Deployment-Centered Evaluation: Predicting Query-Level Rejection Risk in a Clinical LLM System
Pith reviewed 2026-06-27 09:41 UTC · model grok-4.3
The pith
Deployment context improves prediction of user rejection for clinical LLM responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
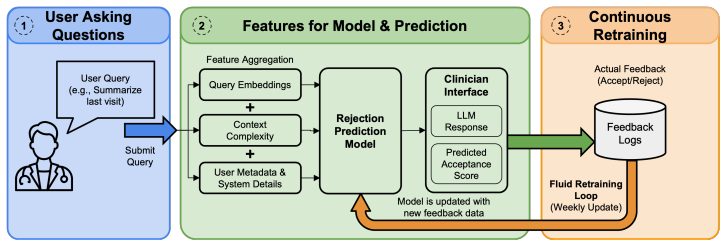
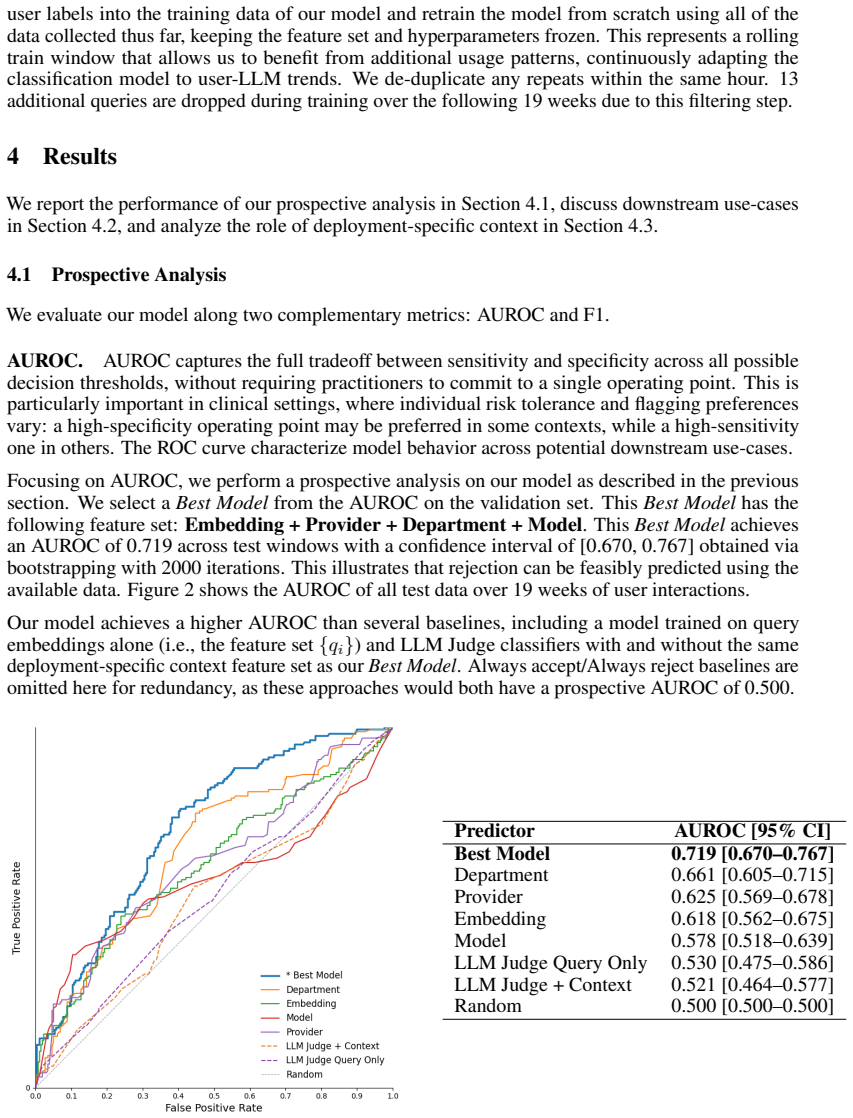
A pre-response classifier that combines query content with deployment-specific context (provider type, department name, language model) can predict whether a user will reject the LLM output, achieving an AUROC of 0.719 in a prospective 4.5-month analysis at an academic medical center. This context improves performance relative to query-only baselines, demonstrating the feasibility of deployment-centered evaluation that relies on sparse but authentic user feedback rather than static benchmarks.
