From Imitation to Alignment: Human-Preference Flow Policies for Long-Horizon Sidewalk Navigation
Pith reviewed 2026-06-27 09:28 UTC · model grok-4.3
The pith
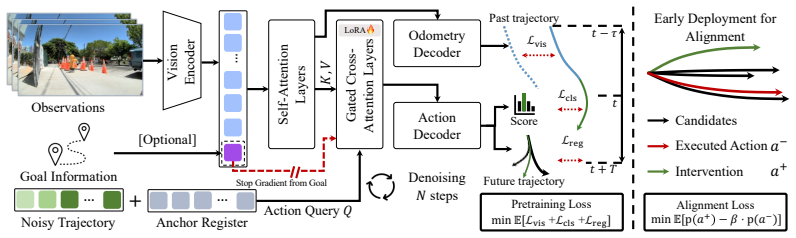
FlowPilot pre-trains a sidewalk navigation policy with anchored flow matching on robot fleet data then aligns it via human preference tuning on intervention data to handle long-horizon tasks with only a monocular camera.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlowPilot achieves robust and efficient long-horizon navigation performance using only a monocular RGB camera. Anchored flow matching serves as the action representation for policy pre-training on large-scale robot fleet data to capture the diverse, complex, multimodal distribution of sidewalk navigation behaviors. A subsequent human-in-the-loop preference learning scheme tunes the policy on a small amount of human intervention data, strengthening counterfactual reasoning and social compliance on sidewalks.
What carries the argument
Anchored flow matching as the action representation for pre-training, combined with human-in-the-loop preference learning on intervention data for alignment.
If this is right
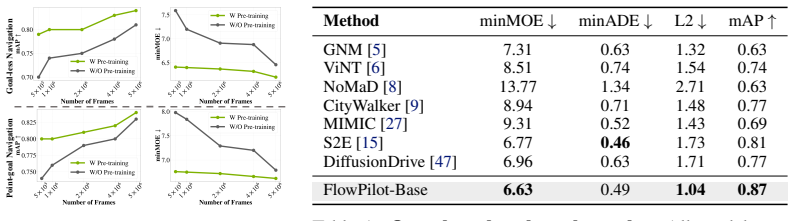
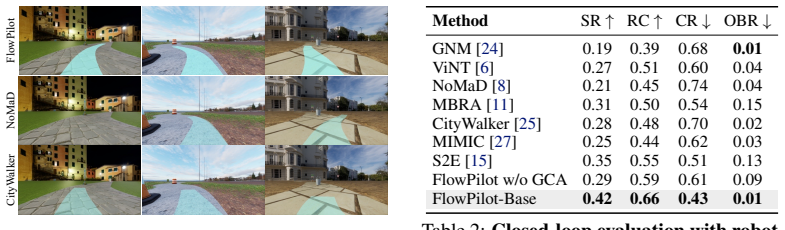
- FlowPilot reaches 42 percent success rate and 66 percent route completion in simulation.
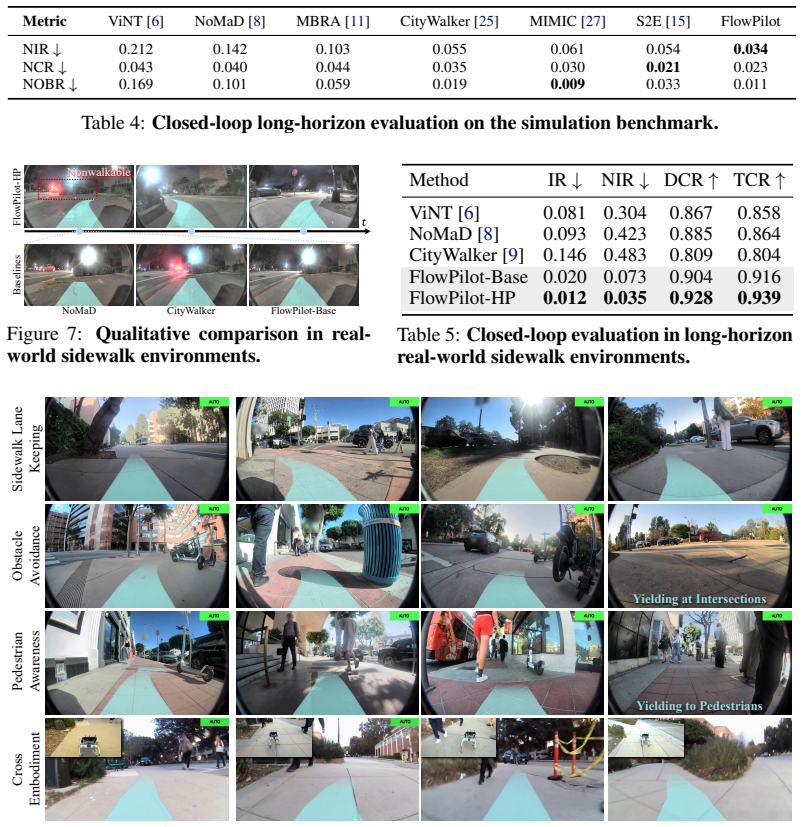
- FlowPilot-HP reduces intervention rate by 40.0 percent and near-miss intervention rate by 52.1 percent relative to the base model in real-world tests.
