From Parameters to Feature Space: Task Arithmetic for Backdoor Mitigation in Model Merging
Pith reviewed 2026-06-27 09:22 UTC · model grok-4.3
The pith
By shifting task arithmetic to feature space, Linear Feature Path Minimization suppresses backdoors in merged models while preserving clean performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LFPM formulates the backdoor robustness of the merged model from a unified feature-space perspective under the Cross-Task Linearity (CTL) framework, which leverages the approximate linearity of features across tasks. This perspective guides the optimization of the anti-backdoor task to suppress backdoors while preserving clean-task performance, with an effective optimization mechanism based on gradient accumulation and loss path-integral. Extensive experiments demonstrate that LFPM consistently exhibits strong robustness against backdoor attacks in both full fine-tuning and Parameter-Efficient Fine-Tuning settings.
What carries the argument
Linear Feature Path Minimization (LFPM) under the Cross-Task Linearity (CTL) framework, which optimizes an anti-backdoor task vector in feature space to suppress backdoors along the interpolation path.
If this is right
- Backdoor attacks on merged models can be mitigated effectively in both full fine-tuning and Parameter-Efficient Fine-Tuning settings.
- The optimization ensures robust backdoor suppression along the interpolation path between models.
- Clean-task performance is preserved better than with direct parameter-space editing methods.
