TWLA: Achieving Ternary Weights and Low-Bit Activations for LLMs via Post-Training Quantization
Pith reviewed 2026-06-27 07:36 UTC · model grok-4.3
The pith
TWLA is a post-training method that achieves 1.58-bit ternary weights and 4-bit activations for large language models while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
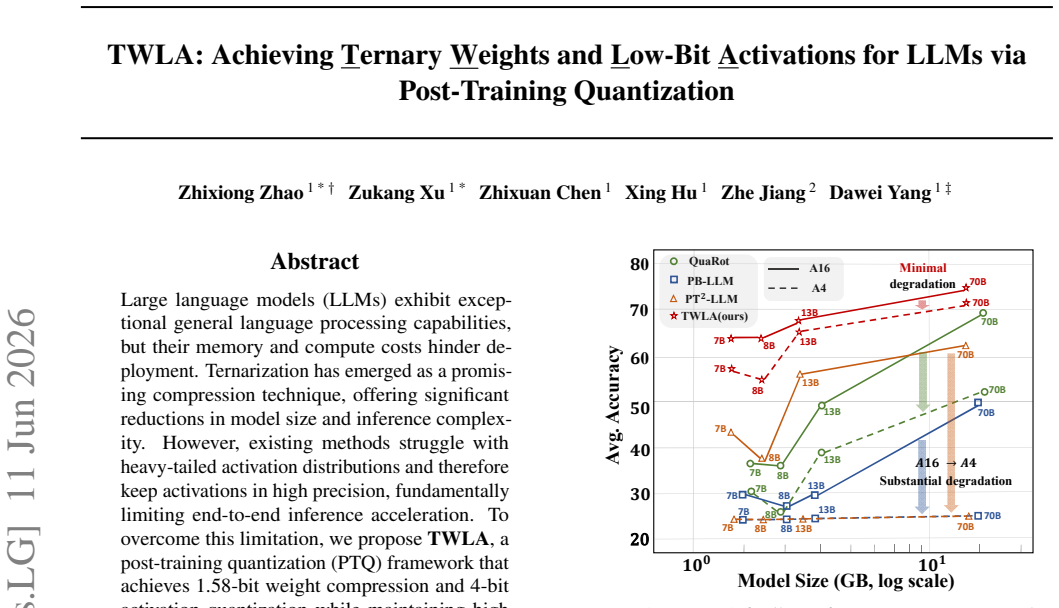
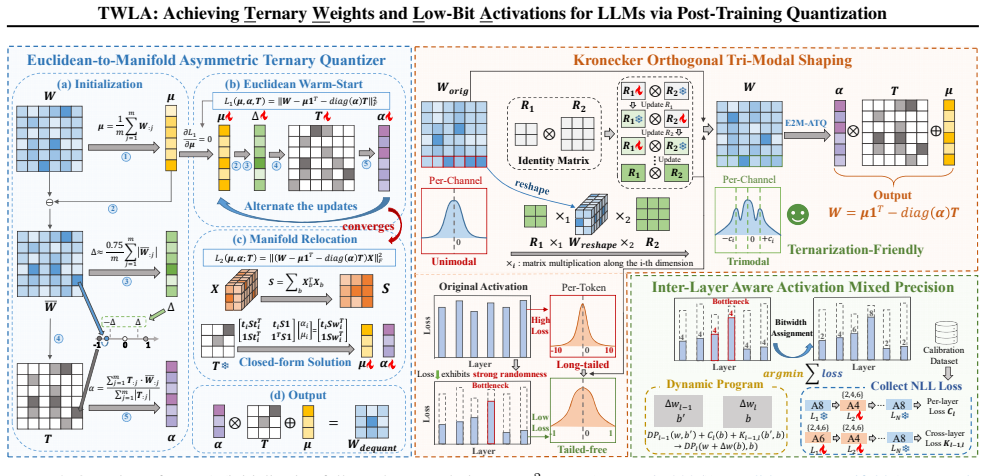
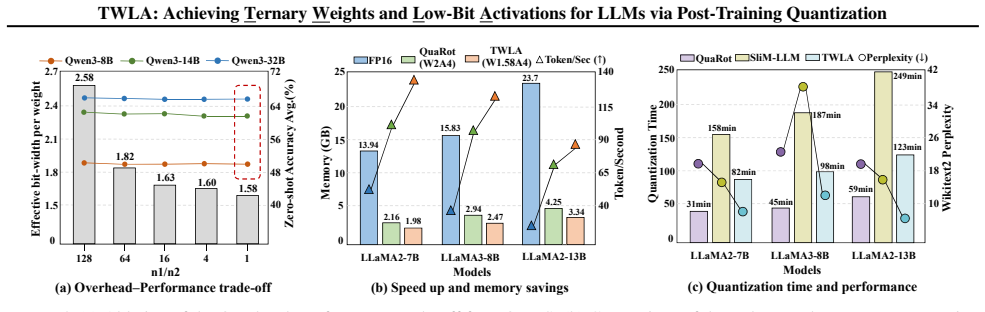
The paper claims that its TWLA framework, built from Euclidean-to-Manifold Asymmetric Ternary Quantizer for layer-output error minimization, Kronecker Orthogonal Tri-Modal Shaping for tri-modal weight reshaping and outlier suppression, and Inter-Layer Aware Activation Mixed Precision for joint bit allocation, enables W1.58A4 quantization of LLMs that maintains high accuracy on language tasks and yields inference acceleration.
What carries the argument
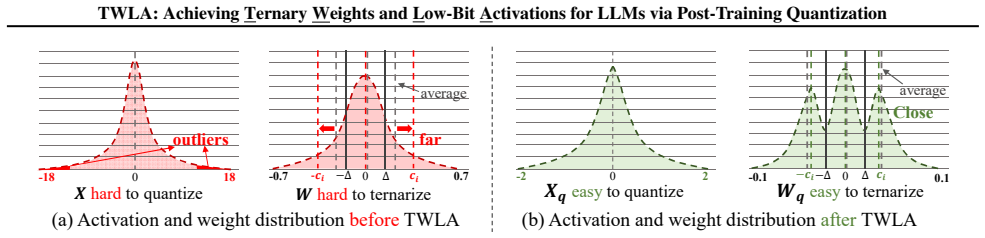
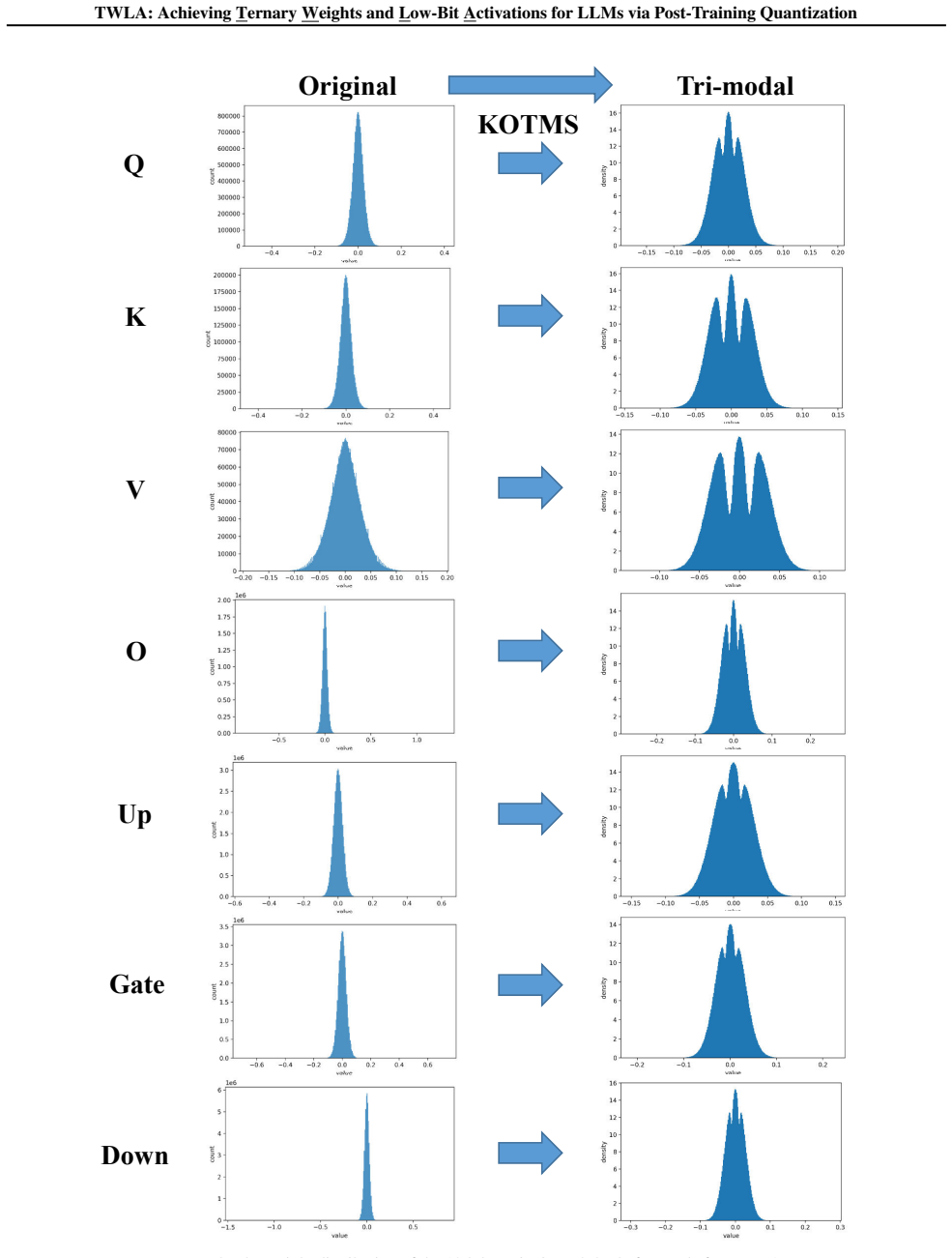
