Reinforcement Learning for Neural Model Editing
Pith reviewed 2026-06-27 07:37 UTC · model grok-4.3
The pith
Neural model editing can be cast as a reinforcement learning problem so that policies are learned from reward feedback instead of being hand-engineered for each task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
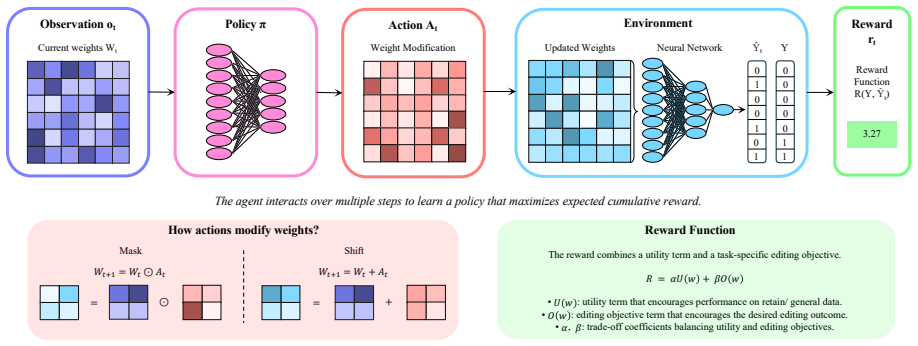
The paper claims that neural model editing can be cast as a reinforcement learning problem, allowing editing policies to be learned from reward feedback rather than manually engineered for each task. Two environments are introduced, MaskWorld in which agents scale weights multiplicatively and ShiftWorld in which agents apply additive weight updates. The reward function combines a utility-preservation objective with a task-specific editing objective. Policies trained in this way reduce forget-set accuracy to nearly zero while preserving over 90 percent retain-set accuracy on unlearning and improve bias-related metrics by more than 5 percent while maintaining classification utility on bias mit
What carries the argument
The reinforcement-learning formulation that lets an agent choose weight modifications inside either the MaskWorld (multiplicative) or ShiftWorld (additive) environment, guided by a reward that balances overall utility preservation against the desired edit.
If this is right
- Policies learned in the two environments reach near-zero accuracy on forget sets while keeping over 90 percent accuracy on retain sets for machine unlearning.
- The same policies raise bias-related performance metrics by more than 5 percent without harming general classification accuracy.
- A single learned policy approach replaces the creation of separate specialized algorithms for each new editing objective.
- Agents can discover useful weight changes through reward feedback rather than through manual design of update rules.
Where Pith is reading between the lines
- If the reward components transfer across different model sizes or architectures, the same training loop could be reused for many editing goals without redesign.
- One could test whether policies trained on image unlearning also succeed on language-model unlearning by simply swapping the reward terms.
- The framework suggests that weight-editing strategies might be discovered automatically for objectives that currently lack any dedicated algorithm.
- Extending the environments to allow more complex sequences of modifications could reveal whether longer-horizon policies produce finer control over model behavior.
Load-bearing premise
The combined reward that mixes utility preservation with the task-specific editing objective can be written so that it yields stable policies without hidden trade-offs or unintended damage to model behavior.
What would settle it
Run the learned policy on a held-out editing task and measure whether it either fails to reach the target edit accuracy or drops overall model accuracy by more than the drop produced by a specialized baseline algorithm.
Figures

read the original abstract
Editing pretrained neural networks requires specialized algorithms tailored to specific objectives. Designing such algorithms is often time-consuming and demands significant effort. We present an exploratory framework that formulates neural model editing as a reinforcement learning problem, where agents modify models using reward feedback. We introduce two environments: MaskWorld, where agents scale weights multiplicatively, and ShiftWorld, where agents apply additive weight updates. The reward function combines a utility-preservation objective with a task-specific editing objective, enabling agents to learn targeted modifications while maintaining overall model performance. We evaluate the framework on bias mitigation in text classification and machine unlearning in image classification, both of which traditionally rely on specialized algorithms. Our results show that the learned policies reduce forget set accuracy to nearly 0% while preserving over 90% retain set accuracy on the unlearning task. In the bias mitigation setting, the learned policies improve bias-related performance by more than 5% while maintaining general classification utility. Our findings show that neural model editing can be cast as a reinforcement learning problem, allowing editing policies to be learned from reward feedback rather than manually engineered for each task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an exploratory framework that formulates neural model editing as a reinforcement learning problem. Agents operate in two environments—MaskWorld (multiplicative weight scaling) and ShiftWorld (additive weight updates)—and learn editing policies from a reward that combines a utility-preservation term with a task-specific editing objective. The approach is evaluated on bias mitigation in text classification and machine unlearning in image classification. Reported outcomes include forget-set accuracy near 0% with retain-set accuracy above 90% on unlearning, and bias-related performance gains exceeding 5% while preserving classification utility. The central claim is that this RL formulation allows editing policies to be learned from reward feedback rather than manually engineered per task.
Significance. If the results prove robust under proper controls and the reward structure generalizes without extensive per-task re-engineering, the work could provide a flexible, automated alternative to hand-designed editing algorithms. The RL perspective on model editing is a distinct angle that might reduce reliance on task-specific heuristics, though the current evaluation on only two tasks leaves the generality of the framework open.
major comments (2)
- [Abstract] Abstract: The performance claims (forget-set accuracy near 0%, retain-set >90%, bias improvement >5%) are presented without baselines, statistical tests, hyperparameter details, or information on reward-weight selection. This omission prevents assessment of whether the learned policies outperform or match existing specialized algorithms.
