Operadic consistency: a label-free signal for compositional reasoning failures in LLMs
Pith reviewed 2026-06-27 06:35 UTC · model grok-4.3
The pith
LLM direct answers to a query should match the result of composing answers to its stated parts, and agreement predicts correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
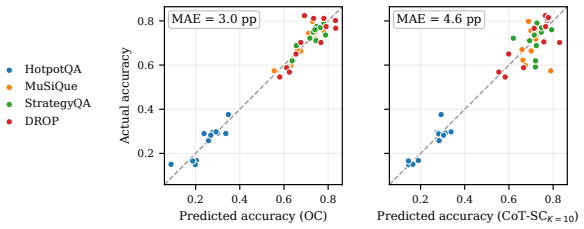
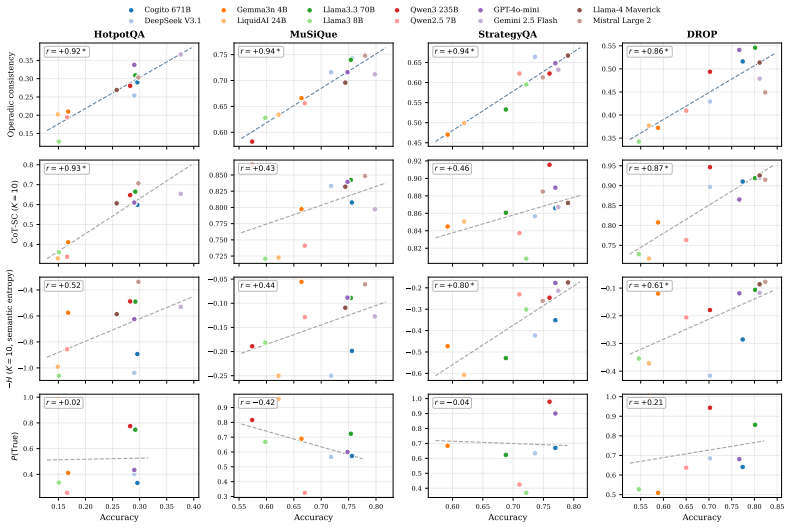
Operadic consistency, the agreement between an LLM's direct answer to a compositional query and the answer obtained by composing its responses to a stated decomposition of the same query, is strongly correlated with accuracy (Pearson r in [0.86, 0.94]) on every dataset tested and is the only evaluated signal that maintains r at or above 0.85 uniformly; at the per-question level it contributes information beyond chain-of-thought self-consistency and semantic entropy, and yields selective-prediction gains at equal sampling budget.
What carries the argument
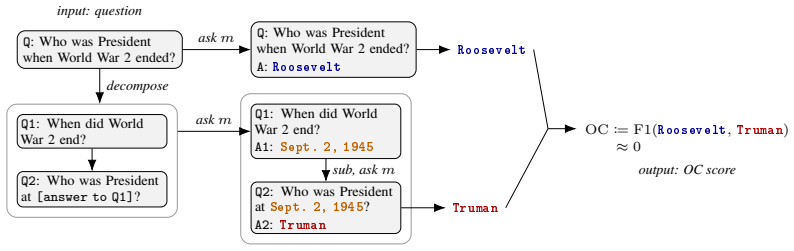
Operadic consistency (OC), the per-question agreement between a direct answer and the composed answer from a decomposition, which acts as a diagnostic for whether the model respects the substitution structure of the query.
If this is right
- OC remains the only signal with uniformly high correlation across HotpotQA, DROP, MuSiQue, and StrategyQA while CoT-SC drops sharply on the latter two.
- At the per-question level OC adds predictive power even after controlling for CoT-SC, semantic entropy, and decomposition-aware baselines.
- At equal sampling budget K=3, OC-based selective prediction raises AUARC by 0.086-0.096 and AUROC by 0.092-0.164 over a tuned CoT-SC baseline.
- When the decomposition is extracted from the model's own chain of thought on frontier thinking models, OC still produces positive selective-prediction lifts on 12 of 16 dataset-budget-metric cells.
Where Pith is reading between the lines
- Models that systematically violate operadic consistency are likely failing to treat queries as substitutable structures rather than as flat patterns.
- Training objectives that explicitly reward consistency between direct and composed answers could reduce compositional errors without extra labels.
- The same consistency check could be applied to any task whose queries admit iterated substitution, such as program synthesis or multi-step planning.
Load-bearing premise
A stated or extracted decomposition is a valid and faithful breakdown whose composition should equal the direct answer precisely when the model reasons correctly.
What would settle it
On a fresh multi-hop QA dataset, compute OC for many questions and find that its correlation with accuracy falls below 0.6 or loses statistical significance.
