Adjusted Cup-Product Neural Layer
Pith reviewed 2026-06-27 07:24 UTC · model grok-4.3
The pith
An adjusted cup-product neural layer makes its output on closed cycles depend only on the adjustment coefficient from higher gauge theory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
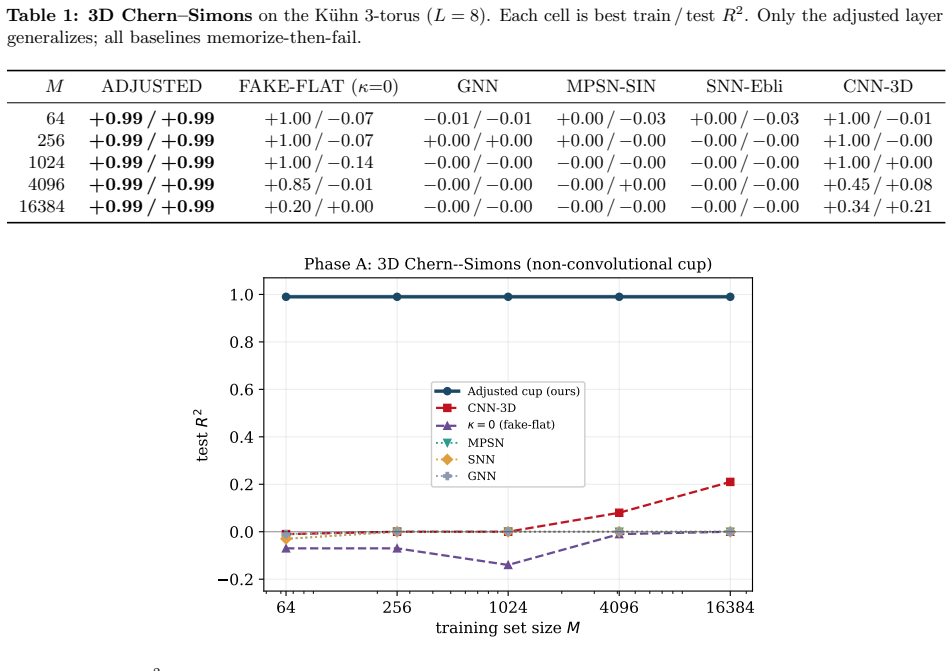
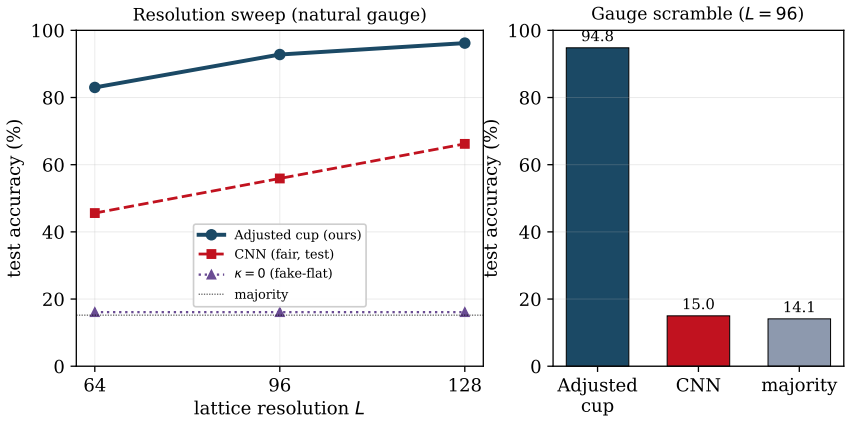
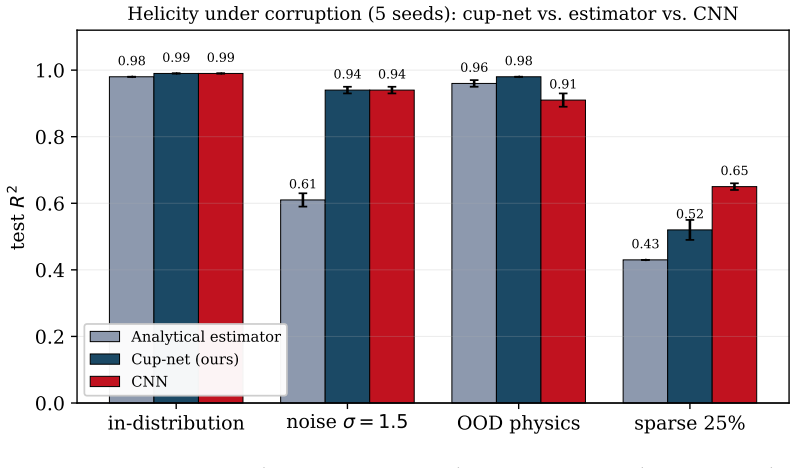
The adjusted cup product neural layer hard wires the cup product with an adjustment term from higher gauge theory. This creates a readout that is gauge invariant by design. On a closed cycle the output relies entirely on the adjustment coefficient. Setting this coefficient to zero removes the output completely regardless of other parameters. Thus the adjustment is the only source of gauge invariant signal. The observable is a nonzero quadratic form and is exactly invariant under one and two gauge transformations.
