Perceive, Interact, Reason: Building Tool-Augmented Visual Agents for Spatial Reasoning
Pith reviewed 2026-06-27 07:48 UTC · model grok-4.3
The pith
PERIA agents equip vision-language models with perception and interaction tools to improve spatial reasoning through active evidence gathering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
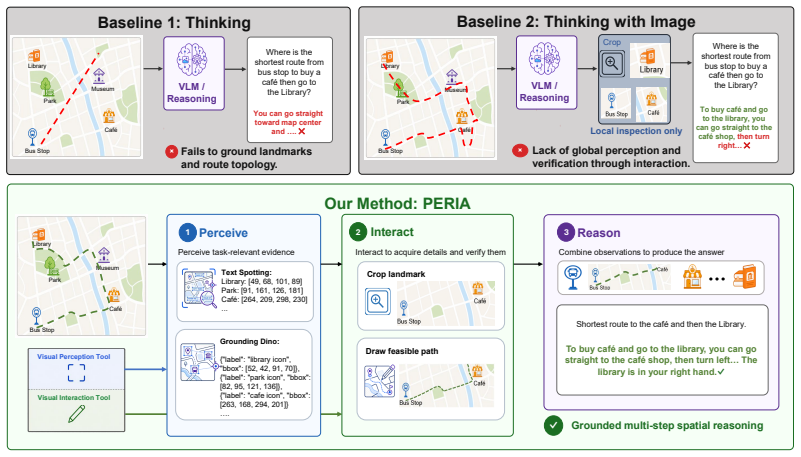
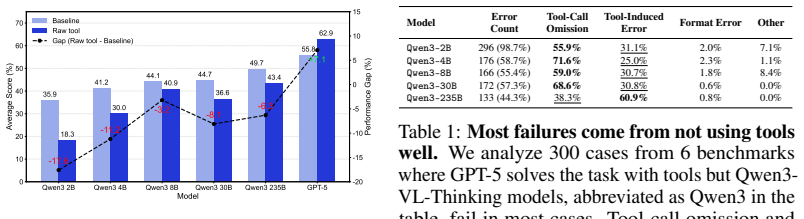
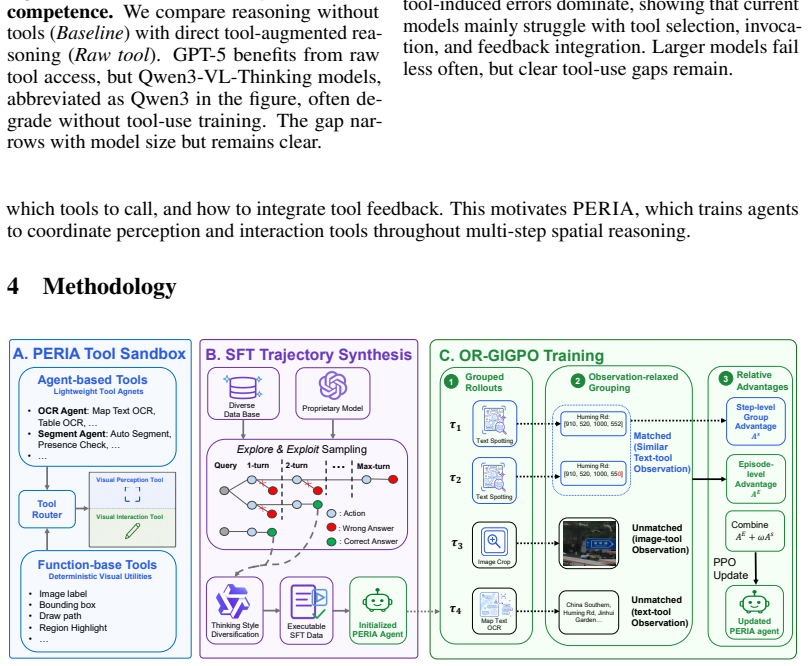
PERIA is a tool-augmented visual agent that uses vision perception tools and vision interaction tools, trained via supervised tool-use trajectory synthesis, composite rewards, and Observation-Relaxed Group-in-Group Policy Optimization (OR-GIGPO), delivering 10.0% gains on in-distribution benchmarks and 4.4% on out-of-distribution benchmarks over the Qwen3-8B backbone while beating similar-sized prior state-of-the-art models by 7.0%-14.8% and matching much larger models such as Qwen3-VL-235B-A22B-Thinking.