- Task arithmetic can be extended from parameters to features for security purposes.
Where Pith is reading between the lines
- If the feature linearity assumption holds broadly, similar feature-space methods could address other vulnerabilities in model merging such as data poisoning.
- This suggests that backdoor defenses might benefit from operating in the space where the model's decision boundaries are more linearly separable across tasks.
- Future work could test whether LFPM scales to merging more than two or three models without additional adjustments.
Load-bearing premise
The assumption that features remain approximately linear across tasks holds sufficiently well that feature-space optimization will reliably suppress backdoors.
What would settle it
An experiment on a merged model where cross-task feature linearity is deliberately broken, after which LFPM no longer reduces backdoor success rate without also lowering clean-task accuracy.
Figures

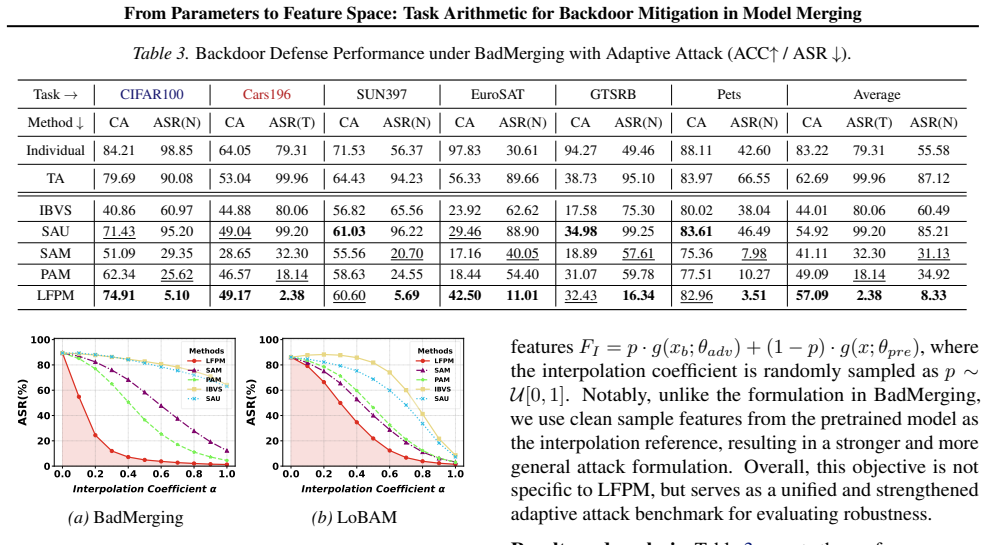
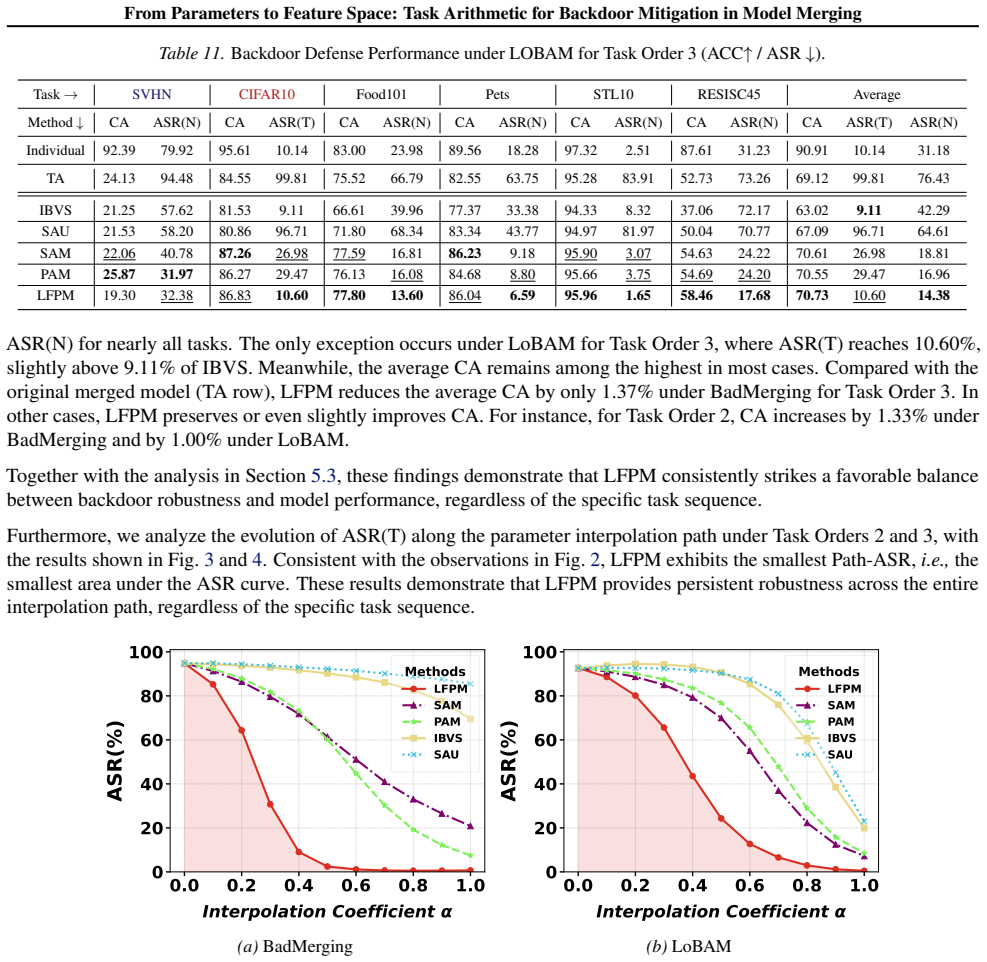
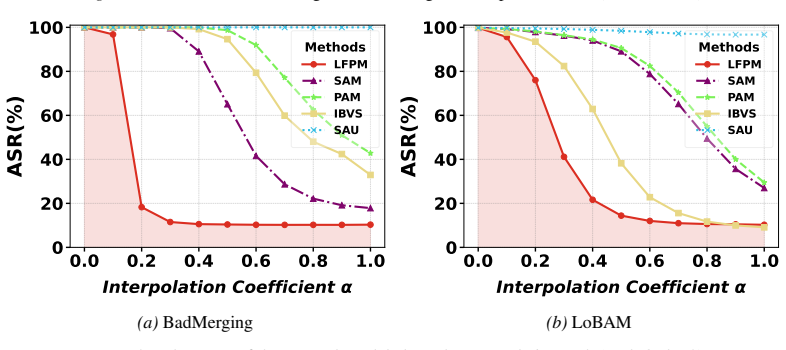
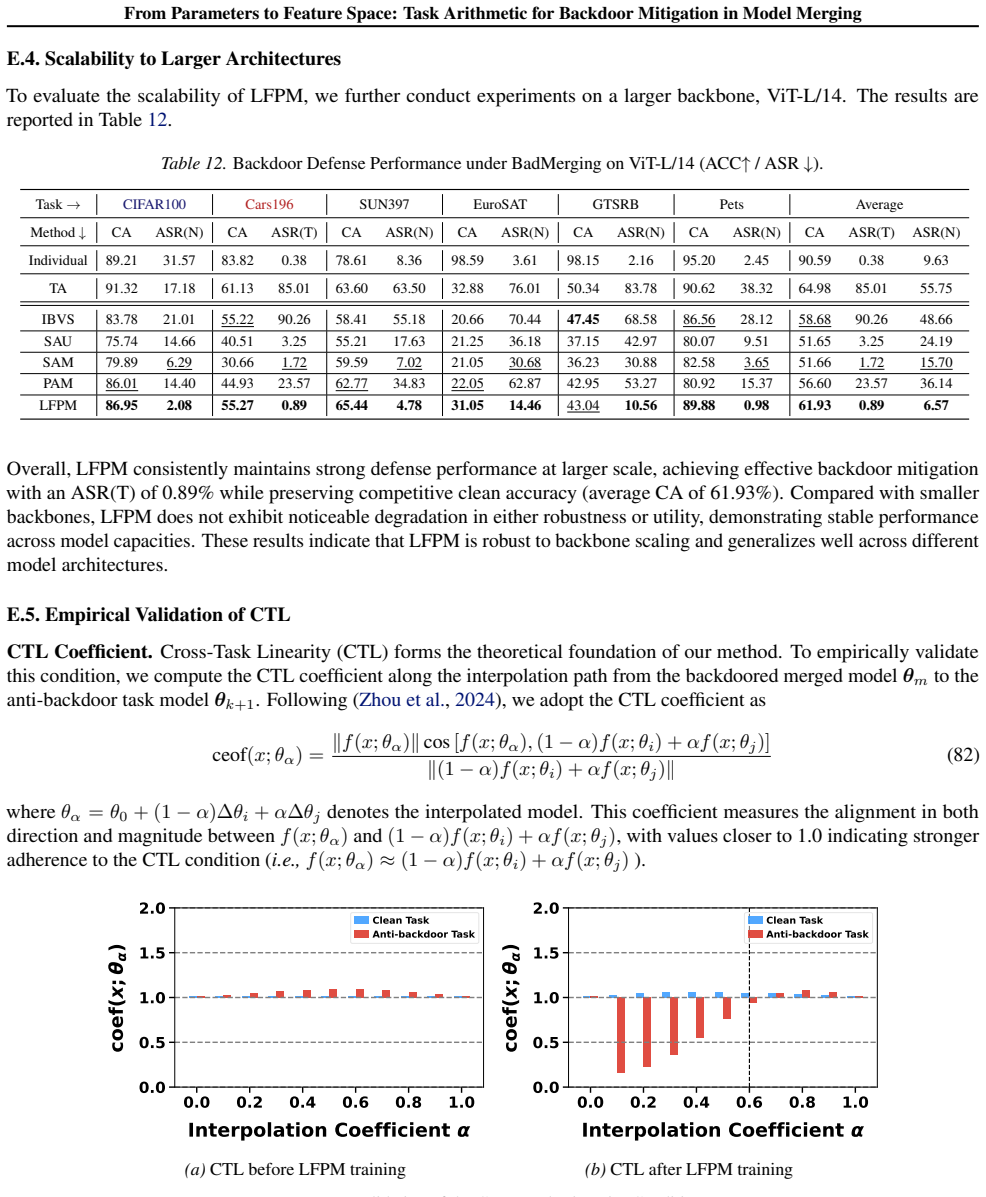
read the original abstract
Model merging (MM) has gained significant attention as a cost-effective approach to integrate multiple task-specific models into a unified model. However, recent work reveals that MM is highly susceptible to backdoor attacks. Existing defenses based on task arithmetic often fail to eliminate backdoors without substantially degrading clean-task performance, owing to their reliance on direct parameter-space editing. To address this gap, we propose Linear Feature Path Minimization (LFPM), a backdoor mitigation framework for model merging, which introduces an anti-backdoor task vector into the backdoored merged model. Unlike prior approaches, LFPM formulates the backdoor robustness of the merged model from a unified feature-space perspective under the Cross-Task Linearity (CTL) framework, which leverages the approximate linearity of features across tasks. This perspective guides the optimization of the anti-backdoor task to suppress backdoors while preserving clean-task performance. Furthermore, we introduce an effective optimization mechanism based on gradient accumulation and loss path-integral, ensuring robust backdoor suppression along the interpolation path. Extensive experiments demonstrate that LFPM consistently exhibits strong robustness against backdoor attacks in both full fine-tuning and Parameter-Efficient Fine-Tuning (PEFT) settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Linear Feature Path Minimization (LFPM), a framework for mitigating backdoors in model merging. It shifts from direct parameter-space task arithmetic to a feature-space formulation under the Cross-Task Linearity (CTL) assumption, introducing an optimized 'anti-backdoor task vector' that suppresses backdoor triggers while preserving clean-task performance. The optimization uses gradient accumulation and path-integral loss to ensure robustness along the interpolation path. Experiments are claimed to show consistent robustness in both full fine-tuning and PEFT settings.