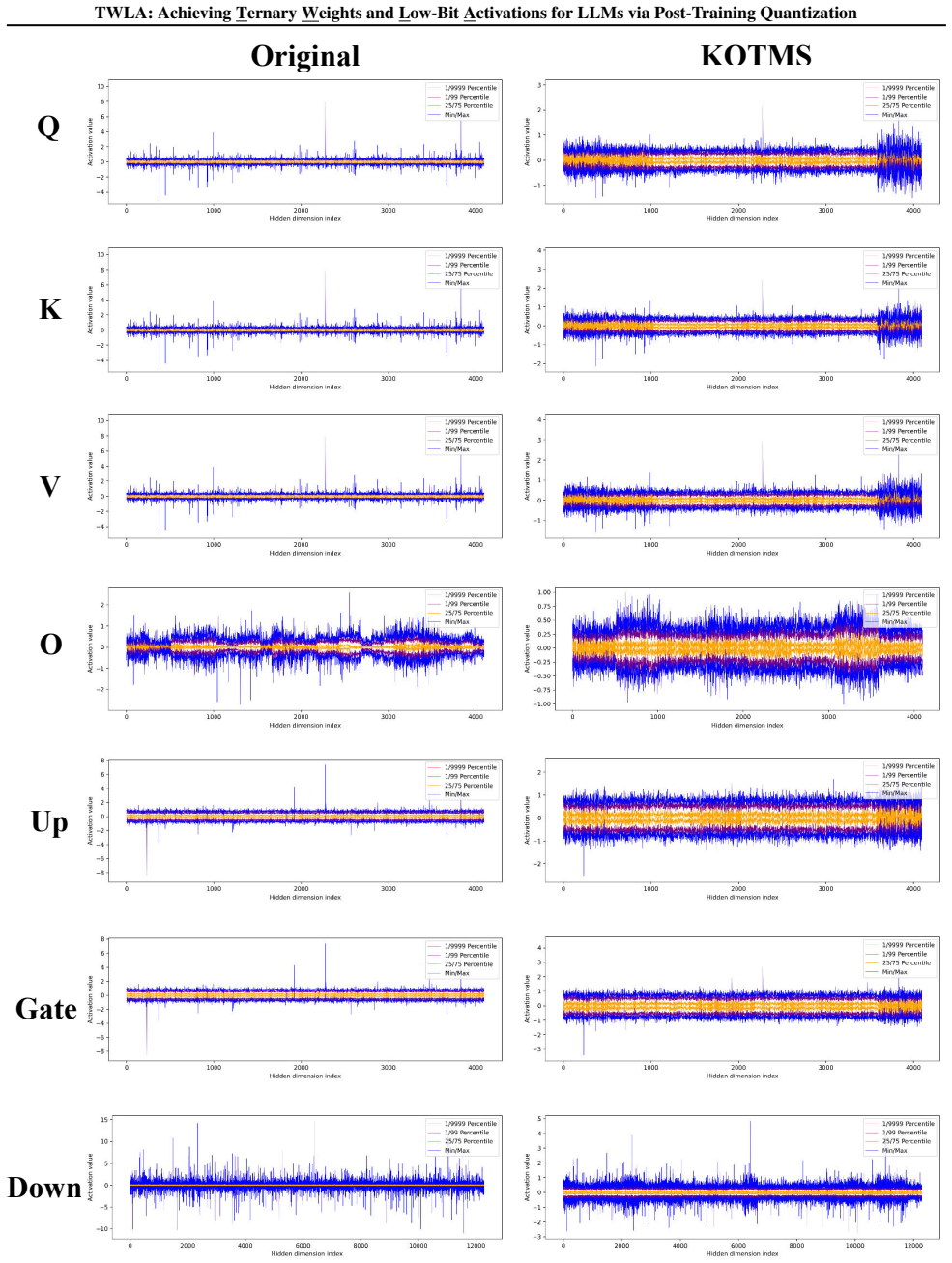
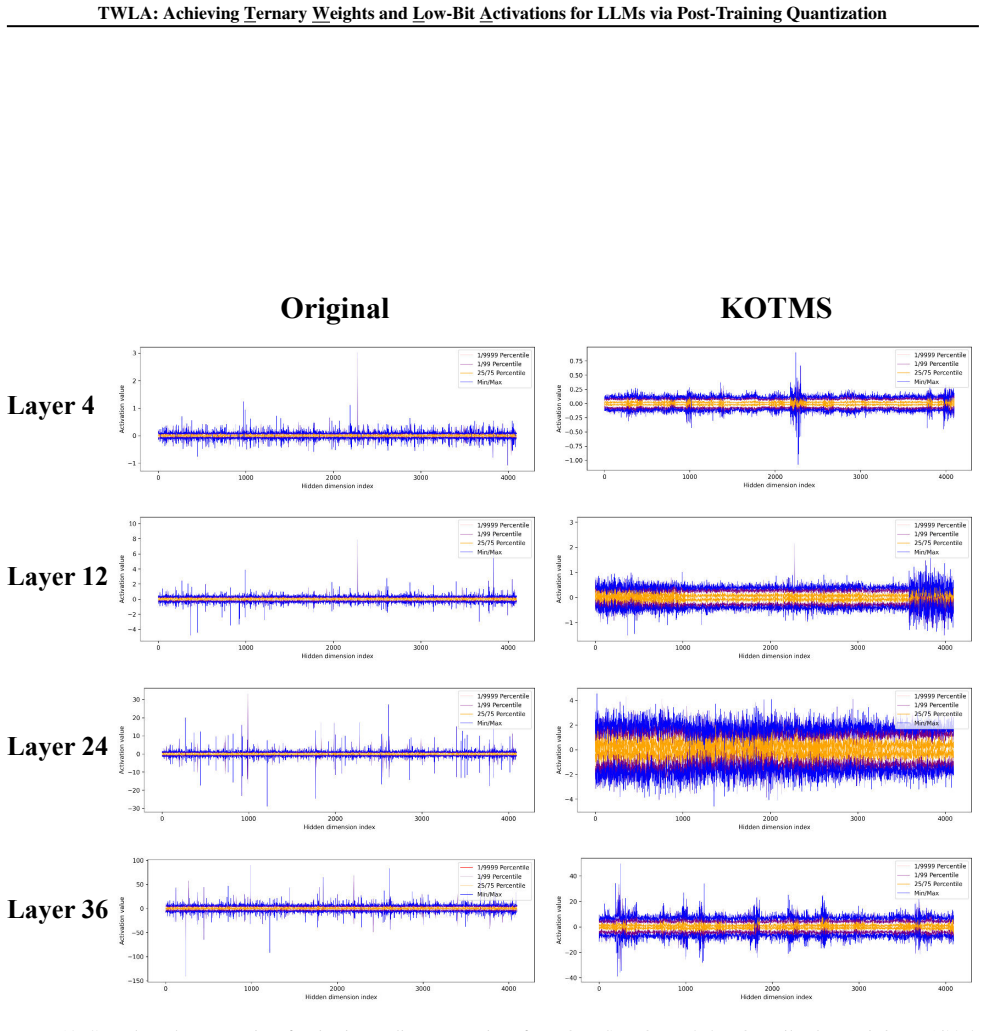
The Kronecker Orthogonal Tri-Modal Shaping component, which applies a Kronecker-structured orthogonal rotation to weights to produce ternary-friendly tri-modal distributions while statistically suppressing activation outliers.
If this is right
- Model memory footprint shrinks substantially from 1.58-bit weight storage.
- Inference compute accelerates because both weights and activations use low-bit arithmetic.
- End-to-end low-precision execution becomes feasible without retaining high-precision activations.
- Accuracy remains competitive with full-precision baselines on language modeling and downstream tasks.
Where Pith is reading between the lines
- The outlier-suppression effect of the shared rotation might extend to other low-bit activation schemes beyond 4 bits.
- The inter-layer cost modeling could be adapted to mixed-precision schemes that also vary weight bits.
