Quality-Preserving Imperceptible Adversarial Attack on Skeleton-based Human Action Recognition
Pith reviewed 2026-06-27 07:16 UTC · model grok-4.3
The pith
A distribution-based attack closes the empirical-true risk gap to produce imperceptible adversarial motions on skeleton action recognition without noise perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
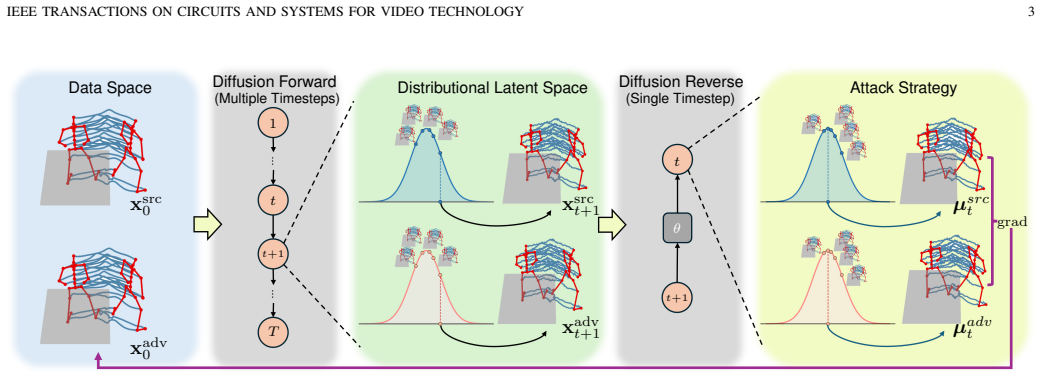
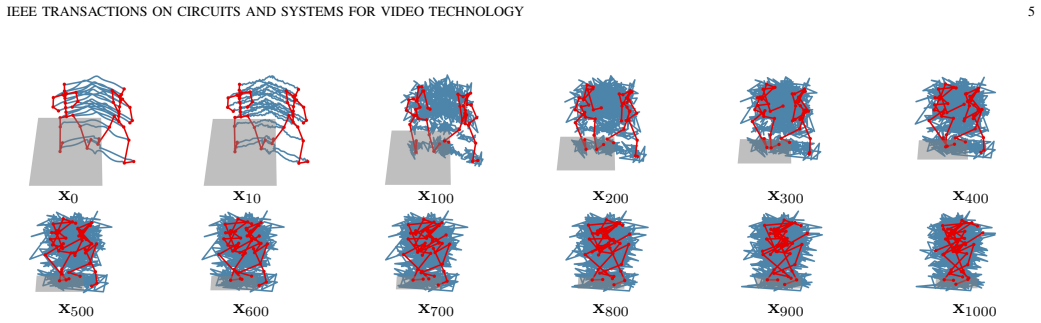
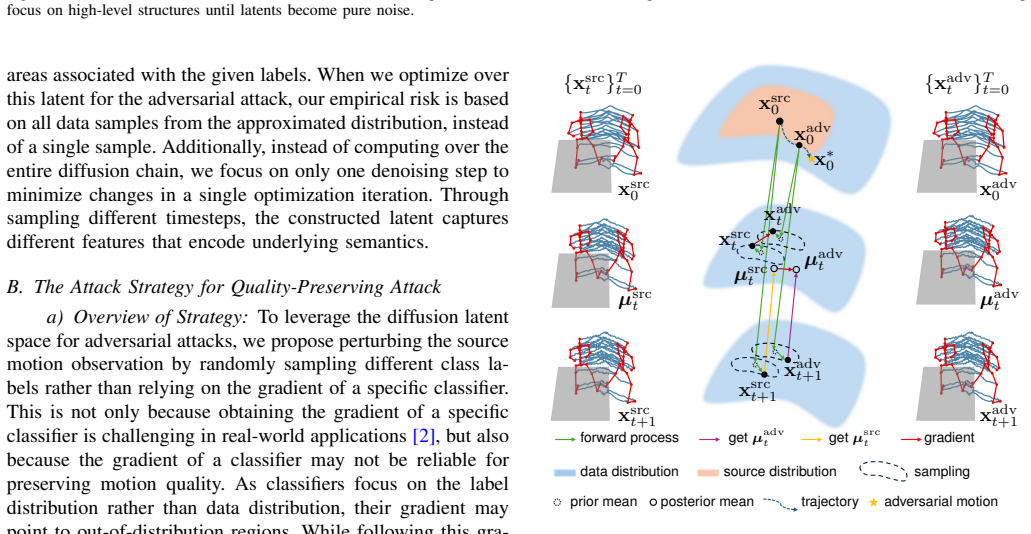
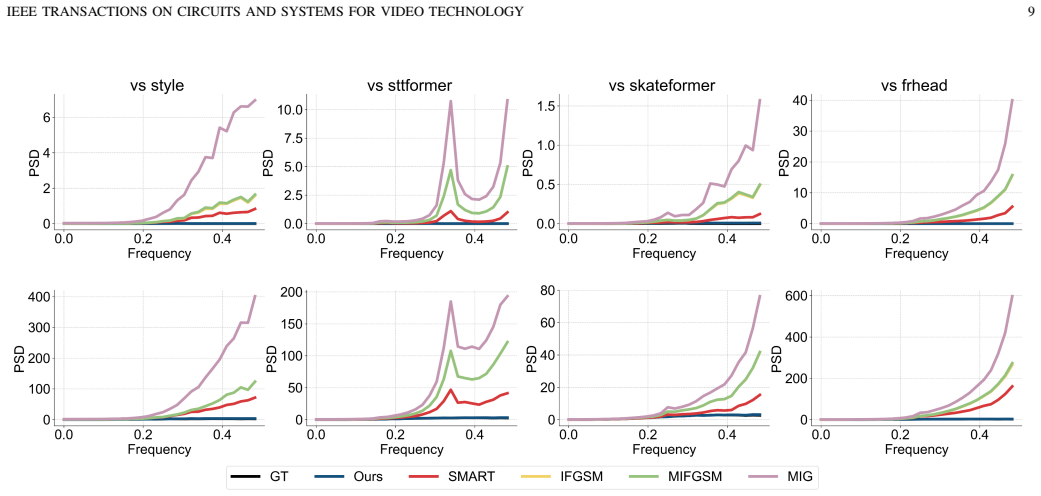
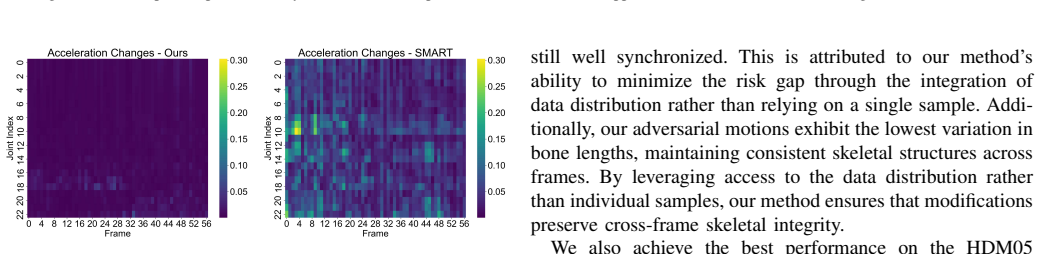
Degradation in motion quality after adversarial attacks on skeleton-based human action recognition stems from the gap between empirical and true risks in the optimization process. A distribution-based adversarial attack method minimizes this gap without introducing noise-like perturbations, thereby preserving motion quality while achieving higher attack success rates, as shown through experiments on state-of-the-art methods across two datasets and a newly proposed human-aligned quality metric.
What carries the argument
Distribution-based adversarial attack that minimizes the empirical-true risk gap without noise-like perturbations.
If this is right
- Attack success rates exceed those of prior noise-based methods on state-of-the-art skeleton action recognizers.
- Post-attack motions retain naturalness according to both the proposed metric and qualitative inspection.
- The attacks remain imperceptible even to recent S-HAR systems that detect noise-like perturbations.
- The results indicate that current action recognizers lack robustness against carefully optimized distribution shifts.
- Further defense research is needed to address optimization gaps rather than perturbation magnitude alone.
Where Pith is reading between the lines
- If the risk-gap diagnosis is accurate, similar distribution-based formulations could be tested on video or RGB action datasets to check whether the same quality preservation occurs.
- Defenses might be strengthened by explicitly regularizing the empirical-true risk gap during training rather than only penalizing perturbation size.
- The new quality metric could serve as a general benchmark for any motion-editing task where human perception of naturalness matters.
Load-bearing premise
The gap between empirical and true risks is the primary driver of motion quality loss, and switching to distribution-based optimization removes that gap without creating new perceptible artifacts.
What would settle it
A controlled comparison in which the distribution-based attack still produces measurable drops in the new human-aligned quality metric or in which the empirical-true risk gap remains large after the method is applied.
