CloudCons: A Comprehensive End-to-End Benchmark for Cloud Resource Consolidation
Pith reviewed 2026-06-27 07:01 UTC · model grok-4.3
The pith
Foundation models' superior forecasting accuracy does not automatically yield better cloud resource consolidation results; predictive quantile selection instead controls the efficiency-reliability balance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
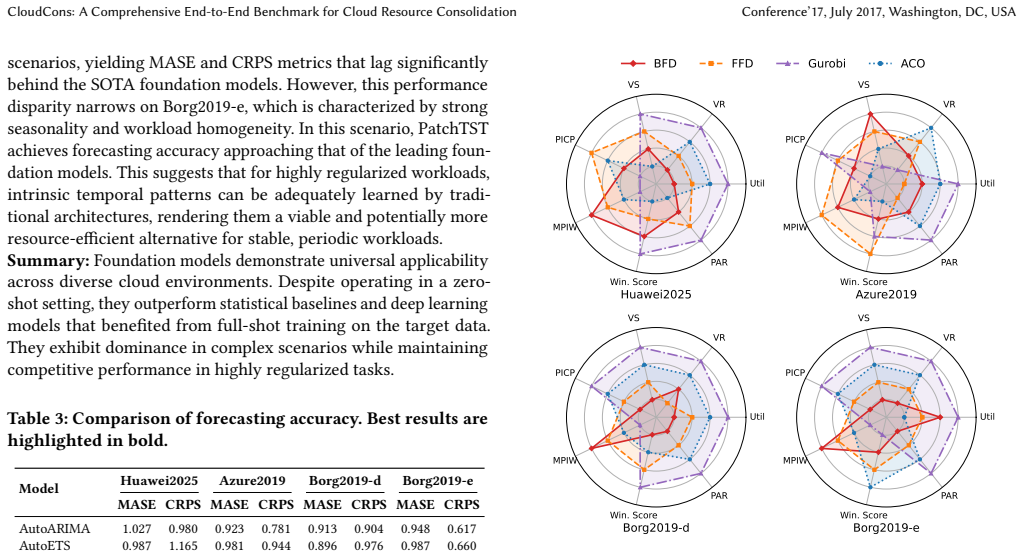
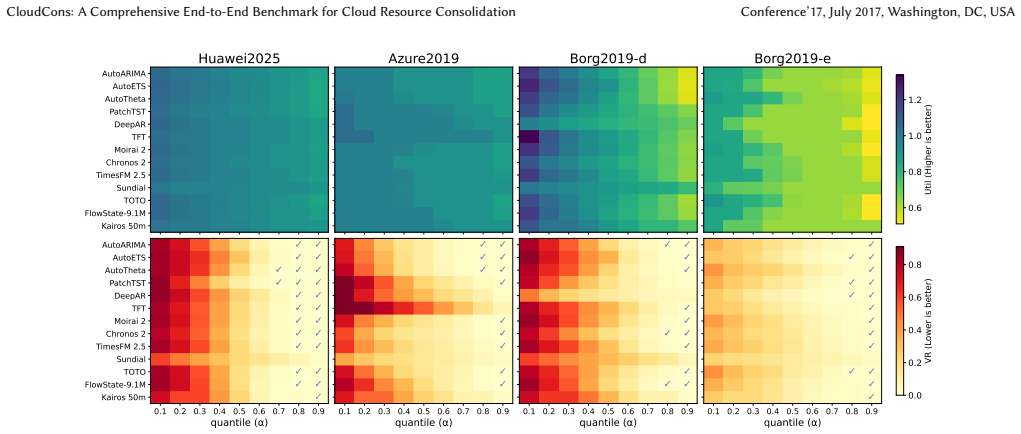
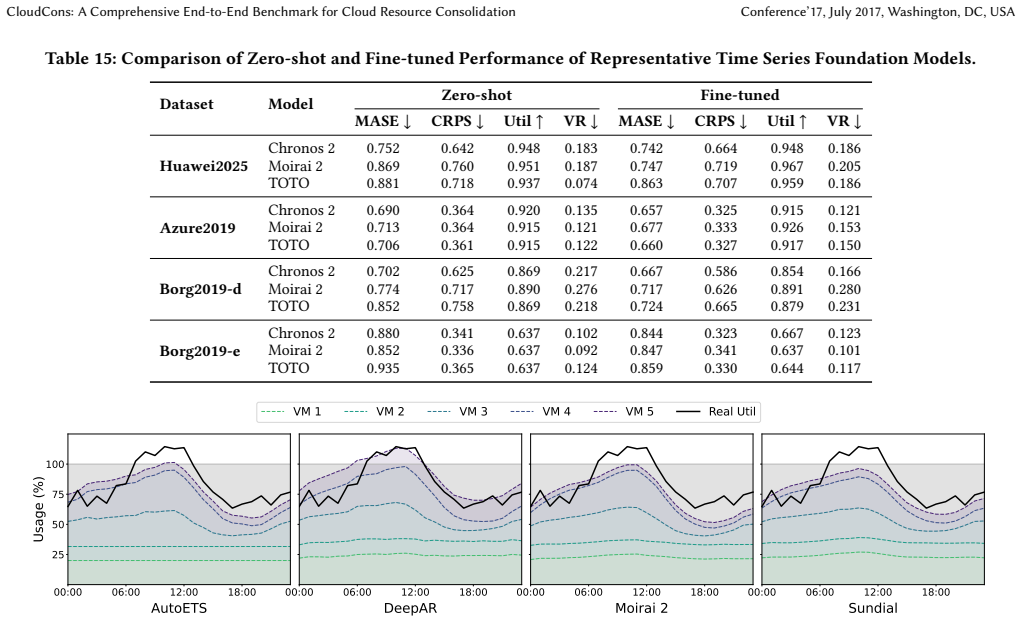
While foundation models achieve superior zero-shot forecasting accuracy on cloud time series, this advantage does not translate into better decision utility when the forecasts drive consolidation optimization. Systematic tests reveal that the selection of predictive quantiles serves as the critical control for balancing resource efficiency against service reliability, and the paper supplies guidelines for calibrating those quantiles according to workload type.
What carries the argument
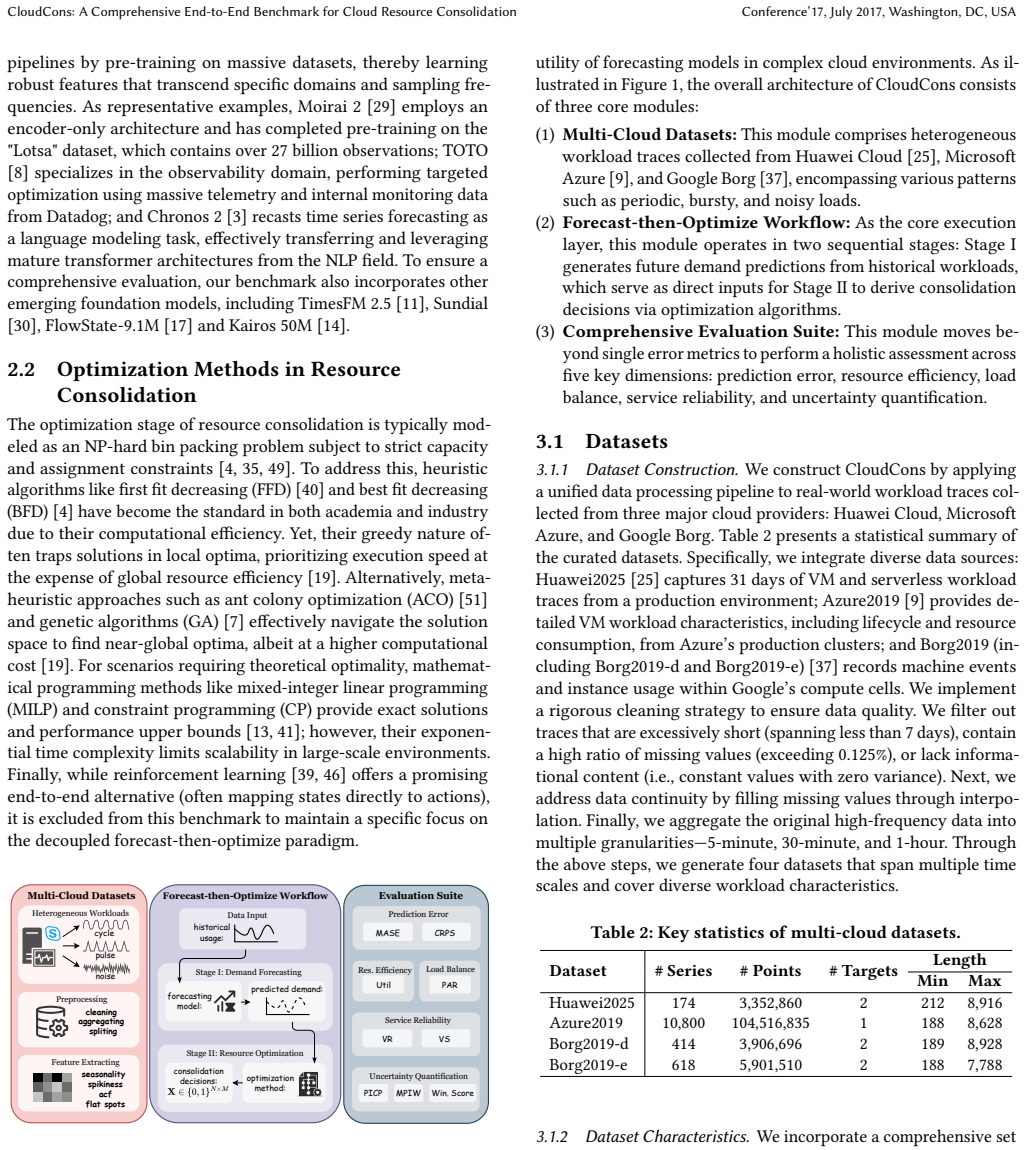
The CloudCons end-to-end benchmark that pairs multi-source cloud workload datasets with a consolidation optimization procedure to score models on realized decision utility instead of isolated forecast metrics.
Load-bearing premise
