μVLA: On Recurrent Memory for Partially Observable Manipulation in VLA Models
Pith reviewed 2026-06-27 10:48 UTC · model grok-4.3
The pith
Adding a small set of learnable memory tokens to a pretrained VLA transformer, updated only through self-attention and trained with TBPTT, raises average success from 0.42 to 0.84 on partially observable manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By augmenting a transformer-based VLA with a small set of learnable memory tokens carried across timesteps and updated through self-attention, trained end-to-end with truncated backpropagation through time and no auxiliary losses, the resulting models achieve average success rates of 0.84 on five training tasks and 0.23 on held-out tasks that share the identical memory structure, compared with 0.42 and 0.07 for the memoryless baseline; performance stays near baseline on tasks requiring a different memory structure and reaches 96.2 percent average success on a fully observable benchmark.
What carries the argument
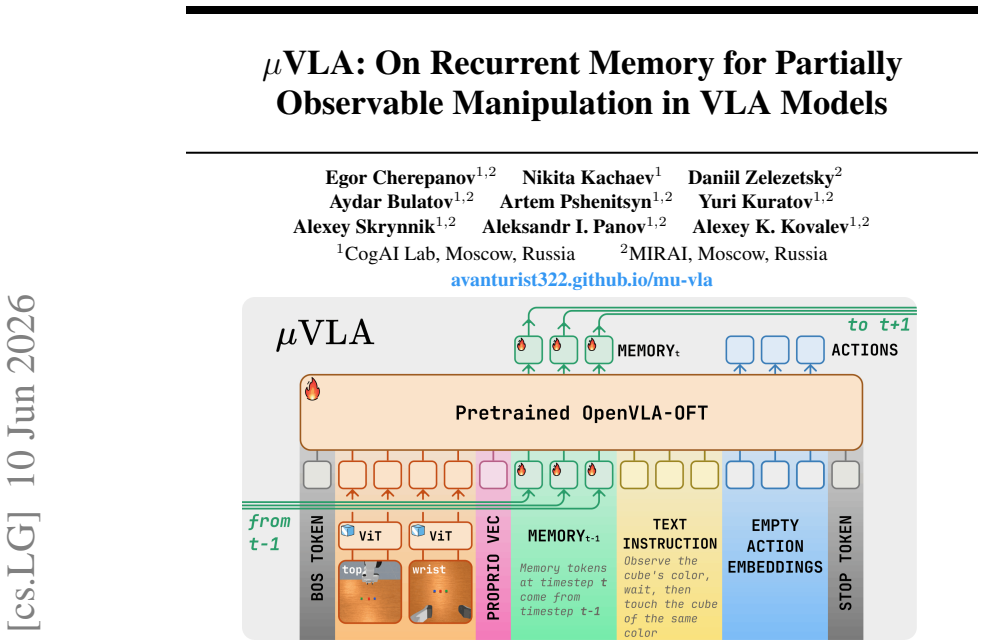
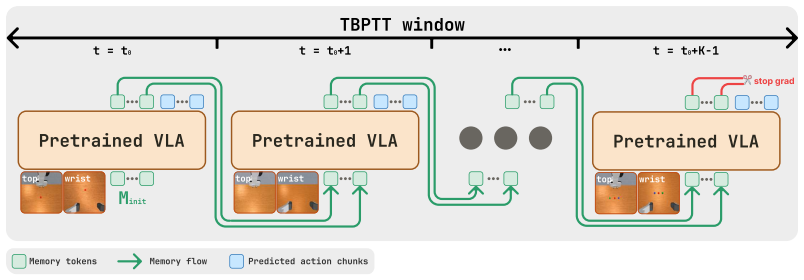
A small set of learnable memory tokens carried across timesteps and updated through self-attention inside the transformer, with the only varying factors being memory width, TBPTT length, and the choice between cross-step gradients or detached EMA update.
If this is right
- On tasks sharing the same memory demand structure, recurrent models reach substantially higher success rates than memoryless baselines.
- On tasks whose memory demands differ, recurrent models perform near the memoryless baseline.
- The strongest recurrent variant reaches 96.2 percent average success on fully observable benchmarks with no regression.
- Recurrence can be isolated from retrieval, compression, auxiliary objectives, or hierarchical memory while still producing measurable gains.
Where Pith is reading between the lines
- For many manipulation tasks whose partial observability fits a simple temporal pattern, minimal recurrence may be sufficient and more complex memory architectures may be unnecessary.
- The gap between training and held-out tasks with matched versus mismatched memory structure suggests that generalization depends on correctly identifying the required memory pattern in advance.
- Extending the same token-based recurrence to longer horizons or different sensor modalities could test the boundaries of the regime identified here.
- The same isolation approach could be applied to other sequential decision domains where partial observability is the limiting factor.
Load-bearing premise
The measured performance gains are produced by the recurrence mechanism itself rather than by differences in optimization dynamics, task selection, or the labeling of which tasks require memory.
What would settle it
An experiment that matches training procedure exactly and still finds no success-rate difference between recurrent and memoryless models on the same partially observable tasks would falsify the claim that recurrence drives the gains.