- The preference-tuned policy improves real-world robustness and social compliance over imitation-only training.
Where Pith is reading between the lines
- The two-stage recipe could be applied to other long-horizon robotic tasks that require social awareness, such as indoor service robots.
- Small preference datasets may suffice to correct imitation failures in many navigation domains, lowering the cost of human data collection.
- The monocular-camera constraint suggests the method might combine with additional low-cost sensors without redesigning the core policy architecture.
Load-bearing premise
The small amount of human intervention data is representative enough to strengthen counterfactual reasoning and social compliance without introducing new biases or distribution shifts that degrade performance on unseen sidewalk scenarios.
What would settle it
A controlled test on a new collection of diverse sidewalk routes where the human-preference-tuned policy shows higher intervention rates or lower success than the base FlowPilot model would falsify the alignment benefit.
Figures












read the original abstract
Autonomous long-horizon sidewalk navigation is essential for micro-mobility applications such as robotic food delivery and assistive electronic wheelchairs. Unlike autonomous driving on the road, long-horizon sidewalk navigation requires precise maneuvering through unpredictable sidewalk terrains and pedestrians, with a lightweight perception stack as minimal as a single monocular RGB camera. While imitation learning (IL) from demonstrations offers a practical solution, the resulting autopilot policy often suffers from compounding errors, a lack of social compliance on sidewalks, and deficiencies in counterfactual reasoning to handle complex situations. To address these challenges, we introduce FlowPilot, a mapless navigation policy that achieves robust and efficient long-horizon navigation performance using only a monocular RGB camera. We first propose to use anchored flow matching as an action representation for policy pre-training on large-scale robot fleet data and to capture the diverse, complex, multimodal distribution of sidewalk navigation behaviors. To bridge the gap between imitation and alignment, we further design a human-in-the-loop preference learning scheme to tune the policy on a small amount of human intervention data. It strengthens the model's counterfactual reasoning and social compliance on sidewalks. We evaluate FlowPilot through extensive simulation and real-world experiments in diverse sidewalk environments. FlowPilot achieves 42% success rate and 66% route completion in simulation, while FlowPilot-HP further improves real-world robustness and social compliance, reducing IR by 40.0% and NIR by 52.1% relative to the base model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlowPilot, a mapless long-horizon sidewalk navigation policy that relies solely on monocular RGB input. It pre-trains an anchored flow-matching policy on large-scale robot fleet demonstrations to capture multimodal behaviors, then applies human-in-the-loop preference tuning on a small set of human intervention trajectories to improve counterfactual reasoning and social compliance. Simulation results are reported as 42% success rate and 66% route completion; the preference-tuned FlowPilot-HP variant is claimed to reduce real-world intervention rate (IR) by 40.0% and near-intervention rate (NIR) by 52.1% relative to the base model.
Significance. If the reported gains are shown to be robust and not artifacts of uncharacterized data shifts, the two-stage imitation-to-alignment pipeline would constitute a practical advance for lightweight, camera-only navigation in unstructured pedestrian environments. The use of flow matching as an action representation and the explicit human-preference stage are technically interesting; however, the absence of baseline comparisons, statistical reporting, and data-coverage metrics in the provided abstract substantially weakens the ability to judge whether the central claim holds.
major comments (2)
- [Abstract] Abstract: the headline numerical claims (42% success, 66% route completion; IR −40.0%, NIR −52.1%) are presented without any baseline algorithms, statistical significance tests, definitions of success/interruption, or data-exclusion criteria. These quantities are load-bearing for the central claim that FlowPilot-HP improves robustness and social compliance.
