Learning-Augmented Approximation for Unrelated-Machines Makespan Scheduling
Pith reviewed 2026-06-27 05:19 UTC · model grok-4.3
The pith
Predictions of heavy job assignments give a (1+ε) approximation for unrelated-machines makespan that degrades to 2-approximation with error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By using predictions of heavy job assignments, the algorithm achieves a polynomial-time (1+ε)-approximation for accurate predictions that smoothly degrades to a worst-case 2-approximation as the error increases for the R||C_max problem.
What carries the argument
Learning-augmented algorithm that incorporates predictions of heavy job assignments to guide the assignment of jobs to machines.
If this is right
- The algorithm returns a solution whose makespan is at most (1+ε) times optimal whenever the predictions correctly identify the machines for heavy jobs.
- The approximation ratio increases continuously with prediction error and never exceeds 2.
- The running time remains polynomial for any fixed ε.
- The method supplies the first learning-augmented constant-factor guarantee for this scheduling problem.
Where Pith is reading between the lines
- The same prediction style might be tested on related or identical parallel-machine variants to check whether the degradation property transfers.
- If predictors for job-machine affinities can be trained cheaply, the approach suggests a practical route to near-optimal schedules on large instances.
- The construction leaves open whether a similar prediction interface works for other non-selection problems such as bin packing or graph coloring.
Load-bearing premise
The selection-problem framework can be generalized to unrelated-machines makespan scheduling by means of predictions that identify heavy job assignments.
What would settle it
A family of instances in which the observed approximation ratio exceeds 2 even when predictions are completely erroneous, or fails to reach (1+ε) when predictions match the optimal assignment for all heavy jobs.
Figures
read the original abstract
Recently, Antoniadis et al. (ICLR 2025) proposed a framework for incorporating predictions to approximate NP-hard selection problems. Despite its simplicity, this approach tightly matches theoretical lower bounds, making its generalization highly compelling. We address an open question raised in the work of Antoniadis et al., concerning the extension of this approach to other important problems outside the class of selection problems, such as scheduling. We develop a learning-augmented algorithm for the makespan minimization problem on unrelated machines, denoted by $R\|C_{\max}$. By using predictions of heavy job assignments, we achieve a polynomial-time $(1+\varepsilon)$-approximation for accurate predictions that smoothly degrades to a worst-case 2-approximation as the error increases. We conclude our work with an empirical analysis of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a learning-augmented algorithm for the unrelated-machines makespan minimization problem R||C_max. By using predictions of heavy job assignments, the algorithm achieves a polynomial-time (1+ε)-approximation when predictions are accurate and degrades smoothly to the standard 2-approximation as prediction error grows. The work generalizes the prediction framework of Antoniadis et al. (ICLR 2025) from selection problems to scheduling and concludes with an empirical analysis.
Significance. If the guarantees hold, the result is significant because it directly addresses an open question from Antoniadis et al. by extending their framework to a canonical scheduling problem outside the selection-problem class. The smooth interpolation between learned and worst-case performance, combined with polynomial runtime, is a substantive contribution. The paper explicitly credits the prior framework and supplies empirical validation, both of which strengthen the assessment.
major comments (1)
- Abstract: the central claim of a polynomial-time (1+ε)-approximation that degrades to 2 is stated without any derivation, error-measure definition, or proof sketch, so the load-bearing technical content cannot be verified from the provided text.
minor comments (1)
- The specific prediction-error model and the precise manner in which the approximation ratio interpolates between (1+ε) and 2 should be defined in the introduction rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for their review and for recognizing the potential significance of extending the learning-augmented framework to scheduling. We address the major comment below.
read point-by-point responses
-
Referee: Abstract: the central claim of a polynomial-time (1+ε)-approximation that degrades to 2 is stated without any derivation, error-measure definition, or proof sketch, so the load-bearing technical content cannot be verified from the provided text.
Authors: The abstract is intended as a concise high-level summary, per standard conventions for theoretical papers. The prediction error measure (discrepancy on heavy job assignments) is formally defined in the manuscript, the algorithm is described in full, and the proof establishing the (1+ε) guarantee under accurate predictions together with smooth degradation to the 2-approximation is contained in the main body. The full text therefore permits verification of the central claims. revision: no
Circularity Check
No significant circularity
full rationale
The paper explicitly generalizes an external framework from Antoniadis et al. (ICLR 2025) with distinct authors to the unrelated-machines makespan problem via heavy-job-assignment predictions. The stated guarantees ((1+ε) for accurate predictions degrading to the known 2-approximation) are presented as a direct extension addressing an open question from that prior work. No self-citations, self-definitional steps, fitted inputs renamed as predictions, or ansatz smuggling appear in the abstract or description. The derivation chain is self-contained against the external benchmark and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The prediction-augmented framework developed for selection problems extends to unrelated-machine scheduling via heavy-job assignment predictions.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/j.ejor.2022.11.034
ISSN 0377-2217. doi: 10.1016/j.ejor.2022.11.034. Braverman, V ., Dharangutte, P., Shah, V ., and Wang, C. Learning-augmented maximum indepen- dent set. InApproximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques (APPROX/RANDOM), volume 317 ofLeibniz International Proceedings in Informat- ics (LIPIcs), pp. 24:1–24:18. Schloss ...