Figures

read the original abstract
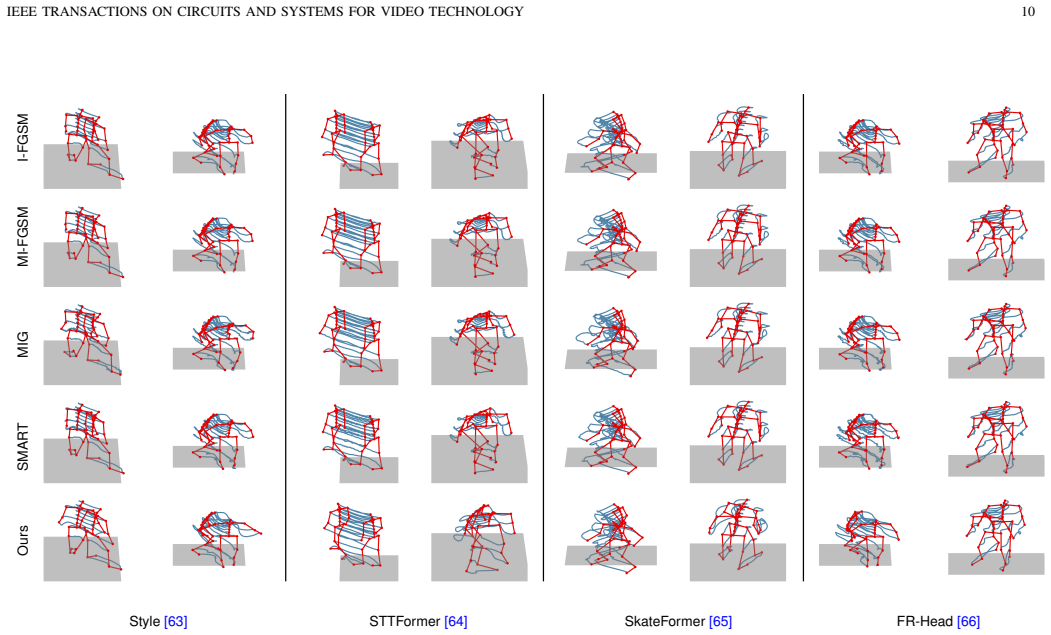
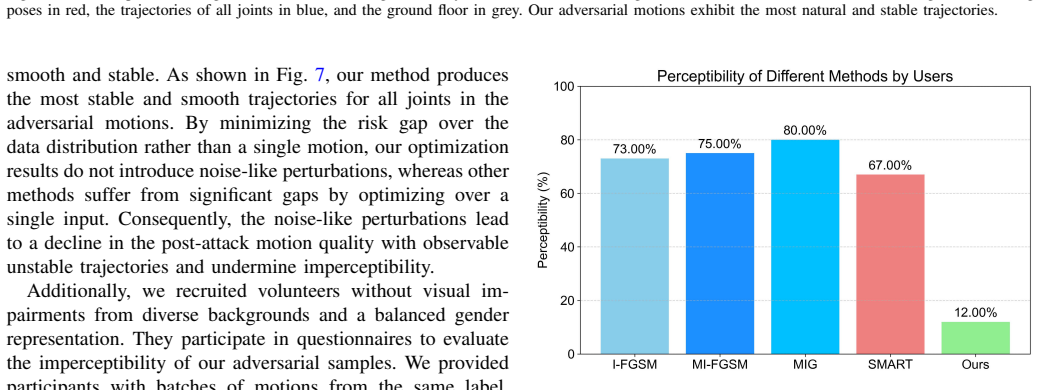
Adversarial attacks on skeletal human action recognition have received significant attention. However, existing methods typically introduce noise-like perturbations that degrade motion quality post-attack, and thereby are inherently perceptible with recent advancements in S-HAR systems. We discover that this degradation stems from the gap between empirical and true risks during the optimization process of previous adversarial attacks. To address this issue, we propose an attack where adversarial motions are obtained without compromising their motion quality. To minimize the risk gap and preserve motion quality, we propose a distribution-based adversarial attack method without introducing noise-like perturbations. To faithfully evaluate the motion quality, we propose a new metric that aligns with human perception on real-world naturalness. Experiments have been conducted on the state-of-the-art S-HAR methods across two datasets, demonstrating the superiority of our method in both the attack success rate and the post-attack motion quality through qualitative and quantitative analyses. The success of our quality-preserving attack application and distribution-based method raises serious concerns about the robustness of action recognizers, highlighting the need for further enhancements in this domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that motion quality degradation in prior adversarial attacks on skeleton-based human action recognition (S-HAR) arises from the gap between empirical and true risks during optimization. It proposes a distribution-based attack method that generates adversarial motions without noise-like perturbations to close this gap and preserve quality, introduces a new human-perception-aligned motion quality metric, and reports superior attack success rates and post-attack quality on state-of-the-art S-HAR models across two datasets via qualitative and quantitative experiments.
Significance. If the risk-gap causal mechanism is isolated and the distribution-based method demonstrably closes it without other artifacts, the work would usefully expose robustness gaps in S-HAR systems and supply a quality-preserving attack baseline. The multi-dataset, multi-model experimental protocol and the attempt to introduce a perceptually aligned metric are positive elements that could support follow-on robustness research.
major comments (2)
- [Abstract] Abstract: the assertion that quality degradation 'stems from the gap between empirical and true risks' is load-bearing for the motivation and for the claim that the distribution-based method addresses the root cause. No ablation is described that holds perturbation magnitude or manifold distance fixed while varying only the risk-gap term, leaving the causal attribution untested against alternative explanations such as perturbation style.