- [Abstract] Abstract / evaluation description: the human-intervention dataset is characterized only as “small” with no quantitative information on its size, diversity, coverage of pedestrian/terrain types, or distributional overlap with the test sidewalks. This directly bears on the assumption that preference tuning strengthens counterfactual reasoning without introducing new biases or failure modes.
minor comments (1)
- [Abstract] The abstract refers to “anchored flow matching” and “human-preference flow policies” without a brief parenthetical gloss on the key technical distinction from standard flow matching or behavioral cloning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the abstract accordingly to improve clarity and completeness while preserving the manuscript's core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline numerical claims (42% success, 66% route completion; IR −40.0%, NIR −52.1%) are presented without any baseline algorithms, statistical significance tests, definitions of success/interruption, or data-exclusion criteria. These quantities are load-bearing for the central claim that FlowPilot-HP improves robustness and social compliance.
Authors: We agree the abstract would benefit from additional context. In revision we will add concise references to the baseline algorithms evaluated in the full paper (standard behavior cloning and other IL policies), note that metrics are averaged over multiple random seeds with statistical details reported in Section 5, and include brief definitions of success rate, route completion, IR, and NIR along with data-exclusion criteria from the experimental protocol. revision: yes
-
Referee: [Abstract] Abstract / evaluation description: the human-intervention dataset is characterized only as “small” with no quantitative information on its size, diversity, coverage of pedestrian/terrain types, or distributional overlap with the test sidewalks. This directly bears on the assumption that preference tuning strengthens counterfactual reasoning without introducing new biases or failure modes.
Authors: We acknowledge that 'small' is insufficiently precise in the abstract. We will revise to report the dataset size (number of trajectories and interventions), note coverage across pedestrian densities and terrain types, and reference the distributional analysis already present in Section 4.2 that demonstrates overlap with test environments and supports improved counterfactual reasoning without new failure modes. revision: yes
Circularity Check
No circularity: results are measured experimental outcomes
full rationale
The paper reports performance metrics (42% success rate, 66% route completion, IR/NIR reductions) as direct measurements from simulation and real-world experiments on policies trained with anchored flow matching pre-training followed by human-in-the-loop preference tuning. These quantities are not derived by construction from the paper's own equations, fitted parameters, or self-referential definitions. No load-bearing self-citations, uniqueness theorems, or ansatzes that reduce the central claims to inputs appear in the provided text. The evaluation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Engesser, E
V . Engesser, E. Rombaut, L. Vanhaverbeke, and P. Lebeau. Autonomous delivery solutions for last-mile logistics operations: A literature review and research agenda.Sustainability, 15(3): 2774, 2023
2023
-
[2]
X. Liu, L. Zhang, and T. Zhu. Service robots in my workplace: Effects of employee-service robot co-work experiences on psychological empowerment.Journal of Hospitality Marketing & Management, 34(2):175–203, 2025
2025
-
[3]
Tuomi, I
A. Tuomi, I. P. Tussyadiah, and J. Stienmetz. Applications and implications of service robots in hospitality.Cornell Hospitality Quarterly, 62(2):232–247, 2021
2021
-
[4]
Arntz, J
E. Arntz, J. Van Duin, A. Van Binsbergen, L. Tavasszy, and T. Klein. Assessment of readiness of a traffic environment for autonomous delivery robots.Frontiers in Future Transportation, 4:1102302, 2023
2023
- [5]
- [6]
-
[7]
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 17853–17862, 2023
2023
-
[8]
Sridhar, D
A. Sridhar, D. Shah, C. Glossop, and S. Levine. Nomad: Goal masked diffusion policies for navigation and exploration. In2024 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 63–70. IEEE, 2024
2024
- [9]
-
[10]
B. D. Argall, S. Chernova, M. Veloso, and B. Browning. A survey of robot learning from demonstration.Robotics and autonomous systems, 57(5):469–483, 2009
2009
-
[11]
Hirose, L
N. Hirose, L. Ignatova, K. Stachowicz, C. Glossop, S. Levine, and D. Shah. Learning to drive anywhere with model-based reannotation.IEEE Robotics and Automation Letters, 11(2): 1242–1249, 2025
2025
-
[12]
Karnan, A
H. Karnan, A. Nair, X. Xiao, G. Warnell, S. Pirk, A. Toshev, J. Hart, J. Biswas, and P. Stone. Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022
