CCKS: Consensus-based Communication and Knowledge Sharing
Pith reviewed 2026-06-27 07:32 UTC · model grok-4.3
The pith
A consensus model built via contrastive learning on local observations lets agents selectively follow teacher advice in cooperative multi-agent tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
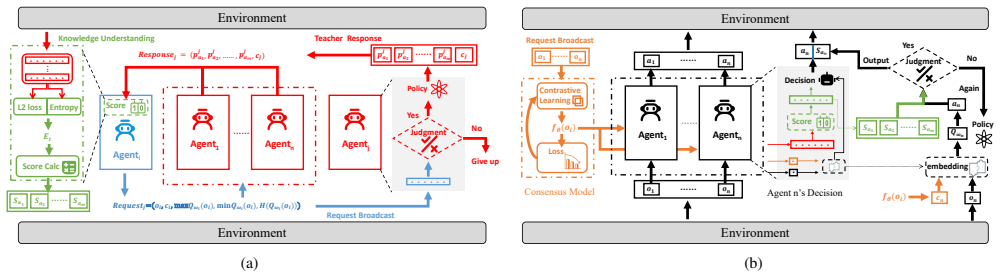
CCKS constructs a consensus model via contrastive learning on local observations during training; in action selection, agents score candidate actions against this model and shared knowledge to decide whether to follow a teacher's recommendation, thereby replacing blind adherence with consensus-constrained choice and producing more stable and effective cooperation.
What carries the argument
Consensus model constructed by contrastive learning on local observations, which agents use to score actions and enforce compatibility constraints on teacher advice.
If this is right
- Agents reduce excessive advising by only accepting recommendations that satisfy the consensus constraint.
- Exploration is preserved while still benefiting from experienced teachers, raising overall task performance.
- The same consensus scoring layer can be attached to any existing DTDE algorithm without altering its core training loop.
- Cooperation efficiency rises because incompatible advice is filtered before it distorts joint policy updates.
Where Pith is reading between the lines
- The same local-observation contrastive construction might be reused to filter advice in other decentralized coordination settings beyond reinforcement learning.
- If the consensus model remains stable across changing team compositions, it could support lifelong multi-agent learning without retraining the compatibility layer from scratch.
- Testing whether the learned consensus generalizes to teacher policies trained on different tasks would clarify the limits of the compatibility measure.
Load-bearing premise
Contrastive learning on local observations during training produces a consensus model that reliably measures teacher-student compatibility and does not introduce new selection biases when used for action scoring.
What would settle it
Adding CCKS to a standard DTDE baseline in the StarCraft II Multi-Agent Challenge produces no measurable rise in win rate or learning-curve slope compared with the unmodified baseline.
Figures

read the original abstract
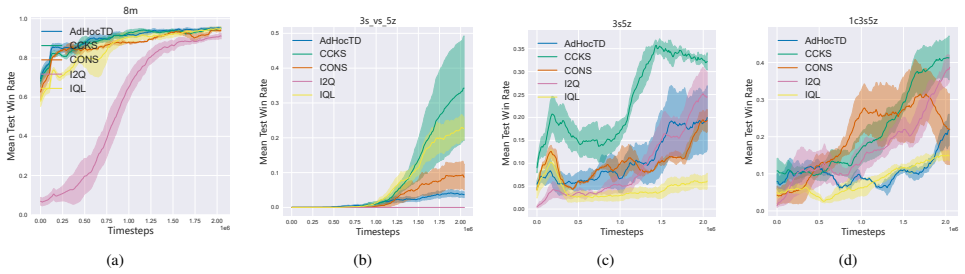
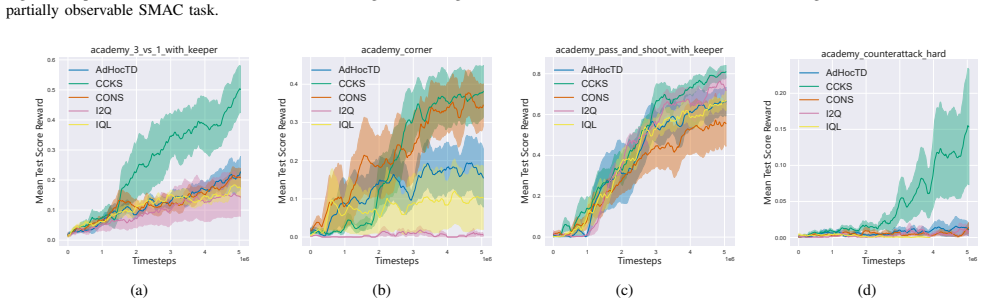
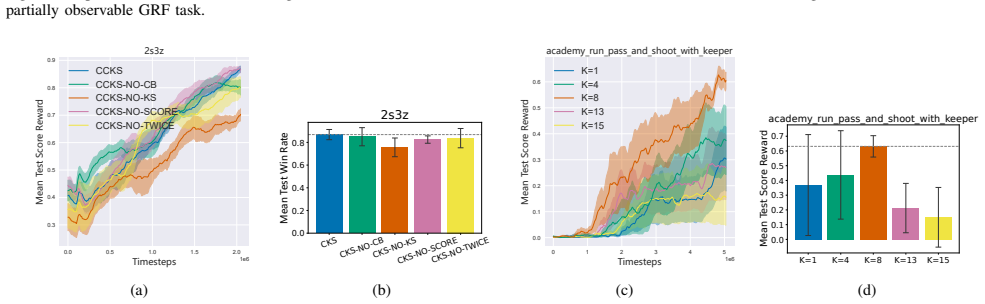