- [Abstract, §4] Abstract and §4 (method): the distribution-based optimization is presented as directly minimizing the risk gap without introducing perceptible artifacts, yet the manuscript does not report an explicit measurement of the empirical-true risk gap on prior attacks or a controlled comparison showing that gap reduction (rather than on-manifold sampling by construction) is responsible for the observed quality gains.
minor comments (2)
- [§3.2] The new motion quality metric is introduced without a dedicated validation section comparing it against existing perceptual or geometric metrics on a human study; this should be added or referenced.
- [§4] Notation for the distribution-based attack (e.g., how the motion distribution is parameterized and optimized) is introduced without an explicit equation or pseudocode block, making reproduction difficult.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. The concerns about isolating the causal role of the empirical-true risk gap are well-taken and point to opportunities to strengthen the manuscript. We respond to each major comment below and commit to revisions that directly address the identified gaps in evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that quality degradation 'stems from the gap between empirical and true risks' is load-bearing for the motivation and for the claim that the distribution-based method addresses the root cause. No ablation is described that holds perturbation magnitude or manifold distance fixed while varying only the risk-gap term, leaving the causal attribution untested against alternative explanations such as perturbation style.
Authors: We agree that the current manuscript does not contain an ablation that isolates the risk-gap term while holding perturbation magnitude and manifold distance fixed. Such a controlled experiment would provide stronger support for the causal claim over alternative explanations. In the revised version we will add this ablation, comparing optimization objectives under matched constraints on perturbation size and manifold proximity. revision: yes
-
Referee: [Abstract, §4] Abstract and §4 (method): the distribution-based optimization is presented as directly minimizing the risk gap without introducing perceptible artifacts, yet the manuscript does not report an explicit measurement of the empirical-true risk gap on prior attacks or a controlled comparison showing that gap reduction (rather than on-manifold sampling by construction) is responsible for the observed quality gains.
Authors: The manuscript does not report numerical values of the empirical-true risk gap for baseline attacks, nor a direct comparison that attributes quality gains specifically to gap reduction versus the on-manifold sampling property. While the distribution-based formulation is motivated by gap minimization and the quality results are consistent with this view, we acknowledge the absence of the requested explicit measurements. We will compute and report the risk-gap values for prior methods and our approach, together with the controlled comparison, in the revision. revision: yes
Circularity Check
No circularity: derivation relies on external empirical observation and new method, not self-referential reduction
full rationale
The abstract asserts a causal link between quality degradation and the empirical-true risk gap, then introduces a distribution-based attack to close that gap. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text that would make the proposed method or its superiority equivalent to the inputs by construction. The new quality metric and experimental comparisons are presented as independent evaluations. This matches the default expectation of a non-circular paper whose central claims rest on external benchmarks rather than tautological redefinitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Degradation in motion quality of prior attacks stems primarily from the gap between empirical and true risks in optimization
invented entities (2)
-
distribution-based adversarial attack method
no independent evidence
-
new motion quality metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on 3d skeleton-based action recognition using learning method,
B. Ren, M. Liu, R. Ding, and H. Liu, “A survey on 3d skeleton-based action recognition using learning method,”Cyborg and Bionic Systems, vol. 5, p. 0100, 2024
2024
-
[2]
Tasar: Transferable attack on skeletal action recognition,
Y . Diao, B. Wu, R. Zhang, A. Liu, X. Wei, M. Wang, and H. Wang, “Tasar: Transferable attack on skeletal action recognition,”arXiv preprint arXiv:2409.02483, 2024
-
[3]
Recent advances in adversarial training for adversarial robustness,
T. Bai, J. Luo, J. Zhao, B. Wen, and Q. Wang, “Recent advances in adversarial training for adversarial robustness,” inProceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI- 21, Z.-H. Zhou, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 2021, pp. 4312–4321, survey Track
2021
-
[4]
Toward trustworthy artificial intelligence (tai) in the context of explainability and robustness,