2022
-
[13]
X. Pan, T. Zhang, B. Ichter, A. Faust, J. Tan, and S. Ha. Zero-shot imitation learning from demonstrations for legged robot visual navigation. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 679–685. IEEE, 2020
2020
-
[14]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[15]
H. He, Y . Ma, W. Wu, and B. Zhou. From seeing to experiencing: Scaling navigation founda- tion models with reinforcement learning.arXiv preprint arXiv:2507.22028, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011. 10
2011
-
[17]
Celemin, R
C. Celemin, R. P ´erez-Dattari, E. Chisari, G. Franzese, L. de Souza Rosa, R. Prakash, Z. Ajanovi´c, M. Ferraz, A. Valada, J. Kober, et al. Interactive imitation learning in robotics: A survey.Foundations and Trends® in Robotics, 10(1-2):1–197, 2022
2022
-
[18]
Z. M. Peng, W. Mo, C. Duan, Q. Li, and B. Zhou. Learning from active human involvement through proxy value propagation.Advances in neural information processing systems, 36: 77969–77992, 2023
2023
-
[19]
H. Cai, Z. Peng, and B. Zhou. Predictive preference learning from human interventions. In Advances in Neural Information Processing Systems, 2025
2025
-
[20]
D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[21]
Training language models to follow instructions with human feedback
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://arxiv.org/abs/2305. 18290
2023
-
[23]
S. Thrun. Probabilistic robotics.Communications of the ACM, 45(3):52–57, 2002
2002
-
[24]
D. Shah, A. Sridhar, A. Bhorkar, N. Hirose, and S. Levine. Gnm: A general navigation model to drive any robot. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 7226–7233. IEEE, 2023
2023
-
[25]
X. Liu, J. Li, Y . Jiang, N. Sujay, Z. Yang, J. Zhang, J. Abanes, J. Zhang, and C. Feng. City- walker: Learning embodied urban navigation from web-scale videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6875–6885, 2025
2025
- [26]
- [27]
- [28]
-
[29]
arXiv preprint arXiv:2412.04453 (2024)
A.-C. Cheng, Y . Ji, Z. Yang, Z. Gongye, X. Zou, J. Kautz, E. Bıyık, H. Yin, S. Liu, and X. Wang. Navila: Legged robot vision-language-action model for navigation.arXiv preprint arXiv:2412.04453, 2024
- [30]
- [31]
-
[32]
Kretzschmar, M
H. Kretzschmar, M. Spies, C. Sprunk, and W. Burgard. Socially compliant mobile robot navi- gation via inverse reinforcement learning.The International Journal of Robotics Research, 35 (11):1289–1307, 2016. 11
2016
-
[33]
Ho and S
J. Ho and S. Ermon. Generative adversarial imitation learning.Advances in neural information processing systems, 29, 2016
2016
-
[34]
B. D. Ziebart, A. L. Maas, J. A. Bagnell, A. K. Dey, et al. Maximum entropy inverse reinforce- ment learning. InAaai, volume 8, pages 1433–1438. Chicago, IL, USA, 2008
2008
-
[35]
G. Seneviratne, J. An, S. Ellahy, K. Weerakoon, M. B. Elnoor, J. D. Kannan, A. T. Sunil, and D. Manocha. Halo: Human preference aligned offline reward learning for robot navigation. arXiv preprint arXiv:2508.01539, 2025
-
[36]
H. Cai, Z. Peng, and B. Zhou. Robot-gated interactive imitation learning with adaptive inter- vention mechanism. InInternational Conference on Machine Learning, 2025
2025
-
[37]
Sadigh, A
D. Sadigh, A. D. Dragan, S. S. Sastry, and S. A. Seshia. Active preference-based learning of reward functions. InRobotics: Science and Systems, 2017
2017
-
[38]
J. Choi, C. Dance, J.-e. Kim, K.-s. Park, J. Han, J. Seo, and M. Kim. Fast adaptation of deep re- inforcement learning-based navigation skills to human preference. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 3363–3370. IEEE, 2020
2020
- [39]
-
[40]
R. Wang, W. Wang, and B.-C. Min. Feedback-efficient active preference learning for socially aware robot navigation. In2022 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 11336–11343. IEEE, 2022
2022
-
[41]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Y...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierar- chical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[44]
P. K. A. Vasu, J. Gabriel, J. Zhu, O. Tuzel, and A. Ranjan. Fastvit: A fast hybrid vision transformer using structural reparameterization. InProceedings of the IEEE/CVF international conference on computer vision, pages 5785–5795, 2023
2023
-
[45]
J. Liu, G. Liu, J. Liang, Y . Li, J. Liu, X. Wang, P. Wan, D. Zhang, and W. Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
J. Liu, G. Liu, J. Liang, Z. Yuan, X. Liu, M. Zheng, X. Wu, Q. Wang, M. Xia, X. Wang, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
2025
-
[48]
P. E. Hart, N. J. Nilsson, and B. Raphael. A formal basis for the heuristic determination of minimum cost paths.IEEE transactions on Systems Science and Cybernetics, 4(2):100–107, 1968. 12
1968
-
[49]
Zhang, C