Significance. If the CTL approximation holds for backdoor inputs, LFPM offers a conceptually cleaner alternative to existing parameter-editing defenses by grounding mitigation in feature-space linearity. This could improve the clean/backdoor trade-off in merged models and generalize to PEFT scenarios. The introduction of the anti-backdoor task vector and path-integral optimization are concrete technical contributions that, if validated, would strengthen the task-arithmetic literature on security.
major comments (2)
- [§3] §3 (CTL framework and anti-backdoor task vector): The central claim requires that approximate linearity of features across tasks continues to hold for backdoor-triggered inputs (which are OOD by design). No analysis, bound, or ablation is provided showing that the linearity error remains comparable on triggered examples versus clean ones; if the error grows, the feature-space loss minimization need not produce a merged model whose parameter-space behavior suppresses triggers.
- [§4] §4 (experiments): The abstract states that 'extensive experiments demonstrate consistent robustness,' yet the provided description contains no quantitative metrics, error bars, baseline comparisons, or details on backdoor success rate measurement. Without these, it is impossible to assess whether the reported robustness is robust to post-hoc exclusions or distribution shifts in the trigger set.
minor comments (1)
- [§3.1] Notation for the anti-backdoor task vector is introduced without an explicit equation linking it to the merged model parameters; adding a short derivation or pseudocode would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3] §3 (CTL framework and anti-backdoor task vector): The central claim requires that approximate linearity of features across tasks continues to hold for backdoor-triggered inputs (which are OOD by design). No analysis, bound, or ablation is provided showing that the linearity error remains comparable on triggered examples versus clean ones; if the error grows, the feature-space loss minimization need not produce a merged model whose parameter-space behavior suppresses triggers.
Authors: We agree that validating the CTL assumption specifically on backdoor-triggered inputs is essential, as these inputs are out-of-distribution by construction. The manuscript relies on the empirical observation that backdoor triggers are small perturbations and that feature linearity observed on clean tasks extends approximately to triggered inputs under the same model. However, we acknowledge the absence of a direct comparison of linearity error. In the revised manuscript we will add an ablation that computes the feature-space linearity error (as defined in the CTL framework) on both clean and triggered examples across the evaluated tasks and report whether the error remains comparable. This will either confirm the assumption or highlight its limitations. revision: yes
-
Referee: [§4] §4 (experiments): The abstract states that 'extensive experiments demonstrate consistent robustness,' yet the provided description contains no quantitative metrics, error bars, baseline comparisons, or details on backdoor success rate measurement. Without these, it is impossible to assess whether the reported robustness is robust to post-hoc exclusions or distribution shifts in the trigger set.
