Using Explainability as a Training-Time Reliability Signal for Efficient ECG Classification
Pith reviewed 2026-06-27 10:12 UTC · model grok-4.3
The pith
Explanation quality from Grad-CAM can serve as a training signal to select reliable samples and reduce costs in ECG classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
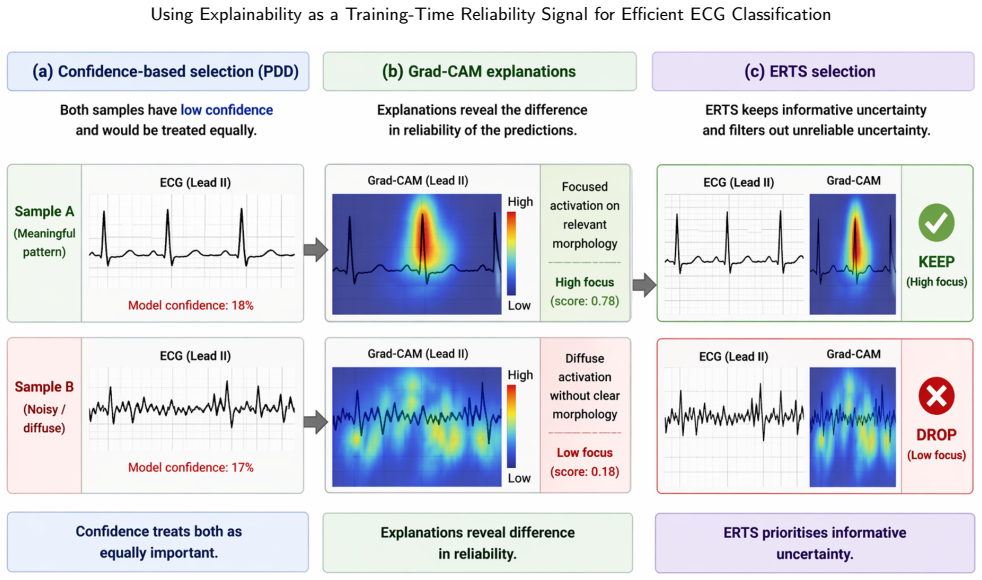
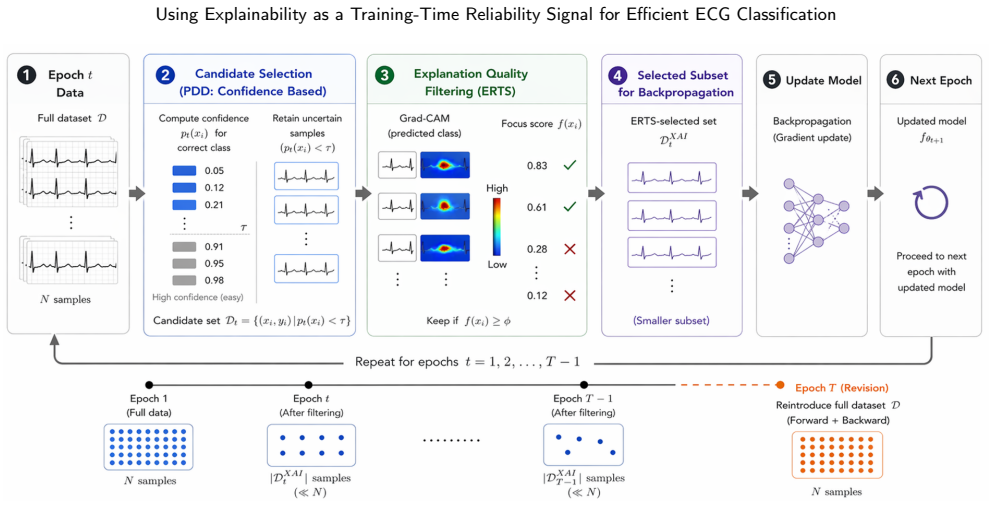
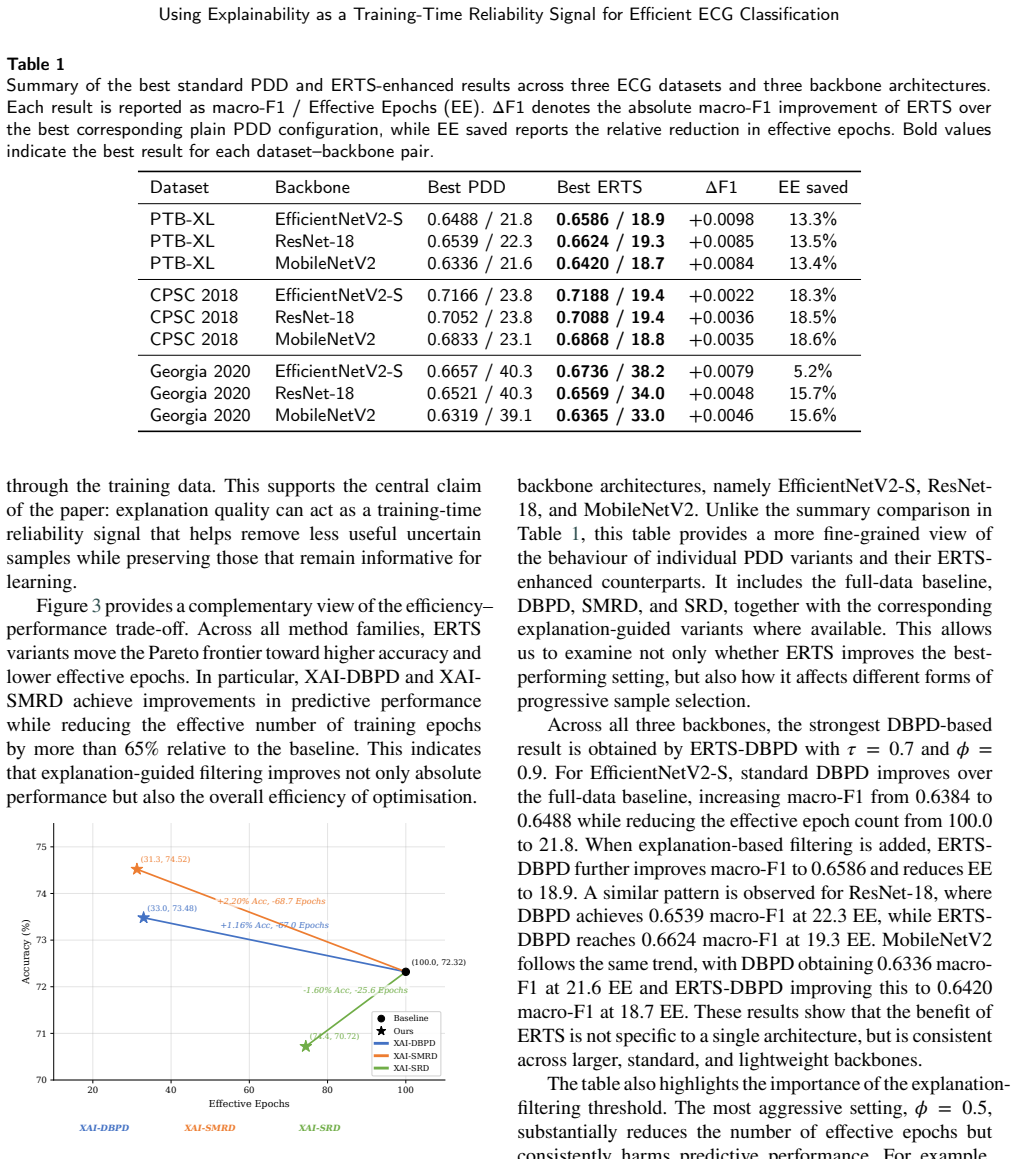
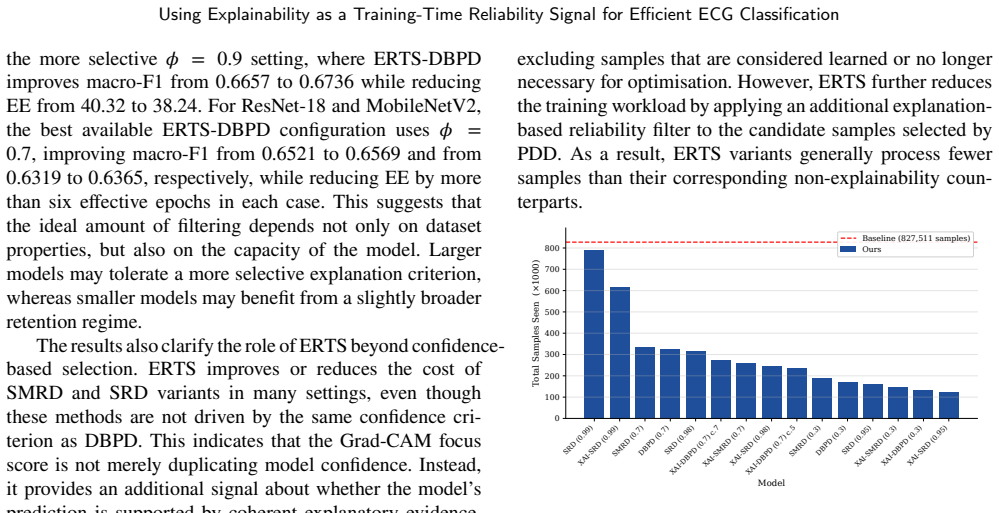
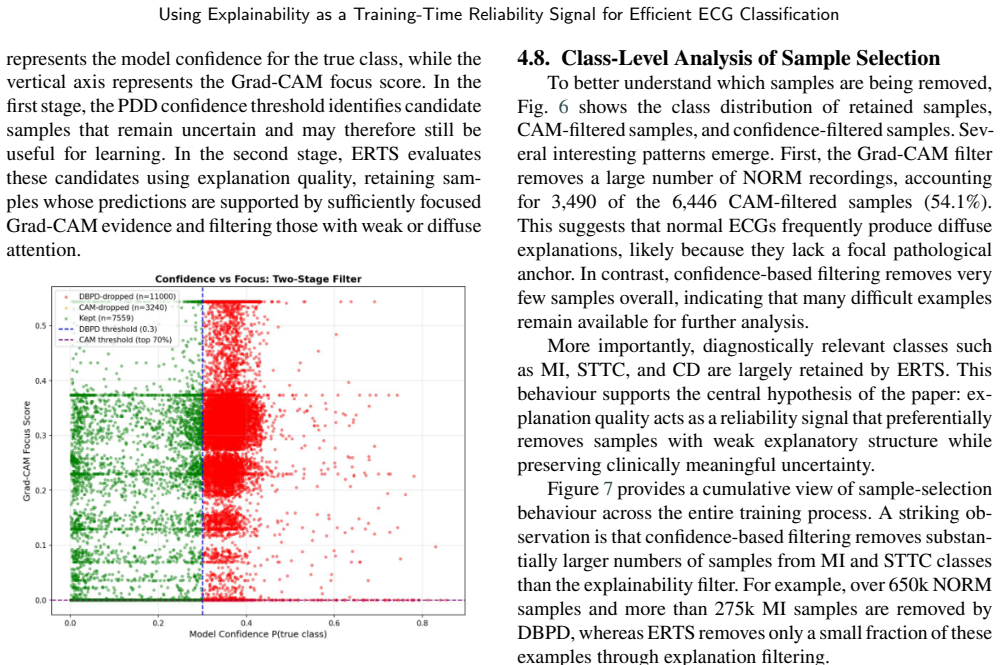
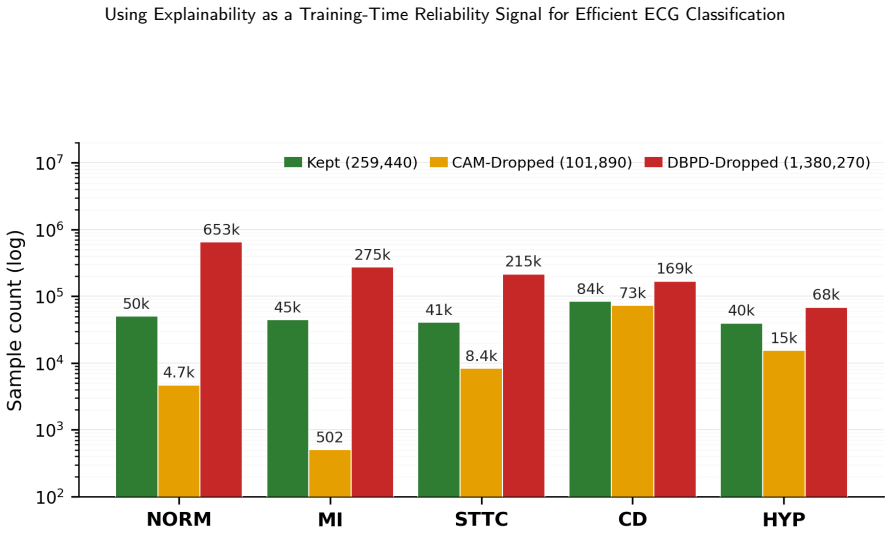
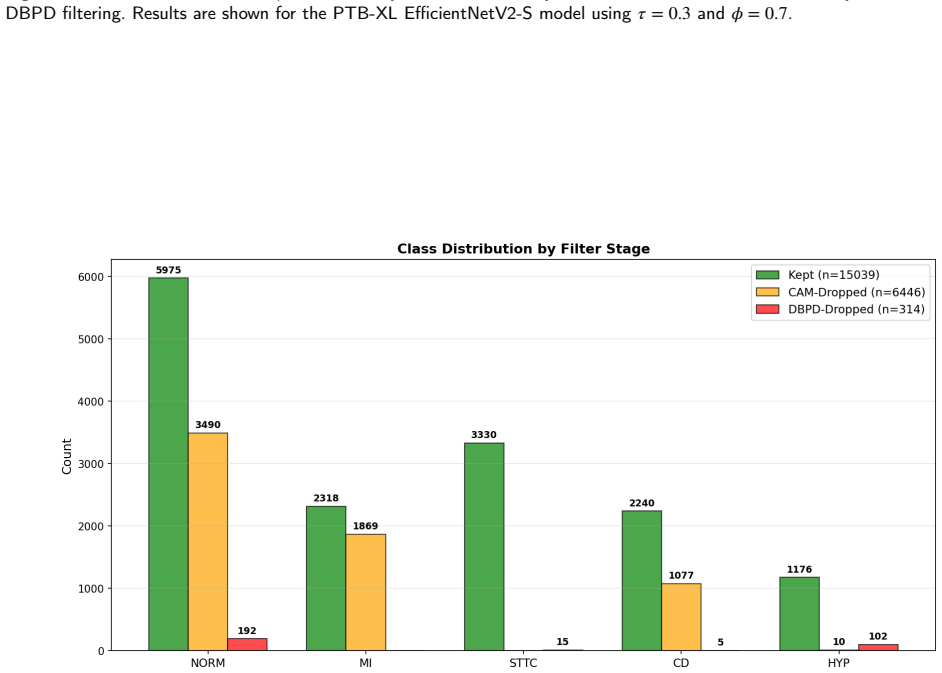