In Decentralized Training and Decentralized Execution (DTDE) for cooperative Multi-Agent Reinforcement Learning (MARL), action-advising-based knowledge sharing promotes interpretable and scalable cooperation among agents. However, current action advising approaches often adhere too much to the teacher's guidance without evaluating teacher-student compatibility, which causes excessive advising, suboptimal stability, and degraded performance. To overcome these challenges, this paper presents a Consensus-based Communication and Knowledge Sharing (CCKS) framework, which allows agents to adopt recommendations based on consensus-derived constraints and to follow the teacher's instructions more smartly. This mechanism enables agents to balance exploration and learning from experienced teachers, improving overall performance. The key is the consensus model construction, for which we propose to employ contrastive learning to construct consensus models based on local observations in the agents' training phase. In action selection, agents score and choose actions based on consensus and shared knowledge. Designed as a plug-and-play solution, CCKS integrates seamlessly with existing DTDE algorithms. Experiments conducted in the Google Research Football environment and the complex StarCraft II Multi-Agent Challenge demonstrate that the integration with CCKS significantly improves cooperation efficiency, learning speed, and overall performance compared with current DTDE baselines. The code is available at https://github.com/yuanxpy/CCKS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Consensus-based Communication and Knowledge Sharing (CCKS) framework as a plug-and-play addition to DTDE MARL algorithms. Agents construct a consensus model via contrastive learning on local observations during training; at action selection, this model is used to score actions and decide whether to follow teacher advice, thereby addressing over-advising and compatibility issues. Experiments in Google Research Football and StarCraft II Multi-Agent Challenge are reported to show gains in cooperation efficiency, learning speed, and overall performance relative to DTDE baselines.
Significance. If the empirical improvements are robust and properly controlled, the plug-and-play design could provide a practical mechanism for more selective knowledge sharing in cooperative MARL. The use of contrastive learning to derive compatibility constraints is a potentially reusable idea for balancing teacher guidance with exploration.
major comments (1)
- Abstract: the central performance claims are stated without any quantitative results, error bars, ablation studies, or description of the precise integration of the consensus model into the action-selection step, preventing evaluation of the reported gains in GRF and SMAC.
Simulated Author's Rebuttal
We thank the referee for their feedback. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the central performance claims are stated without any quantitative results, error bars, ablation studies, or description of the precise integration of the consensus model into the action-selection step, preventing evaluation of the reported gains in GRF and SMAC.
