Functional Cache Grafting: Robust and Rapid Code-Policy Synthesis for Embodied Agents
Pith reviewed 2026-06-27 05:25 UTC · model grok-4.3
The pith
FCGraft grafts function-level KV caches to synthesize robust code policies for embodied agents faster than full regeneration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
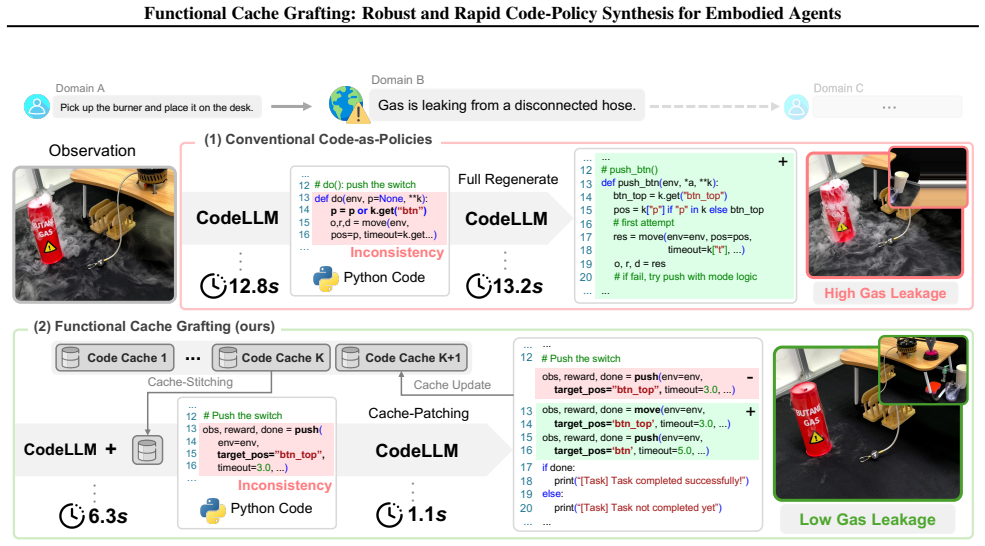
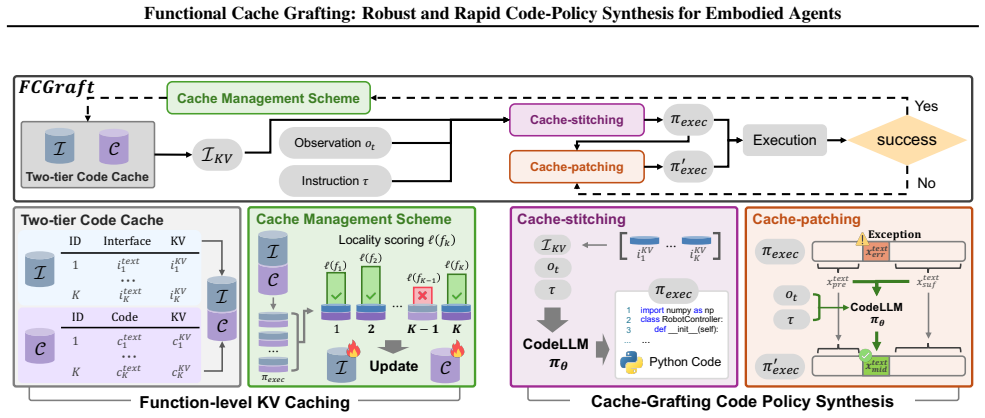
FCGraft maintains a library of function-level validated code skeletons and their associated prompt-level Transformer key-value caches, and synthesizes new policies by retrieving relevant functions and grafting their KV caches when a new task is provided, performing cache grafting via stitching to compose cached function segments and patching to locally adapt only necessary code regions with minimal additional decoding.
What carries the argument
Functional cache grafting, which retrieves function skeletons and their KV caches then stitches them into composite policies while patching only task-specific parts with limited new decoding.