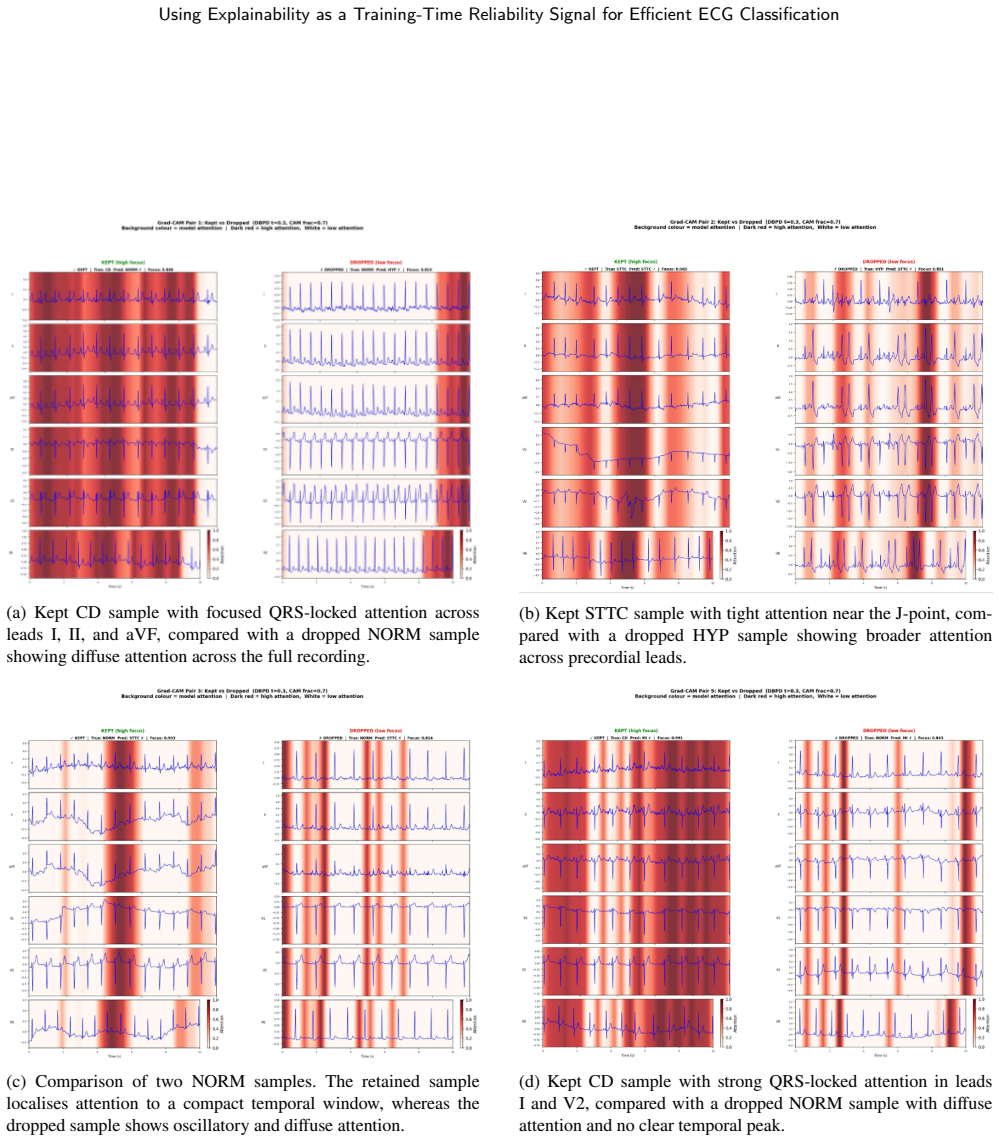
ERTS computes a focus score from Grad-CAM attention maps on candidate samples and uses that score to filter samples for gradient updates, retaining only those with coherent and localised attention while excluding low-focus examples. This replaces the confidence-based criterion in progressive data dropout so that samples difficult due to noise are removed earlier. The method produces higher macro-F1 scores with reduced training cost across three ECG datasets and multiple backbone architectures.
What carries the argument
The focus score derived from Grad-CAM attention maps, which measures whether a prediction rests on coherent and localised patterns to decide whether a sample continues to receive gradient updates.
If this is right
- Higher macro-F1 scores are obtained while the number of samples receiving full gradient updates is reduced.
- The method distinguishes unreliable uncertainty from informative uncertainty more effectively than confidence alone.
- Performance gains hold across three different ECG datasets and several backbone architectures.
- The approach can be layered on existing progressive data selection pipelines without changing the underlying loss or architecture.
Where Pith is reading between the lines
- The same focus score could be reused at inference time to flag individual predictions whose explanations are diffuse.
- The technique may transfer to other clinical time-series problems where attention maps can be computed and where noise is common.
- Combining the explanation-based filter with confidence or loss-based criteria could produce a hybrid selection rule that further reduces training cost.
Load-bearing premise
The focus score from Grad-CAM attention maps reliably separates samples that are difficult because of noise or ambiguity from those that are difficult because the model itself is making errors on informative data.