Figures



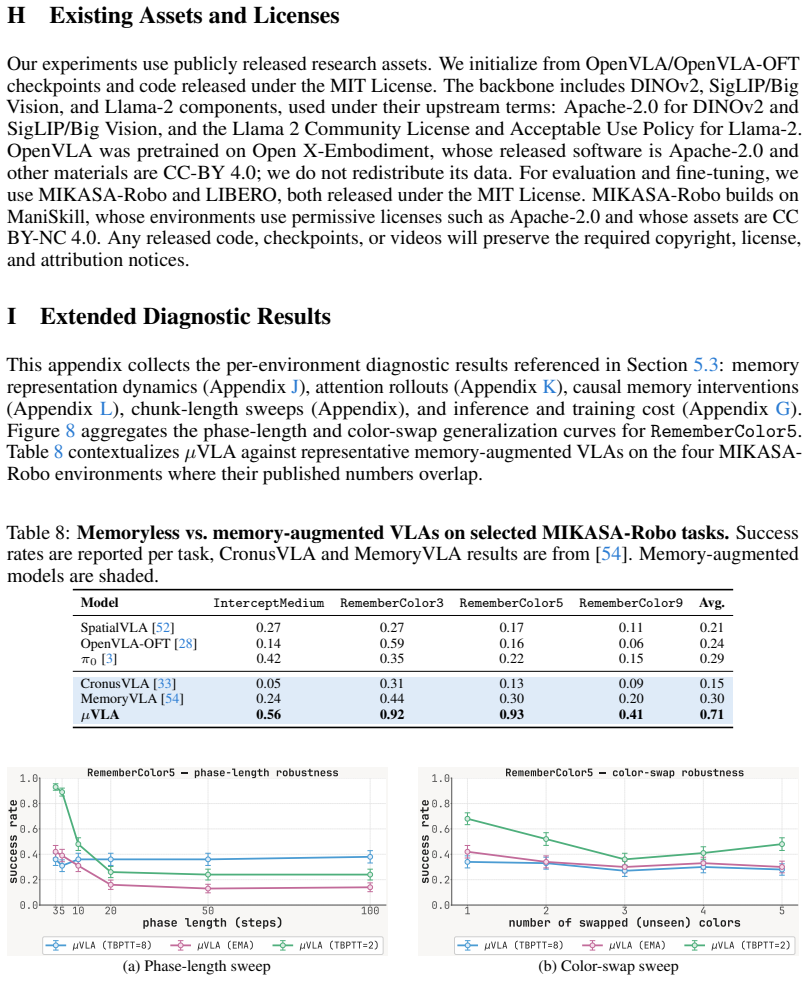
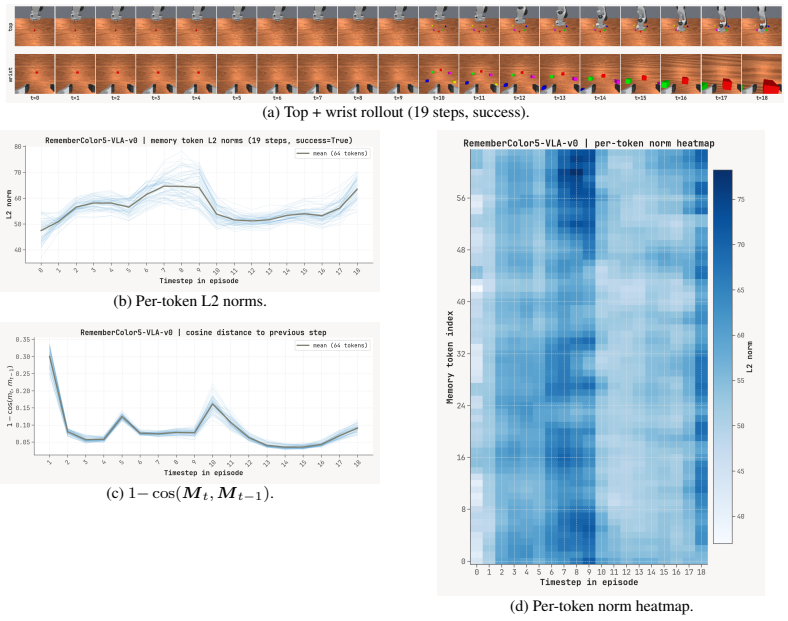
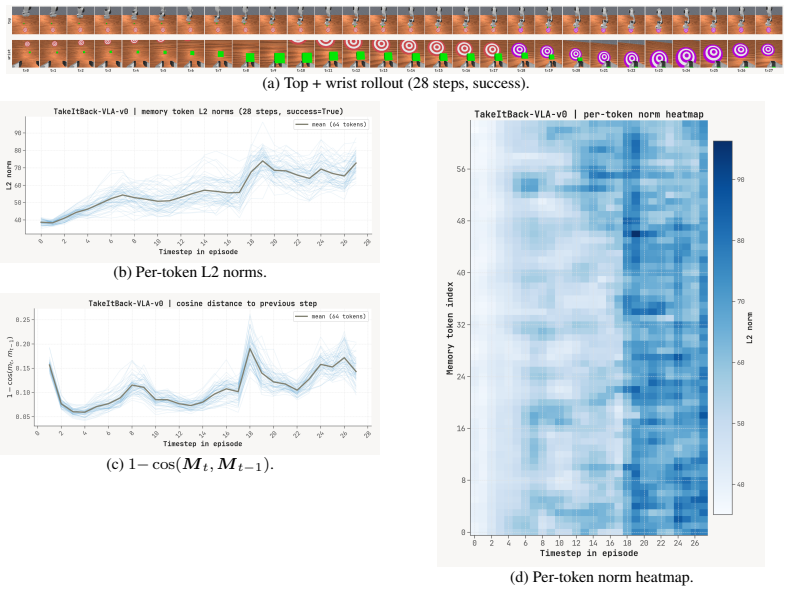
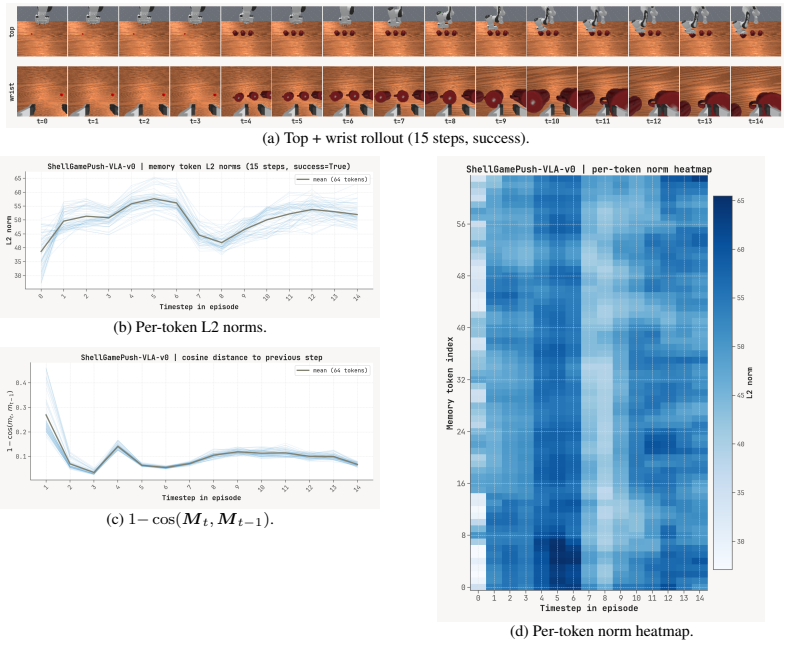
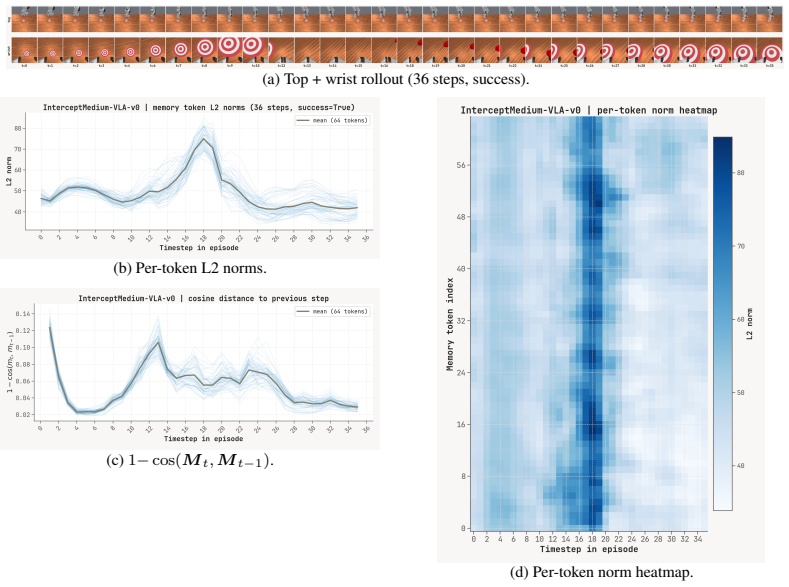
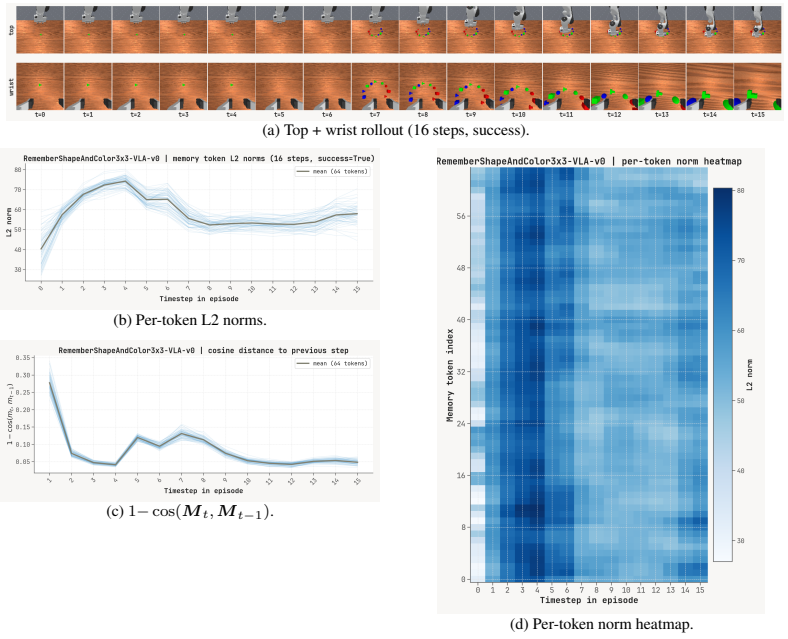
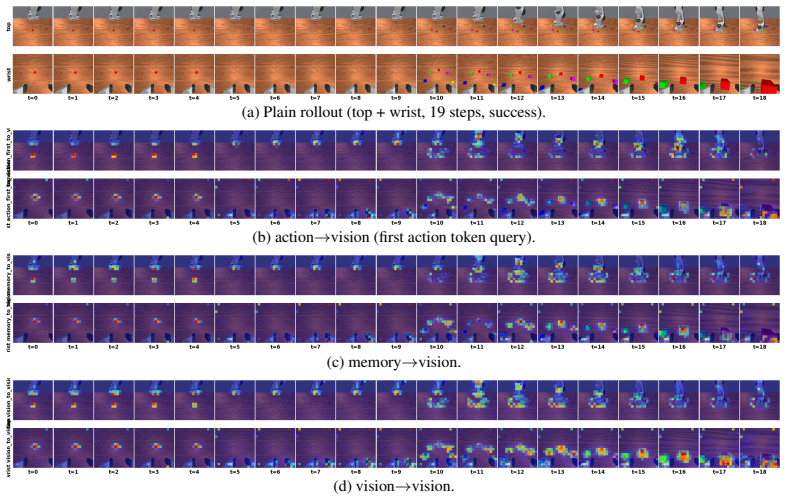
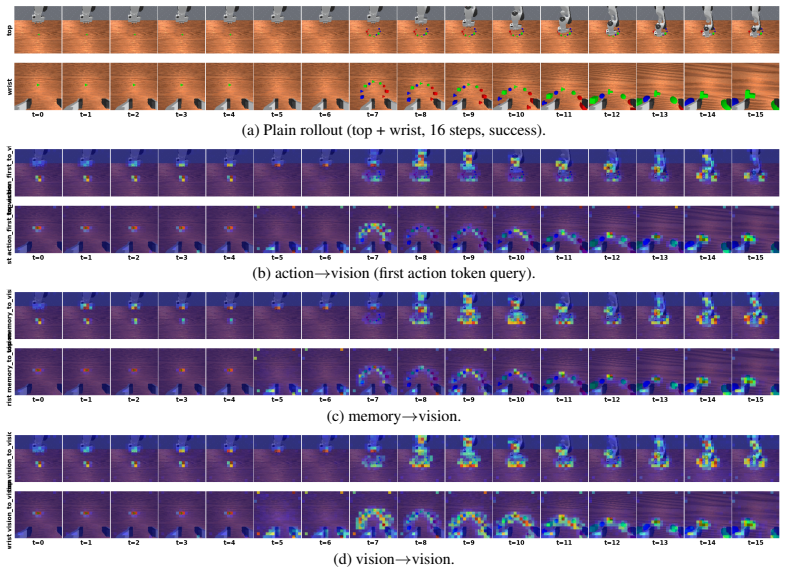


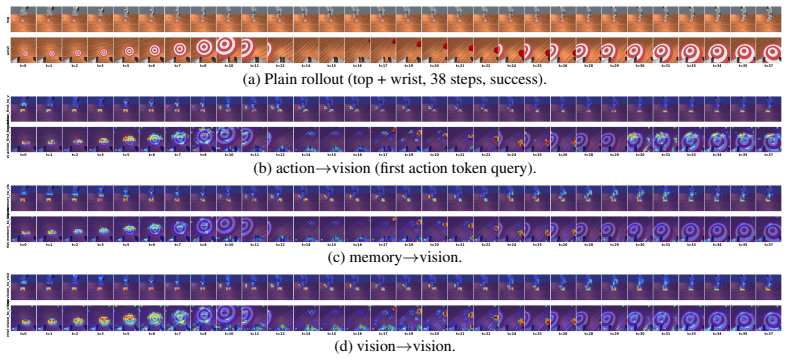
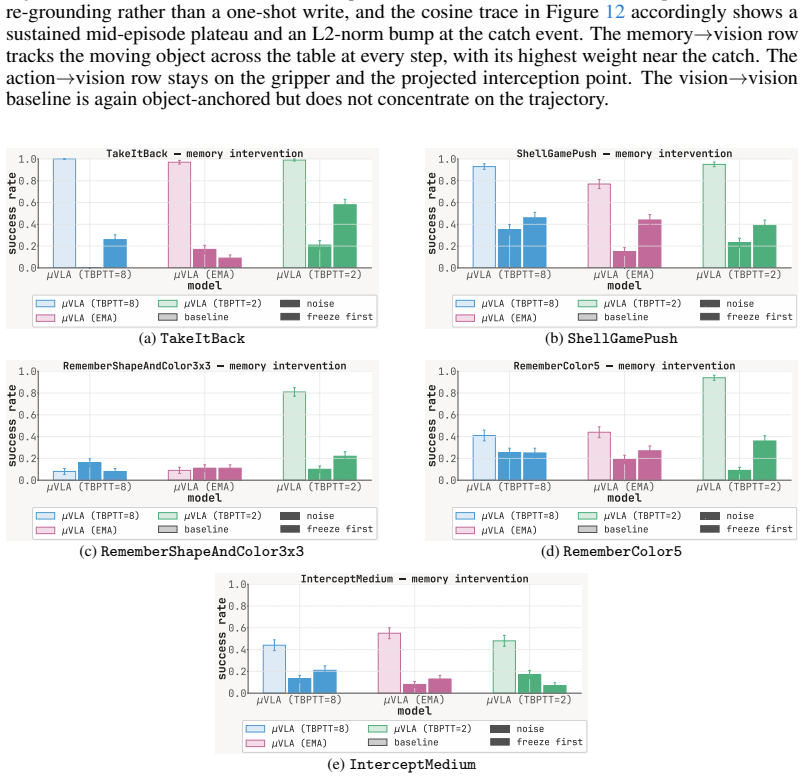
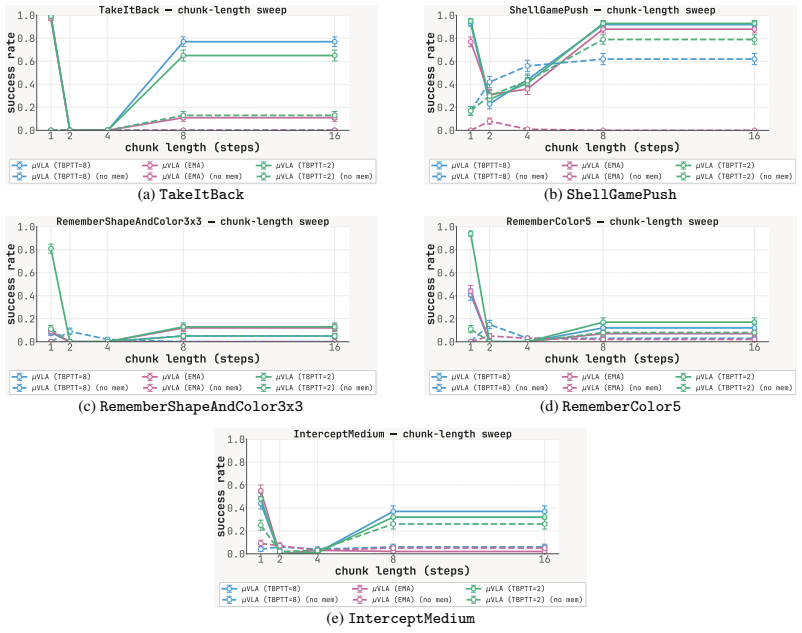
read the original abstract
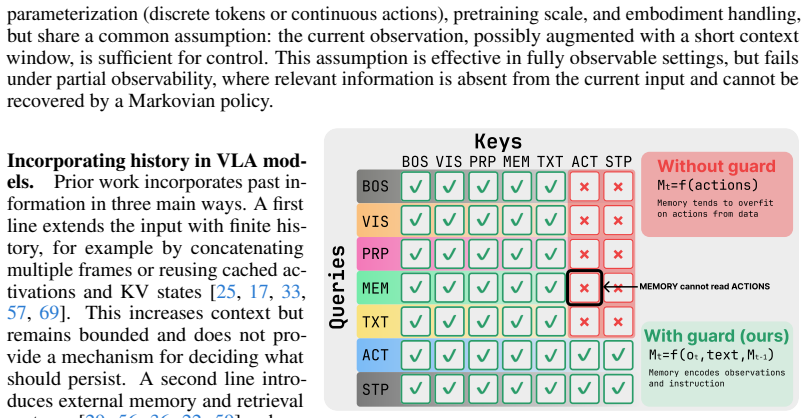
Vision-language-action (VLA) models predict chunks of future actions from the current observation, an assumption that fails under partial observability, where decisions depend on information no longer visible. Existing memory-augmented VLAs simultaneously introduce recurrence, retrieval, compression modules, auxiliary objectives, hierarchical memory, or task-specific architectural changes, so the contribution of recurrence itself remains entangled with surrounding machinery. We present a controlled isolation study of recurrence in a strong pretrained VLA backbone. Our formulation augments