What carries the argument
Two lightweight tool families (vision perception tools for evidence exposure and vision interaction tools for context manipulation) combined with the OR-GIGPO training procedure that supports coordinated multi-tool use.
If this is right
- An 8B model reaches performance comparable to models with 235B parameters on spatial reasoning tasks.
- Gains appear consistently across 13 benchmarks spanning map reasoning, visual probing, and vision reconstruction.
- The method improves both in-distribution and out-of-distribution generalization.
- Similar-sized models can surpass earlier state-of-the-art baselines without increasing parameter count.
Where Pith is reading between the lines
- Explicit tool interfaces may prove more sample-efficient than further parameter scaling for tasks that require sequential visual verification.
- The same perception-plus-interaction pattern could be tested on non-spatial sequential reasoning domains such as temporal event ordering or multi-step planning.
- Forcing models to output explicit tool calls may reduce certain classes of visual hallucination by requiring verifiable intermediate steps.
Load-bearing premise
That the reported gains arise specifically from the tool families and OR-GIGPO rather than from differences in training data volume, prompting details, or benchmark construction.
What would settle it
An ablation that removes the perception and interaction tools (or replaces OR-GIGPO with standard supervised fine-tuning) and finds the 8B backbone returns to baseline performance levels on the same 13 benchmarks would falsify the claim.
Figures






read the original abstract
While recent vision-language models (VLMs) demonstrate strong multimodal understanding, they remain limited in spatial reasoning tasks that require active evidence acquisition and multi-step visual interaction. This limitation suggests that relying solely on implicit visual representations from vision encoders is insufficient for recovering fine-grained spatial evidence. We introduce PERception-Interaction-reason Agent (PERIA), a tool-augmented visual agent for spatial reasoning tasks across map reasoning, visual probing, and vision reconstruction. PERIA uses two lightweight tool families: vision perception tools for exposing textual, symbolic, and spatial evidence, and vision interaction tools for manipulating visual context, tracing paths, and verifying spatial relations. To train PERIA, we develop a unified recipe that combines supervised tool-use trajectory synthesis, composite rewards, and Observation-Relaxed Group-in-Group Policy Optimization (OR-GIGPO) for effective multi-tool behavior. Experiments on 13 benchmarks from 8 datasets show that PERIA-8B improves over the Qwen3-8B backbone by 10.0% on in-distribution benchmarks and 4.4% on out-of-distribution benchmarks, while outperforming previous state-of-the-art baselines of similar size by 7.0%-14.8%. It also achieves performance comparable to much larger models such as Qwen3-VL-235B-A22B-Thinking and GPT-5, demonstrating the effectiveness of PERIA in enhancing spatial reasoning capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PERIA, a tool-augmented visual agent for spatial reasoning tasks (map reasoning, visual probing, vision reconstruction) that augments a VLM backbone with two lightweight tool families—vision perception tools (exposing textual/symbolic/spatial evidence) and vision interaction tools (manipulating context, tracing paths, verifying relations)—and trains it via supervised tool-use trajectory synthesis, composite rewards, and Observation-Relaxed Group-in-Group Policy Optimization (OR-GIGPO). Experiments on 13 benchmarks from 8 datasets report that the 8B variant improves over the Qwen3-8B backbone by 10.0% (in-distribution) and 4.4% (out-of-distribution) while outperforming prior same-size SOTAs by 7.0–14.8% and matching much larger models.
Significance. If the performance deltas can be isolated to the tool families and OR-GIGPO, the work would supply concrete evidence that explicit tool interfaces plus relaxed group-in-group RL can measurably strengthen spatial reasoning beyond implicit vision-encoder representations, offering a scalable recipe for interactive visual agents.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the headline claim attributes the 10.0% in-distribution and 4.4% out-of-distribution gains specifically to the two tool families and OR-GIGPO, yet the manuscript does not state that the Qwen3-8B backbone received identical supervised trajectory data volume, the same number of optimization steps, or identical evaluation prompting. Without this control the observed deltas cannot be isolated from possible differences in training data or prompting.
