Representing Time Series as Structured Programs for LLM Reasoning
Pith reviewed 2026-06-27 11:03 UTC · model grok-4.3
The pith
Converting time series into structured symbolic programs lets off-the-shelf LLMs reason about them without fine-tuning or raw serialization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
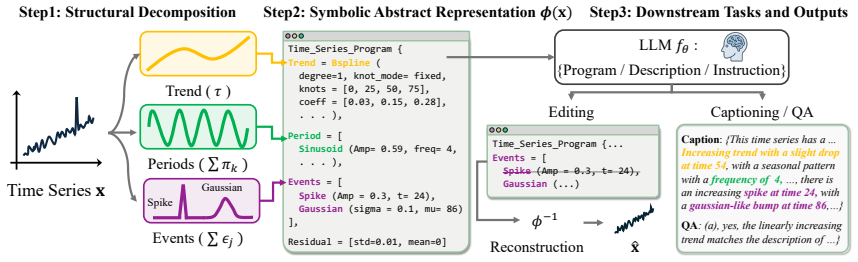
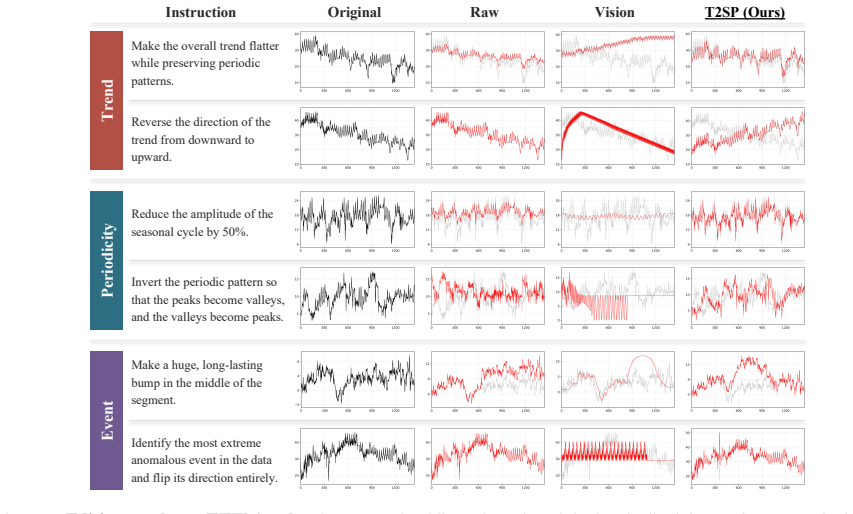
T2SP is a deterministic, training-free method that represents a time series as a structured symbolic program. T2SP decomposes time series into trends, periods, and salient events, expressing them in a program-friendly format aligned with the