What carries the argument
Pre-response classifier estimating rejection risk from query content plus deployment context available before generation.
If this is right
- Risk scores can be used to trigger targeted guardrails on queries predicted to be rejected.
- The system can abstain from generating responses for high-risk queries.
- Evaluation can shift from aggregate correctness metrics to query-level acceptance under real deployment conditions.
- The same approach applies to other LLM systems where user feedback is collected in the target environment.
Where Pith is reading between the lines
- The method could extend to non-clinical high-stakes domains that also collect sparse user feedback, such as legal or financial assistants.
- Integrating the rejection predictor with model selection or prompt adaptation might further reduce rejection rates.
- Longer-term deployment data might reveal whether rejection patterns shift as users adapt to the system.
Load-bearing premise
Sparse user feedback closely reflects the actual conditions and acceptance patterns of the live clinical deployment.
What would settle it
A replication in which adding deployment context to the classifier produces no AUROC gain, or in which the resulting risk scores fail to improve guardrail or abstention outcomes when deployed.
Figures

read the original abstract
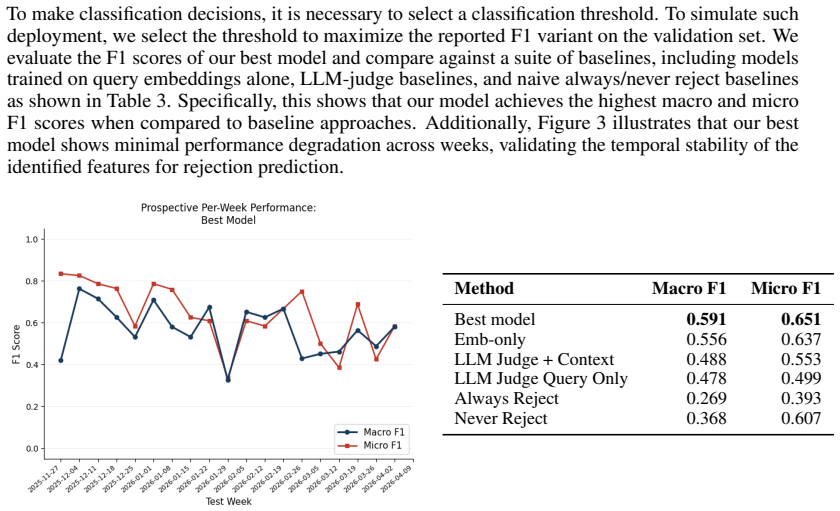
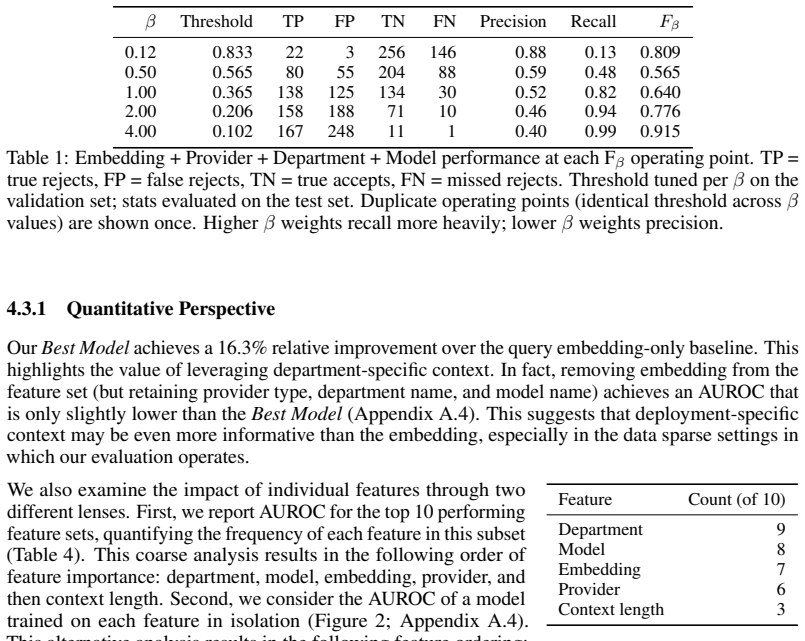
Large language models (LLMs) are increasingly integrated into clinical systems, making it essential to evaluate the real-world utility of these systems. However, static benchmarks tend to measure correctness rather than user acceptance, aggregate performance across queries, and require densely annotated datasets -- leading to major blind spots for evaluating clinical systems. In this work, we perform a deployment-centered evaluation of an LLM system embedded within electronic health records at an academic medical center, where user feedback is sparse but closely reflects the deployment conditions. Specifically, we train a pre-response classifier that estimates the risk that a future interaction will result in the user rejecting the LLM response, based on query content and deployment-specific context available before generation. We conduct a prospective analysis of our model over 4.5 months of user feedback, finding that our prediction model achieves an AUROC of 0.719. Further, we estimate the benefit of such predictions in two downstream use cases (guardrail triggering and abstention). Our key conceptual insight is that making use of deployment-specific context (i.e., the provider type, department name, language model used for response), as opposed to only query content, improves the ability to predict whether the user will reject the system output. Altogether, our empirical case study demonstrates the feasibility of predicting user rejection using deployment-specific context, opening the door to targeted guardrails.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a deployment-centered evaluation of an LLM system integrated into clinical EHR workflows. It trains a pre-response classifier to predict query-level user rejection risk using both query content and deployment-specific context features (provider type, department name, LM used), reports an AUROC of 0.719 on 4.5 months of prospective user feedback, and estimates downstream benefits for guardrail triggering and abstention. The central conceptual claim is that deployment context improves rejection prediction over query content alone.