What would settle it
Training the same architectures on the same ECG datasets with ERTS and with standard progressive dropout, then finding that the ERTS version shows lower macro-F1 or higher effective cost, would indicate the focus score does not provide the claimed advantage.
Figures
read the original abstract
Training deep neural networks for clinical time-series analysis is computationally demanding, yet many healthcare settings lack the resources required for repeated model development and deployment. This challenge is particularly evident in electrocardiogram classification, where large datasets and long training schedules make efficiency practically important. Progressive Data Dropout reduces training cost by excluding samples from gradient updates once they are learned, but it relies on model confidence and may retain samples that are difficult due to noise or ambiguity rather than useful signal. In this work, we introduce ERTS, an explainability-based reliability training signal for efficient ECG classification. ERTS uses explanation quality during training to distinguish between informative and unreliable uncertainty. Building on progressive data selection, we compute Grad-CAM attention maps for candidate samples and derive a focus score that measures whether model predictions are supported by coherent and localised patterns. Samples with low focus are filtered out, while those with meaningful attention are prioritised for gradient updates. We evaluate ERTS across three ECG datasets and multiple backbone architectures, showing consistent improvements in macro-F1 alongside reduced effective training cost. These results suggest that explanation quality can serve as a practical signal for improving both efficiency and reliability in clinical time-series learning. Code will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ERTS, an explainability-based reliability training signal for efficient ECG classification. Building on progressive data selection, it computes Grad-CAM attention maps during training to derive a focus score measuring coherent and localised patterns in model predictions. Low-focus samples are filtered from gradient updates while high-focus samples are prioritised, with the goal of distinguishing informative uncertainty from noise or ambiguity. The method is evaluated on three ECG datasets across multiple backbone architectures, reporting consistent macro-F1 improvements alongside reduced effective training cost.
Significance. If the results hold and the focus-score assumption is validated, the work would demonstrate a practical use of explanation quality as a training-time signal to improve both efficiency and reliability in clinical time-series tasks. This is relevant for resource-limited healthcare settings where repeated full-dataset training is costly. The planned code release would aid reproducibility.
major comments (1)
- [Abstract] Abstract (paragraph describing ERTS): the central claim requires that the focus score derived from Grad-CAM reliably identifies samples difficult due to noise/ambiguity rather than model error. No explicit validation (e.g., correlation with expert-labeled noise, comparison to oracle difficulty, or ablation on class-imbalance effects) is described; this assumption is load-bearing because the progressive training loop uses the score to decide which samples receive gradient updates. If low-focus samples instead reflect early-training instability or imbalance, filtering removes useful signal and the reported efficiency/reliability gains become illusory.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify the assumptions underlying ERTS. The major comment concerns the lack of explicit validation for the focus score. We address this point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing ERTS): the central claim requires that the focus score derived from Grad-CAM reliably identifies samples difficult due to noise/ambiguity rather than model error. No explicit validation (e.g., correlation with expert-labeled noise, comparison to oracle difficulty, or ablation on class-imbalance effects) is described; this assumption is load-bearing because the progressive training loop uses the score to decide which samples receive gradient updates. If low-focus samples instead reflect early-training instability or imbalance, filtering removes useful signal and the reported efficiency/reliability gains become illusory.
Authors: We agree that direct validation of the focus score would strengthen the central claim. The manuscript does not report correlations with expert-labeled noise or oracle difficulty measures, as these annotations are unavailable in the public ECG datasets used. However, the consistent macro-F1 improvements and reduced training cost across three datasets and multiple architectures provide empirical support that the focus score prioritizes samples with coherent attention patterns. To mitigate concerns about class imbalance and early-training instability, we will add ablations in the revised manuscript that track focus-score distributions over epochs and stratified by class frequency. These analyses will help confirm that low-focus filtering does not primarily remove useful signal due to imbalance or instability. revision: partial
- Direct correlation analysis against expert-labeled noise annotations, which are not present in the evaluated public datasets.