- [Abstract] Abstract: The central claim that policies are learned rather than manually engineered rests on the assumption that the combined reward (utility preservation + task-specific term) can be specified without per-task tuning or unintended trade-offs. No transfer experiments or ablations on reward design across new objectives are described, leaving the claim unsupported by the reported evidence on two fixed tasks.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our exploratory framework. We address the two major comments point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claims (forget-set accuracy near 0%, retain-set >90%, bias improvement >5%) are presented without baselines, statistical tests, hyperparameter details, or information on reward-weight selection. This omission prevents assessment of whether the learned policies outperform or match existing specialized algorithms.
Authors: We agree the abstract omits these elements. The work is framed as an exploratory demonstration that model editing can be cast as RL, not as a performance benchmark against specialized algorithms. The full manuscript details the MaskWorld and ShiftWorld environments, the combined reward structure, and training procedures (including hyperparameter choices), but does not report baseline comparisons, statistical tests, or explicit reward-weight selection procedures. We will revise the abstract to contextualize the reported numbers as feasibility results on two tasks and add a brief discussion of experimental controls in the results section. revision: yes
-
Referee: [Abstract] Abstract: The central claim that policies are learned rather than manually engineered rests on the assumption that the combined reward (utility preservation + task-specific term) can be specified without per-task tuning or unintended trade-offs. No transfer experiments or ablations on reward design across new objectives are described, leaving the claim unsupported by the reported evidence on two fixed tasks.
Authors: The manuscript demonstrates policy learning from reward feedback on the two evaluated tasks (bias mitigation and unlearning). We acknowledge that the evidence is limited to these fixed tasks, with no transfer experiments or reward ablations provided, so the generality of the reward design is not established. This is a limitation of the current exploratory study. We will revise the abstract and discussion sections to more precisely scope the central claim to the reported setting and note the requirement for future work on reward transfer. revision: partial
Circularity Check
No circularity; empirical RL framing with no self-referential derivations or fitted predictions.
full rationale
The paper introduces MaskWorld and ShiftWorld environments plus a composite reward (utility preservation + task-specific term) and reports empirical results on unlearning and bias mitigation. No equations, uniqueness theorems, or derivations are presented that reduce any claimed prediction to an input quantity defined by the authors themselves. The central claim is supported by observed performance metrics rather than by construction or self-citation chains. This is the normal case of a self-contained empirical framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceed- ings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, pages 67–73
Measuring and mitigat- ing unintended bias in text classification. InProceed- ings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, pages 67–73. John Duchi, Elad Hazan, and Yoram Singer
2018
-
[2]
InFindings of the Association for Computational Linguistics: ACL 2024, pages 5907–5913
Model editing by standard fine-tuning. InFindings of the Association for Computational Linguistics: ACL 2024, pages 5907–5913. Jia-Chen Gu, Hao-Xiang Xu, Jun-Yu Ma, Pan Lu, Zhen- Hua Ling, Kai-Wei Chang, and Nanyun Peng
2024
-
[3]
InPro- ceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing, pages 16801– 16819
5 Model editing harms general abilities of large lan- guage models: Regularization to the rescue. InPro- ceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing, pages 16801– 16819. Yoav Gur-Arieh, Clara Haya Suslik, Yihuai Hong, Fazl Barez, and Mor Geva
2024
-
[4]
InPro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pages 18997– 19017
Precise in-parameter concept erasure in large language models. InPro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pages 18997– 19017. David Ha, Andrew Dai, and Quoc V Le
2025
-
[5]
Hyper- networks.arXiv preprint arXiv:1609.09106. Sepp Hochreiter and Jürgen Schmidhuber
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980. Yann LeCun
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Learning to optimize. arXiv preprint arXiv:1606.01885. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022a. Locating and editing factual as- sociations in gpt.Advances in neural information processing systems, 35:17359–17372. Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. 2022b. Mass- editing memory in a transf...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Proximal Policy Optimization Algorithms
Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. David Silver, Thomas Hubert, Julian Schrittwieser, Ioan- nis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Mastering chess and shogi by self-play with a general reinforcement learn- ing algorithm.arXiv preprint arXiv:1712.01815. Anton Sinitsin, Vsevolod Plokhotnyuk, Dmitriy Pyrkin, Sergei Popov, and Artem Babenko
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Editable neural networks.arXiv preprint arXiv:2004.00345. Matthew Sotoudeh and A Thakur
-
[11]
InInternational Conference on Learning Representations, volume 2025, pages 61897–61931
Rethinking llm unlearning objectives: A gradient perspective and go beyond. InInternational Conference on Learning Representations, volume 2025, pages 61897–61931. 6 A Appendix A.1 Related Works Learned Optimizers.Neural networks are typically trained using hand-designed optimization algorithms such as gradient descent and its variants, including Adam (Ki...
2025
-
[12]
More recently, Chen et al
and showed that they can outperform hand-designed methods on the tasks for which they are trained. More recently, Chen et al. (2023) formulated algorithm discovery as program search and applied it to discover the Lion optimization algorithm. Li and Malik (2016) reframed learning an optimization algorithm as a reinforcement learning problem and showed that...
2023
-
[13]
In this work, the policy learns to edit the weights of the second fully connected layer, whose parameter matrix has di- mensions 128×32. Bias Mitigation.We create a balanced subset of 20,000 samples from the Jigsaw Toxic Comment Classification Challenge dataset (cjadams et al., 2017), which we divide into training, validation, and test sets in a 70/15/15 ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.