-
[2]
doi: 10.4230/LIPIcs.APPROX/RANDOM.2024.24
ISBN 978-3-95977-348-5. doi: 10.4230/LIPIcs.APPROX/RANDOM.2024.24. Brucker, P.Scheduling Algorithms. Springer, 5 edition,
-
[3]
doi: 10.1007/978-3-540-69516-5
ISBN 978-3-540-69516-5. doi: 10.1007/978-3-540-69516-5. Cohen-Addad, V ., d'Orsi, T., Gupta, A., Lee, E., and Panigrahi, D. Learning-augmented approximation algorithms for maximum cut and related problems. InAdvances in Neural Information Processing Systems, volume 37, pp. 25961–25980. Curran Associates, Inc.,
-
[4]
doi: 10.52202/079017-0816. Fanjul-Peyro, L. and Ruiz, R. Iterated greedy local search methods for unrelated parallel machine scheduling.European Journal of Operational Research, 207(1):55–69,
-
[5]
doi: 10.1016/j.ejor.2010.03.030
ISSN 0377-2217. doi: 10.1016/j.ejor.2010.03.030. 10 Fanjul-Peyro, L. and Ruiz, R. Size-reduction heuristics for the unrelated parallel machines scheduling problem.Computers & Operations Research, 38(1):301–309,
-
[6]
doi: 10.1016/j.cor.2010.05.005
ISSN 0305-0548. doi: 10.1016/j.cor.2010.05.005. Graham, R., Lawler, E., Lenstra, J., and Kan, A. Optimization and approximation in deterministic sequencing and scheduling: a survey. InDiscrete Optimization II, volume 5 ofAnnals of Discrete Mathematics, pp. 287–326. Elsevier,
-
[7]
Grigorescu, E., Lin, Y .-S., Silwal, S., Song, M., and Zhou, S
doi: 10.1016/S0167-5060(08)70356-X. Grigorescu, E., Lin, Y .-S., Silwal, S., Song, M., and Zhou, S. Learning-augmented algorithms for online linear and semidefinite programming. InAdvances in Neural Information Processing Systems, volume 35, pp. 38643–38654. Curran Associates, Inc.,
-
[8]
Hijazi, A., Ozaltin, O., and Uzsoy, R. All you need is an improving column: Enhancing column generation for parallel machine scheduling via transformers.arXiv preprint arXiv:2410.15601,
-
[9]
doi: 10.1007/s12532-017-0130-5. Im, S., Kumar, R., Petety, A., and Purohit, M. Parsimonious learning-augmented caching. InPro- ceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pp. 9588–9601. PMLR, 17–23 Jul
-
[10]
ISSN 1436-4646. doi: 10.1007/BF01585745. Lykouris, T. and Vassilvitskii, S. Competitive caching with machine learned advice. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pp. 3296–3305. PMLR,
-
[11]
Optimization and Reoptimization in Scheduling Problems
ISSN 0001-0782. doi: 10.1145/3528087. Mordechai, Y . Optimization and reoptimization in scheduling problems.arXiv preprint arXiv:1509.01630,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3528087
-
[12]
doi: 10.1007/978-3-319-26580-3
ISBN 978-3-319-26580-3. doi: 10.1007/978-3-319-26580-3. Purohit, M., Svitkina, Z., and Kumar, R. Improving online algorithms via ML predictions. In Advances in Neural Information Processing Systems, volume
-
[13]
doi: 10.5802/ojmo.4. Rohatgi, D. Near-optimal bounds for online caching with machine learned advice. InProceedings of the 2020 ACM-SIAM Symposium on Discrete Algorithms (SODA), pp. 1834–1845. doi: 10.1137/1. 9781611975994.112. Shmoys, D. B. and Tardos, É. An approximation algorithm for the generalized assignment problem.Mathematical Programming, 62(1):461...
-
[14]
ISSN 1436-4646. doi: 10.1007/BF01585178. 11 Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, ˙I., Feng, Y ., Moore, E. W...
-
[15]
doi: 10.1038/s41592-019-0686-2. Wei, A. Better and simpler learning-augmented online caching. InApproximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques (APPROX/RANDOM), volume 176 ofLeibniz International Proceedings in Informatics (LIPIcs), pp. 60:1–60:17. Schloss Dagstuhl – Leibniz-Zentrum für Informatik,
-
[16]
doi: 10.4230/LIPIcs.APPROX/ RANDOM.2020.60
ISBN 978-3-95977-164-1. doi: 10.4230/LIPIcs.APPROX/ RANDOM.2020.60. A Extended related work A.1 Learning-augmented online algorithms The learning-augmented algorithms framework was developed primarily in the online setting (Mitzen- macher & Vassilvitskii, 2022). The central idea is to augment a worst-case algorithm with predictions, for example from a mac...