the transformer with a small set of learnable memory tokens carried across timesteps and updated through self-attention, trained end to end with truncated backpropagation through time, with no auxiliary losses and no architectural changes. We instantiate this as $\mu$VLA, a family of OpenVLA-OFT variants parameterized by memory width m, TBPTT length K, and the memory update rule (cross-step gradients or a detached EMA), so that recurrence is the only varying factor. On MIKASA-Robo, $\mu$VLA improves average success rate on five training tasks from 0.42 to 0.84 at the strongest setting and reaches 0.23 on held-out tasks with the same memory structure versus 0.07 for the memoryless baseline. On tasks requiring different memory structure, performance remains near baseline. On LIBERO, the strongest recurrent variant achieves 96.2% average success, indicating no regression under full observability. We interpret these results as a calibration of the capability envelope of minimal in-backbone recurrence, identifying the regime in which it is sufficient and the regime where additional memory structure is required. Demos and videos can be found in https://avanturist322.github.io/mu-vla/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to isolate the contribution of recurrence in VLA models for partially observable manipulation by augmenting a pretrained backbone (OpenVLA-OFT) with a small set of learnable memory tokens that are carried across timesteps, updated via self-attention, and trained end-to-end with TBPTT (no auxiliary losses or other architectural changes). Recurrence is the sole varying factor via parameters m (memory width), K (TBPTT length), and update rule (cross-step gradients or detached EMA). On MIKASA-Robo this yields average success rate gains from 0.42 to 0.84 on five training tasks at the strongest setting and from 0.07 to 0.23 on held-out tasks sharing the same memory structure (versus memoryless baseline), with performance remaining near baseline on tasks requiring different memory structure; on LIBERO the strongest variant reaches 96.2% average success with no regression under full observability. The results are interpreted as calibrating the regime in which minimal in-backbone recurrence suffices.
