A Mathematical Forum Platform for Collaborative Problem Solving and Dataset Generation for AI Reasoning
Pith reviewed 2026-06-27 06:50 UTC · model grok-4.3
The pith
A forum platform with embedded image-to-LaTeX conversion generates a growing, community-validated dataset of mathematical problems and solutions for training AI reasoning systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Embedding an OCR-based image-to-LaTeX conversion pipeline directly inside a forum posting flow removes the main barriers to sharing mathematical content online and simultaneously produces a continuously growing, community-validated collection of problems together with their step-by-step solutions that can serve as training and benchmark data for AI mathematical reasoning systems.
What carries the argument
The integrated image-to-LaTeX pipeline that accepts an uploaded or captured image, routes it through the Mathpix OCR API, normalizes LaTeX or inline-math delimiters, and renders a live preview before database commit.
If this is right
- The platform supports posting and viewing on both desktop and mobile devices without external tools.
- Posts accumulate into a dataset that can be used to train AI systems for accurate mathematical reasoning.
- The same dataset can serve as a benchmark for evaluating AI performance on step-by-step math problem solving.
- The three-layer architecture (image processing, rendering, storage) can be extended to other content types that require OCR or rendering.
Where Pith is reading between the lines
- If the dataset grows large enough it could reduce reliance on synthetic math problems for AI training.
- Mobile capture support may increase the rate at which handwritten classroom notes enter the public dataset.
- The same integration pattern could be applied to chemistry structures or physics diagrams to create analogous datasets in those domains.
Load-bearing premise
Enough users will post both problems and detailed step-by-step solutions rather than only questions or low-quality content.
What would settle it
User activity logs showing that the majority of posts contain questions without accompanying solutions or consist mainly of low-quality content, so that the accumulated data fails to form a high-value training set.
Figures
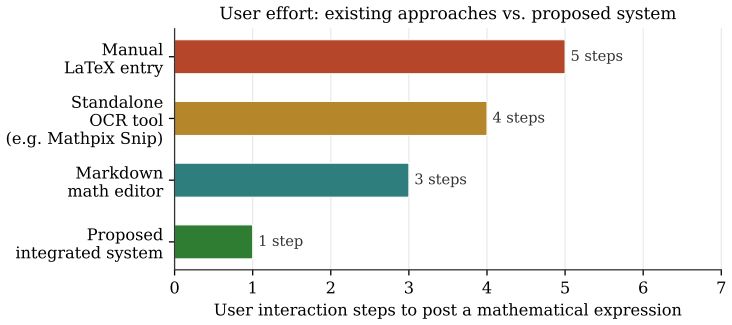
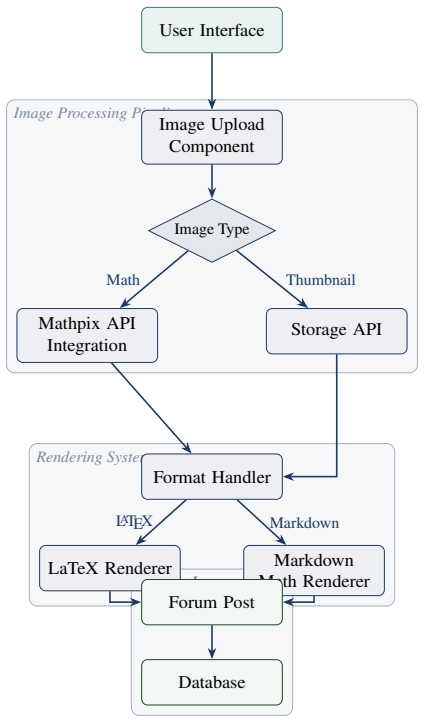
read the original abstract
Sharing mathematical content in online forums remains a significant friction point for students and educators: writing raw LATEX is error-prone, standalone optical character recognition tools require platform switching, and current forum software offers no integrated path from a photograph of a formula to a rendered post. We present a unified system that eliminates this friction by embedding an image to LATEX conversion pipeline directly inside a forum posting interface. A user uploads or captures an image of a mathematical expression; the system routes it through the Mathpix OCR API, detects whether the returned output is LATEX or plain text containing inline math, applies the appropriate delimiter normalisation, and renders a live preview in either LATEX or Markdown mode before the post is committed to the database. The architecture is organized in three loosely coupled layers: image processing, rendering, and storage, and supports both desktop and mobile clients. A provisional US patent application has been filed covering the core methods. We describe the full system design, each component in detail, the data schema, and the key technical innovations, and we position the work against existing standalone tools and forum platforms to demonstrate the practical gap it closes. Beyond immediate usability, we argue that a deployed platform of this kind constitutes a continuously growing, community-validated dataset of mathematical problems and step-by-step solutions, a resource that can be used to train and benchmark AI systems for accurate mathematical reasoning