textual and code-like modalities on which LLMs are natively trained. By shifting temporal-structure extraction from the model to the representation itself, T2SP enables off-the-shelf LLMs to leverage their existing reasoning capabilities for time-series understanding.
What carries the argument
T2SP representation, which decomposes any time series into trends, periods, and salient events expressed as a structured symbolic program.
If this is right
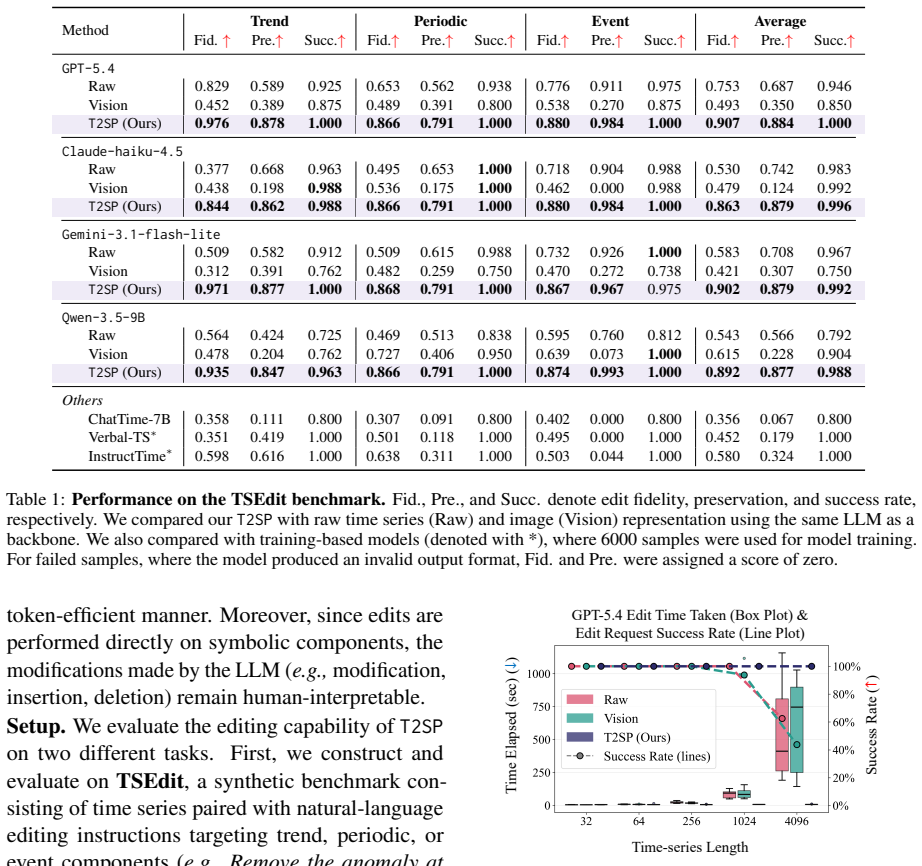
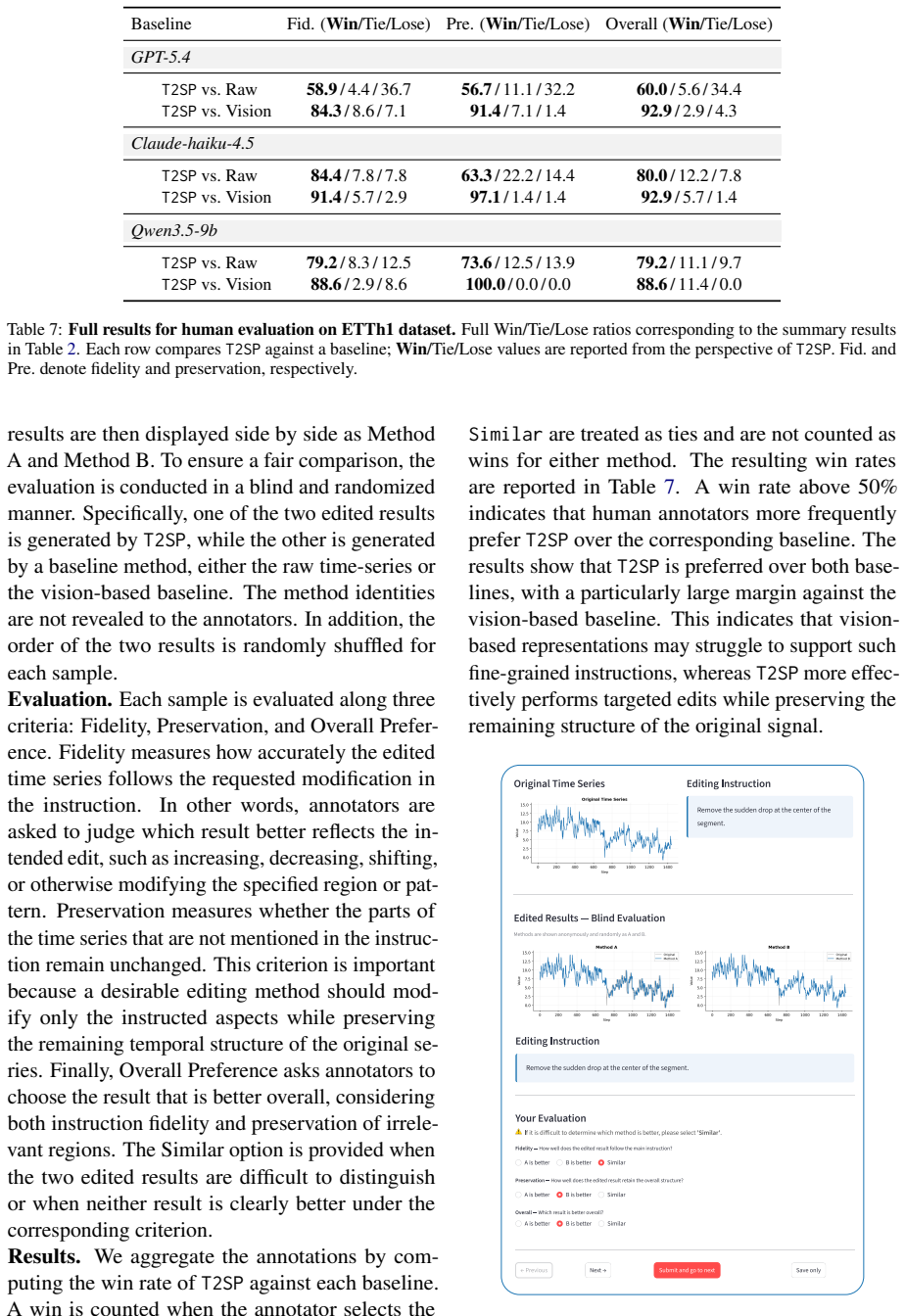
- Performance improves on time-series editing, captioning, and question answering compared with raw-string inputs.