Authors: We agree the abstract would be strengthened by quantitative results and a concise description of the integration. In revision we will add specific metrics (e.g., win-rate or reward improvements with standard errors from the GRF and SMAC tables) and a one-sentence statement of how the consensus model is queried at action selection to score and gate teacher advice. Ablation results remain in the main experimental section; space permitting we will reference the key ablation outcomes in the abstract. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical plug-and-play framework for DTDE MARL that constructs consensus models via contrastive learning on local observations and uses them for action scoring. No derivation chain, first-principles prediction, or fitted quantity is presented that reduces by construction to its own inputs, self-citations, or ansatzes. The central claims rest on experimental performance gains versus baselines in GRF and SMAC, with the method presented as an algorithmic integration rather than a mathematical reduction. This is the most common honest finding for empirical MARL papers without load-bearing self-referential equations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Distributed multi-robot collision avoidance via deep reinforcement learning for navigation in complex scenarios,
T. Fan, P. Long, W. Liu, and J. Pan, “Distributed multi-robot collision avoidance via deep reinforcement learning for navigation in complex scenarios,”The International Journal of Robotics Research, vol. 39, no. 7, pp. 856–892, 2020
2020
-
[2]
An introduction to multi-agent reinforcement learning and review of its application to autonomous mobility,
L. M. Schmidt, J. Brosig, A. Plinge, B. M. Eskofier, and C. Mutschler, “An introduction to multi-agent reinforcement learning and review of its application to autonomous mobility,” in2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2022, pp. 1342–1349
2022
-
[3]
Mastering complex control in moba games with deep reinforcement learning,
D. Ye, Z. Liu, M. Sun, B. Shi, P. Zhao, H. Wu, H. Yu, S. Yang, X. Wu, Q. Guo,et al., “Mastering complex control in moba games with deep reinforcement learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 6672–6679
2020
-
[4]
Decentralized pomdps,
F. A. Oliehoek, “Decentralized pomdps,” inReinforcement learning: state-of-the-art. Springer, 2012, pp. 471–503
2012
-
[5]
Multi-agent actor-critic for mixed cooperative-competitive environments,
R. Lowe, Y . I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environments,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[6]
Monotonic value function factorisation for deep multi- agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi- agent reinforcement learning,”Journal of Machine Learning Research, vol. 21, no. 178, pp. 1–51, 2020
2020
-
[7]
Actor-attention-critic for multi-agent reinforcement learning,
S. Iqbal and F. Sha, “Actor-attention-critic for multi-agent reinforcement learning,” inInternational conference on machine learning. PMLR, 2019, pp. 2961–2970
2019
-
[8]
Pic: permutation invariant critic for multi-agent deep reinforcement learning,
I.-J. Liu, R. A. Yeh, and A. G. Schwing, “Pic: permutation invariant critic for multi-agent deep reinforcement learning,” inConference on Robot Learning. PMLR, 2020, pp. 590–602
2020
-
[9]
Multi-agent reinforcement learning: Independent vs. coopera- tive agents,
M. Tan, “Multi-agent reinforcement learning: Independent vs. coopera- tive agents,” inProceedings of the tenth international conference on machine learning, 1993, pp. 330–337
1993
-
[10]
Multiagent cooperation and competition with deep reinforcement learning,
A. Tampuu, T. Matiisen, D. Kodelja, I. Kuzovkin, K. Korjus, J. Aru, J. Aru, and R. Vicente, “Multiagent cooperation and competition with deep reinforcement learning,”PloS one, vol. 12, no. 4, p. e0172395, 2017
2017
-
[11]
Facmac: Factored multi-agent centralised policy gradients,
B. Peng, T. Rashid, C. Schroeder de Witt, P.-A. Kamienny, P. Torr, W. Böhmer, and S. Whiteson, “Facmac: Factored multi-agent centralised policy gradients,”Advances in Neural Information Processing Systems, vol. 34, pp. 12 208–12 221, 2021
2021
-
[12]
I2q: A fully decentralized q-learning algorithm,
J. Jiang and Z. Lu, “I2q: A fully decentralized q-learning algorithm,” Advances in Neural Information Processing Systems, vol. 35, pp. 20 469– 20 481, 2022
2022
-
[13]
Learning multiagent communication with backpropagation,
S. Sukhbaatar, R. Fergus,et al., “Learning multiagent communication with backpropagation,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[14]
Learning individually inferred communication for multi-agent cooperation,
Z. Ding, T. Huang, and Z. Lu, “Learning individually inferred communication for multi-agent cooperation,”Advances in neural information processing systems, vol. 33, pp. 22 069–22 079, 2020
2020
-
[15]