Significance. If the empirical result holds after addressing label bias and providing missing methodological details, the work offers a concrete demonstration that real-world deployment logs can support rejection-risk modeling in clinical LLMs. The prospective analysis and focus on user acceptance (rather than static correctness) are strengths that address known blind spots in LLM evaluation. Credit is due for grounding the evaluation in actual sparse feedback from a live system.
major comments (2)
- [Abstract] Abstract: the reported AUROC of 0.719 is presented without any description of model architecture, feature definitions, baseline comparisons, sample size, confidence intervals, or exclusion criteria. These omissions make it impossible to assess whether the central performance claim is reproducible or robust.
- [Abstract] Abstract: the statement that 'user feedback is sparse but closely reflects the deployment conditions' is not accompanied by any analysis showing that feedback probability is independent of provider type, department, or LM. If feedback is non-random (e.g., more likely after rejection or in certain departments), then (a) the label distribution is biased and (b) the reported improvement from context features may simply reflect feedback propensity rather than genuine rejection risk. This directly undermines both the AUROC and the key conceptual insight.
minor comments (1)
- The manuscript would benefit from a table or section explicitly listing all input features, their encoding, and any preprocessing steps applied to the deployment logs.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key areas for improving the clarity and robustness of our abstract and evaluation. We address each point below and have made revisions to incorporate additional details and analysis as requested.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported AUROC of 0.719 is presented without any description of model architecture, feature definitions, baseline comparisons, sample size, confidence intervals, or exclusion criteria. These omissions make it impossible to assess whether the central performance claim is reproducible or robust.
Authors: We agree that the abstract's brevity limits immediate assessment of the performance claim. The full manuscript details the model (a classifier incorporating query content features and deployment context), feature definitions, baselines, sample size, confidence intervals, and exclusion criteria in the Methods and Results sections. To address this, we have revised the abstract to include a concise description of the model type, sample size, and reference to the reported baselines and intervals, while maintaining length constraints. Full reproducibility information remains in the body of the paper. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'user feedback is sparse but closely reflects the deployment conditions' is not accompanied by any analysis showing that feedback probability is independent of provider type, department, or LM. If feedback is non-random (e.g., more likely after rejection or in certain departments), then (a) the label distribution is biased and (b) the reported improvement from context features may simply reflect feedback propensity rather than genuine rejection risk. This directly undermines both the AUROC and the key conceptual insight.