- Reasoning time decreases for these tasks.
- Failure rates drop when LLMs receive the structured program format.
- Off-the-shelf LLMs can be applied directly without fine-tuning on time-series data.
Where Pith is reading between the lines
- The same pre-structuring idea could be tested on other non-text data such as images or audio by converting them into symbolic descriptions first.
- Because the output is a readable program, humans might inspect or edit the temporal decomposition before feeding it to the LLM.
- Longer sequences might show even larger gains since raw serialization tends to degrade more sharply with length.
Load-bearing premise
A deterministic decomposition of any time series into trends, periods, and salient events can be expressed in a program-friendly format that reliably aligns with LLM textual and code-like modalities without introducing errors.
What would settle it
A counterexample where the T2SP program for a given time series causes an LLM to produce incorrect outputs on editing, captioning, or question-answering tasks while the raw numerical string succeeds.
Figures



read the original abstract
Large language models (LLMs) have demonstrated strong reasoning and instruction-following capabilities, making them potentially powerful tools for time-series analysis. However, time series lie outside their native textual modality, raising a fundamental question: how should time series be represented so that LLMs can reason about them effectively? Existing work typically serializes raw numerical sequences or fine-tunes pre-trained LLMs on time-series data. These approaches place the burden of extracting temporal structure directly on the LLM, creating a modality mismatch that often degrades performance on long sequences and introduces substantial computational overhead. In this work, we introduce Time-Series-to-Structured-Program representation (T2SP), a deterministic, training-free method that represents a time series as a structured symbolic program. T2SP decomposes time series into trends, periods, and salient events, expressing them in a program-friendly format aligned with the textual and code-like modalities on which LLMs are natively trained. By shifting temporal-structure extraction from the model to the representation itself, T2SP enables off-the-shelf LLMs to leverage their existing reasoning capabilities for time-series understanding. We evaluate T2SP on three reasoning tasks -- editing, captioning, and question answering -- where it consistently improves performance, reduces reasoning time, and lowers failure rates compared with raw-string representations. Our results demonstrate that T2SP provides an effective interface between time series and LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces T2SP, a deterministic, training-free method that represents time series as structured symbolic programs by decomposing them into trends, periods, and salient events expressed in a program-friendly format. This is claimed to shift temporal structure extraction away from the LLM, enabling off-the-shelf models to achieve better performance on editing, captioning, and question-answering tasks while reducing reasoning time and failure rates relative to raw-string representations.
Significance. If the results hold, T2SP could provide a practical, parameter-free interface for applying LLMs to time-series reasoning without fine-tuning or modality mismatch. The deterministic and training-free design is a clear strength, avoiding circularity or learned parameters and directly leveraging LLMs' existing code and text capabilities. This has potential implications for efficient temporal analysis in domains where labeled time-series data is scarce.
major comments (2)
- [Abstract] Abstract: the claim that T2SP 'consistently improves performance' on the three tasks is presented without quantitative results, baselines, error bars, dataset details, or description of how the decomposition is performed, so the data-to-claim link cannot be evaluated.