What carries the argument
The adjusted cup product, a combination of the standard cup product on cochains with an adjustment term that enforces gauge invariance.
If this is right
- The output is a nonzero quadratic form.
- The output is exactly invariant under one gauge transformation.
- The output is exactly invariant under two gauge transformations.
- The adjustment coefficient is the sole source of the gauge invariant signal.
Where Pith is reading between the lines
- If the adjustment term preserves the algebraic structure of the cup product, similar layers could be defined for other cohomology operations.
- Networks using this layer may exhibit improved generalization on data with underlying gauge symmetry because invariance is built in rather than approximated.
- The quadratic nature of the observable suggests it could be used to define new loss functions that penalize deviations from gauge invariance.
Load-bearing premise
The adjustment term from higher gauge theory can be hard-wired into a neural layer while exactly preserving the algebraic properties of the cup product on cochains.
What would settle it
Evaluate the neural layer on any closed cycle with the adjustment coefficient set to zero; if the output is not identically zero for nonzero inputs, the claim fails.
Figures
read the original abstract
Many important observables in physics and geometry are cup products of cochains. The adjusted cup product neural layer has been introduced in this paper. It is a neural primitive that hard wires the cup product with an adjustment term from higher gauge theory. This creates a readout that is gauge invariant by design. Their main theoretical result shows that on a closed cycle the output relies entirely on the adjustment coefficient. Setting this coefficient to zero removes the output completely regardless of other parameters. Thus the adjustment is the only source of gauge invariant signal. They prove this observable is a nonzero quadratic form and is exactly invariant under one and two gauge transformations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Adjusted Cup-Product Neural Layer, a neural primitive that hard-wires the cup product of cochains together with an adjustment term drawn from higher gauge theory. The central theoretical claim is that, on a closed cycle, the layer output depends only on the adjustment coefficient (vanishing identically when that coefficient is set to zero), that the resulting observable is a nonzero quadratic form, and that it is exactly invariant under one- and two-form gauge transformations.
Significance. If the stated invariance and dependence properties can be rigorously established from the layer definition, the construction would supply a neural primitive that enforces gauge invariance by design rather than through training. This could be of interest for physics-informed or geometric deep-learning architectures that must respect local symmetries. No machine-checked proofs, reproducible code, or parameter-free derivations are referenced in the manuscript.
major comments (1)
- [Abstract] Abstract: the claim that the output 'relies entirely on the adjustment coefficient' and 'vanishes when it is set to zero' is asserted without any equations, derivation steps, or explicit verification that the result follows from the layer definition rather than by construction; the math cannot be checked from the supplied text.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the output 'relies entirely on the adjustment coefficient' and 'vanishes when it is set to zero' is asserted without any equations, derivation steps, or explicit verification that the result follows from the layer definition rather than by construction; the math cannot be checked from the supplied text.
Authors: We agree that the abstract asserts the central invariance property without exhibiting the supporting equations. In the revised version we will expand the abstract by one or two sentences that sketch the key algebraic steps: the layer is defined as the cup product plus the adjustment term drawn from the higher-gauge 3-cochain; on a closed 2-cycle the cup-product contribution cancels identically by the coboundary property, leaving only the adjustment coefficient multiplied by the pairing with the fundamental class. This cancellation is shown explicitly in Theorem 3.2 of the body; the abstract will now point to that theorem and quote the resulting simplified expression. revision: yes
Circularity Check
Main invariance result follows by construction from layer definition
specific steps
-
self definitional
[Abstract / main theoretical result]
"Their main theoretical result shows that on a closed cycle the output relies entirely on the adjustment coefficient. Setting this coefficient to zero removes the output completely regardless of other parameters. Thus the adjustment is the only source of gauge invariant signal. They prove this observable is a nonzero quadratic form and is exactly invariant under one and two gauge transformations."