The constructed datasets from Huawei Cloud, Microsoft Azure, and Google Borg together with the chosen consolidation optimization procedure faithfully represent the decision utility that would appear in live production environments.
What would settle it
Deploying the accuracy-ranked versus quantile-tuned model selections in an actual production cloud and observing that the accuracy-based selections produce strictly better consolidation outcomes would falsify the central claim.
Figures

read the original abstract
Driven by conservative over-provisioning to guarantee service reliability, resource utilization in cloud data centers remains at low levels. To mitigate this, the forecast-then-optimize paradigm has emerged to optimize consolidation by anticipating future demands. While emerging time series foundation models promise to enhance this paradigm through zero-shot generalization, existing benchmarks focus solely on prediction error metrics. The actual decision utility of these advanced models remains unverified, rendering their practical value for downstream tasks uncertain. To bridge this gap, we propose CloudCons, a comprehensive end-to-end benchmark designed to evaluate forecasting models within the specific context of cloud resource consolidation. We build high-quality datasets that cover diverse workloads from Huawei Cloud, Microsoft Azure, and Google Borg, capturing distinct service characteristics ranging from synchronized diurnal rhythms to stochastic, pulse-like bursts and high-frequency noise. We conduct an extensive evaluation of statistical, deep learning, and foundation models. Our experiments reveal a pivotal finding: while foundation models demonstrate superior zero-shot forecasting accuracy, this advantage does not inherently translate into better decision utility. Of practical significance, we systematically analyze how the selection of predictive quantiles acts as a critical lever. We provide actionable guidelines for calibrating these selections to balance the trade-off between resource efficiency and service reliability, offering vital insights for real-world deployment decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CloudCons, an end-to-end benchmark for evaluating time-series forecasting models (statistical, deep learning, and foundation models) in cloud resource consolidation. It constructs datasets from Huawei Cloud, Microsoft Azure, and Google Borg traces, applies a forecast-then-optimize pipeline, and reports that foundation models' superior zero-shot accuracy does not translate into better decision utility; instead, the choice of predictive quantiles is a critical lever for trading off resource efficiency against service reliability, with accompanying guidelines for calibration.