Authors: The full experimental section (Section 4) and appendix already contain quantitative results, baseline comparisons (including prior task-arithmetic defenses), backdoor success rates, and clean-task accuracy for both full fine-tuning and PEFT settings. Error bars from multiple random seeds are reported for the main tables. To improve clarity and address the concern about measurement details, we will expand the experimental subsection on evaluation protocol to explicitly describe how backdoor success rate is computed (including trigger-set construction and any distribution-shift tests performed) and ensure all numerical results are accompanied by standard deviations. revision: partial
Circularity Check
No circularity: derivation rests on external CTL modeling choice
full rationale
The paper's central construction introduces LFPM as an optimization in feature space guided by the Cross-Task Linearity (CTL) assumption. The provided text presents CTL as an imported modeling framework rather than a quantity defined from the same backdoor-suppression objective or fitted parameters. No equations are shown that equate the claimed robustness directly to a fit performed on the evaluation distribution, and no self-citation chain is invoked to justify uniqueness or the linearity premise. The derivation therefore remains self-contained against external benchmarks and does not reduce by construction to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Features extracted by task-specific models are approximately linear across tasks (Cross-Task Linearity framework).
invented entities (1)
-
Anti-backdoor task vector
no independent evidence
Reference graph
Works this paper leans on
-
[1]
T., Bhardwaj, R., and Poria, S
Deep, P. T., Bhardwaj, R., and Poria, S. Della-merging: Re- ducing interference in model merging through magnitude- based sampling.arXiv preprint arXiv:2406.11617,
-
[2]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo- gies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[3]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[4]
Sharpness-Aware Minimization for Efficiently Improving Generalization
Foret, P., Kleiner, A., Mobahi, H., and Neyshabur, B. Sharpness-aware minimization for efficiently improving generalization.arXiv preprint arXiv:2010.01412,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
Freeman, C. D. and Bruna, J. Topology and geometry of half-rectified network optimization.arXiv preprint arXiv:1611.01540,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Han, Z., Gao, C., Liu, J., Zhang, J., and Zhang, S. Q. Parameter-efficient fine-tuning for large models: A com- prehensive survey.arXiv preprint arXiv:2403.14608,
work page internal anchor Pith review Pith/arXiv arXiv
- [7]
-
[8]
Editing Models with Task Arithmetic
Ilharco, G., Ribeiro, M. T., Wortsman, M., Gururangan, S., Schmidt, L., Hajishirzi, H., and Farhadi, A. Editing mod- els with task arithmetic.arXiv preprint arXiv:2212.04089,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
10 From Parameters to Feature Space: Task Arithmetic for Backdoor Mitigation in Model Merging Pawlak, S., Dubi´nski, J., Marczak, D., and Twardowski, B. Backdoor vectors: a task arithmetic view on backdoor attacks and defenses.arXiv preprint arXiv:2510.08016,
-
[10]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Lmsanitator: De- fending prompt-tuning against task-agnostic backdoors
Wei, C., Meng, W., Zhang, Z., Chen, M., Zhao, M., Fang, W., Wang, L., Zhang, Z., and Chen, W. Lmsanitator: De- fending prompt-tuning against task-agnostic backdoors. arXiv preprint arXiv:2308.13904, 2023a. Wei, S., Zhang, M., Zha, H., and Wu, B. Shared adversarial unlearning: Backdoor mitigation by unlearning shared adversarial examples. InAdvances in Neu...
- [12]
-
[13]
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities
Yang, E., Shen, L., Guo, G., Wang, X., Cao, X., Zhang, J., and Tao, D. Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities.arXiv preprint arXiv:2408.07666,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Lobam: Lora-based backdoor attack on model merging
Yin, M., Zhang, J., Sun, J., Fang, M., Li, H., and Chen, Y . Lobam: Lora-based backdoor attack on model merging. arXiv preprint arXiv:2411.16746,
-
[15]
Yuan, Z., Xu, Y ., Shi, J., Zhou, P., and Sun, L. Merge hijack- ing: Backdoor attacks to model merging of large language models.arXiv preprint arXiv:2505.23561,
-
[16]
Badmerging: Backdoor attacks against model merging
Zhang, J., Chi, J., Li, Z., Cai, K., Zhang, Y ., and Tian, Y . Badmerging: Backdoor attacks against model merging. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pp. 4450–4464,
2024
-
[17]
Zhou, Z., Chen, Z., Chen, Y ., Zhang, B., and Yan, J. On the emergence of cross-task linearity in the pretraining- finetuning paradigm.arXiv preprint arXiv:2402.03660,
-
[18]
14 From Parameters to Feature Space: Task Arithmetic for Backdoor Mitigation in Model Merging B.4. Curvature Evaluation via Hessian–Vector Products (HVPs) Algorithm 4Curvature Evaluation via Hessian–Vector Products (HVPs) 1: Input:Backdoored merged model θm; Anti-backdoor model θk+1; Number of mini-batches N; Adversarial dataset Dadv; Finite-difference st...