- [Experiments] Experiments section: no statistical tests, run-to-run variance, or confidence intervals are reported for the percentage improvements, and baseline details (exact prompting, data composition, and training compute for the plain backbone) are omitted, preventing verification that the protocol accurately isolates spatial-reasoning ability.
minor comments (1)
- [Abstract] The abstract lists 13 benchmarks from 8 datasets but provides no table or appendix reference that enumerates them or states which are in- versus out-of-distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on experimental controls and statistical reporting. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline claim attributes the 10.0% in-distribution and 4.4% out-of-distribution gains specifically to the two tool families and OR-GIGPO, yet the manuscript does not state that the Qwen3-8B backbone received identical supervised trajectory data volume, the same number of optimization steps, or identical evaluation prompting. Without this control the observed deltas cannot be isolated from possible differences in training data or prompting.
Authors: The Qwen3-8B backbone denotes the pretrained model used without the supervised tool-use trajectory synthesis or OR-GIGPO optimization that define PERIA. The reported gains therefore reflect the full training recipe, including trajectory data and policy optimization for tool-augmented behavior. We acknowledge that an explicit ablation training the same backbone on identical trajectories but without the tool interfaces would further isolate the tool families' contribution. We will add this ablation and explicitly document training data volume, optimization steps, and prompting for the backbone in the revised Experiments section. revision: partial
-
Referee: [Experiments] Experiments section: no statistical tests, run-to-run variance, or confidence intervals are reported for the percentage improvements, and baseline details (exact prompting, data composition, and training compute for the plain backbone) are omitted, preventing verification that the protocol accurately isolates spatial-reasoning ability.
Authors: We agree that the current reporting lacks statistical rigor and sufficient baseline transparency. In the revision we will report means and standard deviations over multiple independent runs, add confidence intervals, and include statistical significance tests (e.g., paired t-tests) for the reported improvements. We will also expand the Experiments section with exact prompting templates, data composition, and training compute details for the Qwen3-8B backbone and other baselines. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivation chain
full rationale
The paper reports empirical performance gains from a tool-augmented agent trained via supervised trajectory synthesis and OR-GIGPO. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described content. Claims rest on benchmark deltas (e.g., +10.0% in-distribution over Qwen3-8B), which are external measurements rather than reductions to the paper's own inputs. This is the standard case of an empirical ML paper whose results are falsifiable against held-out benchmarks and therefore scores 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Explicit tool use can recover fine-grained spatial evidence that implicit vision encoders miss
invented entities (2)
-
PERIA
no independent evidence
-
OR-GIGPO
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2511.21631. Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherin...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
URLhttps://arxiv.org/abs/2503.14607. Zhengzhuo Xu, Bowen Qu, Yiyan Qi, Sinan Du, Chengjin Xu, Chun Yuan, and Jian Guo. Chartmoe: Mixture of diversely aligned expert connector for chart understanding, 2025. URL https: //arxiv.org/abs/2409.03277. Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minf...
-
[3]
Call appropriate tools based on the task
-
[4]
Only persue one tool calling per action
-
[5]
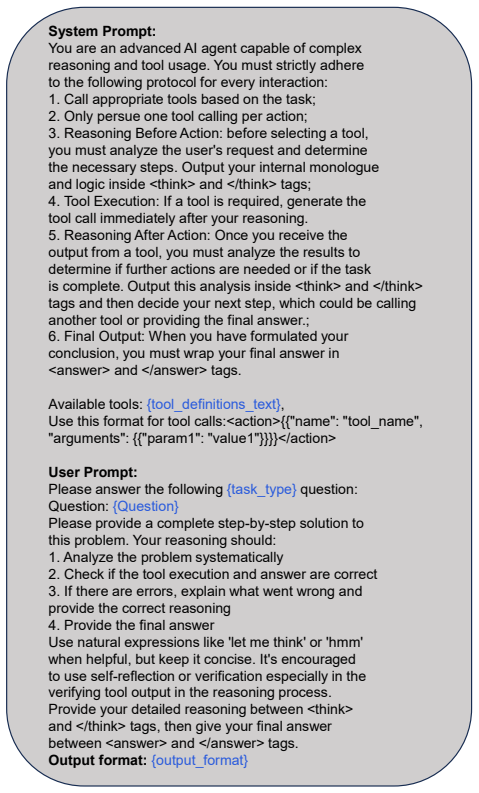
Output your internal monologue and logic inside <think> and </think> tags
Reasoning Before Action: before selecting a tool, you must analyze the user's request and determine the necessary steps. Output your internal monologue and logic inside <think> and </think> tags
-
[6]
Tool Execution: If a tool is required, generate the tool call immediately after your reasoning
-
[7]
Output this analysis inside <think> and </think> tags and then decide your next step, which could be calling another tool or providing the final answer
Reasoning After Action: Once you receive the output from a tool, you must analyze the results to determine if further actions are needed or if the task is complete. Output this analysis inside <think> and </think> tags and then decide your next step, which could be calling another tool or providing the final answer
-
[8]
name": "tool_name
Final Output: When you have formulated your conclusion, you must wrap your final answer in <answer> and </answer> tags. Available tools: {tool_definitions_text}, Use this format for tool calls:<action>{{"name": "tool_name", "arguments": {{"param1": "value1"}}}}</action> User Prompt: Please answer the following {task_type} question: Question: {Question} Pl...