If this is right
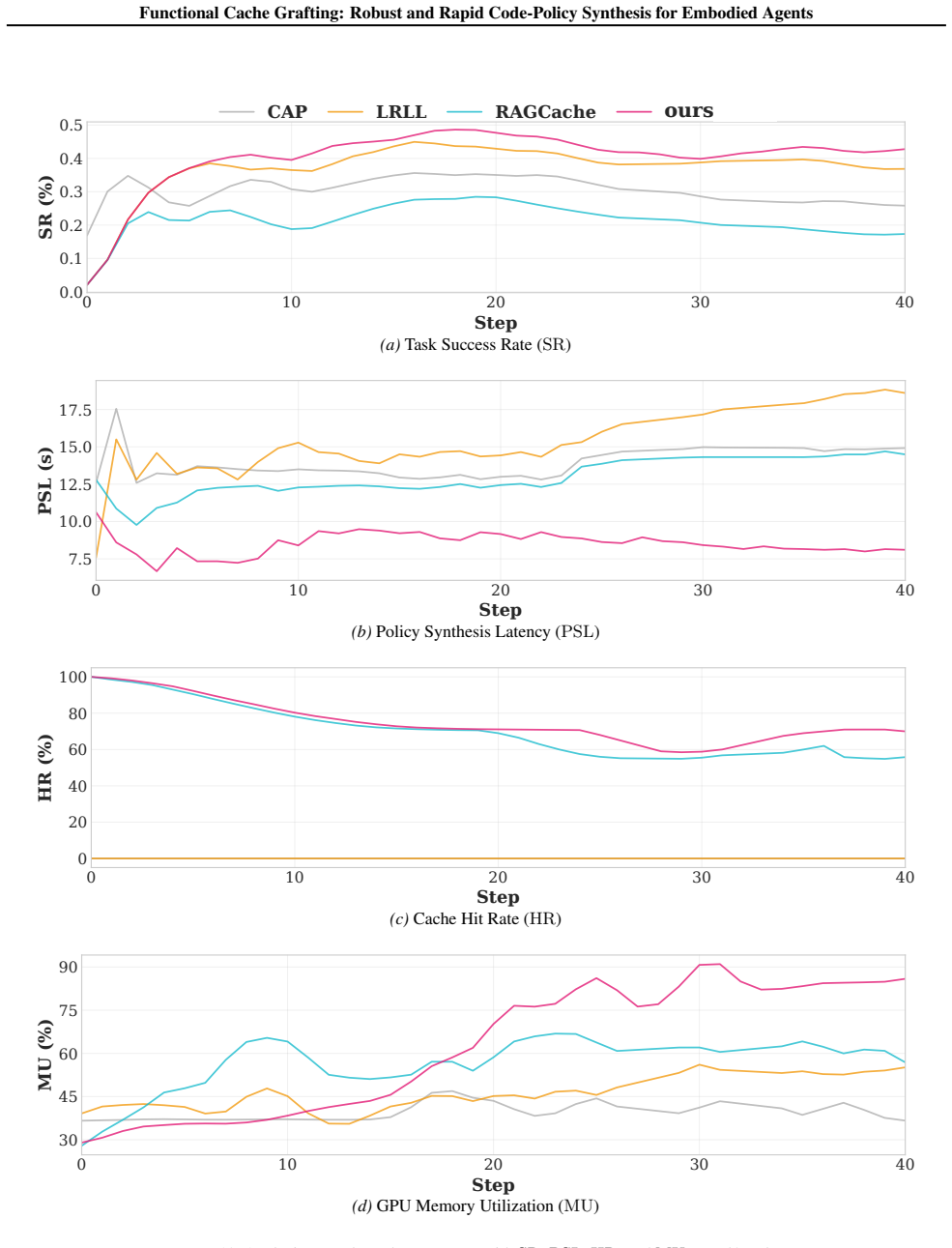
- Redundant prefill computation over long prompts is eliminated, lowering generation latency.
- Reusing validated control structures and safety guards raises overall policy robustness.
- Task success rate increases by 18.31 percent relative to prompt-level caching baselines.
- Policy synthesis speed improves by a factor of 2.3 over prompt-level methods.
- New policies satisfy environmental constraints with only localized changes rather than full regeneration.
Where Pith is reading between the lines
- The same grafting pattern could extend to other structured-generation tasks such as API call sequences or planning scripts.
- Library coverage would need periodic expansion or versioning to handle evolving environments without performance loss.
- The speed and reliability gains rest on how well the retrieval step matches functions to new task descriptions.
Load-bearing premise
Relevant functions can be reliably retrieved from the library and their KV caches can be stitched and patched while preserving correctness and satisfying task-specific constraints.
What would settle it
A controlled test in which retrieved functions frequently produce invalid stitched policies or require so much additional decoding that the claimed latency reduction disappears would falsify the central claim.
