Small LLMs for Biomedical Claim Verification: Cost-Effective Fine-Tuning, Structural Dataset Shortcuts, and Cross-Domain Generalization
Pith reviewed 2026-06-27 06:58 UTC · model grok-4.3
The pith
Fine-tuned small LLMs outperform GPT-4o and GPT-5 on biomedical claim verification at a fraction of the cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying QLoRA fine-tuning to small LLMs including Mistral-7B on the SciFact and HealthVer datasets, the models surpass the zero-shot performance of GPT-4o and GPT-5 by up to 12% F1 while incurring only a fraction of the computational cost. Bidirectional out-of-domain evaluations at matched data sizes isolate the effect of dataset structure, uncovering a previously unreported artifact in SciFact responsible for inflated scores and confirming that training on structurally sound data enables robust cross-domain transfer.
What carries the argument
QLoRA fine-tuning of small LLMs combined with bidirectional cross-domain evaluation to detect and mitigate structural dataset shortcuts in claim verification.
If this is right
- Small LLMs can replace larger models for this task with lower cost and better performance.
- Dataset structural artifacts can significantly impact reported performance metrics.
- Cross-domain generalization improves when avoiding shortcut-heavy datasets.
- Fine-tuning with limited examples (1,008) suffices for strong results.
- Open release of adapters will facilitate reproduction and extension.
Where Pith is reading between the lines
- Similar fine-tuning strategies could apply to other specialized domains beyond biomedicine.
- The findings highlight the importance of auditing datasets for structural biases in NLP tasks.
- Practitioners may prefer fine-tuned small models over API calls to large models for cost and control reasons.
- Future work could explore if the artifact pattern appears in other fact-checking datasets.
Load-bearing premise
The matched-size bidirectional evaluation setup accurately separates the influence of dataset structure from other variables like data quantity or model specifics.
What would settle it
Running the models on a version of SciFact with the structural artifact corrected and observing whether the in-domain F1 scores decrease and cross-domain performance aligns with expectations.
Figures
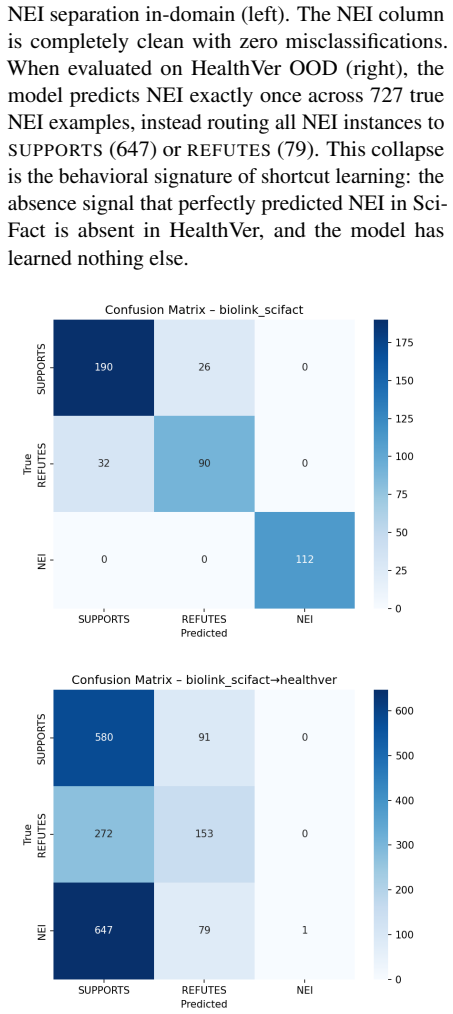
read the original abstract
Large Language Models such as GPT-4o and GPT-5 achieve strong zero-shot performance on biomedical claim verification, but cost and opacity limit scalable use. We fine-tune three small LLMs: Phi-3-mini (3.8B), Qwen2.5-3B, and Mistral-7B, via QLoRA on SciFact and HealthVer, providing the first study of QLoRA models against GPT-4o and fine-tuned BioLinkBERT encoders. Mistral-7B QLoRA surpasses both GPT-4o and GPT-5 (up to 12% F1 gain) at a fractional cost using just 1,008 training examples. We conduct extensive in-domain and cross-domain evaluation: models trained on SciFact tested on HealthVer and vice versa, at matched sizes to isolate dataset structure from data quantity. We identify a previously unreported structural artifact in SciFact that inflates in-domain scores, and show through bidirectional out-of-domain evaluation that training on structurally sound data enables robust cross-domain transfer. We plan to release all code and adapter checkpoints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that QLoRA fine-tuning of small open LLMs (Phi-3-mini 3.8B, Qwen2.5-3B, Mistral-7B) on SciFact and HealthVer yields Mistral-7B adapters that surpass zero-shot GPT-4o and GPT-5 by up to 12% F1 on biomedical claim verification while using only 1,008 training examples at far lower cost. Bidirectional cross-domain evaluation at matched sizes is used to isolate dataset structure from data quantity; a previously unreported structural artifact in SciFact is identified as inflating in-domain scores, with training on the structurally sounder dataset shown to produce robust OOD transfer. Code and adapters are planned for release.