-
[9]
Analyze the problem systematically
-
[10]
Check if the tool execution and answer are correct
-
[11]
If there are errors, explain what went wrong and provide the correct reasoning
-
[12]
It's encouraged to use self-reflection or verification especially in the verifying tool output in the reasoning process
Provide the final answer Use natural expressions like 'let me think' or 'hmm' when helpful, but keep it concise. It's encouraged to use self-reflection or verification especially in the verifying tool output in the reasoning process. Provide your detailed reasoning between <think> and </think> tags, then give your final answer between <answer> and </answe...
2026
-
[13]
Question Related to the Image: {question}
-
[14]
Ground Truth Answer: {ground_truth}
-
[15]
Don’t know
Model Predicted Answer: {prediction} Your task is to evaluate the model's predicted answer against the ground truth answer, based on the context provided by the question related to the image. Consider the following criteria for evaluation: Relevance, whether the predicted answer directly addresses the question posed; and Accuracy, whether the prediction m...
-
[16]
You MUST select a tool - NEVER answer the question directly
-
[17]
Only output the tool NAME - do NOT include parameters
-
[18]
Select only ONE tool per turn
-
[19]
In this phase, you must execute the tool call based on previous reasoning
Do NOT output anything outside the <think></think> tags TOOL_CALL_ONLY_PROMPT: You are an advanced AI agent. In this phase, you must execute the tool call based on previous reasoning. Instructions:
-
[20]
Based on the reasoning provided, execute the tool call immediately
-
[21]
Make sure the tool call is consistent with the decision in the reasoning phase
-
[22]
Do NOT provide any final answer in this phase
-
[23]
Do NOT provide any text explanation, just call the tool with the parameters specified in the reasoning
-
[24]
Wait, I think my previous analysis might be incomplete
Never require a tool to directly solve the problem, but rather to analyze the problem and provide more information for you to solve the problem. Figure 7:Round-1 prompts force exploration before answering.At round 1, TOOL_SELECTION_PROMPT forces the model to select exactly one tool and explain the reason inside <think> tags, while TOOL_CALL_ONLY_PROMPT ex...
-
[25]
Reflect on what might have gone wrong
-
[26]
Identify what additional information could help
-
[27]
Ok, I have [what you just did]. Now I need to
You have used: {used_tools}. Explore new tools for a DIFFERENT perspective OUTPUT FORMAT: <think> [Your self-reflection - choose or generate a phrase similar to the examples above] Tool: [tool_name] Reason: [what NEW information this tool will provide to correct the analysis] </think> CRITICAL: You MUST call a tool - do NOT provide an answer yet. TOOL_SEL...
-
[28]
Based on all the observations and tool results gathered, analyze them carefully and provide the final answer
-
[29]
Wrap your analysis in <think> and </think> tags
-
[30]
Wrap your final answer in <answer> and </answer> tags
-
[31]
{tool_name}
Be concise and direct in your answer Figure 8:Later-round prompts balance further tool use with final answering.For rounds >1 , TOOL_SELECTION_OR_ANSWER_PROMPT lets the model choose between further tool use and final answering; after a rejected answer, EXTEND_TOOL_SELECTION_PROMPT forces self-reflection and additional tool use; at the maximum round,FINAL_...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.