Significance. If the central empirical finding holds under more varied optimizers and production-like conditions, the work would usefully demonstrate that prediction-error metrics alone are insufficient for assessing practical value in downstream optimization tasks. The emphasis on quantile selection as an actionable lever and the release of diverse workload datasets would provide concrete guidance for cloud operators and model developers.
major comments (2)
- [Experimental setup / consolidation procedure] The central claim that foundation-model accuracy does not translate to decision utility rests on a single fixed consolidation optimizer whose objective and constraints are not shown to capture production factors such as migration overhead, network contention, or multi-resource packing dynamics. Without sensitivity analysis varying the optimizer formulation, the reported utility gap could be an artifact of that choice rather than a robust property of the forecasting models.
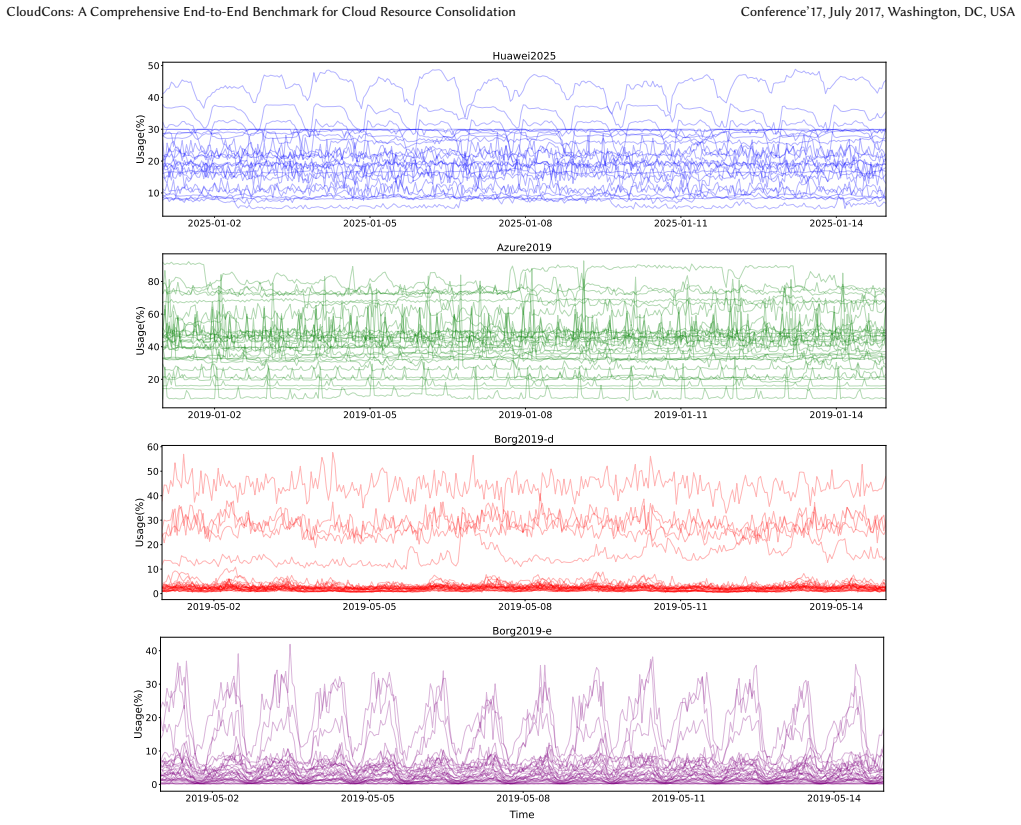
- [Dataset construction] The decision-utility metric (resource efficiency vs. reliability) is computed on the constructed datasets, yet no validation is provided that these traces, after any preprocessing, reproduce the statistical properties or failure modes observed in live production environments. This directly affects whether the quantile-calibration guidelines generalize.