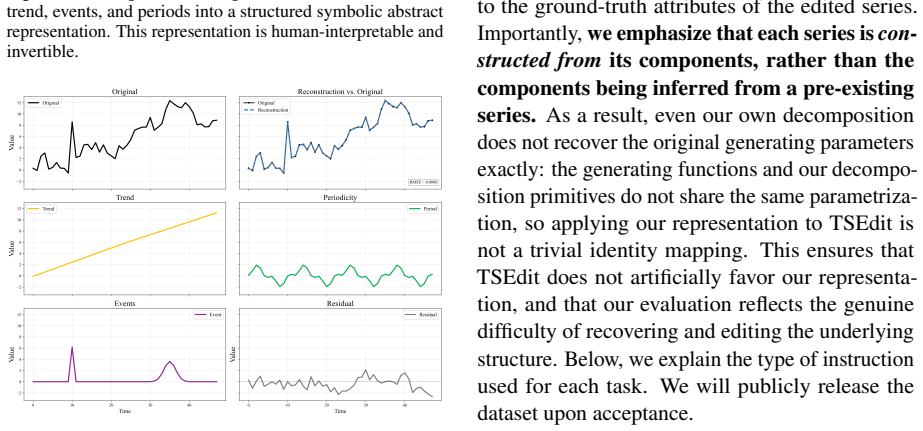
- [T2SP method description] T2SP method description: no quantitative fidelity metric (e.g., reconstruction error or alignment with ground-truth structure) or failure-case analysis is supplied for the deterministic decomposition into trends/periods/events. This is load-bearing for the central premise that the representation introduces no errors that could degrade LLM reasoning on complex or noisy series.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify opportunities to strengthen the abstract's self-containment and to provide explicit validation of the decomposition step. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that T2SP 'consistently improves performance' on the three tasks is presented without quantitative results, baselines, error bars, dataset details, or description of how the decomposition is performed, so the data-to-claim link cannot be evaluated.
Authors: We agree that the abstract, being a concise summary, does not embed the supporting quantitative details. The body of the manuscript (Sections 4 and 5) reports the full results, including baselines, error bars, dataset descriptions, and per-task metrics that substantiate the 'consistently improves' claim. To improve self-containment, we will revise the abstract to incorporate brief quantitative highlights (e.g., average relative gains) and a short clause describing the deterministic decomposition into trends, periods, and events. revision: yes
-
Referee: [T2SP method description] T2SP method description: no quantitative fidelity metric (e.g., reconstruction error or alignment with ground-truth structure) or failure-case analysis is supplied for the deterministic decomposition into trends/periods/events. This is load-bearing for the central premise that the representation introduces no errors that could degrade LLM reasoning on complex or noisy series.
Authors: The decomposition employs standard, deterministic signal-processing routines whose fidelity is implicit in their design. Nevertheless, we accept that an explicit quantitative check would strengthen the central premise. In the revised manuscript we will add a dedicated fidelity subsection reporting reconstruction error (MSE between original and program-reconstructed series) across the evaluation datasets together with a brief analysis of failure modes on noisy or irregular inputs. revision: yes
Circularity Check
No circularity: deterministic representation method with external baselines
full rationale
The paper introduces T2SP as a deterministic, training-free decomposition of time series into trends/periods/events expressed in program format. No equations, fitted parameters, or predictions are defined in terms of themselves. Performance is measured against raw-string baselines on editing/captioning/QA tasks, providing independent empirical content. No self-citation chains or uniqueness theorems are invoked as load-bearing premises in the provided text. The central claim reduces to the method's design and measured gains rather than any definitional loop or renamed input.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Time series data can be decomposed into trends, periods, and salient events in a way that produces a program-friendly symbolic representation aligned with LLM training modalities.
Reference graph
Works this paper leans on
-
[2]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[3]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Language models still struggle to zero-shot reason about time series , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[6]
Forty-first international conference on machine learning , year=
Position: What can large language models tell us about time series analysis , author=. Forty-first international conference on machine learning , year=
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Chattime: A unified multimodal time series foundation model bridging numerical and textual data , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[10]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Evaluating large language models on time series feature understanding: A comprehensive taxonomy and benchmark , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[12]
Advances in neural information processing systems , volume=
Large language models are zero-shot time series forecasters , author=. Advances in neural information processing systems , volume=
-
[13]
IEEE Transactions on Knowledge and Data Engineering , volume=
Promptcast: A new prompt-based learning paradigm for time series forecasting , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2023 , publisher=
2023
-
[14]
Proceedings of the VLDB Endowment , volume=
ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning , author=. Proceedings of the VLDB Endowment , volume=. 2025 , publisher=