Figures





read the original abstract
Code-writing large language models (CodeLLMs) generate executable code policies for embodied agents by translating natural language goals and environmental constraints into structured control programs. However, policy generation in open-domain embodied environments suffers from two fundamental limitations: (i) delayed decoding caused by repetitive prefill computation over long prompts, and (ii) limited robustness due to fully generative decoding, which often produces API mismatches, missing safety guards, and unstable control logic. To address these limitations, we present FCGraft, a Functional Cache Grafting framework. FCGraft maintains a library of function-level validated code skeletons and their associated prompt-level Transformer key-value (KV) caches, and synthesizes new policies by retrieving relevant functions and grafting their KV caches when a new task is provided. Given retrieved function caches, FCGraft performs cache grafting via stitching, which composes cached function segments into a composite policy, and patching, which locally adapts only the necessary code regions to satisfy task-specific parameters and constraints with minimal additional decoding. By eliminating redundant prefill computation, this approach reduces generation latency, while reusing validated control structures improves robustness over prompt-level caching methods RAGCache, achieving 18.31% higher task success rate and 2.3x faster policy synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FCGraft, a Functional Cache Grafting framework for CodeLLMs that synthesizes executable code policies for embodied agents. It maintains a library of function-level validated code skeletons paired with their prompt-level Transformer KV caches; for a new task, relevant functions are retrieved and their caches are grafted via stitching (composing cached segments into a composite policy) and patching (local adaptation of code regions to satisfy task-specific constraints with minimal additional decoding). The approach is claimed to eliminate redundant prefill computation, yielding 18.31% higher task success rate and 2.3x faster policy synthesis than prompt-level methods such as RAGCache while improving robustness through reuse of validated control structures.
Significance. If the grafting mechanism is shown to preserve policy correctness, the work could meaningfully advance efficient, real-time code synthesis for embodied agents by combining modularity with KV-cache reuse. The function-level library and validated skeletons represent a concrete step beyond prompt-level caching, with potential applicability to other CodeLLM settings that require both speed and reliability.
major comments (2)
- [Abstract] Abstract: the central performance claims (18.31% higher task success rate, 2.3x faster synthesis) are stated without any experimental details, task count, baselines beyond RAGCache, statistical tests, variance, or error analysis. This directly affects verifiability of the primary empirical contribution.
- [Abstract] Abstract (grafting description): the stitching and patching procedure is presented as preserving correctness with only minimal additional decoding, yet no argument, derivation, or ablation addresses whether KV-cache concatenation at function boundaries yields identical logits to a full forward pass. Cross-segment attention dependencies, variable-length prefixes, and control-flow differences can alter subsequent attention scores, undermining the robustness and latency claims.
minor comments (1)
- [Abstract] Abstract: the library-construction process (how validated skeletons and caches are initially obtained and stored) is not described even at a high level.
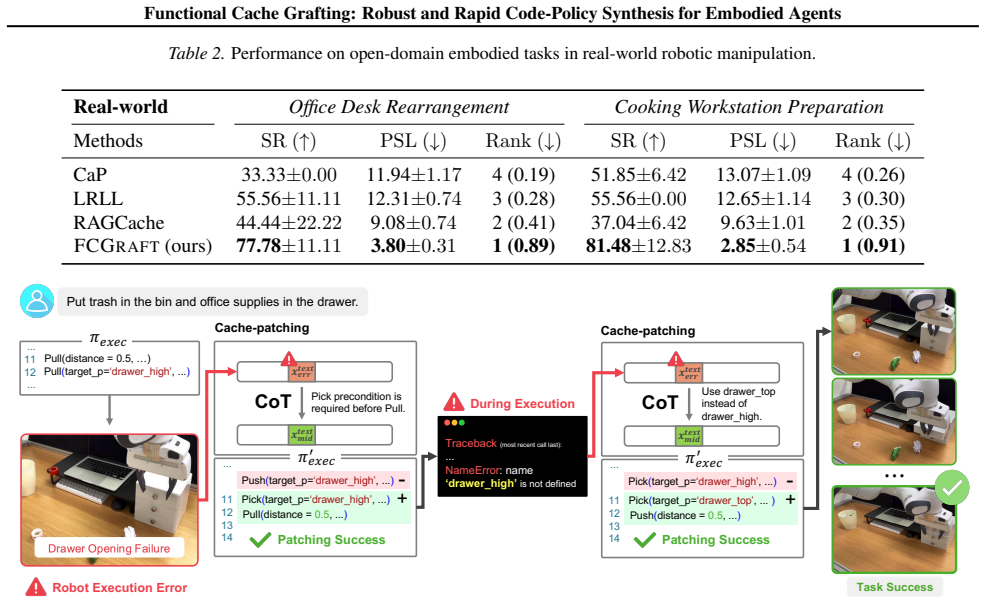
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (18.31% higher task success rate, 2.3x faster synthesis) are stated without any experimental details, task count, baselines beyond RAGCache, statistical tests, variance, or error analysis. This directly affects verifiability of the primary empirical contribution.