- Hardware implementations could exploit the fixed rotation matrix for further speed gains on specific accelerators.
Load-bearing premise
The assumption that the shared orthogonal rotation sufficiently suppresses activation outliers to support reliable 4-bit quantization without major accuracy loss.
What would settle it
A clear accuracy or perplexity drop on a standard LLM benchmark when the full TWLA pipeline is applied with 4-bit activations would falsify the central claim.
Figures
read the original abstract
Large language models (LLMs) exhibit exceptional general language processing capabilities, but their memory and compute costs hinder deployment. Ternarization has emerged as a promising compression technique, offering significant reductions in model size and inference complexity. However, existing methods struggle with heavy-tailed activation distributions and therefore keep activations in high precision, fundamentally limiting end-to-end inference acceleration. To overcome this limitation, we propose TWLA, a post-training quantization (PTQ) framework that achieves 1.58-bit weight compression and 4-bit activation quantization while maintaining high accuracy. TWLA comprises three components: (1) Euclidean-to-Manifold Asymmetric Ternary Quantizer (E2M-ATQ) minimizes layer-output error under weight ternarization via a two-stage optimization from Euclidean initialization to manifold relocation; (2) Kronecker Orthogonal Tri-Modal Shaping (KOTMS) applies a Kronecker-structured orthogonal rotation to reshape weights into ternary-friendly tri-modal distributions, while the shared rotation statistically suppresses activation outliers; and (3) Inter-Layer Aware Activation Mixed Precision (ILA-AMP) explicitly introduces adjacent-layer second-order interaction costs in bit allocation and jointly optimizes for the layer-wise disparity of activation quantization gains induced by the shared orthogonal transform, preventing cascades triggered by a few weak layers. Extensive experiments demonstrate that TWLA maintains high accuracy under W1.58A4, while delivering significant inference acceleration. The code is available at <https://github.com/Kishon-zzx/TWLA>.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TWLA, a post-training quantization framework for LLMs that achieves 1.58-bit ternary weights and 4-bit activations while preserving high accuracy. It consists of three components: E2M-ATQ (a two-stage Euclidean-to-manifold optimization for layer-output error minimization under ternarization), KOTMS (Kronecker-structured orthogonal rotation to produce tri-modal weight distributions that also statistically suppresses activation outliers), and ILA-AMP (inter-layer aware mixed-precision activation bit allocation that accounts for second-order interactions and shared-transform effects). Experiments are claimed to demonstrate maintained accuracy under W1.58A4 with inference acceleration; code is released.