2025
-
[15]
Advances in Neural Information Processing Systems , volume=
Towards editing time series , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Instruction-based Time Series Editing , author=. Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1 , pages=
-
[17]
International Conference on Machine Learning , pages=
Time-VLM: Exploring Multimodal Vision-Language Models for Augmented Time Series Forecasting , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[20]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Time-mqa: Time series multi-task question answering with context enhancement , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[21]
International Conference on Learning Representations , volume=
Test: Text prototype aligned embedding to activate llm's ability for time series , author=. International Conference on Learning Representations , volume=
-
[22]
STL: A seasonal-trend decomposition , author=. J. off. Stat , volume=
-
[23]
Advances in neural information processing systems , volume=
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting , author=. Advances in neural information processing systems , volume=
-
[24]
International Conference on Machine Learning , pages=
TransPL: VQ-Code Transition Matrices for Pseudo-Labeling of Time Series Unsupervised Domain Adaptation , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[25]
Journal of Approximation theory , volume=
On calculating with B-splines , author=. Journal of Approximation theory , volume=. 1972 , publisher=
1972
-
[26]
Forty-second International Conference on Machine Learning , year=
Verbalts: Generating time series from texts , author=. Forty-second International Conference on Machine Learning , year=
-
[28]
International conference on machine learning , pages=
Pal: Program-aided language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[30]
Transactions on Machine Learning Research , year=
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks , author=. Transactions on Machine Learning Research , year=
-
[32]
IEEE/CAA Journal of Automatica Sinica , volume=
The UCR time series archive , author=. IEEE/CAA Journal of Automatica Sinica , volume=. 2019 , publisher=
2019
-
[33]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Clipscore: A reference-free evaluation metric for image captioning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[34]
TRQA: Time Series Reasoning Question And Answering Benchmark , author=
-
[35]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
Pith/arXiv arXiv 2023
-
[36]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, and 1 others. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
Pith/arXiv arXiv 2021
-
[37]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. 2023. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. Transactions on Machine Learning Research
2023
-
[38]
Robert B Cleveland, William S Cleveland, Jean E McRae, Irma Terpenning, and 1 others. 1990. Stl: A seasonal-trend decomposition. J. off. Stat, 6(1):3--73
1990
-
[39]
Hoang Anh Dau, Anthony Bagnall, Kaveh Kamgar, Chin-Chia Michael Yeh, Yan Zhu, Shaghayegh Gharghabi, Chotirat Ann Ratanamahatana, and Eamonn Keogh. 2019. The ucr time series archive. IEEE/CAA Journal of Automatica Sinica, 6(6):1293--1305
2019
-
[40]
Carl De Boor. 1972. On calculating with b-splines. Journal of Approximation theory, 6(1):50--62
1972
-
[41]
Yueyang Ding, HaoPeng Zhang, Rui Dai, Yi Wang, Tianyu Zong, Kaikui Liu, and Xiangxiang Chu. 2026. Llatisa: Towards difficulty-stratified time series reasoning from visual perception to semantics. arXiv preprint arXiv:2604.17295
Pith/arXiv arXiv 2026
-
[42]
Elizabeth Fons, Rachneet Kaur, Soham Palande, Zhen Zeng, Tucker Balch, Manuela Veloso, and Svitlana Vyetrenko. 2024. Evaluating large language models on time series feature understanding: A comprehensive taxonomy and benchmark. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21598--21634
2024
-
[43]
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Pal: Program-aided language models. In International conference on machine learning, pages 10764--10799. PMLR
2023
-
[44]
Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G Wilson. 2023. Large language models are zero-shot time series forecasters. Advances in neural information processing systems, 36:19622--19635
2023
-
[45]
Shuqi Gu, Chuyue Li, Baoyu Jing, and Kan Ren. 2025. Verbalts: Generating time series from texts. In Forty-second International Conference on Machine Learning
2025
-
[46]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
2021
-
[47]
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. 2021. Clipscore: A reference-free evaluation metric for image captioning. In Proceedings of the 2021 conference on empirical methods in natural language processing, pages 7514--7528