Circularity Check
No significant circularity; derivation uses external Grad-CAM without self-referential reduction
full rationale
The paper defines ERTS by applying standard Grad-CAM (cited from prior external literature) to compute a focus score on attention maps, then uses that score to filter samples during progressive data selection. No equations appear that equate the focus score or selection outcome to fitted parameters by construction. The method does not rename known results, smuggle ansatzes via self-citation, or invoke uniqueness theorems from the authors' prior work. The central claim rests on an empirical assumption about what the focus score measures, but that assumption is not forced by definition or self-reference; the derivation chain remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arazo, E., Ortego, D., Albert, P., O’Connor, N., McGuinness, K.,
-
[2]
Unsupervised label noise modeling and loss correction, in: International conference on machine learning, PMLR. pp. 312–321
-
[3]
An artificial intelligence-enabled ecg algorithm for the identification of patients with atrial fibrillation during sinus rhythm: a retrospective analysis of outcome prediction
Attia, Z.I., Noseworthy, P.A., Lopez-Jimenez, F., Asirvatham, S.J., Deshmukh,A.J.,Gersh,B.J.,Carter,R.E.,Yao,X.,Rabinstein,A.A., Erickson, B.J., et al., 2019. An artificial intelligence-enabled ecg algorithm for the identification of patients with atrial fibrillation during sinus rhythm: a retrospective analysis of outcome prediction. The Lancet 394, 861–867
2019
-
[4]
Bengio,Y.,Louradour,J.,Collobert,R.,Weston,J.,2009.Curriculum learning, in: Proceedings of the 26th annual international conference on machine learning, pp. 41–48
2009
-
[5]
Active label cleaning for improved dataset quality under resource constraints
Bernhardt, M., Castro, D.C., Tanno, R., Schwaighofer, A., Tezcan, K.C.,Monteiro,M.,Bannur,S.,Lungren,M.P.,Nori,A.,Glocker,B., et al., 2022. Active label cleaning for improved dataset quality under resource constraints. Nature communications 13, 1161
2022
-
[6]
Chattopadhay, A., Sarkar, A., Howlader, P., Balasubramanian, V.N.,
-
[7]
Grad-cam++: Generalized gradient-based visual explanations fordeepconvolutionalnetworks,in:2018IEEEwinterconferenceon applications of computer vision (WACV), IEEE. pp. 839–847
-
[8]
Erion, G., Janizek, J.D., Sturmfels, P., Lundberg, S.M., Lee, S.I.,
-
[9]
Nature machine intelligence 3, 620–631
Improving performance of deep learning models with ax- iomatic attribution priors and expected gradients. Nature machine intelligence 3, 620–631
-
[10]
Adaptive data dropout: Towards self-regulated learning in deep neural networks
Gahir, A., Patel, V., Gowda, S.N., 2026. Adaptive data dropout: Towards self-regulated learning in deep neural networks. arXiv preprint arXiv:2604.12945
Pith/arXiv arXiv 2026
-
[11]
Synthetic sample selection for generalized zero-shot learning, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp
Gowda, S.N., 2023. Synthetic sample selection for generalized zero-shot learning, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 58–67
2023
-
[12]
Gowda, S.N., Hao, X., Li, G., Gowda, S.N., Jin, X., Sevilla-Lara, L.,
-
[13]
Wattforwhat:Rethinkingdeeplearning’senergy-performance relationship,in:EuropeanConferenceonComputerVision,Springer. pp. 388–405
-
[14]
Cardiac health assessment across scenarios and devices using a multimodal foundation model pretrained on data from 1.7 million individuals
Gu, X., Tang, W., Han, J., Sangha, V., Liu, F., Gowda, S.N., Ribeiro, A.H., Schwab, P., Branson, K., Clifton, L., et al., 2026. Cardiac health assessment across scenarios and devices using a multimodal foundation model pretrained on data from 1.7 million individuals. Nature Machine Intelligence 8, 220–233
2026
-
[15]
Deepcompression:Compressing deepneuralnetworkswithpruning,trainedquantizationandhuffman coding
Han,S.,Mao,H.,Dally,W.J.,2015. Deepcompression:Compressing deepneuralnetworkswithpruning,trainedquantizationandhuffman coding. arXiv preprint arXiv:1510.00149
Pith/arXiv arXiv 2015
-
[16]
Cardiologist-level arrhythmia detectionandclassificationinambulatoryelectrocardiogramsusinga deep neural network
Hannun, A.Y., Rajpurkar, P., Haghpanahi, M., Tison, G.H., Bourn, C., Turakhia, M.P., Ng, A.Y., 2019. Cardiologist-level arrhythmia detectionandclassificationinambulatoryelectrocardiogramsusinga deep neural network. Nature medicine 25, 65–69
2019
-
[17]
Distillingtheknowledgeina neural network
Hinton,G.,Vinyals,O.,Dean,J.,2015. Distillingtheknowledgeina neural network. arXiv preprint arXiv:1503.02531
Pith/arXiv arXiv 2015
-
[18]
Quantization and training of neural networks for efficient integer-arithmetic-only inference, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp
Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., Kalenichenko, D., 2018. Quantization and training of neural networks for efficient integer-arithmetic-only inference, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2704–2713
2018
-
[19]
Explainable detection of myocardial infarction using deep learning models with grad-cam technique on ecg signals