Authors: We acknowledge this as a substantive concern about potential selection bias in the sparse feedback labels. The original manuscript does not include an explicit analysis of feedback independence from the context variables. In revision, we have added a new analysis in the Methods section examining feedback rates across provider types, departments, and LMs, along with statistical tests for dependence. This supports that feedback propensity does not substantially confound the context features' contribution to rejection prediction. We have also expanded the Limitations section to discuss this issue and its implications for interpreting the AUROC and conceptual claim. revision: yes
Circularity Check
No circularity; standard empirical classifier on held-out deployment logs
full rationale
The paper trains and evaluates a pre-response classifier on real deployment logs with a prospective 4.5-month holdout, reporting AUROC 0.719. No equations, self-definitions, or self-citations reduce the reported performance metric to a fitted parameter or input by construction. The central claim (value of deployment context features) is tested via standard feature-ablation on external data rather than being presupposed. Feedback sparsity is noted but does not create a definitional loop in the reported metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User rejection serves as a valid proxy for real-world utility of the LLM response
Reference graph
Works this paper leans on
-
[1]
Large language models in real-world clinical workflows: a systematic review of applications and implementation.Frontiers in Digital Health, 7:1659134, 2025
Yaara Artsi, Vera Sorin, Benjamin S Glicksberg, Panagiotis Korfiatis, Girish N Nadkarni, and Eyal Klang. Large language models in real-world clinical workflows: a systematic review of applications and implementation.Frontiers in Digital Health, 7:1659134, 2025
2025
-
[2]
doi:10.1038/s41746-025-01670-7 , issn =
Elham Asgari, Nina Montaña-Brown, Magda Dubois, Saleh Khalil, Jasmine Balloch, Joshua Au Yeung, and Dominic Pimenta. A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation.npj Digital Medicine, 8(1), may 13 2025. ISSN 2398-6352. doi: 10.1038/s41746-025-01670-7. URL http://dx.doi.org/10.1038/ s41746-025-01670-7
-
[3]
Suhana Bedi, Yutong Liu, Lucy Orr-Ewing, Dev Dash, Sanmi Koyejo, Alison Callahan, Jason A Fries, Michael Wornow, Akshay Swaminathan, Lisa Soleymani Lehmann, Hyo Jung Hong, Mehr Kashyap, Akash R Chaurasia, Nirav R Shah, Karandeep Singh, Troy Tazbaz, Arnold Milstein, Michael A Pfeffer, and Nigam H Shah. Testing and evaluation of health care applications of ...
-
[4]
Suhana Bedi, Hejie Cui, Miguel Fuentes, Alyssa Unell, Michael Wornow, Juan M. Banda, Nikesh Kotecha, Timothy Keyes, Yifan Mai, Mert Oez, Hao Qiu, Shrey Jain, Leonardo Schet- tini, Mehr Kashyap, Jason Alan Fries, Akshay Swaminathan, Philip Chung, Fateme Nateghi Haredasht, Ivan Lopez, Asad Aali, Gabriel Tse, Ashwin Nayak, Shivam Vedak, Sneha S. Jain, Birju ...
-
[5]
CARE: A Conformal Safety Layer for Medical Summarization
Suhana Bedi, Bridget Lin, Anson Y . Zhou, Chloe O. Stanwyck, Jenelle A. Jindal, Sanmi Koyejo, David Stutz, and Nigam H. Shah. CARE: A conformal safety layer for medical summarization. arXiv preprint arXiv:2606.08969, 2026. doi: 10.48550/arXiv.2606.08969. 10
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.08969 2026
-
[6]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolaos Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael I. Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating llms by human preference.arXiv preprint arXiv:2403.04132, 2024
Pith/arXiv arXiv 2024
-
[7]
Chun En Chua, Ngoh Lee Ying Clara, Mohammad Shaheryar Furqan, James Lee Wai Kit, Andrew Makmur, Yih Chung Tham, Amelia Santosa, and Kee Yuan Ngiam. Integration of customised llm for discharge summary generation in real-world clinical settings: a pilot study on russell gpt.The Lancet Regional Health–Western Pacific, 51:101211, 2024. doi: 10.1016/j.lanwpc.2...