Communication in multi-agent reinforcement learning: Intention sharing,
W. Kim, J. Park, and Y . Sung, “Communication in multi-agent reinforcement learning: Intention sharing,” inInternational conference on learning representations, 2020
2020
-
[16]
A q-values sharing framework for multi-agent reinforcement learning under budget constraint,
C. Zhu, H.-F. Leung, S. Hu, and Y . Cai, “A q-values sharing framework for multi-agent reinforcement learning under budget constraint,”ACM Transactions on Autonomous and Adaptive Systems (TAAS), vol. 15, no. 2, pp. 1–28, 2021
2021
-
[17]
Explainable action advising for multi-agent reinforcement learning,
Y . Guo, J. Campbell, S. Stepputtis, R. Li, D. Hughes, F. Fang, and K. Sycara, “Explainable action advising for multi-agent reinforcement learning,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 5515–5521
2023
-
[18]
Cautiously-optimistic knowledge sharing for cooperative multi-agent reinforcement learning,
Y . Ba, X. Liu, X. Chen, H. Wang, Y . Xu, K. Li, and S. Zhang, “Cautiously-optimistic knowledge sharing for cooperative multi-agent reinforcement learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 17 299–17 307
2024
-
[19]
Consensus-based partnerships: the heart of effective interprofessional education and collaborative practice,
S. Snyman and J. Rogers, “Consensus-based partnerships: the heart of effective interprofessional education and collaborative practice,” Sustainability and interprofessional collaboration: Ensuring leadership resilience in collaborative health care, pp. 59–82, 2020
2020
-
[20]
M. Samvelyan, T. Rashid, C. S. De Witt, G. Farquhar, N. Nardelli, T. G. Rudner, C.-M. Hung, P. H. Torr, J. Foerster, and S. Whiteson, “The starcraft multi-agent challenge,”arXiv preprint arXiv:1902.04043, 2019
-
[21]
Google research football: A novel reinforcement learning environment,
K. Kurach, A. Raichuk, P. Sta´nczyk, M. Zaj ˛ ac, O. Bachem, L. Espeholt, C. Riquelme, D. Vincent, M. Michalski, O. Bousquet,et al., “Google research football: A novel reinforcement learning environment,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 04, 2020, pp. 4501–4510
2020
-
[22]
Adaptive coordination strategies for human-robot handovers
C.-M. Huang, M. Cakmak, and B. Mutlu, “Adaptive coordination strategies for human-robot handovers.” inRobotics: science and systems, vol. 11. Rome, Italy, 2015, pp. 1–10
2015
-
[23]
Multi-agent framework for third party logistics in e-commerce,
W. Ying and S. Dayong, “Multi-agent framework for third party logistics in e-commerce,”Expert Systems with Applications, vol. 29, no. 2, pp. 431–436, 2005
2005
-
[24]
Simultaneously learning and advising in multiagent reinforcement learning,
F. L. Da Silva, R. Glatt, and A. H. R. Costa, “Simultaneously learning and advising in multiagent reinforcement learning,” inProceedings of the 16th conference on autonomous agents and multiagent systems, 2017, pp. 1100–1108
2017
-
[25]
Learning hierarchical teaching policies for cooperative agents,
D.-K. Kim, M. Liu, S. Omidshafiei, S. Lopez-Cot, M. Riemer, G. Habibi, G. Tesauro, S. Mourad, M. Campbell, and J. P. How, “Learning hierarchical teaching policies for cooperative agents,”arXiv preprint arXiv:1903.03216, 2019
-
[26]
Hammer: Multi-level coordination of reinforcement learning agents via learned messaging,
N. Gupta, G. Srinivasaraghavan, S. Mohalik, N. Kumar, and M. E. Taylor, “Hammer: Multi-level coordination of reinforcement learning agents via learned messaging,”Neural Computing and Applications, pp. 1–16, 2023
2023
-
[27]
Un- derstanding and sharing intentions: The origins of cultural cognition,
M. Tomasello, M. Carpenter, J. Call, T. Behne, and H. Moll, “Un- derstanding and sharing intentions: The origins of cultural cognition,” Behavioral and brain sciences, vol. 28, no. 5, pp. 675–691, 2005
2005
-
[28]
Consensus learning for cooperative multi-agent reinforcement learning,
Z. Xu, B. Zhang, D. Li, Z. Zhang, G. Zhou, H. Chen, and G. Fan, “Consensus learning for cooperative multi-agent reinforcement learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 10, 2023, pp. 11 726–11 734
2023
-
[29]
Contrastive identity-aware learning for multi-agent value decomposition,
S. Liu, Y . Zhou, J. Song, T. Zheng, K. Chen, T. Zhu, Z. Feng, and M. Song, “Contrastive identity-aware learning for multi-agent value decomposition,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 10, 2023, pp. 11 595–11 603
2023
-
[30]
Learning to ground decentralized multi-agent communication with contrastive learning,
Y . L. Lo and B. Sengupta, “Learning to ground decentralized multi-agent communication with contrastive learning,”arXiv preprint arXiv:2203.03344, 2022
-
[31]
Markov games as a framework for multi-agent rein- forcement learning,
M. L. Littman, “Markov games as a framework for multi-agent rein- forcement learning,” inMachine learning proceedings 1994. Elsevier, 1994, pp. 157–163
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.