Significance. If the accuracy claims under W1.58A4 hold with rigorous verification, the work would advance practical end-to-end low-bit LLM inference by addressing the activation outlier barrier that has limited prior ternarization methods. Code availability strengthens reproducibility.
major comments (2)
- [KOTMS] KOTMS section: the claim that the shared Kronecker orthogonal rotation 'statistically suppresses activation outliers' sufficiently for reliable 4-bit quantization lacks any bound on the dynamic-range reduction factor, any analysis of interaction between the tri-modal weight constraint and activation moments, and any ablation isolating this effect from ILA-AMP. This is load-bearing for the central W1.58A4 accuracy-maintenance claim.
- [Experiments] Experiments section: without reported ablations or quantitative measurements (e.g., 99.9th-percentile reduction factor) showing that outlier suppression reaches the ~4-8x level typically required to avoid clipping loss in 4-bit quantization, the accuracy results cannot be attributed to KOTMS rather than the other components or post-hoc tuning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the KOTMS component and its experimental validation. We address the two major comments below and commit to revisions that strengthen the manuscript with the requested analyses and measurements.
read point-by-point responses
-
Referee: [KOTMS] KOTMS section: the claim that the shared Kronecker orthogonal rotation 'statistically suppresses activation outliers' sufficiently for reliable 4-bit quantization lacks any bound on the dynamic-range reduction factor, any analysis of interaction between the tri-modal weight constraint and activation moments, and any ablation isolating this effect from ILA-AMP. This is load-bearing for the central W1.58A4 accuracy-maintenance claim.
Authors: We agree that additional analysis would strengthen the presentation. In the revision we will derive a bound on the dynamic-range reduction factor induced by the Kronecker-structured orthogonal rotation, provide a short analysis of the interaction between the resulting tri-modal weight distribution and the first two moments of the activations, and add an ablation that isolates KOTMS from ILA-AMP by comparing W1.58A4 accuracy with and without the shared rotation while keeping all other components fixed. revision: yes
-
Referee: [Experiments] Experiments section: without reported ablations or quantitative measurements (e.g., 99.9th-percentile reduction factor) showing that outlier suppression reaches the ~4-8x level typically required to avoid clipping loss in 4-bit quantization, the accuracy results cannot be attributed to KOTMS rather than the other components or post-hoc tuning.
Authors: We will augment the experiments section with the requested quantitative measurements, specifically reporting the 99.9th-percentile activation-range reduction factor achieved by KOTMS across the evaluated models. We will also include the ablation results described above, which directly quantify the outlier-suppression contribution of KOTMS and confirm that the observed reduction is sufficient to support reliable 4-bit activation quantization. revision: yes
Circularity Check
No circularity: framework claims rest on novel components with external code
full rationale
The paper presents TWLA as a new three-component PTQ framework (E2M-ATQ, KOTMS, ILA-AMP) whose central claims about W1.58A4 accuracy are tied to the proposed algorithms and their statistical effects rather than any self-definition, fitted-input prediction, or load-bearing self-citation chain. The abstract explicitly positions the outlier suppression as a consequence of the shared Kronecker rotation (a design choice, not a tautology) and makes the implementation available at an external GitHub link, allowing independent verification. No equations or prior-author citations are invoked in a way that reduces the derivation to its inputs by construction. This is the normal case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ashkboos, S., Mohtashami, A., Croci, M
doi: 10.1109/IJCNN.2017.7966166. Ashkboos, S., Mohtashami, A., Croci, M. L., Li, B., Cameron, P., Jaggi, M., Alistarh, D., Hoefler, T., and Hensman, J. Quarot: Outlier-free 4-bit inference in ro- tated llms.Advances in Neural Information Processing Systems, 37:100213–100240,
-
[2]
Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H
URL https://arxiv.org/abs/ 1911.11641. Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavar- ian, M., Winter, C., Tillet, P., S...