-
[8]
Philip Chung, Akshay Swaminathan, Alex J. Goodell, Yeasul Kim, S. Momsen Reincke, Lichy Han, Ben Deverett, Mohammad Amin Sadeghi, Abdel-Badih Ariss, Marc Ghanem, David Seong, Andrew A. Lee, Caitlin E. Coombes, Brad Bradshaw, Mahir A. Sufian, Hyo Jung Hong, Teresa P. Nguyen, Mohammad R. Rasouli, Komal Kamra, Mark A. Burbridge, James C. McAvoy, Roya Saffary...
arXiv 2025
-
[9]
Implementation of large language models in electronic health records.PLOS Digital Health, 2025
Maxime Griot, Jean Vanderdonckt, and Demet Yuksel. Implementation of large language models in electronic health records.PLOS Digital Health, 2025. doi: 10.1371/journal.pdig.0001141. URLhttps://doi.org/10.1371/journal.pdig.0001141
-
[10]
Liang, Timothy Keyes, Stephen P
Francois Grolleau, April S. Liang, Timothy Keyes, Stephen P. Ma, Thomas Lew, Tridu R. Huynh, Natasha Steele, Philip Chung, Paige Qin, Gowri Chandra, Stephanie F. Wang, Evan Mullen, Lauren Carpenter, Mita Hoppenfeld, Matthew Morrin, Baffour A. Kyerematen, Nerissa Ambers, Nikesh Kotecha, Emily Alsentzer, Jason Hom, Nigam H. Shah, Kevin Schulman, and Jonatha...
-
[11]
Evalu- ation and mitigation of the limitations of large language models in clinical decision-making
Paul Hager, Friederike Jungmann, Robbie Holland, Kunal Bhagat, Inga Hubrecht, Manuel Knauer, Jakob Vielhauer, Marcus Makowski, Rickmer Braren, Georgios Kaissis, et al. Evalu- ation and mitigation of the limitations of large language models in clinical decision-making. Nature medicine, 30(9):2613–2622, 2024
2024
-
[12]
The practical implementation of artificial intelligence technologies in medicine.Nature medicine, 25(1): 30–36, 2019
Jianxing He, Sally L Baxter, Jie Xu, Jiming Xu, Xingtao Zhou, and Kang Zhang. The practical implementation of artificial intelligence technologies in medicine.Nature medicine, 25(1): 30–36, 2019
2019
-
[13]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[14]
Black, Gloria Geng, Danny Park, James Zou, Andrew Y
Yixing Jiang, Kameron C. Black, Gloria Geng, Danny Park, James Zou, Andrew Y . Ng, and Jonathan H. Chen. Medagentbench: A virtual ehr environment to benchmark medical llm agents.NEJM AI, 2(9), August 2025. ISSN 2836-9386. doi: 10.1056/aidbp2500144. URL http://dx.doi.org/10.1056/AIdbp2500144
-
[15]
An evaluation framework for clinical use of large language models in patient interaction tasks
Shreya Johri, Jaehwan Jeong, Benjamin A Tran, Daniel I Schlessinger, Shannon Wongvibulsin, Leandra A Barnes, Hong-Yu Zhou, Zhuo Ran Cai, Eliezer M Van Allen, David Kim, et al. An evaluation framework for clinical use of large language models in patient interaction tasks. Nature medicine, 31(1):77–86, 2025
2025
-
[16]
Sayash Kapoor, Peter Kirgis, Andrew Schwartz, Stephan Rabanser, J. J. Allaire, Rishi Bom- masani, Harry Coppock, Magda Dubois, Gillian K Hadfield, Andrew B. Hall, Sara Hooker, Seth Lazar, Steve Newman, Dimitris Papailiopoulos, Shoshannah Tekofsky, Helen Toner, Cozmin Ududec, and Arvind Narayanan. Open-world evaluations for measuring frontier ai capabilities,
-
[17]
URLhttps://arxiv.org/abs/2605.20520
-
[18]
E. Kilsdonk, L.W. Peute, and M.W.M. Jaspers. Factors influencing implementation success of guideline-based clinical decision support systems: A systematic review and gaps analysis. 11 International Journal of Medical Informatics, 98:56–64, 2017. ISSN 1386-5056. doi: https://doi. org/10.1016/j.ijmedinf.2016.12.001. URL https://www.sciencedirect.com/science...