A. Zhang, C. Eranki, C. Zhang, J.-H. Park, R. Hong, P. Kalyani, L. Kalyanaraman, A. Gamare, A. Bagad, M. Esteva, et al. Toward robust robot 3-d perception in urban environments: The ut campus object dataset.IEEE Transactions on Robotics, 40:3322–3340, 2024
2024
-
[50]
EgoWalk: A Multimodal Dataset for Robot Navigation in the Wild
T. Akhtyamov, M. A. Mdfaa, J. A. R. Benavides, A. Nigmatzyanov, S. Bakulin, G. Devchich, D. Fatykhov, D. R. Salinas, A. Mazurov, K. Zipa, et al. Egowalk: A multimodal dataset for robot navigation in the wild.arXiv preprint arXiv:2505.21282, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Liang, D
J. Liang, D. Das, D. Song, M. N. H. Shuvo, M. Durrani, K. Taranath, I. Penskiy, D. Manocha, and X. Xiao. Gnd: Global navigation dataset with multi-modal perception and multi-category traversability in outdoor campus environments. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 2383–2390. IEEE, 2025
2025
-
[52]
Hirose, D
N. Hirose, D. Shah, A. Sridhar, and S. Levine. Sacson: Scalable autonomous control for social navigation.IEEE Robotics and Automation Letters, 9(1):49–56, 2023
2023
-
[53]
D. M. Nguyen, M. Nazeri, A. Payandeh, A. Datar, and X. Xiao. Toward human-like so- cial robot navigation: A large-scale, multi-modal, social human navigation dataset. In2023 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 7442–
-
[54]
Dauner, M
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, et al. Navsim: Data-driven non-reactive autonomous vehicle sim- ulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706– 28719, 2024
2024
-
[55]
Physicalai autonomous vehicles dataset.https://huggingface
NVIDIA Corporation. Physicalai autonomous vehicles dataset.https://huggingface. co/datasets/nvidia/PhysicalAI-Autonomous-Vehicles, 2025. Hugging Face dataset. Accessed: 2026-06-10
2025
-
[56]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[57]
Kelly, C
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. Hg-dagger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019
2019
-
[58]
Menda, K
K. Menda, K. Driggs-Campbell, and M. J. Kochenderfer. Ensembledagger: A bayesian ap- proach to safe imitation learning. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5041–5048. IEEE, 2019
2019
-
[59]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Munoz, X. Yao, R. Zurbr ¨ugg, N. Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi- modal robot learning.arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
W. Wu, H. He, C. Zhang, J. He, S. Z. Zhao, R. Gong, Q. Li, and B. Zhou. Towards autonomous micromobility through scalable urban simulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27553–27563, 2025
2025
-
[61]
Ettinger, S
S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y . Chai, B. Sapp, C. R. Qi, Y . Zhou, et al. Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset. InProceedings of the IEEE/CVF international conference on computer vision, pages 9710–9719, 2021
2021
-
[62]
Zhang, H
A. Zhang, H. Sikchi, A. Zhang, and J. Biswas. Creste: Scalable mapless navigation with internet scale priors and counterfactual guidance. InRobotics: Science and Systems (RSS), 2025
2025
-
[63]
Van Den Berg, S
J. Van Den Berg, S. J. Guy, M. Lin, and D. Manocha. Reciprocal n-body collision avoidance. InRobotics research: the 14th international symposium ISRR, pages 3–19. Springer, 2011. 13 Appendix We organize the appendix as follows. We first introduce the demonstration video in Sec. A, followed by additional real-world results in Sec. B. We then provide additi...
2011
-
[64]
FlowPilot capabilities demonstrationFlowPilot demonstrates robust navigation in complex real-world sidewalk environments. It successfully negotiates narrow passages, cluttered layouts, and broken curbs while maintaining safe and socially compliant behaviors, including effective obstacle avoidance and pedestrian awareness
-
[65]
Long-horizon sidewalk navigationFlowPilot completes GPS-guided long-horizon navigation with only a few human interventions. It maintains stable sidewalk lane keeping and consistent goal progress over time, while remaining robust to lighting changes and transient disturbances in challenging sidewalk environments
-
[66]
The comparisons highlight the advan- tages of FlowPilot in trajectory smoothness, navigation stability, and safety
Comparison with SOTA methodsWe present side-by-side real-world evaluations against rep- resentative state-of-the-art methods under the same setting. The comparisons highlight the advan- tages of FlowPilot in trajectory smoothness, navigation stability, and safety
-
[67]
Cross-embodiment generalityFlowPilot transfers effectively across different robot platforms both without finetuning and with only a few embodiment-specific examples. It preserves reasonable navigation behaviors under changes in platform dynamics and sensing configurations, demonstrating strong generalization and rapid adaptation across embodiments. B Real...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.