Authors: We agree the abstract's brevity limits immediate verifiability. The full manuscript reports results over 50 tasks in three embodied environments, with comparisons to RAGCache plus two additional baselines, five-run averages, and statistical significance tests in Sections 4 and 5. We will revise the abstract to state the task count and note multi-run evaluation with variance. revision: yes
-
Referee: [Abstract] Abstract (grafting description): the stitching and patching procedure is presented as preserving correctness with only minimal additional decoding, yet no argument, derivation, or ablation addresses whether KV-cache concatenation at function boundaries yields identical logits to a full forward pass. Cross-segment attention dependencies, variable-length prefixes, and control-flow differences can alter subsequent attention scores, undermining the robustness and latency claims.
Authors: This observation is valid. The current manuscript provides only empirical evidence of higher success rates and reduced latency; it contains no formal derivation showing that grafted KV segments produce identical logits, nor an ablation isolating cross-segment attention effects. We will add a discussion of the approximation and a limited empirical comparison of attention scores, but a complete theoretical argument lies outside the present scope. revision: partial
- A formal derivation proving that function-boundary KV-cache grafting yields logits identical to a full forward pass under arbitrary cross-segment attention.
Circularity Check
No circularity: method is a constructive engineering proposal with no equations or self-referential derivations
full rationale
The paper presents FCGraft as an algorithmic framework that maintains a library of function-level code skeletons and KV caches, then applies stitching and patching for new policies. No mathematical derivations, equations, fitted parameters, or uniqueness theorems appear in the provided text. The performance claims (18.31% higher success, 2.3x faster synthesis) are presented as empirical outcomes of the method rather than predictions derived from prior results by the same authors. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results are present. The central description is self-contained as an engineering contribution whose validity rests on external evaluation, not on internal reduction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient Training of Language Models to Fill in the Middle
Bavarian, M., Jun, H., Tezak, N., Schulman, J., McLeavey, C., Tworek, J., and Chen, M. Efficient training of language models to fill in the middle.arXiv preprint arXiv:2207.14255,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
J., Chen, C.-T., Cheng, J.-H., and Huang, H.-H
Chan, B. J., Chen, C.-T., Cheng, J.-H., and Huang, H.-H. Don’t do rag: When cache-augmented generation is all you need for knowledge tasks. InCompanion Proceed- ings of the ACM on Web Conference 2025, pp. 893–897,
2025
-
[3]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Choi, W., Park, J., Ahn, S., Lee, D., and Woo, H. Nesyc: A neuro-symbolic continual learner for complex embodied tasks in open domains.arXiv preprint arXiv:2503.00870,
-
[5]
Chon, H., Lee, S., Yeo, J., and Lee, D. Is functional correctness enough to evaluate code language models? exploring diversity of generated codes.arXiv preprint arXiv:2408.14504,
-
[6]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Guo, D., Zhu, Q., Yang, D., Xie, Z., Dong, K., Zhang, W., Chen, G., Bi, X., Wu, Y ., Li, Y ., et al. Deepseek-coder: When the large language model meets programming–the rise of code intelligence.arXiv preprint arXiv:2401.14196,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Guo, T., Dong, H., Leng, Y ., Liu, F., Lin, C., Xiao, N., and Zhang, X. Efim: Efficient serving of llms for infill- ing tasks with improved kv cache reuse.arXiv preprint arXiv:2505.21889,
-
[8]
Contextual Markov Decision Processes
Hallak, A., Di Castro, D., and Mannor, S. Con- textual markov decision processes.arXiv preprint arXiv:1502.02259,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Let the code llm edit itself when you edit the code.arXiv preprint arXiv:2407.03157,
He, Z., Zhang, J., Luo, S., Xu, J., Zhang, Z., and He, D. Let the code llm edit itself when you edit the code.arXiv preprint arXiv:2407.03157,
- [10]
-
[11]
Huang, S., Jiang, Z., Dong, H., Qiao, Y ., Gao, P., and Li, H. Instruct2act: Mapping multi-modality instructions to 10 Functional Cache Grafting: Robust and Rapid Code-Policy Synthesis for Embodied Agents robotic actions with large language model.arXiv preprint arXiv:2305.11176, 2023a. Huang, W., Abbeel, P., Pathak, D., and Mordatch, I. Lan- guage models ...