-
[19]
Perfor- mance of chatgpt on usmle: potential for ai-assisted medical education using large language models.PLoS digital health, 2(2):e0000198, 2023
Tiffany H Kung, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepaño, Maria Madriaga, Rimel Aggabao, Giezel Diaz-Candido, James Maningo, et al. Perfor- mance of chatgpt on usmle: potential for ai-assisted medical education using large language models.PLoS digital health, 2(2):e0000198, 2023
2023
-
[20]
Manning, Christopher Ré, Diana Acosta-Navas, Drew A
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu...
2023
-
[21]
Are we learning yet? a meta review of evaluation failures across machine learning
Thomas Liao, Rohan Taori, Inioluwa Deborah Raji, and Ludwig Schmidt. Are we learning yet? a meta review of evaluation failures across machine learning. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[22]
Lord.Applications of Item Response Theory to Practical Testing Problems
Frederic M. Lord.Applications of Item Response Theory to Practical Testing Problems. Rout- ledge, New York, 1980
1980
-
[23]
Lord, Melvin R
Frederic M. Lord, Melvin R. Novick, and Allan Birnbaum.Statistical Theories of Mental Test Scores. Addison-Wesley, 1968
1968
-
[24]
Knowing when to abstain: Medical llms under clinical uncertainty
Sravanthi Machcha, Sushrita Yerra, Sahil Gupta, Aishwarya Sahoo, Sharmin Sultana, Hong Yu, and Zonghai Yao. Knowing when to abstain: Medical llms under clinical uncertainty. InPro- ceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 6153–6182, 2026
2026
-
[25]
”My AI is Lying to Me”: User-reported LLM hallucinations in AI mobile apps reviews
Rhodes Massenon, Ishaya Gambo, Javed Ali Khan, Christopher Agbonkhese, and Ayed Al- wadain. ”My AI is Lying to Me”: User-reported LLM hallucinations in AI mobile apps reviews. Scientific Reports, 15(1), aug 19 2025. ISSN 2045-2322. doi: 10.1038/s41598-025-15416-8. URLhttp://dx.doi.org/10.1038/s41598-025-15416-8
-
[26]
Azure openai service
Microsoft Corporation. Azure openai service. Microsoft Azure Cloud Plat- form, 2026. URL https://azure.microsoft.com/en-us/products/ai-services/ openai-service. Accessed: 2026-04-03. Private endpoint deployment with HIPAA-compliant configuration
2026
-
[27]
Joshua W. Ohde, Lauren M. Rost, and Joshua D. Overgaard. The burden of reviewing llm- generated content.NEJM AI, 2(2), jan 2025. doi: 10.1056/AIp2400979
-
[28]
text-embedding-3-large
OpenAI. text-embedding-3-large. OpenAI API, 2024. URL https://developers.openai. com/api/docs/models/text-embedding-3-large . Released January 25, 2024. Accessed: 2026-04-03
2024
-
[29]
GPT-4.1.https://openai.com/index/gpt-4-1/, 2025
OpenAI. GPT-4.1.https://openai.com/index/gpt-4-1/, 2025. Accessed: 2025
2025
-
[30]
Detecting omissions in LLM-generated medical summaries
Achir Oukelmoun, Nasredine Semmar, Gaël de Chalendar, Clement Cormi, Mariame Oukel- moun, Eric Vibert, and Marc-Antoine Allard. Detecting omissions in LLM-generated medical summaries. In Saloni Potdar, Lina Rojas-Barahona, and Sebastien Montella, editors,Pro- ceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Tra...