2021
-
[48]
Ming Jin, Yifan Zhang, Wei Chen, Kexin Zhang, Yuxuan Liang, Bin Yang, Jindong Wang, Shirui Pan, and Qingsong Wen. 2024. Position: What can large language models tell us about time series analysis. In Forty-first international conference on machine learning
2024
-
[49]
Trqa: Time series reasoning question and answering benchmark
Baoyu Jing, Sanhorn Chen, Lecheng Zheng, Boyu Liu, Zihao Li, Jiaru Zou, Tianxin Wei, Zhining Liu, Zhichen Zeng, Ruizhong Qiu, and 1 others. Trqa: Time series reasoning question and answering benchmark
-
[50]
Baoyu Jing, Shuqi Gu, Tianyu Chen, Zhiyu Yang, Dongsheng Li, Jingrui He, and Kan Ren. 2024. Towards editing time series. Advances in Neural Information Processing Systems, 37:37561--37593
2024
-
[51]
Jaeho Kim and Seulki Lee. 2025. Transpl: Vq-code transition matrices for pseudo-labeling of time series unsupervised domain adaptation. In International Conference on Machine Learning, pages 30462--30479. PMLR
2025
-
[52]
Yaxuan Kong, Yiyuan Yang, Yoontae Hwang, Wenjie Du, Stefan Zohren, Zhangyang Wang, Ming Jin, and Qingsong Wen. 2025. Time-mqa: Time series multi-task question answering with context enhancement. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29736--29753
2025
-
[53]
Patrick Langer, Thomas Kaar, Max Rosenblattl, Maxwell A Xu, Winnie Chow, Martin Maritsch, Robert Jakob, Ning Wang, Juncheng Liu, Aradhana Verma, and 1 others. 2025. Opentslm: Time-series language models for reasoning over multivariate medical text-and time-series data. arXiv preprint arXiv:2510.02410
arXiv 2025
-
[54]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. 2024. The ai scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292
Pith/arXiv arXiv 2024
-
[55]
Mike A Merrill, Mingtian Tan, Vinayak Gupta, Thomas Hartvigsen, and Tim Althoff. 2024. Language models still struggle to zero-shot reason about time series. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 3512--3533
2024
-
[56]
Shvat Messica, Jiawen Zhang, Kevin Li, Theodoros Tsiligkaridis, and Marinka Zitnik. 2026. Adaptive time series reasoning via segment selection. arXiv preprint arXiv:2602.18645
Pith/arXiv arXiv 2026
-
[57]
Jingchao Ni, Ziming Zhao, ChengAo Shen, Hanghang Tong, Dongjin Song, Wei Cheng, Dongsheng Luo, and Haifeng Chen. 2025. Harnessing vision models for time series analysis: A survey. arXiv preprint arXiv:2502.08869
arXiv 2025
-
[58]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, and 1 others. 2025. Humanity's last exam. arXiv preprint arXiv:2501.14249
Pith/arXiv arXiv 2025
-
[59]
Jiaxing Qiu, Dongliang Guo, Brynne Sullivan, Teague R Henry, and Thomas Hartvigsen. 2026. Instruction-based time series editing. In Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1, pages 1216--1227
2026
-
[60]
Medhasweta Sen, Zachary Gottesman, Jiaxing Qiu, C Bayan Bruss, Nam Nguyen, and Tom Hartvigsen. 2025. Bedtime: A unified benchmark for automatically describing time series. arXiv preprint arXiv:2509.05215
Pith/arXiv arXiv 2025
-
[61]
Chenxi Sun, Hongyan Li, Yaliang Li, and Shenda Hong. 2024. Test: Text prototype aligned embedding to activate llm's ability for time series. In International Conference on Learning Representations, volume 2024, pages 37854--37881
2024
-
[62]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, and 1 others. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971
Pith/arXiv arXiv 2023
-
[63]
Chengsen Wang, Qi Qi, Jingyu Wang, Haifeng Sun, Zirui Zhuang, Jinming Wu, Lei Zhang, and Jianxin Liao. 2025. Chattime: A unified multimodal time series foundation model bridging numerical and textual data. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 12694--12702
2025
-
[64]
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. 2021. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Advances in neural information processing systems, 34:22419--22430
2021
-
[65]
Zhe Xie, Zeyan Li, Xiao He, Longlong Xu, Xidao Wen, Tieying Zhang, Jianjun Chen, Rui Shi, and Dan Pei. 2025. Chatts: Aligning time series with llms via synthetic data for enhanced understanding and reasoning. Proceedings of the VLDB Endowment, 18(8):2385--2398
2025
-
[66]
Hao Xue and Flora D Salim. 2023. Promptcast: A new prompt-based learning paradigm for time series forecasting. IEEE Transactions on Knowledge and Data Engineering, 36(11):6851--6864
2023
-
[67]
Siru Zhong, Weilin Ruan, Ming Jin, Huan Li, Qingsong Wen, and Yuxuan Liang. 2025. Time-vlm: Exploring multimodal vision-language models for augmented time series forecasting. In International Conference on Machine Learning, pages 78478--78497. PMLR
2025
-
[68]
Tianyi Zhou, Deqing Fu, Mahdi Soltanolkotabi, Robin Jia, and Vatsal Sharan. 2025. Fone: Precise single-token number embeddings via fourier features. arXiv preprint arXiv:2502.09741
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.