B. Chander, C. John, L. Warrier, and K. Gopalakrishnan, “Toward trustworthy artificial intelligence (tai) in the context of explainability and robustness,”ACM Computing Surveys, 2024
2024
-
[5]
Understanding the robustness of skeleton-based action recognition under adversarial attack,
H. Wang, F. He, Z. Peng, T. Shao, Y .-L. Yang, K. Zhou, and D. Hogg, “Understanding the robustness of skeleton-based action recognition under adversarial attack,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 656–14 665
2021
-
[6]
Adversarial attack on skeleton-based human action recognition,
J. Liu, N. Akhtar, and A. Mian, “Adversarial attack on skeleton-based human action recognition,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 4, pp. 1609–1622, 2020
2020
-
[7]
Decomposing biological motion: A framework for analysis and synthesis of human gait patterns,
N. F. Troje, “Decomposing biological motion: A framework for analysis and synthesis of human gait patterns,”Journal of vision, vol. 2, no. 5, pp. 2–2, 2002
2002
-
[8]
Modulation of motor area activity during observation of unnatural body movements,
S. Shimada and K. Oki, “Modulation of motor area activity during observation of unnatural body movements,”Brain and cognition, vol. 80, no. 1, pp. 1–6, 2012
2012
-
[9]
Ntu rgb+ d: A large scale dataset for 3d human activity analysis,
A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang, “Ntu rgb+ d: A large scale dataset for 3d human activity analysis,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1010–1019
2016
-
[10]
The Kinetics Human Action Video Dataset
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijaya- narasimhan, F. Viola, T. Green, T. Back, P. Natsevet al., “The kinetics human action video dataset,”arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding,
J. Liu, A. Shahroudy, M. Perez, G. Wang, L.-Y . Duan, and A. C. Kot, “Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding,”IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 10, pp. 2684–2701, 2019
2019
-
[12]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” inInternational Conference on Learning Representations, 2018
2018
-
[13]
Adversarial examples are not bugs, they are features,
A. Ilyas, S. Santurkar, D. Tsipras, L. Engstrom, B. Tran, and A. Madry, “Adversarial examples are not bugs, they are features,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[14]
Adversarial examples are not real features,
A. Li, Y . Wang, Y . Guo, and Y . Wang, “Adversarial examples are not real features,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[15]
Optimizing diffusion noise can serve as universal motion priors,
K. Karunratanakul, K. Preechakul, E. Aksan, T. Beeler, S. Suwajanakorn, and S. Tang, “Optimizing diffusion noise can serve as universal motion priors,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1334–1345
2024
-
[16]
Lidpose: Real-time 3d human pose estimation in sparse lidar point clouds with non-repetitive circular scanning pattern,
L. Kov ´acs, B. M. B´odis, and C. Benedek, “Lidpose: Real-time 3d human pose estimation in sparse lidar point clouds with non-repetitive circular scanning pattern,”Sensors, vol. 24, no. 11, p. 3427, 2024
2024
-
[17]
Finepose: Fine-grained prompt-driven 3d human pose estimation via diffusion models,
J. Xu, Y . Guo, and Y . Peng, “Finepose: Fine-grained prompt-driven 3d human pose estimation via diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 561–570
2024
-
[18]
Wham: Reconstructing world-grounded humans with accurate 3d motion,
S. Shin, J. Kim, E. Halilaj, and M. J. Black, “Wham: Reconstructing world-grounded humans with accurate 3d motion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2070–2080
2024
-
[19]
Principles of risk minimization for learning theory,
V . Vapnik, “Principles of risk minimization for learning theory,”Ad- vances in neural information processing systems, vol. 4, 1991
1991
-
[20]
Devroye, L
L. Devroye, L. Gy ¨orfi, and G. Lugosi,A probabilistic theory of pattern recognition. Springer Science & Business Media, 2013, vol. 31
2013
-
[21]
Model selection and model averaging,
G. Claeskens and N. L. Hjort, “Model selection and model averaging,” Cambridge books, 2008
2008
-
[22]
Costs of position, velocity, and force requirements in optimal control induce triphasic muscle activation during reaching movement,
Y . Ueyama, “Costs of position, velocity, and force requirements in optimal control induce triphasic muscle activation during reaching movement,”Scientific Reports, vol. 11, no. 1, p. 16815, 2021
2021
-
[23]
Five basic muscle ac- tivation patterns account for muscle activity during human locomotion,
Y . P. Ivanenko, R. E. Poppele, and F. Lacquaniti, “Five basic muscle ac- tivation patterns account for muscle activity during human locomotion,” The Journal of physiology, vol. 556, no. 1, pp. 267–282, 2004
2004
-
[24]
Real-time style modelling of human locomotion via feature-wise transformations and local motion phases,
I. Mason, S. Starke, and T. Komura, “Real-time style modelling of human locomotion via feature-wise transformations and local motion phases,”Proceedings of the ACM on Computer Graphics and Interactive Techniques, vol. 5, no. 1, may 2022