minor comments (2)
- [Methods] Clarify the exact definition of the consolidation objective function and any constraints used in the optimizer (e.g., whether SLA violation penalties are modeled explicitly).
- [Datasets] Add a table or figure summarizing the key statistical properties (periodicity, burstiness, coefficient of variation) of each dataset to allow readers to assess workload diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: The central claim that foundation-model accuracy does not translate to decision utility rests on a single fixed consolidation optimizer whose objective and constraints are not shown to capture production factors such as migration overhead, network contention, or multi-resource packing dynamics. Without sensitivity analysis varying the optimizer formulation, the reported utility gap could be an artifact of that choice rather than a robust property of the forecasting models.
Authors: We fixed the optimizer to a standard forecast-then-optimize formulation to isolate the contribution of the forecasting models themselves. This choice follows common practice in the literature for benchmarking prediction-to-decision pipelines. We agree that production factors such as migration overhead are relevant; the current results therefore reflect utility under this specific optimizer. In revision we will add a sensitivity subsection that re-runs the pipeline with an alternative optimizer incorporating migration cost, allowing readers to assess robustness. revision: partial
-
Referee: The decision-utility metric (resource efficiency vs. reliability) is computed on the constructed datasets, yet no validation is provided that these traces, after any preprocessing, reproduce the statistical properties or failure modes observed in live production environments. This directly affects whether the quantile-calibration guidelines generalize.
Authors: The source traces are the publicly released Huawei, Azure, and Borg datasets that have been analyzed in multiple prior studies. Our preprocessing steps (resampling, alignment, and noise filtering) were chosen to retain the original diurnal, bursty, and stochastic characteristics documented in those works. To make this explicit, the revised manuscript will include a new table comparing key statistical descriptors (periodicity, coefficient of variation, tail indices) of the processed datasets against the values reported in the original trace papers. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivation chain
full rationale
The paper is a benchmark study that constructs datasets from Huawei Cloud, Azure, and Borg traces, then measures forecasting accuracy and downstream consolidation utility across statistical, DL, and foundation models. All claims rest on observed experimental outcomes rather than equations, fitted parameters renamed as predictions, or self-citation chains. No load-bearing steps reduce by construction to inputs; the central finding (FM accuracy advantage does not imply decision utility) is an empirical result, not a definitional or fitted tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A next-generation hyperparameter optimization frame- work. InProceedings of the 25th ACM SIGKDD international conference on knowl- edge discovery & data mining. 2623–2631
2019
- [2]
-
[3]
Chronos-2: From Univariate to Universal Forecasting