Significance. If the isolation of recurrence holds, the work supplies a useful empirical calibration of the capability envelope of minimal recurrence inside VLA transformers for POMDPs, distinguishing regimes where the mechanism is sufficient from those requiring additional memory structure. The explicit parameterization by m, K, and update rule, together with the attempt at a controlled study on a strong pretrained backbone, is a methodological strength that could serve as a reproducible baseline for future memory-augmented VLA research.
major comments (1)
- [MIKASA-Robo experiments and held-out task evaluation] The central claim that performance deltas (0.42→0.84 on training tasks, 0.07→0.23 on held-out) are attributable to recurrence rather than extra capacity, attention changes, or task selection requires that the assignment of tasks to 'same memory structure' versus 'different memory structure' be based on a pre-specified, observable criterion (e.g., a formal Markovian/non-Markovian state definition or other independent property) defined before seeing results. The manuscript provides no such independent criterion in the experimental section, leaving the isolation claim under-determined.
minor comments (2)
- [Results] The abstract and results statements report point estimates without error bars, number of seeds, or statistical tests; these should be added to all tables and figures reporting success rates.
- [Experiments] Full baseline details, ablation tables over m and K, and exact task definitions for the memory-structure split should be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address the single major comment below and will revise the manuscript to strengthen the experimental claims.
read point-by-point responses
-
Referee: [MIKASA-Robo experiments and held-out task evaluation] The central claim that performance deltas (0.42→0.84 on training tasks, 0.07→0.23 on held-out) are attributable to recurrence rather than extra capacity, attention changes, or task selection requires that the assignment of tasks to 'same memory structure' versus 'different memory structure' be based on a pre-specified, observable criterion (e.g., a formal Markovian/non-Markovian state definition or other independent property) defined before seeing results. The manuscript provides no such independent criterion in the experimental section, leaving the isolation claim under-determined.
Authors: We agree that the isolation claim would be strengthened by an explicit, pre-specified criterion for task categorization that is independent of observed model performance. The current manuscript does not provide such a criterion in the experimental section. In the revised manuscript we will add a dedicated subsection (prior to the results) that defines 'same memory structure' versus 'different' based on an observable, benchmark-defined property: whether the task requires the agent to maintain information about object identities or positions that become fully occluded after the initial observation (as specified in the MIKASA-Robo task definitions). This definition will be stated before any training or evaluation results are presented, ensuring the categorization is not post-hoc. revision: yes
Circularity Check
No circularity: empirical comparisons only
full rationale
The paper reports experimental success rates (0.42→0.84 on training tasks, 0.23 vs 0.07 on held-out) from controlled variants of memory-token recurrence in a pretrained VLA backbone. No equations, fitted parameters presented as predictions, or derivation steps exist that reduce any claimed result to its inputs by construction. Task descriptions and memory-structure labels are given as experimental conditions; results are framed as direct measurements rather than self-referential outputs. Any self-citations are incidental and not load-bearing for a mathematical claim.
Axiom & Free-Parameter Ledger
free parameters (2)
- memory width m
- TBPTT length K
axioms (1)
- domain assumption Self-attention over memory tokens can maintain and update task-relevant state across timesteps without auxiliary losses.
invented entities (1)
-
learnable memory tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Recursive belief vision language action models.arXiv preprint arXiv:2602.20659, 2026
Vaidehi Bagaria, Bijo Sebastian, and Nirav Kumar Patel. Recursive belief vision language action models.arXiv preprint arXiv:2602.20659, 2026
arXiv 2026
-
[2]
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[3]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, Laura Smith, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Z...
-
[4]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Mall...