2022
-
[25]
Documentation mocap database hdm05,
M. M ¨uller, T. R¨oder, M. Clausen, B. Eberhardt, B. Kr¨uger, and A. Weber, “Documentation mocap database hdm05,” Universit¨at Bonn, Tech. Rep. CG-2007-2, June 2007
2007
-
[26]
Intriguing properties of neural networks
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,”arXiv preprint arXiv:1312.6199, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[27]
Better aggregation in test-time augmentation,
D. Shanmugam, D. Blalock, G. Balakrishnan, and J. Guttag, “Better aggregation in test-time augmentation,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2021, pp. 1214–1223
2021
-
[28]
Retouchuaa: Unconstrained adversarial attack via realistic image retouching,
M. Xie, Y . He, Z. Qin, and M. Fang, “Retouchuaa: Unconstrained adversarial attack via realistic image retouching,”IEEE Transactions IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY 14 on Circuits and Systems for Video Technology, vol. 35, no. 3, pp. 2586– 2602, 2025
2025
-
[29]
Lesep: Boosting adversarial transferability via latent encoding and semantic embedding perturbations,
Y . Gan, C. Wu, D. Ouyang, S. Tang, M. Ye, and T. Xiang, “Lesep: Boosting adversarial transferability via latent encoding and semantic embedding perturbations,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 4, pp. 3368–3382, 2025
2025
-
[30]
Videopure: Diffusion-based adversarial purification for video recognition,
K. Jiang, Z. Chen, J. Fu, L. Hong, J. Li, and W. Zhang, “Videopure: Diffusion-based adversarial purification for video recognition,”IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2025
2025
-
[31]
Transhfc: Joints hypergraph filtering convolution and transformer framework for temporal forgery localization,
J. Huang, X. Yuan, C.-T. Lam, S.-K. Im, F. Lei, and X. Bi, “Transhfc: Joints hypergraph filtering convolution and transformer framework for temporal forgery localization,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[32]
A unified framework for adversarial patch attacks against visual 3d object detection in autonomous driving,
J. Wang, F. Li, and L. He, “A unified framework for adversarial patch attacks against visual 3d object detection in autonomous driving,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[33]
Synthesizing robust adversarial examples,
A. Athalye, L. Engstrom, A. Ilyas, and K. Kwok, “Synthesizing robust adversarial examples,” inInternational conference on machine learning. PMLR, 2018, pp. 284–293
2018
-
[34]
Deeprobust: A pytorch library for adversarial attacks and defenses,
Y . Li, W. Jin, H. Xu, and J. Tang, “Deeprobust: A pytorch library for adversarial attacks and defenses,”arXiv preprint arXiv:2005.06149, 2020
-
[35]
Adversarial attacks on time series,
F. Karim, S. Majumdar, and H. Darabi, “Adversarial attacks on time series,”IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 10, pp. 3309–3320, 2020
2020
-
[36]
Hard no- box adversarial attack on skeleton-based human action recognition with skeleton-motion-informed gradient,
Z. Lu, H. Wang, Z. Chang, G. Yang, and H. P. Shum, “Hard no- box adversarial attack on skeleton-based human action recognition with skeleton-motion-informed gradient,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4597–4606
2023
-
[37]
Understanding the vulnerability of skeleton-based human activity recognition via black-box attack,
Y . Diao, H. Wang, T. Shao, Y . Yang, K. Zhou, D. Hogg, and M. Wang, “Understanding the vulnerability of skeleton-based human activity recognition via black-box attack,”Pattern Recognition, vol. 153, p. 110564, 2024
2024
-
[38]
Adversarial bone length attack on action recognition,
N. Tanaka, H. Kera, and K. Kawamoto, “Adversarial bone length attack on action recognition,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 2, 2022, pp. 2335–2343
2022
-
[39]
Bones of contention: Exploring query-efficient attacks against skeleton recognition systems,
Y . Cao, K. Ye, D. Wang, M. Xue, H. Ge, C. Qian, and J. S. Dong, “Bones of contention: Exploring query-efficient attacks against skeleton recognition systems,”IEEE Transactions on Information Forensics and Security, vol. 21, pp. 183–196, 2025
2025
-
[40]
Qesar: Query effective decision-based attack on skeletal action recognition,
Z. Kang, Y . Zhang, R. Zhang, Y . Jiang, and H. Xia, “Qesar: Query effective decision-based attack on skeletal action recognition,” inChi- nese Conference on Pattern Recognition and Computer Vision (PRCV). Springer, 2023, pp. 417–429
2023
-
[41]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” inInternational Conference on Machine Learning. PMLR, 2015, pp. 2256–2265
2015
-
[42]
On the design fundamentals of diffusion models: A survey,
Z. Chang, G. A. Koulieris, and H. P. Shum, “On the design fundamentals of diffusion models: A survey,”arXiv preprint arXiv:2306.04542, 2023
-
[43]
Boosting black-box attack to deep neural networks with conditional diffusion models,