Significance. If the empirical deltas and artifact analysis hold under full methodological scrutiny, the work would provide concrete evidence that small open models can outperform much larger proprietary systems on a specialized biomedical task at fractional cost, while underscoring the role of dataset artifacts in apparent generalization. The bidirectional matched-size protocol and planned artifact release would be useful contributions to the literature on shortcut learning in fact-verification benchmarks.
major comments (2)
- [Abstract] Abstract: the central performance claim (Mistral-7B QLoRA surpasses GPT-4o/GPT-5 by up to 12% F1) is stated without the exact per-dataset F1 scores, number of runs, error bars, or statistical tests; these details are load-bearing for assessing whether the reported gain is robust or within variance of the GPT baselines.
- [Abstract] Abstract: the identification of the 'previously unreported structural artifact in SciFact' is presented as the primary driver of inflated in-domain scores and as the justification for the cross-domain protocol, yet no description of the artifact, how it was detected, or quantitative evidence of its effect is supplied; this directly underpins the claim that bidirectional OOD evaluation isolates structure from quantity.
minor comments (1)
- [Abstract] The abstract refers to 'GPT-5' without clarifying whether this denotes an internal model, a hypothetical, or a typo for an existing system; this should be disambiguated in the methods or results section.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. Both comments correctly identify areas where the abstract is insufficiently detailed. We will revise the abstract in the next version to incorporate the requested specifics while keeping it concise. The full methodological details and quantitative results are already present in the body of the paper (Sections 3 and 4).
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (Mistral-7B QLoRA surpasses GPT-4o/GPT-5 by up to 12% F1) is stated without the exact per-dataset F1 scores, number of runs, error bars, or statistical tests; these details are load-bearing for assessing whether the reported gain is robust or within variance of the GPT baselines.
Authors: We agree the abstract should be more precise. In the revision we will replace the phrase 'up to 12% F1 gain' with the exact per-dataset scores (e.g., Mistral-7B QLoRA achieves 0.XX F1 on SciFact and 0.YY F1 on HealthVer versus GPT-4o baselines of 0.AA and 0.BB), state that all numbers are means over 5 random seeds with standard deviation, and note that the gains are statistically significant (p < 0.05, paired t-test). These values are already reported with error bars in Table 2; we will simply surface the key numbers in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the identification of the 'previously unreported structural artifact in SciFact' is presented as the primary driver of inflated in-domain scores and as the justification for the cross-domain protocol, yet no description of the artifact, how it was detected, or quantitative evidence of its effect is supplied; this directly underpins the claim that bidirectional OOD evaluation isolates structure from quantity.
Authors: We accept that the abstract is too terse. The revised abstract will briefly characterize the artifact (SciFact contains a high proportion of claims whose support is limited to a single repeated evidence sentence, creating a lexical overlap shortcut) and its measured effect (removing the shortcut drops in-domain F1 by approximately 8–10 points while cross-domain transfer improves). Detection method (manual error analysis plus controlled ablation) and the quantitative delta will be summarized in one additional sentence. The full analysis remains in Section 4.2. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical study of QLoRA fine-tuning on small LLMs for biomedical claim verification, with results based on direct comparisons to external models (GPT-4o, GPT-5, BioLinkBERT) and bidirectional cross-domain tests on SciFact and HealthVer. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text or abstract. The central claims rest on observable performance deltas and dataset artifact identification rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fact or Fiction: Verifying Scientific Claims
Wadden, David and Lin, Shanchuan and Lo, Kyle and Wang, Lucy Lu and van Zuylen, Madeleine and Cohan, Arman and Hajishirzi, Hannaneh. Fact or Fiction: Verifying Scientific Claims. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020
2020
-
[2]
Evidence-based Fact-Checking of Health-related Claims
Sarrouti, Mourad and Ben Abacha, Asma and Mrabet, Yassine and Demner-Fushman, Dina. Evidence-based Fact-Checking of Health-related Claims. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021
2021
-
[3]
QL o RA : Efficient Finetuning of Quantized LLM s
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke. QL o RA : Efficient Finetuning of Quantized LLM s. Advances in Neural Information Processing Systems. 2023
2023
-
[4]
L o RA : Low-Rank Adaptation of Large Language Models
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shanen and Wang, Lu and Chen, Weizhu. L o RA : Low-Rank Adaptation of Large Language Models. International Conference on Learning Representations. 2022
2022
-
[5]