Jahmunah, V., Ng, E.Y., Tan, R.S., Oh, S.L., Acharya, U.R., 2022. Explainable detection of myocardial infarction using deep learning models with grad-cam technique on ecg signals. Computers in Biology and Medicine 146, 105550
2022
-
[20]
Improving medical images classification with label noise using dual-uncertainty estimation
Ju, L., Wang, X., Wang, L., Mahapatra, D., Zhao, X., Zhou, Q., Liu, T., Ge, Z., 2022. Improving medical images classification with label noise using dual-uncertainty estimation. IEEE transactions on medical imaging 41, 1533–1546
2022
-
[21]
Not all samples are created equal: Deep learning with importance sampling, in: International conference on machine learning, PMLR
Katharopoulos, A., Fleuret, F., 2018. Not all samples are created equal: Deep learning with importance sampling, in: International conference on machine learning, PMLR. pp. 2525–2534
2018
-
[22]
Arrhythmia detection model using modified densenet for comprehensible grad-cam visual- ization
Kim, J.K., Jung, S., Park, J., Han, S.W., 2022. Arrhythmia detection model using modified densenet for comprehensible grad-cam visual- ization. Biomedical Signal Processing and Control 73, 103408
2022
-
[23]
A unified approach to interpreting model predictions
Lundberg, S.M., Lee, S.I., 2017. A unified approach to interpreting model predictions. Advances in neural information processing sys- tems 30
2017
-
[24]
Methodsforinterpret- ingandunderstandingdeepneuralnetworks.Digitalsignalprocessing 73, 1–15
Montavon,G.,Samek,W.,Müller,K.R.,2018. Methodsforinterpret- ingandunderstandingdeepneuralnetworks.Digitalsignalprocessing 73, 1–15
2018
-
[25]
Confident learning: Esti- matinguncertaintyindatasetlabels
Northcutt, C., Jiang, L., Chuang, I., 2021. Confident learning: Esti- matinguncertaintyindatasetlabels. JournalofArtificialIntelligence Research 70, 1373–1411
2021
-
[26]
Exploring interpretable ai methods for ecg data classification, in: Proceedings of the 5th ACM Workshop on Intelligent Cross-Data Analysis and Retrieval, pp
Ojha, J., Haugerud, H., Yazidi, A., Lind, P.G., 2024. Exploring interpretable ai methods for ecg data classification, in: Proceedings of the 5th ACM Workshop on Intelligent Cross-Data Analysis and Retrieval, pp. 11–18
2024
-
[27]
Carbon emissions andlargeneuralnetworktraining
Patterson, D., Gonzalez, J., Le, Q., Liang, C., Munguia, L.M., Rothchild, D., So, D., Texier, M., Dean, J., 2021. Carbon emissions andlargeneuralnetworktraining. arXivpreprintarXiv:2104.10350
Pith/arXiv arXiv 2021
-
[28]
Deeplearningonadata diet:Findingimportantexamplesearlyintraining.Advancesinneural information processing systems 34, 20596–20607
Paul,M.,Ganguli,S.,Dziugaite,G.K.,2021. Deeplearningonadata diet:Findingimportantexamplesearlyintraining.Advancesinneural information processing systems 34, 20596–20607
2021
-
[29]
Rajpurkar, P., Hannun, A.Y., Haghpanahi, M., Bourn, C., Ng, A.Y.,
-
[30]
arXiv preprint arXiv:1707.01836
Cardiologist-level arrhythmia detection with convolutional neural networks. arXiv preprint arXiv:1707.01836
-
[31]
Training deep neural networks on noisy labels with bootstrapping
Reed, S., Lee, H., Anguelov, D., Szegedy, C., Erhan, D., Rabinovich, A., 2014. Training deep neural networks on noisy labels with bootstrapping. arXiv preprint arXiv:1412.6596
Pith/arXiv arXiv 2014
-
[32]
Classification of 12-leadecgs:Thephysionet/computingincardiologychallenge2020, in: 2020 Computing in Cardiology, IEEE
Reyna, M.A., Alday, E.A.P., Gu, A., Liu, C., Seyedi, S., Rad, A.B., Elola, A., Li, Q., Sharma, A., Clifford, G.D., 2020. Classification of 12-leadecgs:Thephysionet/computingincardiologychallenge2020, in: 2020 Computing in Cardiology, IEEE. pp. 1–4. V. K. Dangeti, S. N. Gowda:Preprint submitted to ElsevierPage 15 of 16 Using Explainability as a Training-Ti...
2020
-
[33]
Right for the right reasons: Training differentiable models by constraining their explanations
Ross, A.S., Hughes, M.C., Doshi-Velez, F., 2017. Right for the right reasons: Training differentiable models by constraining their explanations. arXiv preprint arXiv:1703.03717
Pith/arXiv arXiv 2017
-
[34]
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.,
-
[35]
4510–4520
Mobilenetv2: Inverted residuals and linear bottlenecks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4510–4520
-
[36]
Making deep neuralnetworks right forthe right scientificreasons by interact- ingwiththeirexplanations
Schramowski, P., Stammer, W., Teso, S., Brugger, A., Herbert, F., Shao, X., Luigs, H.G., Mahlein, A.K., Kersting, K., 2020. Making deep neuralnetworks right forthe right scientificreasons by interact- ingwiththeirexplanations. NatureMachineIntelligence2,476–486
2020
-
[37]
Green ai
Schwartz, R., Dodge, J., Smith, N.A., Etzioni, O., 2020. Green ai. Communications of the ACM 63, 54–63
2020
-
[38]
Grad-cam:Visualexplanationsfromdeepnetworksvia gradient-basedlocalization,in:ProceedingsoftheIEEEinternational conference on computer vision, pp
Selvaraju,R.R.,Cogswell,M.,Das,A.,Vedantam,R.,Parikh,D.,Ba- tra,D.,2017. Grad-cam:Visualexplanationsfromdeepnetworksvia gradient-basedlocalization,in:ProceedingsoftheIEEEinternational conference on computer vision, pp. 618–626