R. Liu, W. Zhou, T. Zhang, K. Chen, J. Zhao, and K.-Y . Lam, “Boosting black-box attack to deep neural networks with conditional diffusion models,”IEEE Transactions on Information Forensics and Security, 2024
2024
-
[44]
Advdiffuser: Natural adversarial example synthesis with diffusion models,
X. Chen, X. Gao, J. Zhao, K. Ye, and C.-Z. Xu, “Advdiffuser: Natural adversarial example synthesis with diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4562–4572
2023
-
[45]
Un- stoppable attack: Label-only model inversion via conditional diffusion model,
R. Liu, D. Wang, Y . Ren, Z. Wang, K. Guo, Q. Qin, and X. Liu, “Un- stoppable attack: Label-only model inversion via conditional diffusion model,”IEEE Transactions on Information Forensics and Security, 2024
2024
-
[46]
Towards transferable attack via adversarial diffusion in face recognition,
C. Hu, Y . Li, Z. Feng, and X. Wu, “Towards transferable attack via adversarial diffusion in face recognition,”IEEE Transactions on Information Forensics and Security, 2024
2024
-
[47]
Establishing robust generative image steganography via popular stable diffusion,
X. Hu, S. Li, Q. Ying, W. Peng, X. Zhang, and Z. Qian, “Establishing robust generative image steganography via popular stable diffusion,” IEEE Transactions on Information Forensics and Security, 2024
2024
-
[48]
Diffilter: Defending against adversarial perturbations with diffusion filter,
Y . Chen, X. Li, X. Wang, P. Hu, and D. Peng, “Diffilter: Defending against adversarial perturbations with diffusion filter,”IEEE Transac- tions on Information Forensics and Security, 2024
2024
-
[49]
Diffusion patch attack with spatial–temporal cross-evolution for video recognition,
J. Yang, Z. Guan, J. Li, Z. Shi, and X. Liu, “Diffusion patch attack with spatial–temporal cross-evolution for video recognition,”IEEE Transac- tions on Circuits and Systems for Video Technology, vol. 34, no. 12, pp. 13 190–13 200, 2024
2024
-
[50]
Videopure: Diffusion-based adversarial purification for video recognition,
K. Jiang, Z. Chen, J. Fu, L. Hong, J. Li, and W. Zhang, “Videopure: Diffusion-based adversarial purification for video recognition,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[51]
Human motion generation: A survey,
W. Zhu, X. Ma, D. Ro, H. Ci, J. Zhang, J. Shi, F. Gao, Q. Tian, and Y . Wang, “Human motion generation: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[52]
From the perception of action to the understanding of intention,
S.-J. Blakemore and J. Decety, “From the perception of action to the understanding of intention,”Nature reviews neuroscience, vol. 2, no. 8, pp. 561–567, 2001
2001
-
[53]
Brain areas involved in perception of biological motion,
E. Grossman, M. Donnelly, R. Price, D. Pickens, V . Morgan, G. Neigh- bor, and R. Blake, “Brain areas involved in perception of biological motion,”Journal of cognitive neuroscience, vol. 12, no. 5, pp. 711–720, 2000
2000
-
[54]
A latent space of stochastic diffusion models for zero-shot image editing and guidance,
C. H. Wu and F. De la Torre, “A latent space of stochastic diffusion models for zero-shot image editing and guidance,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 7378–7387
2023
-
[55]
Intriguing properties of generative classifiers,
P. Jaini, K. Clark, and R. Geirhos, “Intriguing properties of generative classifiers,” inThe Twelfth International Conference on Learning Rep- resentations, 2024
2024
-
[56]
Action-conditioned 3d human motion synthesis with transformer vae,
M. Petrovich, M. J. Black, and G. Varol, “Action-conditioned 3d human motion synthesis with transformer vae,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 985–10 995
2021
-
[57]
Diffusion autoencoders: Toward a meaningful and decodable represen- tation,
K. Preechakul, N. Chatthee, S. Wizadwongsa, and S. Suwajanakorn, “Diffusion autoencoders: Toward a meaningful and decodable represen- tation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 619–10 629
2022
-
[58]
Noise2score: tweedie’s approach to self- supervised image denoising without clean images,
K. Kim and J. C. Ye, “Noise2score: tweedie’s approach to self- supervised image denoising without clean images,”Advances in Neural Information Processing Systems, vol. 34, pp. 864–874, 2021
2021
-
[59]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInternational Conference on Learning Representations, 2021
2021
-
[60]
Muscles in action,
M. Chiquier and C. V ondrick, “Muscles in action,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 091–22 101
2023
-
[61]
Muscles in time: Learning to understand human motion in-depth by simulating muscle activations,
D. Schneider, S. Reiß, M. Kugler, A. Jaus, K. Peng, S. Sutschet, M. S. Sarfraz, S. Matthiesen, and R. Stiefelhagen, “Muscles in time: Learning to understand human motion in-depth by simulating muscle activations,” Advances in Neural Information Processing Systems, 2025
2025
-
[62]
Basar: Black-box attack on skeletal action recognition,
Y . Diao, T. Shao, Y .-L. Yang, K. Zhou, and H. Wang, “Basar: Black-box attack on skeletal action recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, Confer- ence Proceedings, pp. 7597–7607