Pith/arXiv arXiv 1911
-
[3]
Chen, T., Li, Z., Xu, W., Zhu, Z., Li, D., Tian, L., Barsoum, E., Wang, P., and Cheng, J
URL https://arxiv.org/abs/ 2107.03374. Chen, T., Li, Z., Xu, W., Zhu, Z., Li, D., Tian, L., Barsoum, E., Wang, P., and Cheng, J. Ternaryllm: Ternarized large language model,
-
[4]
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O
URL https://arxiv.org/ abs/2406.07177. Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge,
-
[5]
URL https://arxiv.org/abs/ 1803.05457. Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems,
-
[6]
URL https://arxiv. org/abs/2110.14168. Dettmers, T., Svirschevski, R., Egiazarian, V ., Kuznedelev, D., Frantar, E., Ashkboos, S., Borzunov, A., Hoefler, T., and Alistarh, D. Spqr: A sparse-quantized representation for near-lossless llm weight compression,
-
[7]
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D
URL https://arxiv.org/abs/2306.03078. Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. Gptq: Accurate post-training quantization for generative pre- trained transformers,
-
[8]
URL https://arxiv. org/abs/2210.17323. Gu, H., Hu, L., Yu, L., Li, H., and Liu, F. Lopro: Enhanc- ing low-rank quantization via permuted block-wise rota- tion,
-
[9]
doi: 10.1145/3649329. 3658498. URL http://dx.doi.org/10.1145/ 3649329.3658498. Gul, H., Hu, L., Niu, S., and Liu, F. Flrq: Faster llm quan- tization with flexible low-rank matrix sketching,
-
[10]
URLhttps://arxiv.org/abs/2601.05684. Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., Zhang, X., Yu, X., Wu, Y ., Wu, Z. F., Gou, Z., Shao, Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B., Feng, B., Lu, C., Zhao, C., Deng, C., Ruan, C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Luo, F., Hao, ...
-
[11]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
ISSN 1476-4687. doi: 10.1038/s41586-025-09422-z. URL http://dx. doi.org/10.1038/s41586-025-09422-z. Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding,
-
[12]
Huang, W., Qin, H., Liu, Y ., Li, Y ., Liu, Q., Liu, X., Benini, L., Magno, M., Zhang, S., and Qi, X
URL https: //arxiv.org/abs/2009.03300. Huang, W., Qin, H., Liu, Y ., Li, Y ., Liu, Q., Liu, X., Benini, L., Magno, M., Zhang, S., and Qi, X. Slim-llm: Salience- driven mixed-precision quantization for large language models.arXiv preprint arXiv:2405.14917,
Pith/arXiv arXiv 2009
-
[13]
Li, M., Zhang, D., He, T., Xie, X., Li, Y .-F., and Qin, K
URL https://arxiv.org/ abs/1605.04711. Li, M., Zhang, D., He, T., Xie, X., Li, Y .-F., and Qin, K. Towards effective data-free knowledge distillation via diverse diffusion augmentation. InProceedings of the 32nd ACM International Conference on Multimedia, pp. 4416–4425, 2024a. Li, M., Zhang, D., Dong, Q., Xie, X., and Qin, K. Adaptive dataset quantization...
-
[14]
Li, Z., Yan, X., Zhang, T., Qin, H., Xie, D., Tian, J., Kong, L., Zhang, Y ., Yang, X., et al. Arb-llm: Alternating refined binarizations for large language models.arXiv preprint arXiv:2410.03129, 2024b. Liu, K., Yang, K., Chen, Z., Li, Z., Guo, Y ., Li, W., Kong, L., and Zhang, Y . Bimacosr: Binary one-step diffusion model leveraging flexible matrix comp...