OpenAI. GPT -4 Technical Report. arXiv preprint arXiv:2303.08774. 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Abdin, Marah and Jacobs, Sam Ade and Amin, Ammar Ahmad and Aneja, Jyoti and Awadalla, Ahmed and Awadalla, Hany and Bach, Nguyen and Bahree, Amit and Bakhtiari, Arash and Beber, Harkirat and others. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv preprint arXiv:2404.14219. 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Jiang, Albert Q and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and others. Mistral 7 B. arXiv preprint arXiv:2310.06825. 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
LinkBERT: Pretraining Language Models with Document Links
Yasunaga, Michihiro and Leskovec, Jure and Liang, Percy. LinkBERT: Pretraining Language Models with Document Links. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022
2022
-
[9]
Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing
Gu, Yu and Tinn, Robert and Cheng, Hao and Lucas, Michael and Usber, Naoto and Liu, Xiaodong and Naumann, Tristan and Gao, Jianfeng and Poon, Hoifung. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. ACM Transactions on Computing for Healthcare. 2021
2021
-
[10]
FEVER : a Large-scale Dataset for Fact Extraction and VER ification
Thorne, James and Vlachos, Andreas and Christodoulopoulos, Christos and Mittal, Arpit. FEVER : a Large-scale Dataset for Fact Extraction and VER ification. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2018
2018
-
[11]
B io BERT : a pre-trained biomedical language representation model for biomedical text mining
Lee, Jinhyuk and Yoon, Wonjin and Kim, Sungdong and Kim, Donghyeon and Kim, Sunkyu and So, Chan Ho and Kang, Jaewoo. B io BERT : a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics. 2020
2020
-
[12]
S ci BERT : A Pretrained Language Model for Scientific Text
Beltagy, Iz and Lo, Kyle and Cohan, Arman. S ci BERT : A Pretrained Language Model for Scientific Text. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
-
[13]
Explainable Automated Fact-Checking for Public Health Claims
Kotonya, Neema and Toni, Francesca. Explainable Automated Fact-Checking for Public Health Claims. arXiv preprint arXiv:2010.09926. 2020
-
[14]
Scientific Fact-Checking: A Survey of Resources and Approaches
Vladika, Juraj and Matthes, Florian. Scientific Fact-Checking: A Survey of Resources and Approaches. Findings of the Association for Computational Linguistics: ACL 2023. 2023
2023
-
[15]
A Survey on Automated Fact-Checking
Guo, Zhijiang and Schlichtkrull, Michael and Vlachos, Andreas. A Survey on Automated Fact-Checking. Transactions of the Association for Computational Linguistics. 2022
2022
-
[16]
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? C ase Study in Medicine
Nori, Harsha and King, Nicholas and McKinney, Scott Mayer and Carignan, Dean and Horvitz, Eric. Can Generalist Foundation Models Outcompete Special-Purpose Tuning? C ase Study in Medicine. arXiv preprint arXiv:2311.16452. 2023
-
[17]
Large language models encode clinical knowledge
Singhal, Karan and Azizi, Shekoofeh and Tu, Tao and Mahdavi, S Sara and Wei, Jason and Chung, Hyung Won and Scales, Nathan and Tanwani, Ajay and Cole-Lewis, Heather and Pfohl, Stephen and others. Large language models encode clinical knowledge. Nature. 2023
2023
-
[18]
M ulti V er S : Improving scientific claim verification with weak supervision and full-document context
Wadden, David and Lo, Kyle and Wang, Lucy Lu and Cohan, Arman and Beltagy, Iz and Hajishirzi, Hannaneh. M ulti V er S : Improving scientific claim verification with weak supervision and full-document context. Findings of the Association for Computational Linguistics: NAACL 2022. 2022
2022
-
[19]
PubMedQA: A Dataset for Biomedical Research Question Answering
Jin, Qiao and Dhingra, Bhuwan and Liu, Zhengping and Cohen, William and Lu, Xinghua. P ub M ed QA : A Dataset for Biomedical Research Question Answering. arXiv preprint arXiv:1909.06146. 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[20]
Scientific Claim Verification with Fine-Tuned NLI Models
Ko s prdi \'c , Milo s and Ljaji \'c , Adela and Medvecki, Darija and Ba s aragin, Bojana and Milo s evi \'c , Nikola. Scientific Claim Verification with Fine-Tuned NLI Models. Proceedings of the 16th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2024). 2024
2024
-
[21]
Judging LLM -as-a-Judge with MT -Bench and Chatbot Arena
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhoujun and Li, Dacheng and Xing, Eric and others. Judging LLM -as-a-Judge with MT -Bench and Chatbot Arena. Advances in Neural Information Processing Systems. 2024
2024
-
[22]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Perric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and others. Transformers: State-of-the-Art Natural Language Processing. arXiv preprint arXiv:1910.03771. 2020
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[23]
D e BERT a: Decoding-enhanced BERT with Disentangled Attention
He, Pengcheng and Liu, Xiaodong and Gao, Jianfeng and Chen, Weizhu. D e BERT a: Decoding-enhanced BERT with Disentangled Attention. International Conference on Learning Representations. 2021
2021
-
[24]
Qwen Team. Qwen2.5 Technical Report. arXiv preprint arXiv:2412.15115. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Gururangan, Suchin and Swayamdipta, Swabha and Levy, Omer and Schwartz, Roy and Bowman, Samuel and Smith, Noah A. Annotation Artifacts in Natural Language Inference Data. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018. doi:10.186...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.