2017
-
[39]
Progressive data dropout: An embarrassingly simple approach to train faster, in: The Thirty-ninth Annual Conference on Neural Information Processing Systems
Shriram, M., Hao, X., Hou, S., Lu, Y., Sevilla-Lara, L., Arnab, A., Gowda, S.N., . Progressive data dropout: An embarrassingly simple approach to train faster, in: The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[40]
Trainingregion-based object detectors with online hard example mining, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp
Shrivastava,A.,Gupta,A.,Girshick,R.,2016. Trainingregion-based object detectors with online hard example mining, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 761–769
2016
-
[41]
Smoothgrad: removing noise by adding noise
Smilkov, D., Thorat, N., Kim, B., Viégas, F., Wattenberg, M., 2017. Smoothgrad: removing noise by adding noise. arXiv preprint arXiv:1706.03825
Pith/arXiv arXiv 2017
-
[42]
Attention- based 3d cnn with residual connections for efficient ecg-based covid- 19 detection
Sobahi, N., Sengur, A., Tan, R.S., Acharya, U.R., 2022. Attention- based 3d cnn with residual connections for efficient ecg-based covid- 19 detection. Computers in Biology and Medicine 143, 105335
2022
-
[43]
Deep learningforecganalysis:Benchmarksandinsightsfromptb-xl
Strodthoff, N., Wagner, P., Schaeffter, T., Samek, W., 2020. Deep learningforecganalysis:Benchmarksandinsightsfromptb-xl. IEEE journal of biomedical and health informatics 25, 1519–1528
2020
-
[44]
Energy and policy considerations for deep learning in nlp, in: Proceedings of the 57th annual meeting of the association for computational linguistics, pp
Strubell, E., Ganesh, A., McCallum, A., 2019. Energy and policy considerations for deep learning in nlp, in: Proceedings of the 57th annual meeting of the association for computational linguistics, pp. 3645–3650
2019
-
[45]
Axiomatic attribution for deep networks, in: International conference on machine learning, PMLR
Sundararajan, M., Taly, A., Yan, Q., 2017. Axiomatic attribution for deep networks, in: International conference on machine learning, PMLR. pp. 3319–3328
2017
-
[46]
Dataset cartography: Mapping and diagnosing datasets with training dynamics, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp
Swayamdipta, S., Schwartz, R., Lourie, N., Wang, Y., Hajishirzi, H., Smith, N.A., Choi, Y., 2020. Dataset cartography: Mapping and diagnosing datasets with training dynamics, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 9275–9293
2020
-
[47]
Efficientnet: Rethinking model scaling for convolutional neural networks, in: International conference on machine learning, PMLR
Tan, M., Le, Q., 2019. Efficientnet: Rethinking model scaling for convolutional neural networks, in: International conference on machine learning, PMLR. pp. 6105–6114
2019
-
[48]
Anempiricalstudyofexampleforgettingduring deep neural network learning
Toneva, M., Sordoni, A., Combes, R.T.d., Trischler, A., Bengio, Y., Gordon,G.J.,2018. Anempiricalstudyofexampleforgettingduring deep neural network learning. arXiv preprint arXiv:1812.05159
arXiv 2018
-
[49]
Ptb-xl, a large publicly available electrocardiography dataset
Wagner,P.,Strodthoff,N.,Bousseljot,R.D.,Kreiseler,D.,Lunze,F.I., Samek, W., Schaeffter, T., 2020. Ptb-xl, a large publicly available electrocardiography dataset. Scientific data 7, 154
2020
-
[50]
Data dropout: Optimizing training data for convolutional neural networks, in: 2018 IEEE 30th interna- tional conference on tools with artificial intelligence (ICTAI), IEEE
Wang, T., Huan, J., Li, B., 2018. Data dropout: Optimizing training data for convolutional neural networks, in: 2018 IEEE 30th interna- tional conference on tools with artificial intelligence (ICTAI), IEEE. pp. 39–46
2018
-
[51]
Learning with noisy labels revisited: A study using real-world human annota- tions
Wei, J., Zhu, Z., Cheng, H., Liu, T., Niu, G., Liu, Y., 2021. Learning with noisy labels revisited: A study using real-world human annota- tions. arXiv preprint arXiv:2110.12088
arXiv 2021
-
[52]
Deep learning with noisy labels in medical prediction problems: a scoping review
Wei, Y., Deng, Y., Sun, C., Lin, M., Jiang, H., Peng, Y., 2024. Deep learning with noisy labels in medical prediction problems: a scoping review. JournaloftheAmericanMedicalInformaticsAssociation31, 1596–1607
2024
-
[53]
When dynamic data selection meets data augmentation: Achieving enhanced training ac- celeration,in:InternationalConferenceonMachineLearning,PMLR
Yang, S., Ye, P., Shen, F., Zhou, D., 2025. When dynamic data selection meets data augmentation: Achieving enhanced training ac- celeration,in:InternationalConferenceonMachineLearning,PMLR. pp. 71508–71520
2025
-
[54]
Instance- dependentearlystopping,in:TheThirteenthInternationalConference on Learning Representations
Yuan, S., Lin, R., Feng, L., Han, B., Liu, T., 2025. Instance- dependentearlystopping,in:TheThirteenthInternationalConference on Learning Representations. V. K. Dangeti, S. N. Gowda:Preprint submitted to ElsevierPage 16 of 16
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.