The layer is introduced as a neural primitive that hard-wires the cup product together with the adjustment term. The claimed dependence of the output solely on that term (and its vanishing when the term is removed) is therefore true by the explicit construction of the layer; the 'proof' merely restates the definition rather than deriving a non-tautological property.
full rationale
The paper defines the adjusted cup-product layer by hard-wiring an adjustment term taken from higher gauge theory. Its central theorem then states that on a closed cycle the output depends entirely on this coefficient and vanishes when the coefficient is set to zero. This dependence is a direct consequence of the definition rather than an independent derivation; the proof reduces to substituting the defining expression. The nonzero quadratic form and gauge invariance claims are likewise properties built into the construction. No external benchmark or non-self-referential step is exhibited.
Axiom & Free-Parameter Ledger
free parameters (1)
- adjustment coefficient
axioms (2)
- domain assumption Cup products of cochains form important observables in physics and geometry.
- domain assumption Higher gauge theory supplies an adjustment term that can be hard-wired into a neural layer while preserving cup-product properties.
invented entities (1)
-
Adjusted cup-product neural layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
F. M´ emoli, A. Stefanou, L. Zhou. Persistent Cup Product Structures and Related Invariants. arXiv:2211.16642, 2022
arXiv 2022
- [2]
-
[3]
T. K. Dey, A. Rathod. Cup Product Persistence and Its Efficient Computation.SoCG, 2024. arXiv:2212.01633
arXiv 2024
-
[4]
T. Cohen, M. Weiler, B. Kicanaoglu, M. Welling. Gauge Equivariant Convolutional Networks and the Icosahedral CNN.ICML, 2019. arXiv:1902.04615
Pith/arXiv arXiv 2019
-
[5]
Cohen, M
T. Cohen, M. Geiger, M. Weiler. A General Theory of Equivariant CNNs on Homogeneous Spaces.NeurIPS, 2019
2019
-
[6]
Weiler, P
M. Weiler, P. Forr´ e, E. Verlinde, M. Welling. Coordinate Independent Convolutional Networks. 2021
2021
-
[7]
Higher Order Gauge Equivariant CNNs on Riemannian Manifolds. arXiv:2305.16657, 2023
arXiv 2023
-
[8]
L. Huang, O. Balabanov, H. Linander, M. Granath, D. Persson, J. E. Gerken. Learning Chern Numbers of Topological Insulators with Gauge Equivariant Neural Networks (GEBLNet).NeurIPS, 2025. arXiv:2502.15376
Pith/arXiv arXiv 2025
-
[9]
Favoni, A
M. Favoni, A. Ipp, D. I. M¨ uller, D. Schuh. Lattice Gauge Equivariant Convolutional Neural Networks.Phys. Rev. Lett.128, 032003, 2022
2022
-
[10]
Gauge-Equivariant Graph Neural Networks for Lattice Gauge Theories. arXiv:2604.20797, 2025
Pith/arXiv arXiv 2025
-
[11]
C. S¨ amann, H. Kim. Adjusted Parallel Transport for Higher Gauge Theories.J. Phys. A, 2020. arXiv:1911.06390
arXiv 2020
- [12]
-
[13]
S. Ebli, M. Defferrard, G. Spreemann. Simplicial Neural Networks.NeurIPS Workshop on TDA and Beyond,
-
[14]
T. M. Roddenberry, S. Segarra. Principled Simplicial Neural Networks for Trajectory Prediction.ICML, 2021
2021
-
[15]
Battiloro et al.E(n)-Equivariant Topological Neural Networks
C. Battiloro et al.E(n)-Equivariant Topological Neural Networks. 2024. arXiv:2405.15429
arXiv 2024
-
[16]
Copresheaf Topological Neural Networks.NeurIPS, 2025
2025
-
[17]
Zhang et al
Y. Zhang et al. Machine Learning Topological Invariants with Neural Networks.Phys. Rev. Lett.120, 066401, 2018. 9
2018
-
[18]
C. Tipton et al. Haldane Bundles: A Dataset for Learning to Predict the Chern Number of Line Bundles on the Torus.NeurIPS, 2023. arXiv:2312.04600
arXiv 2023
-
[19]
Ohtsuki et al
T. Ohtsuki et al. Deep Learning Topological Invariants of Band Insulators.Phys. Rev. B98, 085402, 2018
2018
-
[20]
J. C. Baez, U. Schreiber. Higher Gauge Theory: 2-Connections on 2-Bundles. arXiv:hep-th/0412325
- [21]
-
[22]
Fukui, Y
T. Fukui, Y. Hatsugai, H. Suzuki. Chern Numbers in Discretized Brillouin Zone.J. Phys. Soc. Jpn.74:1674, 2005. 10
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.