-
[12]
Jin, C., Zhang, Z., Jiang, X., Liu, F., Liu, X., Liu, X., and Jin, X. Ragcache: Efficient knowledge caching for retrieval- augmented generation.arXiv preprint arXiv:2404.12457,
-
[13]
J., Lou, Y ., Karlekar, J., Pranata, S., Ki- nose, A., Oguri, K., Wick, F., and You, Y
Kagaya, T., Yuan, T. J., Lou, Y ., Karlekar, J., Pranata, S., Ki- nose, A., Oguri, K., Wick, F., and You, Y . Rap: Retrieval- augmented planning with contextual memory for mul- timodal llm agents.arXiv preprint arXiv:2402.03610,
-
[14]
Think before you act: Decision transformers with working memory.arXiv preprint arXiv:2305.16338,
Kang, J., Laroche, R., Yuan, X., Trischler, A., Liu, X., and Fu, J. Think before you act: Decision transformers with working memory.arXiv preprint arXiv:2305.16338,
-
[15]
Li, J., Li, G., Li, Y ., and Jin, Z. Structured chain-of- thought prompting for code generation.ACM Transac- tions on Software Engineering and Methodology, 34(2): 1–23, 2025a. Li, Y ., Wang, L., Piao, S., Yang, B.-H., Li, Z., Zeng, W., and Tsung, F. Mccoder: streamlining motion control with llm-assisted code generation and rigorous verification. arXiv pre...
-
[16]
Li, Z., Xie, Y ., Shao, R., Chen, G., Jiang, D., and Nie, L. Optimus-2: Multimodal minecraft agent with goal- observation-action conditioned policy.arXiv preprint arXiv:2502.19902, 2025b. Liang, C., Feng, Z., Liu, Z., Jiang, W., Xu, J., Chen, Y ., and Wang, Y . Textualized agent-style reasoning for complex tasks by multiple round llm generation.arXiv prep...
-
[17]
Mell: Memory-efficient large language model serving via multi- gpu kv cache management
Liu, Q., Hong, Z., Li, P., Chen, F., and Guo, S. Mell: Memory-efficient large language model serving via multi- gpu kv cache management. InIEEE INFOCOM 2025- IEEE Conference on Computer Communications, pp. 1–
2025
-
[18]
Lu, S., Wang, H., Rong, Y ., Chen, Z., and Tang, Y . Turborag: Accelerating retrieval-augmented generation with pre- computed kv caches for chunked text.arXiv preprint arXiv:2410.07590,
-
[19]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
Nijkamp, E., Pang, B., Hayashi, H., Tu, L., Wang, H., Zhou, Y ., Savarese, S., and Xiong, C. Codegen: An open large language model for code with multi-turn program synthe- sis.arXiv preprint arXiv:2203.13474,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Teach: Task-driven embodied agents that chat
Padmakumar, A., Thomason, J., Shrivastava, A., Lange, P., Narayan-Chen, A., Gella, S., Piramuthu, R., Tur, G., and Hakkani-Tur, D. Teach: Task-driven embodied agents that chat. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 2017–2025,
2017
-
[21]
Residual skill policies: Learning an adaptable skill-based action space for reinforcement learning for robotics
Rana, K., Xu, M., Tidd, B., Milford, M., and S¨underhauf, N. Residual skill policies: Learning an adaptable skill-based action space for reinforcement learning for robotics. In Conference on Robot Learning, pp. 2095–2104. PMLR,
2095
-
[22]
Code Llama: Open Foundation Models for Code
Roziere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., Adi, Y ., Liu, J., Sauvestre, R., Remez, T., et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Sarch, G., Wu, Y ., Tarr, M. J., and Fragkiadaki, K. Open-ended instructable embodied agents with memory- augmented large language models.arXiv preprint arXiv:2310.15127,
-
[24]
Sarch, G., Somani, S., Kapoor, R., Tarr, M. J., and Fragki- adaki, K. Helper-x: A unified instructable embod- ied agent to tackle four interactive vision-language do- mains with memory-augmented language models.arXiv preprint arXiv:2404.19065,