-
[17]
The running-time bound is inherited directly from Theorem 5.1
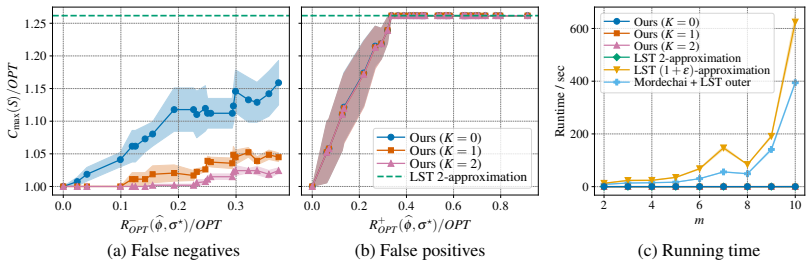
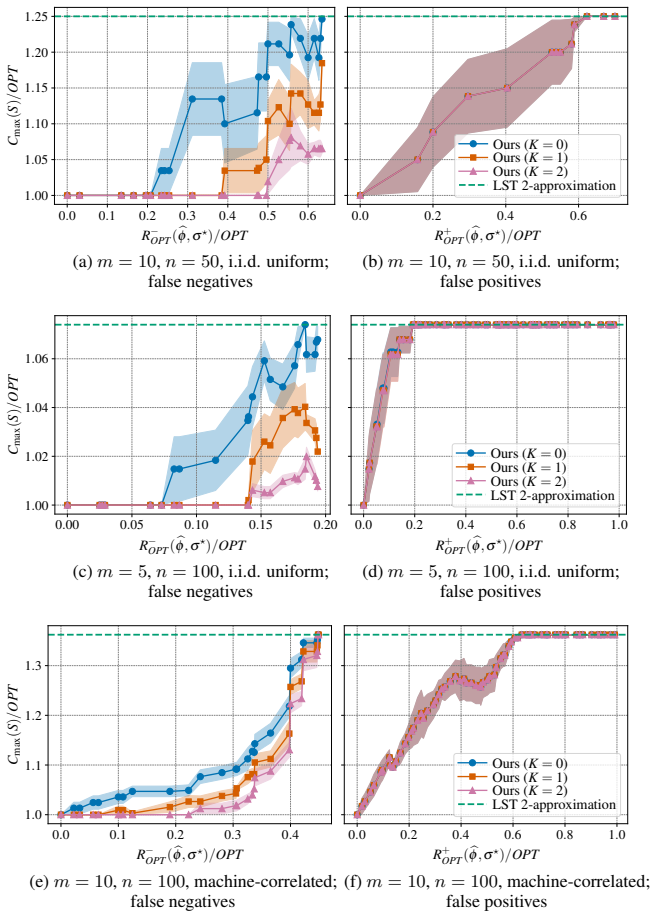
Applying Theorem 5.1, we obtain the claimed bound immediately. The running-time bound is inherited directly from Theorem 5.1. Interpretation.Corollary C.1 reveals a genuine asymmetry between the two types of prediction error. False-negative heavy assignments affect the running time through the augmentation budget K, since they must be recovered by additio...
1990
-
[18]
We use OR-Tools version 9.15.6755 and SciPy version 1.17.1
through SciPy (Virtanen et al., 2020). We use OR-Tools version 9.15.6755 and SciPy version 1.17.1. Machine specifications.All experiments are run on a single machine with an Intel ® CoreTM Ultra 7 155H CPU (22 logical CPUs) and 16 GB RAM, running Arch Linux. F Additional experimental results F.1 Additional results on false negatives and false positives In...
2020
-
[19]
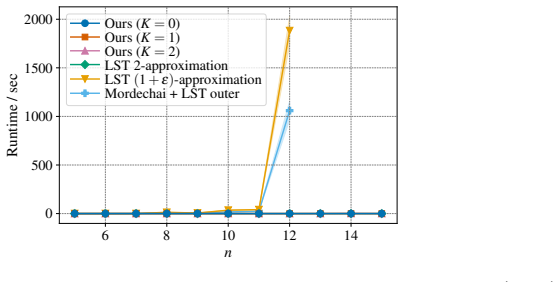
This reflects the fact that the classical (1 +ε) -type running times can still contain large factors such as nm/ε or 2mn, even for constant m
The results show that our algorithm remains substantially faster than the classical (1 +ε) -type baselines even when m is fixed and n varies. This reflects the fact that the classical (1 +ε) -type running times can still contain large factors such as nm/ε or 2mn, even for constant m. In contrast, our algorithm runs almost as fast as the polynomial-time 2-...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.