Abdul Fatir Ansari, Oleksandr Shchur, Jaris Küken, Andreas Auer, Boran Han, Pedro Mercado, Syama Sundar Rangapuram, Huibin Shen, Lorenzo Stella, Xiyuan Zhang, Mononito Goswami, Shubham Kapoor, Danielle C. Maddix, Pablo Guerron, Tony Hu, Junming Yin, Nick Erickson, Prateek Mutalik Desai, Hao Wang, Huzefa Rangwala, George Karypis, Yuyang Wang, and Michael B...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Patricia Arroba, José M Moya, Jose L Ayala, and Rajkumar Buyya. 2017. Dynamic Voltage and Frequency Scaling-aware dynamic consolidation of virtual machines for energy efficient cloud data centers.Concurrency and Computation: Practice and Experience29, 10 (2017), e4067
2017
-
[5]
Bharathan Balaji, Christopher Kakovitch, and Balakrishnan Narayanaswamy
-
[6]
Proceedings of Machine Learning and Systems3 (2021), 652–663
Fireplace: Placing firecraker virtual machines with hindsight imitation. Proceedings of Machine Learning and Systems3 (2021), 652–663
2021
-
[7]
2001.Probabilistic risk analysis: foundations and methods
Tim Bedford and Roger Cooke. 2001.Probabilistic risk analysis: foundations and methods. Cambridge University Press
2001
-
[8]
Djillali Boukhelef, Jalil Boukhobza, Kamel Boukhalfa, Hamza Ouarnoughi, and Laurent Lemarchand. 2019. Optimizing the cost of DBaaS object placement in hybrid storage systems.Future Generation Computer Systems93 (2019), 176–187
2019
-
[9]
Ben Cohen, Emaad Khwaja, Youssef Doubli, Salahidine Lemaachi, Chris Lettieri, Charles Masson, Hugo Miccinilli, Elise Ramé, Qiqi Ren, Afshin Rostamizadeh, Jean Ogier du Terrail, Anna-Monica Toon, Kan Wang, Stephan Xie, Zongzhe Xu, Viktoriya Zhukova, David Asker, Ameet Talwalkar, and Othmane Abou- Amal. 2025. This Time is Different: An Observability Perspec...
-
[10]
Eli Cortez, Anand Bonde, Alexandre Muzio, Mark Russinovich, Marcus Fontoura, and Ricardo Bianchini. 2017. Resource central: Understanding and predicting workloads for improved resource management in large cloud platforms. InPro- ceedings of the 26th Symposium on Operating Systems Principles. 153–167
2017
- [11]
-
[12]
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. 2024. A decoder- only foundation model for time-series forecasting. arXiv:2310.10688 [cs.CL] https://arxiv.org/abs/2310.10688
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Emir Demirović, Peter J Stuckey, James Bailey, Jeffrey Chan, Chris Leckie, Ko- tagiri Ramamohanarao, and Tias Guns. 2019. An investigation into prediction+ optimisation for the knapsack problem. InInternational Conference on Integra- tion of Constraint Programming, Artificial Intelligence, and Operations Research. Springer, 241–257
2019
-
[14]
Hang Dong, Boshi Wang, Bo Qiao, Wenqian Xing, Chuan Luo, Si Qin, Qingwei Lin, Dongmei Zhang, Gurpreet Virdi, and Thomas Moscibroda. 2021. Predictive Job Scheduling under Uncertain Constraints in Cloud Computing.. InIJCAI. 3627–3634
2021
-
[15]
Kun Feng, Shaocheng Lan, Yuchen Fang, Wenchao He, Lintao Ma, Xingyu Lu, and Kan Ren. 2025. Kairos: Towards Adaptive and Generalizable Time Series Foundation Models. arXiv:2509.25826 [cs.LG] https://arxiv.org/abs/2509.25826
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Valentin Flunkert, David Salinas, and Jan Gasthaus. 2017. DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks.International Journal of Forecasting36 (04 2017). doi:10.1016/j.ijforecast.2019.07.001
-
[17]
Federico Garza, Max Mergenthaler Canseco, Cristian Challú, and Kin G Olivares
-
[18]
StatsForecast: Lightning fast forecasting with statistical and econometric models.PyCon Salt Lake City, Utah, US2022 (2022), 66
2022
- [19]
-
[20]
Gurobi Optimization, LLC. 2025. Gurobi Optimizer Reference Manual. https: //www.gurobi.com Accessed: 2026-02-03
2025
-
[21]