-
[31]
Polo, Lucas Weber, Leshem Choshen, Y
Maia F. Polo, Lucas Weber, Leshem Choshen, Y . Sun, G. Xu, and Mikhail Yurochkin. tiny- benchmarks: Evaluating llms with fewer examples. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 34303–34326. PMLR, 2024
2024
-
[32]
Achieving large-scale clinician adoption of ai-enabled decision support.BMJ health & care informatics, 31(1):e100971, 2024
Ian A Scott, Anton Van Der Vegt, Paul Lane, Steven McPhail, and Farah Magrabi. Achieving large-scale clinician adoption of ai-enabled decision support.BMJ health & care informatics, 31(1):e100971, 2024
2024
-
[33]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Seneviratne, Paul Gamble, Chris Kelly, Abubakr Babiker, Nathanael Schärli, Aakanksha Chowdhery, Philip Mansfield, Dina Demner-Fushman, Blaise Agüera y Arcas, Dale Web- ster, Greg S. Corrad...
-
[34]
Beyond the imitation game: Quantifying and extrapolating the capabili- ties of language models.Transactions on Machine Learning Research (TMLR), 2023
Aarohi Srivastava et al. Beyond the imitation game: Quantifying and extrapolating the capabili- ties of language models.Transactions on Machine Learning Research (TMLR), 2023
2023
-
[35]
Alexander F Stevens and Pete Stetson. Theory of trust and acceptance of artificial intelli- gence technology (traait): An instrument to assess clinician trust and acceptance of artificial intelligence.Journal of biomedical informatics, 148:104550, 2023
2023
-
[36]
Reliable and efficient amortized model-based evaluation, 2025
Sang Truong, Yuheng Tu, Percy Liang, Bo Li, and Sanmi Koyejo. Reliable and efficient amortized model-based evaluation, 2025. URLhttps://arxiv.org/abs/2503.13335
arXiv 2025
-
[37]
Shirui Wang, Zhihui Tang, Huaxia Yang, Qiuhong Gong, Tiantian Gu, Hongyang Ma, Yongxin Wang, Wubin Sun, Zeliang Lian, Kehang Mao, Yinan Jiang, Zhicheng Huang, Lingyun Ma, Wenjie Shen, Yajie Ji, Yunhui Tan, Chunbo Wang, Yunlu Gao, Qianling Ye, Rui Lin, Mingyu Chen, Lijuan Niu, Zhihao Wang, Peng Yu, Mengran Lang, Yue Liu, Huimin Zhang, Haitao Shen, Long Che...
arXiv 2025
-
[38]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyu Zhuang, Zuxuan Wu, Yong Zhuang, Zi Lin, Ziwei Li, Diyi Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a- judge with mt-bench and chatbot arena. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://arxiv.org/abs/ 2306.05685
Pith/arXiv arXiv 2023
-
[39]
Hongli Zhou, Hui Huang, Ziqing Zhao, Lvyuan Han, Huicheng Wang, Kehai Chen, Muyun Yang, Wei Bao, Jian Dong, Bing Xu, Conghui Zhu, Hailong Cao, and Tiejun Zhao. Lost in benchmarks? rethinking large language model benchmarking with item response theory. In Proceedings of the AAAI Conference on Artificial Intelligence, 2026. URL https://arxiv. org/abs/2505.1...
arXiv 2026
-
[40]
CONTINUOUS SCORE (0–1): How likely is the user to accept an LLM response to this query?
-
[41]
TheQuery Only variant omitted the context block entirely, receiving only the user query as input
DISCRETE ACCEPTANCE (Yes/No): Will the user accept an LLM response to this query? •Yes = The user will accept an LLM response •No = The user would NOT accept an LLM response Respond in EXACTLY this format: CONTINUOUS_SCORE: [number between 0 and 1] DISCRETE_ACCEPTANCE: [Yes or No] REASONING: [brief explanation] Deployment-Specific Context Block (Query + C...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.