-
[5]
Recurrent memory transformer.Advances in Neural Information Processing Systems, 35:11079–11091, 2022
Aydar Bulatov, Yury Kuratov, and Mikhail Burtsev. Recurrent memory transformer.Advances in Neural Information Processing Systems, 35:11079–11091, 2022
2022
-
[6]
History-aware visuomotor policy learning via point tracking.arXiv preprint arXiv:2509.17141, 2025
Jingjing Chen, Hongjie Fang, Chenxi Wang, Shiquan Wang, and Cewu Lu. History-aware visuomotor policy learning via point tracking.arXiv preprint arXiv:2509.17141, 2025
arXiv 2025
-
[7]
Tianxing Chen, Yuran Wang, Mingleyang Li, Yan Qin, Hao Shi, Zixuan Li, Yifan Hu, Yingsheng Zhang, Kaixuan Wang, Yue Chen, et al. Rmbench: Memory-dependent robotic manipulation benchmark with insights into policy design.arXiv preprint arXiv:2603.01229, 2026
arXiv 2026
-
[8]
Xueyao Chen, Jingkai Jia, Tong Yang, Yibo Fu, Wei Li, and Wenqiang Zhang. Longbench: Evaluating robotic manipulation policies on real-world long-horizon tasks.arXiv preprint arXiv:2604.16788, 2026
Pith/arXiv arXiv 2026
-
[9]
Yangtao Chen, Zixuan Chen, Nga Teng Chan, Junting Chen, Junhui Yin, Jieqi Shi, Yang Gao, Yong-Lu Li, and Jing Huo. Robohiman: A hierarchical evaluation paradigm for compositional generalization in long-horizon manipulation.arXiv preprint arXiv:2510.13149, 2025
arXiv 2025
-
[10]
Yipeng Chen, Wentao Tan, Lei Zhu, Fengling Li, Jingjing Li, Guoli Yang, and Heng Tao Shen. Non-markovian long-horizon robot manipulation via keyframe chaining.arXiv preprint arXiv:2603.01465, 2026
arXiv 2026
-
[11]
Memory, bench- mark & robots: A benchmark for solving complex tasks with reinforcement learning
Egor Cherepanov, Nikita Kachaev, Alexey Kovalev, and Aleksandr Panov. Memory, bench- mark & robots: A benchmark for solving complex tasks with reinforcement learning. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=9cLPurIZMj
2026
-
[12]
ELMUR: External layer memory with update/rewrite for long-horizon RL problems
Egor Cherepanov, Alexey Kovalev, and Aleksandr Panov. ELMUR: External layer memory with update/rewrite for long-horizon RL problems. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=bm3rbtEMFj
2026
-
[13]
Recurrent action transformer with memory
Egor Cherepanov, Aleksei Staroverov, Alexey Kovalev, and Aleksandr Panov. Recurrent action transformer with memory. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=kByN4v0M3e. 10
2026
-
[14]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[15]
Rethinking progression of memory state in robotic manipulation: An object-centric perspective
Nhat Chung, Taisei Hanyu, Toan Nguyen, Huy Le, Frederick Bumgarner, Duy Minh Ho Nguyen, Khoa V o, Kashu Yamazaki, Chase Rainwater, Tung Kieu, et al. Rethinking progression of memory state in robotic manipulation: An object-centric perspective. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 3407–3415, 2026
2026
-
[16]
Yinpei Dai, Hongze Fu, Jayjun Lee, Yuejiang Liu, Haoran Zhang, Jianing Yang, Chelsea Finn, Nima Fazeli, and Joyce Chai. Robomme: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639, 2026
Pith/arXiv arXiv 2026
-
[17]
Yiguo Fan, Pengxiang Ding, Shuanghao Bai, Xinyang Tong, Yuyang Zhu, Hongchao Lu, Fengqi Dai, Wei Zhao, Yang Liu, Siteng Huang, et al. Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation.arXiv preprint arXiv:2508.19958, 2025
arXiv 2025
-
[18]
Gated memory policy.arXiv preprint arXiv:2604.18933, 2026
Yihuai Gao, Jinyun Liu, Shuang Li, and Shuran Song. Gated memory policy.arXiv preprint arXiv:2604.18933, 2026
Pith/arXiv arXiv 2026
-
[19]
Octo: An Open-Source Generalist Robot Policy
Dibya Ghosh, Homer Rich Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Quan Vuong, Ted Xiao, Pannag R Sanketi, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An Open-Source Generalist Robot Policy. InProceedings of Robotics: Science and Systems, ...
-
[20]
Xinying Guo, Chenxi Jiang, Hyun Bin Kim, Ying Sun, Yang Xiao, Yuhang Han, and Jianfei Yang. Chameleon: Episodic memory for long-horizon robotic manipulation.arXiv preprint arXiv:2603.24576, 2026
Pith/arXiv arXiv 2026
-
[21]
Songhao Han, Boxiang Qiu, Yue Liao, Siyuan Huang, Chen Gao, Shuicheng Yan, and Si Liu. Robocerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation.arXiv preprint arXiv:2506.06677, 2025
arXiv 2025
-
[22]
Sanjay Haresh, Daniel Dijkman, Apratim Bhattacharyya, and Roland Memisevic. Notes-to- self: Scratchpad augmented vlas for memory dependent manipulation tasks.arXiv preprint arXiv:2602.21013, 2026
Pith/arXiv arXiv 2026
-
[23]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=nZeVKeeFYf9
2022
-
[24]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[25]
Huiwon Jang, Sihyun Yu, Heeseung Kwon, Hojin Jeon, Younggyo Seo, and Jinwoo Shin. Contextvla: Vision-language-action model with amortized multi-frame context.arXiv preprint arXiv:2510.04246, 2025
arXiv 2025
-
[26]
Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025
Dong Jing, Gang Wang, Jiaqi Liu, Weiliang Tang, Zelong Sun, Yunchao Yao, Zhenyu Wei, Yunhui Liu, Zhiwu Lu, and Mingyu Ding. Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025
Pith/arXiv arXiv 2025
-
[27]
Open- VLA: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Open- VLA: An open-source vision-language-action model. In8th Annual Conference on Robot Learn...