Leila Helali and Mohamed Nazih Omri. 2021. A survey of data center consolida- tion in cloud computing systems.Computer Science Review39 (2021), 100366
2021
-
[22]
Sun-Yuan Hsieh, Cheng-Sheng Liu, Rajkumar Buyya, and Albert Y Zomaya
-
[23]
Parallel and Distrib
Utilization-prediction-aware virtual machine consolidation approach for energy-efficient cloud data centers.J. Parallel and Distrib. Comput.139 (2020), 99–109
2020
-
[24]
Michael Huang and Vishal Gupta. 2024. Decision-focused learning with direc- tional gradients.Advances in Neural Information Processing Systems37 (2024), 79194–79220
2024
-
[25]
2026.tsfeatures: Time Series Feature Extraction
Rob Hyndman, Yanfei Kang, Pablo Montero-Manso, Mitchell O’Hara-Wild, Thiyanga Talagala, Earo Wang, and Yangzhuoran Yang. 2026.tsfeatures: Time Series Feature Extraction. https://pkg.robjhyndman.com/tsfeatures/ R package version 1.1.1.9000
2026
-
[26]
2018.Forecasting: principles and practice
Rob J Hyndman and George Athanasopoulos. 2018.Forecasting: principles and practice. OTexts
2018
-
[27]
Rob J Hyndman and Yeasmin Khandakar. 2008. Automatic time series forecasting: the forecast package for R.Journal of statistical software27 (2008), 1–22
2008
-
[28]
Artjom Joosen, Ahmed Hassan, Martin Asenov, Rajkarn Singh, Luke Darlow, Jianfeng Wang, Qiwen Deng, and Adam Barker. 2025. Serverless cold starts and where to find them. InProceedings of the Twentieth European Conference on Computer Systems. 938–953
2025
-
[29]
Karpenter Community. 2025. Karpenter: Just-in-time Nodes for Any Kubernetes Cluster. https://karpenter.sh/ v1.8 Accessed: 2026-02-03
2025
-
[30]
Abbas Khosravi, Saeid Nahavandi, Doug Creighton, and Amir F Atiya. 2010. Lower upper bound estimation method for construction of neural network-based prediction intervals.IEEE transactions on neural networks22, 3 (2010), 337–346
2010
-
[31]
Bryan Lim, Sercan Ö Arık, Nicolas Loeff, and Tomas Pfister. 2021. Temporal fusion transformers for interpretable multi-horizon time series forecasting.International Journal of Forecasting37, 4 (2021), 1748–1764
2021
- [32]
-
[33]
Yong Liu, Guo Qin, Zhiyuan Shi, Zhi Chen, Caiyin Yang, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. 2025. Sundial: A Family of Highly Capable Time Series Foundation Models. arXiv:2502.00816 [cs.LG] https://arxiv.org/abs/ 2502.00816
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Chuan Luo, Bo Qiao, Xin Chen, Pu Zhao, Randolph Yao, Hongyu Zhang, Wei Wu, Andrew Zhou, and Qingwei Lin. 2020. Intelligent Virtual Machine Provi- sioning in Cloud Computing. InProceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20, Christian Bessiere (Ed.). In- ternational Joint Conferences on Artificial Intell...
-
[35]
Chuan Luo, Bo Qiao, Wenqian Xing, Xin Chen, Pu Zhao, Chao Du, Randolph Yao, Hongyu Zhang, Wei Wu, Shaowei Cai, et al. 2021. Correlation-aware heuristic search for intelligent virtual machine provisioning in cloud systems. InProceed- ings of the AAAI Conference on Artificial Intelligence, Vol. 35. 12363–12372
2021
-
[36]
Microsoft. 2025. Overview of node auto-provisioning (NAP) in Azure Kuber- netes Service (AKS). https://learn.microsoft.com/en-us/azure/aks/node-auto- provisioning Accessed: 2026-02-03
2025
-
[37]
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. 2022. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. In The Eleventh International Conference on Learning Representations
2022
-
[38]
Sareh Fotuhi Piraghaj, Amir Vahid Dastjerdi, Rodrigo N Calheiros, and Rajkumar Buyya. 2015. A framework and algorithm for energy efficient container consoli- dation in cloud data centers. In2015 IEEE International conference on data science and data intensive systems. IEEE, 368–375