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a three-layer architecture (image processing, rendering, storage) for a mathematical forum platform that embeds an image-to-LaTeX pipeline using the Mathpix OCR API directly in the posting interface, with live preview, delimiter normalization, and support for desktop/mobile clients. It positions the system against standalone OCR tools and existing forums, claims to close a usability gap for sharing mathematical content, and argues that a deployed instance will produce a continuously growing, community-validated dataset of problems and step-by-step solutions usable for training and benchmarking AI mathematical reasoning systems. A provisional US patent is noted.
Significance. The core integration of OCR and live rendering into a forum interface addresses a documented friction point in mathematical collaboration and could see practical adoption. The dataset-generation argument, if realized, would be a distinctive contribution by turning user activity into training resources, but the manuscript provides no mechanisms, incentives, or validation steps to support this outcome. The work is a descriptive system design without implementation details, testing, or empirical results.
major comments (1)
- [Abstract] Abstract: the claim that a deployed platform 'constitutes a continuously growing, community-validated dataset of mathematical problems and step-by-step solutions' is load-bearing for the secondary contribution yet unsupported by the architecture. The described layers (image-to-LaTeX via Mathpix, rendering, storage) contain no design elements for incentivizing detailed solutions, quality moderation, or validation of multi-step reasoning, leaving the mapping from reduced posting friction to high-value AI training data dependent on unexamined user behavior.
minor comments (1)
- The data schema and component descriptions would be clearer with an accompanying diagram or pseudocode illustrating the flow from image upload through OCR, normalization, preview, and database commit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and clarify the scope of our claims regarding dataset generation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that a deployed platform 'constitutes a continuously growing, community-validated dataset of mathematical problems and step-by-step solutions' is load-bearing for the secondary contribution yet unsupported by the architecture. The described layers (image-to-LaTeX via Mathpix, rendering, storage) contain no design elements for incentivizing detailed solutions, quality moderation, or validation of multi-step reasoning, leaving the mapping from reduced posting friction to high-value AI training data dependent on unexamined user behavior.
Authors: We agree that the three-layer architecture contains no explicit mechanisms for incentivizing detailed solutions, quality moderation, or automated validation of multi-step reasoning. The manuscript presents the dataset-generation outcome as a prospective argument based on reduced posting friction and the interactive nature of forums (e.g., replies and community feedback), rather than as a feature engineered into the described system. The core contribution remains the OCR integration and live rendering pipeline. To address the concern, we will revise the abstract to qualify the dataset claim as a potential long-term benefit of deployment and community adoption, without implying that the architecture itself guarantees high-value training data. revision: partial
Circularity Check
No circularity: system-design paper with no derivations or fitted predictions
full rationale
The manuscript describes an image-to-LaTeX forum pipeline, its three-layer architecture, data schema, and rendering logic. The sole forward-looking claim—that the platform will produce a growing validated dataset for AI training—is presented as an argument resting on external user behavior, not as a derived quantity, equation, or prediction obtained from any internal model or fit. No self-citations, uniqueness theorems, ansatzes, or renamings appear. The paper is therefore self-contained against external benchmarks and contains no load-bearing step that reduces to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lamport,LaTeX: A Document Preparation System, 2nd ed
