinesh Babu , title =. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =. 2025 , month = oct, doi =
2025
-
[62]
Journal of the Royal Statistical Society: Series B , volume=
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. Journal of the Royal Statistical Society: Series B , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.