2015
-
[39]
Syama Sundar Rangapuram, Matthias W Seeger, Jan Gasthaus, Lorenzo Stella, Yuyang Wang, and Tim Januschowski. 2018. Deep State Space Models for Time Series Forecasting. InAdvances in Neural Information Processing Systems, S. Ben- gio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Eds.), Vol. 31. Curran Associates, Inc
2018
-
[40]
Charles Reiss, John Wilkes, and Joseph L Hellerstein. 2011. Google cluster-usage traces: format+ schema.Google Inc., White Paper1 (2011), 1–14
2011
-
[41]
Seyyed Meysam Rozehkhani, Farnaz Mahan, and Witold Pedrycz. 2025. VM con- solidation steps in cloud computing: A perspective review.Simulation Modelling Practice and Theory138 (2025), 103034
2025
-
[42]
Junjie Sheng, Lu Wang, Fangkai Yang, Bo Qiao, Hang Dong, Xiangfeng Wang, Bo Jin, Jun Wang, Si Qin, Saravan Rajmohan, et al. 2023. Learning cooperative oversubscription for cloud by chance-constrained multi-agent reinforcement learning. InProceedings of the ACM Web Conference 2023. 2927–2936
2023
-
[43]
Tao Shi, Hui Ma, and Gang Chen. 2018. Multi-objective container consolidation in cloud data centers. InAustralasian Joint Conference on Artificial Intelligence. Springer, 783–795
2018
-
[44]
Alain Tchana, Noel De Palma, Ibrahim Safieddine, and Daniel Hagimont. 2016. Software consolidation as an efficient energy and cost saving solution.Future Generation Computer Systems58 (2016), 1–12
2016
-
[45]
Team SimPy. 2024. SimPy: Discrete event simulation for Python. https://simpy. readthedocs.io Accessed: 2026-01-04
2024
-
[46]
Muhammad Tirmazi, Adam Barker, Nan Deng, Md E Haque, Zhijing Gene Qin, Steven Hand, Mor Harchol-Balter, and John Wilkes. 2020. Borg: the next gen- eration. InProceedings of the fifteenth European conference on computer systems. 1–14
2020
-
[47]
William Toner, Thomas L Lee, Artjom Joosen, Rajkarn Singh, and Martin Asenov
-
[48]
arXiv preprint arXiv:2502.12944(2025)
Performance of zero-shot time series foundation models on cloud data. arXiv preprint arXiv:2502.12944(2025)
-
[49]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017). CloudCons: A Comprehensive End-to-End Benchmark for Cloud Resource Consolidation Conference’17, July 2017, Washington, DC, USA
2017
-
[50]
Lu Wang, Mayukh Das, Fangkai Yang, Bo Qiao, Hang Dong, Si Qin, Victor Ruehle, Chetan Bansal, Eli Cortez, Íñigo Goiri, et al. 2025. ProtoRAIL: A Risk-cognizant Imitation Agent for Adaptive vCPU Oversubscription In the Cloud.Proceedings of Machine Learning and Systems7 (2025)
2025
-
[51]
Bryan Wilder, Bistra Dilkina, and Milind Tambe. 2019. Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 1658–1665
2019
- [52]
-
[53]
Jie Yan, Yunlei Lu, Liting Chen, Si Qin, Yixin Fang, Qingwei Lin, Thomas Mosci- broda, Saravan Rajmohan, and Dongmei Zhang. 2022. Solving the Batch Stochas- tic Bin Packing Problem in Cloud: A Chance-constrained Optimization Approach. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Washington DC, USA)(KDD ’22). Assoc...
- [54]
-
[55]
Hui Zhao, Jing Wang, Feng Liu, Quan Wang, Weizhan Zhang, and Qinghua Zheng
-
[56]
Power-aware and performance-guaranteed virtual machine placement in the cloud.IEEE Transactions on Parallel and Distributed Systems29, 6 (2018), 1385–1400. A Implementation Details This section details the experimental configurations for time series forecasting and resource consolidation simulation. A.1 Time Series Forecasting Settings For the forecasting...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.