L. Lamport,LaTeX: A Document Preparation System, 2nd ed. Reading, MA: Addison-Wesley, 1994
1994
-
[2]
MathJax: a platform for mathematics on the web,
D. Cervone, “MathJax: a platform for mathematics on the web,”Notices of the American Mathematical Society, vol. 59, no. 2, pp. 312–316, 2012. doi:10.1090/noti794
-
[3]
Mathpix OCR API,
Mathpix, “Mathpix OCR API,”Technical Documentation, 2024. [Online] Available: https://mathpix.com/ ocr
2024
-
[4]
pix2tex: LaTeX OCR,
L. Blecher, “pix2tex: LaTeX OCR,” GitHub repository, 2022. [Online] Available: https://github.com/ lukas-blecher/LaTeX-OCR
2022
-
[5]
Image-to-markup generation with coarse-to-fine attention,
Y . Deng, A. Kanervisto, J. Ling, and A. M. Rush, “Image-to-markup generation with coarse-to-fine attention,” in Proc. 34th Int. Conf. Machine Learning (ICML), PMLR 70, 2017, pp. 980–989. 10
2017
-
[6]
Syntax-directed recognition of hand-printed two-dimensional mathematics,
R. H. Anderson, “Syntax-directed recognition of hand-printed two-dimensional mathematics,” inProc. ACM Symp. Interactive Systems for Experimental Applied Mathematics, New York, 1967, pp. 436–459
1967
-
[7]
Ambiguity and constraint in mathematical expression recognition,
E. G. Miller and P. A. Viola, “Ambiguity and constraint in mathematical expression recognition,” inProc. AAAI/IAAI, 1998, pp. 784–791
1998
-
[8]
Mathematical expression recognition: a survey,
K.-F. Chan and D.-Y . Yeung, “Mathematical expression recognition: a survey,”Int. J. Document Analysis and Recognition, vol. 3, no. 1, pp. 3–15, 2000
2000
-
[9]
INFTY: an integrated OCR system for mathematical documents,
M. Suzuki, F. Tamari, R. Fukuda, S. Uchida, and T. Kanahori, “INFTY: an integrated OCR system for mathematical documents,” inProc. ACM Symp. Document Engineering (DocEng), 2003, pp. 95–104
2003
-
[10]
Recognition and retrieval of mathematical expressions,
R. Zanibbi and D. Blostein, “Recognition and retrieval of mathematical expressions,”Int. J. Document Analysis and Recognition, vol. 15, no. 4, pp. 331–357, 2012
2012
-
[11]
Advancing OCR accuracy in image-to-LATEX conversion: a critical and creative exploration,
H. Kayal, C. Berberette, A. Iyer, and M. Vaishnav, “Advancing OCR accuracy in image-to-LATEX conversion: a critical and creative exploration,”Applied Sciences, vol. 13, no. 21, art. 12503, 2023
2023
-
[12]
KaTeX: fast math typesetting for the web,
Khan Academy, “KaTeX: fast math typesetting for the web,” GitHub repository, 2014. [Online] Available: https://github.com/KaTeX/KaTeX
2014
-
[13]
D. E. Knuth,The TeXbook. Reading, MA: Addison-Wesley, 1984
1984
-
[14]
React: a JavaScript library for building user interfaces,
Meta, “React: a JavaScript library for building user interfaces,” 2013. [Online] Available:https://react.dev
2013
-
[15]
Axios: promise-based HTTP client for the browser and Node.js,
axios contributors, “Axios: promise-based HTTP client for the browser and Node.js,” GitHub repository, 2016. [Online] Available:https://github.com/axios/axios
2016
-
[16]
Discourse: the 100% open source discussion platform,
Discourse, “Discourse: the 100% open source discussion platform,” 2013. [Online] Available: https://www. discourse.org
2013
-
[18]
[Online] Available:https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Measuring mathe- matical problem solving with the MATH dataset,
D. Hendrycks, C. Burns, S. Kadavath, S. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathe- matical problem solving with the MATH dataset,” inProc. Neural Information Processing Systems (NeurIPS),
-
[20]
[Online] Available:https://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inProc. Neural Information Processing Systems (NeurIPS), 2022. 11
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.