2024
-
[28]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi: 10.15607/RSS.2025.XXI.017
-
[29]
Myungkyu Koo, Daewon Choi, Taeyoung Kim, Kyungmin Lee, Changyeon Kim, Younggyo Seo, and Jinwoo Shin. Hamlet: Switch your vision-language-action model into a history-aware policy.arXiv preprint arXiv:2510.00695, 2025
Pith/arXiv arXiv 2025
-
[30]
Mingcong Lei, Honghao Cai, Yuyuan Yang, Yimou Wu, Jinke Ren, Zezhou Cui, Liangchen Tan, Junkun Hong, Gehan Hu, Shuangyu Zhu, et al. Robomemory: A brain-inspired multi-memory agentic framework for interactive environmental learning in physical embodied systems.arXiv preprint arXiv:2508.01415, 2025
arXiv 2025
-
[31]
Yuheng Lei, Zhixuan Liang, Hongyuan Zhang, and Ping Luo. Vpwem: Non-markovian visuomotor policy with working and episodic memory.arXiv preprint arXiv:2603.04910, 2026
arXiv 2026
-
[32]
Hang Li, Fengyi Shen, Dong Chen, Liudi Yang, Xudong Wang, Jinkui Shi, Zhenshan Bing, Ziyuan Liu, and Alois Knoll. Remem-vla: Empowering vision-language-action model with memory via dual-level recurrent queries.arXiv preprint arXiv:2603.12942, 2026
arXiv 2026
-
[33]
Hao Li, Shuai Yang, Yilun Chen, Yang Tian, Xiaoda Yang, Xinyi Chen, Hanqing Wang, Tai Wang, Feng Zhao, Dahua Lin, et al. Cronusvla: Transferring latent motion across time for multi-frame prediction in manipulation.arXiv preprint arXiv:2506.19816, 2025
arXiv 2025
-
[34]
Haoyang Li, Yang You, Hao Su, and Leonidas Guibas. Physmem: Scaling test-time physical memory for robot manipulation.arXiv preprint arXiv:2602.20323, 2026
Pith/arXiv arXiv 2026
-
[35]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[36]
Runhao Li, Wenkai Guo, Zhenyu Wu, Changyuan Wang, Haoyuan Deng, Zhenyu Weng, Yap- Peng Tan, and Ziwei Wang. Map-vla: Memory-augmented prompting for vision-language-action model in robotic manipulation.arXiv preprint arXiv:2511.09516, 2025
arXiv 2025
-
[37]
Zaijing Li, Bing Hu, Rui Shao, Gongwei Chen, Dongmei Jiang, Pengwei Xie, Jianye Hao, and Liqiang Nie. Global prior meets local consistency: Dual-memory augmented vision- language-action model for efficient robotic manipulation.arXiv preprint arXiv:2602.20200, 2026
Pith/arXiv arXiv 2026
-
[38]
Min Lin, Xiwen Liang, Bingqian Lin, Liu Jingzhi, Zijian Jiao, Kehan Li, Yuhan Ma, Yuecheng Liu, Shen Zhao, Yuzheng Zhuang, et al. Echovla: Robotic vision-language-action model with synergistic declarative memory for mobile manipulation.arXiv preprint arXiv:2511.18112, 2025
arXiv 2025
-
[39]
Minghui Lin, Pengxiang Ding, Shu Wang, Zifeng Zhuang, Yang Liu, Xinyang Tong, Wenxuan Song, Shangke Lyu, Siteng Huang, and Donglin Wang. Hif-vla: Hindsight, insight and foresight through motion representation for vision-language-action models.arXiv preprint arXiv:2512.09928, 2025
Pith/arXiv arXiv 2025
-
[40]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[41]
Long-horizon manipulation via trace-conditioned vla planning.arXiv preprint arXiv:2604.21924, 2026
Isabella Liu, An-Chieh Cheng, Rui Yan, Geng Chen, Ri-Zhao Qiu, Xueyan Zou, Sha Yi, Hongxu Yin, Xiaolong Wang, and Sifei Liu. Long-horizon manipulation via trace-conditioned vla planning.arXiv preprint arXiv:2604.21924, 2026
Pith/arXiv arXiv 2026
-
[42]
Evovla: Self-evolving vision-language- action model.arXiv preprint arXiv:2511.16166, 2025
Zeting Liu, Zida Yang, Zeyu Zhang, and Hao Tang. Evovla: Self-evolving vision-language- action model.arXiv preprint arXiv:2511.16166, 2025. 12
arXiv 2025
-
[43]
Zhen Liu, Xinyu Ning, Zhe Hu, Xinxin Xie, Weize Li, Zhipeng Tang, Chongyu Wang, Zejun Yang, Hanlin Wang, Yitong Liu, et al. Goal2skill: Long-horizon manipulation with adaptive planning and reflection.arXiv preprint arXiv:2604.13942, 2026
Pith/arXiv arXiv 2026
-
[44]
Qi Lv, Weijie Kong, Hao Li, Jia Zeng, Zherui Qiu, Delin Qu, Haoming Song, Qizhi Chen, Xiang Deng, and Jiangmiao Pang. F1: A vision-language-action model bridging understanding and generation to actions.arXiv preprint arXiv:2509.06951, 2025
Pith/arXiv arXiv 2025
-
[45]
Max Sobol Mark, Jacky Liang, Maria Attarian, Chuyuan Fu, Debidatta Dwibedi, Dhruv Shah, and Aviral Kumar. Bpp: Long-context robot imitation learning by focusing on key history frames.arXiv preprint arXiv:2602.15010, 2026
arXiv 2026
-
[46]
Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[47]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
2024
-
[48]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[49]
Spatial traces: Enhancing vla models with spatial-temporal understanding.Optical Memory and Neural Networks, 34(Suppl 1):S72–S82, 2025
Maxim A Patratskiy, Alexey K Kovalev, and Aleksandr I Panov. Spatial traces: Enhancing vla models with spatial-temporal understanding.Optical Memory and Neural Networks, 34(Suppl 1):S72–S82, 2025
2025
-
[50]
FAST: Efficient Action Tokenization for Vision-Language- Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. FAST: Efficient Action Tokenization for Vision-Language- Action Models. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June
-
[51]
doi: 10.15607/RSS.2025.XXI.012
-
[52]
Weikang Qiu, Tinglin Huang, and Rex Ying. Efficient long-horizon vision-language-action models via static-dynamic disentanglement.arXiv preprint arXiv:2602.03983, 2026
Pith/arXiv arXiv 2026
-
[53]
SpatialVLA: Exploring Spatial Representa- tions for Visual-Language-Action Models
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Jiayuan Gu, Zhigang Wang, Yan Ding, Bin Zhao, Dong Wang, and Xuelong Li. SpatialVLA: Exploring Spatial Representa- tions for Visual-Language-Action Models. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025. doi: 10.15607/RSS.2025.XXI.011
-
[54]
Scaling short-term memory of visuo- motor policies for long-horizon tasks, 2026
Rutav Shah, Rajat Kumar Jenamani, Xiaohan Zhang, Lingfeng Sun, Roberto Martín-Martín, Yuke Zhu, Deva Ramanan, and Karl Schmeckpeper. Scaling short-term memory of visuo- motor policies for long-horizon tasks, 2026. URL https://openreview.net/forum?id= 5SMNtmJFGa