-
[15]
Merity, S., Xiong, C., Bradbury, J., and Socher, R
URL https://arxiv.org/ abs/2502.00333. Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843,
-
[16]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., and Liu, P
URL https: //arxiv.org/abs/1606.06031. Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., and Liu, P. J. Explor- ing the limits of transfer learning with a unified text-to- text transformer,
-
[17]
URL https://arxiv.org/ abs/1910.10683. Sakaguchi, K., Bras, R. L., Bhagavatula, C., and Choi, Y . Winogrande: An adversarial winograd schema challenge at scale,
Pith/arXiv arXiv 1910
-
[18]
Saxena, U., Sharify, S., Roy, K., and Wang, X
URL https://arxiv.org/abs/ 1907.10641. Saxena, U., Sharify, S., Roy, K., and Wang, X. Resq: Mixed- precision quantization of large language models with low- rank residuals.arXiv preprint arXiv:2412.14363,
Pith/arXiv arXiv 1907
-
[19]
URL https: //arxiv.org/abs/2310.00034. Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi `ere, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G. Llama: Open and efficient foundation lan- guage models,
-
[20]
URL https://arxiv.org/ abs/2302.13971. Wang, H., Ma, S., and Wei, F. Bitnet v2: Native 4-bit activa- tions with hadamard transformation for 1-bit llms,
-
[21]
Wang, P., Hu, Q., Zhang, Y ., Zhang, C., Liu, Y ., and Cheng, J
URLhttps://arxiv.org/abs/2504.18415. Wang, P., Hu, Q., Zhang, Y ., Zhang, C., Liu, Y ., and Cheng, J. Two-step quantization for low-bit neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June
-
[22]
URLhttps://arxiv.org/abs/2511.22316. 11 TWLA: Achieving Ternary Weights and Low-Bit Activations for LLMs via Post-Training Quantization Xu, Z., Zhao, Z., Hu, X., Chen, Z., and Yang, D. Kbvq- moe: Klt-guided svd with bias-corrected vector quanti- zation for moe large language models.arXiv preprint arXiv:2602.11184,
-
[23]
URL https://arxiv.org/abs/2510.03267. Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M...
-
[24]
Zhang, W., Hou, L., Yin, Y ., Shang, L., Chen, X., Jiang, X., and Liu, Q
URL https://arxiv.org/abs/ 1905.07830. Zhang, W., Hou, L., Yin, Y ., Shang, L., Chen, X., Jiang, X., and Liu, Q. Ternarybert: Distillation-aware ultra-low bit bert,
Pith/arXiv arXiv 1905
-
[25]
URL https://arxiv.org/abs/2009. 12812. Zhao, Z., Li, H., Liu, F., Lu, Y ., Wang, Z., Yang, T., Jiang, L., and Guan, H. Quark: Quantization-enabled circuit sharing for transformer acceleration by exploiting com- mon patterns in nonlinear operations. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD), pp. 1–9. IEEE,
2009
-
[26]
Specquant: Spectral decomposition and adaptive truncation for ultra-low-bit llms quantization
Zhao, Z., Liu, F., Wang, J., Guan, C., Wang, Z., Jiang, L., and Guan, H. Specquant: Spectral decomposition and adaptive truncation for ultra-low-bit llms quantization. In Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 40, pp. 28786–28794, 2026a. Zhao, Z., Xu, Z., and Yang, D. Bwla: Breaking the barrier of w1ax post-training quanti...
-
[27]
URL https://arxiv. org/abs/1612.01064. Zhu, C., Lin, Y ., Shao, J., Lin, J., and Wang, Y . Pathology- aware prototype evolution via llm-driven semantic disam- biguation for multicenter diabetic retinopathy diagnosis. InProceedings of the 33rd ACM International Confer- ence on Multimedia, pp. 9196–9205,
-
[28]
The storage reduction factor is therefore m2 n2 1 +n 2 2 = 16,777,216 8192 = 2048.(57) Thus, the Kronecker parameterization is2048×smaller in storage than a dense4096×4096transform
yields only n2 1 +n 2 2 = 642 + 642 = 8192(56) entries. The storage reduction factor is therefore m2 n2 1 +n 2 2 = 16,777,216 8192 = 2048.(57) Thus, the Kronecker parameterization is2048×smaller in storage than a dense4096×4096transform. B.3.3. FAST APPLICATION VIA RESHAPE–MULTIPLY–VECTORIZE Let v∈R 1×m. Reshape it into a matrix V∈R n1×n2 such that vec(V)...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.