2019
-
[19]
Acura RL Sedan 2012
under parameter-efficient fine-tuning (PEFT) with LoRA. In all attack settings, the adversary injects a backdoor via adversary task vector, such that the triggered samples from the target task are misclassified into an attacker-specified target class. By default, we set class 1 as the target for all target tasks; for example, in the task sequences reporte...
2012
-
[20]
targets low-resource adversarial settings by fine-tuning pre-trained models with LoRA. To compensate for the reduced attack effectiveness under PEFT, LoBAM amplifies the backdoor task vector, defined as the parameter difference between the backdoored and clean models, thereby enabling effective backdoor implantation for model merging. Following prior work...
2025
-
[21]
IBVS.IBVS (Pawlak et al.,
and PAM (Min et al., 2024), which enhance robustness by minimizing loss sharpness through weight perturbations during optimization. IBVS.IBVS (Pawlak et al.,
2024
-
[22]
to obtain the backdoor task vector Vb and clean task vector Vc. Given a merged model update ∆θm, the refined update is computed as ∆θ ′ m = ∆θm −λ(V b −V c).(81) After hyperparameter tuning, we set λ= 2.0 , which provides a favorable balance between backdoor mitigation and clean performance preservation. SAU.SAU (Wei et al., 2023b) is a state-of-the-art b...
2025
-
[23]
comprises two stages: (I) Adversarial Feature Extraction via Subspace Partitioning and (II) Anti-Backdoor Task Vector Optimization. In Stage I, LFPM learns a rank- r projection matrix Ps =U U T to partition the feature subspace and extract adversarial features encoded by learnable visual prompts P (Zhou et al., 2022; Jia et al., 2022). In our experiments,...
2022
-
[24]
The anti-backdoor task vector is optimized for 5 epochs
The optimization is performed on a shadow dataset consisting of 10,000 images randomly sampled from ImageNet-1K (Deng et al., 2009). The anti-backdoor task vector is optimized for 5 epochs. In every optimization step, the above three mechanisms are executed once. Finally, following Step 10 of Algorithm B.1, LFPM merges the anti-backdoor task vector into t...
2009
-
[25]
Table 12.Backdoor Defense Performance under BadMerging on ViT-L/14 (ACC↑/ ASR↓). Task→ CIFAR100 Cars196 SUN397 EuroSAT GTSRB Pets Average Method↓ CA ASR(N) CA ASR(T) CA ASR(N) CA ASR(N) CA ASR(N) CA ASR(N) CA ASR(T) ASR(N) Individual89.21 31.57 83.82 0.38 78.61 8.36 98.59 3.61 98.15 2.16 95.20 2.45 90.59 0.38 9.63 TA 91.32 17.18 61.13 85.01 63.60 63.50 32...
2024
-
[26]
without explicitly constructing the Hessian. Fellowing Pearlmutter (Pearlmutter, 1994), a Hessian-vector product⟨∇ 2f(θ), v⟩can be computed as the directional derivative of the gradient alongv: ∇2f(θ)v= lim ϵ→0 1 ϵ h ∇f(θ+ϵv)− ∇f(θ) i =∇ θ ⟨∇f(θ), v⟩ .(84) This enables efficient computation via automatic differentiation at a small overhead relative to the...
1994
-
[27]
This stability is attributed to the smoothing effect of LFPM, which progressively reduces the effective curvature λeff from 5.47 to 0.22
Table 13.Evolution of Curvatureλ eff throughout Training Epoch 0 1 2 3 4 5 δT Hδ 1.81 1.40 2.32 2.21 1.75 1.53 ∥δ∥2 0.33 1.38 2.89 3.72 5.18 6.85 λeff 5.47 1.01 0.80 0.59 0.34 0.22 From Table 13, we observe that although the parameter distance ∥δ∥2 enlarges nearly 20-fold (6.85/0.33), the CTL deviation remains tightly bounded. This stability is attributed...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.