2026
-
[55]
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision- language-action models for robotic manipulation.arXiv preprint arXiv:2508.19236, 2025
Pith/arXiv arXiv 2025
-
[56]
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[57]
Ajay Sridhar, Jennifer Pan, Satvik Sharma, and Chelsea Finn. Memer: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328, 2025. 13
arXiv 2025
-
[58]
Jun Sun, Boyu Yang, Jiahao Zhang, Ning Ma, Chencheng Wu, Siqing Zhang, Yiou Huang, Qiufeng Wang, Shan Liang, and Yaran Chen. Tempofit: Plug-and-play layer-wise tem- poral kv memory for long-horizon vision-language-action manipulation.arXiv preprint arXiv:2603.07647, 2026
arXiv 2026
-
[59]
Huajie Tan, Peterson Co, Yijie Xu, Shanyu Rong, Yuheng Ji, Cheng Chi, Xiansheng Chen, Qiongyu Zhang, Zhongxia Zhao, Pengwei Wang, et al. Action-sketcher: From reasoning to ac- tion via visual sketches for long-horizon robotic manipulation.arXiv preprint arXiv:2601.01618, 2026
arXiv 2026
-
[60]
Marcel Torne, Karl Pertsch, Homer Walke, Kyle Vedder, Suraj Nair, Brian Ichter, Allen Z Ren, Haohuan Wang, Jiaming Tang, Kyle Stachowicz, et al. Mem: Multi-scale embodied memory for vision language action models.arXiv preprint arXiv:2603.03596, 2026
arXiv 2026
-
[61]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[62]
Yalcin Tur, Jalal Naghiyev, Haoquan Fang, Wei-Chuan Tsai, Jiafei Duan, Dieter Fox, and Ranjay Krishna. Recurrent-depth vla: Implicit test-time compute scaling of vision-language-action models via latent iterative reasoning.arXiv preprint arXiv:2602.07845, 2026
arXiv 2026
-
[63]
Khoa V o, Sieu Tran, Taisei Hanyu, Yuki Ikebe, Duy Nguyen, Bui Duy Quoc Nghi, Minh Vu, Anthony Gunderman, Chase Rainwater, Anh Nguyen, et al. Codegraphvlp: Code-as-planner meets semantic-graph state for non-markovian vision-language-action models.arXiv preprint arXiv:2604.22238, 2026
Pith/arXiv arXiv 2026
-
[64]
Vla knows its limits.arXiv preprint arXiv:2602.21445, 2026
Haoxuan Wang, Gengyu Zhang, Yan Yan, Ramana Rao Kompella, and Gaowen Liu. Vla knows its limits.arXiv preprint arXiv:2602.21445, 2026
Pith/arXiv arXiv 2026
-
[65]
Honghui Wang, Zhi Jing, Jicong Ao, Shiji Song, Xuelong Li, Gao Huang, and Chenjia Bai. Beyond short-horizon: Vq-memory for robust long-horizon manipulation in non-markovian simulation benchmarks.arXiv preprint arXiv:2603.09513, 2026
arXiv 2026
-
[66]
Xiaofan Wang, Xingyu Gao, Jianlong Fu, Zuolei Li, Dean Fortier, Galen Mullins, Andrey Kolobov, and Baining Guo. Lola: Long horizon latent action learning for general robot manipulation.arXiv preprint arXiv:2512.20166, 2025
arXiv 2025
-
[67]
Zhenan Wang, Yanzhe Wang, Meixuan Ren, Peng Li, Yang Liu, Yifei Nie, Limin Long, Yun Ye, Xiaofeng Wang, Zhen Zhu, et al. Tacmamba: A tactile history compression adapter bridging fast reflexes and slow vla reasoning.arXiv preprint arXiv:2603.01700, 2026
arXiv 2026
-
[68]
Ava-vla: Improving vision-language-action models with active visual attention
Lei Xiao, Jifeng Li, Juntao Gao, Feiyang Ye, Yan Jin, Jingjing Qian, Jing Zhang, Yong Wu, and Xiaoyuan Yu. Ava-vla: Improving vision-language-action models with active visual attention. arXiv preprint arXiv:2511.18960, 2025
Pith/arXiv arXiv 2025
-
[69]
Siyu Xu, Zijian Wang, Yunke Wang, Chenghao Xia, Tao Huang, and Chang Xu. Affordance field intervention: Enabling vlas to escape memory traps in robotic manipulation.arXiv preprint arXiv:2512.07472, 2025
arXiv 2025
-
[70]
Wanshun Xu, Long Zhuang, and Lianlei Shan. Kv-efficient vla: A method to speed up vision language models with rnn-gated chunked kv cache.arXiv preprint arXiv:2509.21354, 2025
arXiv 2025
-
[71]
Ruihan Yang, Qinxi Yu, Yecheng Wu, Rui Yan, Borui Li, An-Chieh Cheng, Xueyan Zou, Yunhao Fang, Xuxin Cheng, Ri-Zhao Qiu, et al. Egovla: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
Pith/arXiv arXiv 2025
-
[72]
Yi Yang, Jiaxuan Sun, Siqi Kou, Yihan Wang, and Zhijie Deng. Lohovla: A unified vision- language-action model for long-horizon embodied tasks.arXiv preprint arXiv:2506.00411, 2025
arXiv 2025
-
[73]
Yue Yang, Shuo Cheng, Yu Fang, Homanga Bharadhwaj, Mingyu Ding, Gedas Bertasius, and Daniel Szafir. Lilo-vla: Compositional long-horizon manipulation via linked object-centric policies.arXiv preprint arXiv:2602.21531, 2026. 14
arXiv 2026
-
[74]
Zijian Zeng, Fei Ding, Huiming Yang, and Xianwei Li. Helm: Harness-enhanced long-horizon memory for vision-language-action manipulation.arXiv preprint arXiv:2604.18791, 2026
Pith/arXiv arXiv 2026
-
[75]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[76]
Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. InProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023. doi: 10.15607/RSS.2023.XIX.016
-
[77]
Universal actions for enhanced embodied foundation models
Jinliang Zheng, Jianxiong Li, Dongxiu Liu, Yinan Zheng, Zhihao Wang, Zhonghong Ou, Yu Liu, Jingjing Liu, Ya-Qin Zhang, and Xianyuan Zhan. Universal actions for enhanced embodied foundation models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22508–22519, 2025
2025
-
[78]
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[79]
Dexgraspvla: A vision-language-action framework towards general dexterous grasping
Yifan Zhong, Xuchuan Huang, Ruochong Li, Ceyao Zhang, Zhang Chen, Tianrui Guan, Fanlian Zeng, Ka Nam Lui, Yuyao Ye, Yitao Liang, et al. Dexgraspvla: A vision-language-action framework towards general dexterous grasping. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18836–18844, 2026
2026
-
[80]
memory traps
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 15 A Limitations and Scope Our recurrent formulation is trained with TBPTT, so gradien...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.