2021
-
[63]
Smoodi: Stylized motion diffusion model,
L. Zhong, Y . Xie, V . Jampani, D. Sun, and H. Jiang, “Smoodi: Stylized motion diffusion model,” inEuropean Conference on Computer Vision. Springer, 2025, pp. 405–421
2025
-
[64]
Spatio-temporal tuples transformer for skeleton-based action recognition,
H. Qiu, B. Hou, B. Ren, and X. Zhang, “Spatio-temporal tuples transformer for skeleton-based action recognition,”arXiv preprint arXiv:2201.02849, 2022
-
[65]
Skateformer: Skeletal-temporal transformer for human action recognition,
J. Do and M. Kim, “Skateformer: Skeletal-temporal transformer for human action recognition,” inEuropean Conference on Computer Vision. Springer, 2025
2025
-
[66]
Learning discriminative representations for skeleton based action recognition,
H. Zhou, Q. Liu, and Y . Wang, “Learning discriminative representations for skeleton based action recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 10 608–10 617
2023
-
[67]
Certified adversarial robustness via randomized smoothing,
J. Cohen, E. Rosenfeld, and Z. Kolter, “Certified adversarial robustness via randomized smoothing,” ininternational conference on machine learning. PMLR, 2019, pp. 1310–1320
2019
-
[68]
Generating diverse and natural 3d human motions from text,
C. Guo, S. Zou, X. Zuo, S. Wang, W. Ji, X. Li, and L. Cheng, “Generating diverse and natural 3d human motions from text,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 5152–5161
2022
-
[69]
Physics-constrained attack against convolution-based human motion prediction,
C. Duan, Z. Zhang, X. Liu, Y . Dang, and J. Yin, “Physics-constrained attack against convolution-based human motion prediction,”Neurocom- puting, vol. 575, p. 127272, 2024
2024
-
[70]
Adversarial examples in the physical world,
A. Kurakin, I. J. Goodfellow, and S. Bengio, “Adversarial examples in the physical world,” inArtificial intelligence safety and security. Chapman and Hall/CRC, 2018, pp. 99–112
2018
-
[71]
Boosting adversarial attacks with momentum,
Y . Dong, F. Liao, T. Pang, H. Su, J. Zhu, X. Hu, and J. Li, “Boosting adversarial attacks with momentum,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2018, pp. 9185–9193
2018
-
[72]
Transferable adversarial attack for both vision transformers and convolutional networks via momentum integrated gradients,
W. Ma, Y . Li, X. Jia, and W. Xu, “Transferable adversarial attack for both vision transformers and convolutional networks via momentum integrated gradients,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4630–4639. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY 15
2023
-
[73]
Human motion diffusion model,
G. Tevet, S. Raab, B. Gordon, Y . Shafir, D. Cohen-or, and A. H. Bermano, “Human motion diffusion model,” inThe Eleventh Interna- tional Conference on Learning Representations, 2023
2023
-
[74]
Understanding the latent space of diffusion models through the lens of riemannian geometry,
Y .-H. Park, M. Kwon, J. Choi, J. Jo, and Y . Uh, “Understanding the latent space of diffusion models through the lens of riemannian geometry,”Advances in Neural Information Processing Systems, vol. 36, pp. 24 129–24 142, 2023
2023
-
[75]
A phase transition in diffu- sion models reveals the hierarchical nature of data,
A. Sclocchi, A. Favero, and M. Wyart, “A phase transition in diffu- sion models reveals the hierarchical nature of data,”arXiv preprint arXiv:2402.16991, 2024
-
[76]
Dreamtime: An improved optimization strategy for diffusion-guided 3d generation,
Y . Huang, J. Wang, Y . Shi, B. Tang, X. Qi, and L. Zhang, “Dreamtime: An improved optimization strategy for diffusion-guided 3d generation,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[77]
Diffusion models already have a semantic latent space,
M. Kwon, J. Jeong, and Y . Uh, “Diffusion models already have a semantic latent space,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[78]
Magr: Manifold-aligned graph regularization for continual action quality assessment,
K. Zhou, L. Wang, X. Zhang, H. P. H. Shum, F. W. B. Li, J. Li, and X. Liang, “Magr: Manifold-aligned graph regularization for continual action quality assessment,” inProceedings of the 2024 European Con- ference on Computer Vision, ser. ECCV ’24. Springer, 2024
2024
-
[79]
A video-based augmented reality system for human-in-the-loop muscle strength assessment of juvenile dermatomyositis,
K. Zhou, R. Cai, Y . Ma, Q. Tan, X. Wang, J. Li, H. P. Shum, F. W. Li, S. Jin, and X. Liang, “A video-based augmented reality system for human-in-the-loop muscle strength assessment of juvenile dermatomyositis,”IEEE Transactions on Visualization and Computer Graphics, vol. 29, no. 5, pp. 2456–2466, 2023
2023
-
[80]
Phi: Bridging domain shift in long-term action quality assessment via progressive hierarchical instruction,
K. Zhou, H. P. H. Shum, F. W. B. Li, X. Zhang, and X. Liang, “Phi: Bridging domain shift in long-term action quality assessment via progressive hierarchical instruction,”IEEE Transactions on Image Processing, vol. 34, pp. 3718–3732, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.