-
[25]
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
Singh, I., Blukis, V ., Mousavian, A., Goyal, A., Xu, D., Tremblay, J., Fox, D., Thomason, J., and Garg, A. Prog- prompt: Generating situated robot task plans using large language models.arXiv preprint arXiv:2209.11302,
work page internal anchor Pith review Pith/arXiv arXiv
- [26]
-
[27]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Wolf, T., Debut, L., Sanh, V ., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., et al. Huggingface’s transformers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[28]
A-MEM: Agentic Memory for LLM Agents
Xu, W., Mei, K., Gao, H., Tan, J., Liang, Z., and Zhang, Y . A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Zhao, S., Hu, J., Huang, R., Zheng, J., and Chen, G. Mpic: Position-independent multimodal context caching system for efficient mllm serving.arXiv preprint arXiv:2502.01960,
-
[30]
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
Zhou, A., Yan, K., Shlapentokh-Rothman, M., Wang, H., and Wang, Y .-X. Language agent tree search unifies reasoning acting and planning in language models.arXiv preprint arXiv:2310.04406,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
Zhu, Q., Guo, D., Shao, Z., Yang, D., Wang, P., Xu, R., Wu, Y ., Li, Y ., Gao, H., Ma, S., et al. Deepseek-coder- v2: Breaking the barrier of closed-source models in code intelligence.arXiv preprint arXiv:2406.11931,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Move a plunger to the cabinet
This diversity makes ALFRED a particularly suitable benchmark for evaluating agents on hierarchical reasoning, multi-step planning, and generalization across varied contexts. Environment.To better emulate open-domain deployment, we design three long-horizon evaluation scenarios on top of ALFRED. (1) Inopen-composition, tasks are organized into a curriculu...
2023
-
[33]
Water the plant
spans 109 unique scenes across all 30 kitchens and most of the 30 living rooms, bedrooms, and bathrooms in AI2-THOR, comprising 3215 successful human-human gameplay sessions with rich conversational data (˜45k utterances averaging 13.67 per session) and long action trajectories (averaging 131.8 Follower actions per session). The dataset covers 12 task fam...
2023
-
[34]
reasoning
introduces position-independent caching with the LegoLink algorithm to enable modular KV reuse beyond prefix matching, significantly improving LLM serving efficiency without sacrificing accuracy. Unless otherwise noted, all baselines use the same CodeLLM configuration (max new tokens = 2048, temperature = 0.0, i.e., 21 Functional Cache Grafting: Robust an...
2048
-
[35]
Table 12.Hyperparameters (decoding and framework-level). Model generation hyperparameters max new tokens 2048 temperature 0.0 (greedy) top-k, top-pN/A (greedy; not used) Framework-level hyperparameters Eviction threshold (perplexity-based)τ=15.0 Locality weights (α: temporal,β: spatial,γ: semantic)α= 0.4,β= 0.3,γ= 0.3 Execution trace length 20 Temporal de...
2048
-
[36]
It compares FCGRAFT across different CodeLLM sizes and cache-patching configurations. We evaluate the default setting (CoT-guided cache-patching) against two ablated variants: without CoT and with expert guidance replaced. As model size increases from 3B to 14B, FCGRAFT consistently achieves higherSR(26.57%, 44.50%, 53.75%) andGC(38.36%, 58.14%, 66.54%), ...
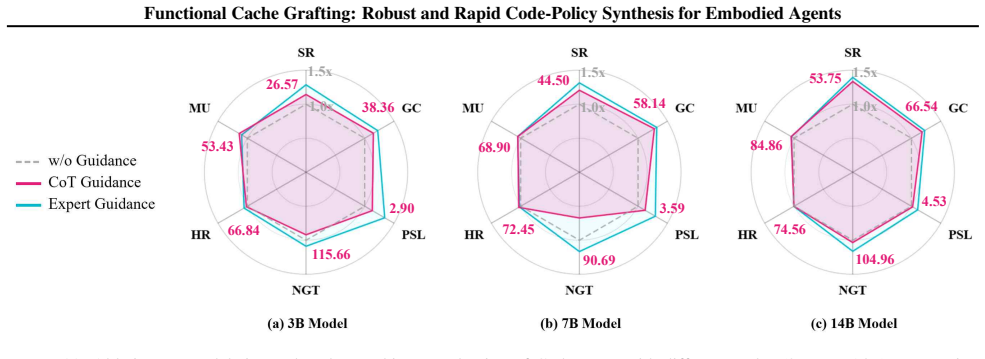
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.