Figures
read the original abstract
Detecting LLM reasoning failures at inference time without ground-truth labels has motivated a wide range of confidence baselines, including self-consistency, semantic entropy, and P(True), built on within-question sampling and self-evaluation. Operad theory, the formalism for systems built by iterated substitution, suggests a complementary diagnostic: a model's direct answer to a compositional query should agree with the answer it produces by composing a stated decomposition of the same query. We instantiate this idea as operadic consistency (OC), a per-question signal. Across twelve instruction-tuned LLMs (4B to 671B parameters, open-weights and closed-source) on four multi-hop QA datasets, OC is strongly correlated with accuracy on every dataset (Pearson $r \in [0.86, 0.94]$, all $p \leq 0.0004$), and is the only signal we evaluate with $r \geq 0.85$ uniformly across all four datasets. Chain-of-thought self-consistency (CoT-SC; Wang et al., 2023) matches OC on HotpotQA and DROP ($r = 0.93, 0.87$) but drops to $r \approx 0.45$ on MuSiQue and StrategyQA. At the per-question level, OC contributes information beyond CoT-SC and semantic entropy on every dataset (cluster-robust $p \leq 10^{-16}$ for the OC coefficient), and the conclusion is robust to additionally controlling for constructed decomposition-aware baselines ($p \leq 10^{-13}$). The same signal yields selective-prediction improvements (accuracy at fixed coverage) over a tuned CoT-SC baseline at the equal-cost $K = 3$ budget (AUARC lifts of +0.086 to +0.096 and AUROC lifts of +0.092 to +0.164; 95% CIs exclude zero on every cell). On five frontier thinking models, where the decomposition is extracted from the model's own chain of thought, the same equal-cost comparison gives positive selective-prediction point-estimate lift on all 16 (dataset, budget, metric) cells tested, with 95% CIs excluding zero on 12 of the 16.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces operadic consistency (OC), a label-free per-question signal defined as agreement between an LLM's direct answer to a compositional query and the answer obtained by composing outputs on a stated or extracted decomposition of that query. It evaluates OC across 12 instruction-tuned LLMs (4B–671B parameters) on four multi-hop QA datasets, reporting Pearson correlations with accuracy of r ∈ [0.86, 0.94] (all p ≤ 0.0004), incremental predictive value over CoT-SC and semantic entropy in cluster-robust regressions (p ≤ 10^{-16}), and selective-prediction gains (AUARC lifts +0.086 to +0.096) at equal-cost K=3 budgets. The same pattern holds when decompositions are extracted from model CoTs on frontier thinking models.
Significance. If the decomposition-faithfulness assumption holds, OC supplies a theoretically grounded diagnostic for compositional failures that is more uniform across datasets than CoT-SC and yields practically useful selective-prediction improvements. The evaluation scale, robustness to additional decomposition-aware controls, and consistent positive lifts on 12/16 cells for frontier models are clear strengths. The result would be of interest to the inference-time reliability literature in NLP.
major comments (3)
- [Abstract, §4] Abstract and §4 (experimental setup): the central claim that OC specifically signals compositional reasoning failures rests on the assumption that stated/extracted decompositions are faithful (complete, non-extraneous, and correctly composable). No independent validation—human ratings of faithfulness, substitution of gold sub-answers, or checks for completeness—is reported. Without this, the observed r ≥ 0.86 correlations and incremental regression coefficients could be artifacts of decomposition quality correlating with question difficulty rather than a genuine compositional signal.
- [§5.2] §5.2 (per-question regressions): the cluster-robust p ≤ 10^{-16} for the OC coefficient after controlling for CoT-SC, semantic entropy, and constructed decomposition-aware baselines is load-bearing for the incremental-value claim, yet the construction of those decomposition-aware baselines is not detailed enough to confirm they fully isolate the operadic component from decomposition difficulty.
- [§4.3, Table 1] §4.3 and Table 1 (dataset statistics): the four datasets differ substantially in decomposition complexity (HotpotQA vs. MuSiQue), yet no per-dataset statistics on decomposition length, number of steps, or human-rated faithfulness are provided, making it impossible to assess whether the uniform high r for OC is driven by dataset-specific decomposition properties.
minor comments (2)
- [§3] Notation for the operadic composition operator is introduced without an explicit equation; adding a short formal definition (e.g., Eq. (1) in §3) would improve clarity.
- [§5.3] The selective-prediction results report 95% CIs excluding zero on most cells, but the exact bootstrap or cluster-robust procedure used to obtain those CIs is not stated.
Simulated Author's Rebuttal
Thank you for the referee's insightful comments regarding the faithfulness of decompositions and the need for more detailed statistics and baseline constructions. We provide point-by-point responses below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (experimental setup): the central claim that OC specifically signals compositional reasoning failures rests on the assumption that stated/extracted decompositions are faithful (complete, non-extraneous, and correctly composable). No independent validation—human ratings of faithfulness, substitution of gold sub-answers, or checks for completeness—is reported. Without this, the observed r ≥ 0.86 correlations and incremental regression coefficients could be artifacts of decomposition quality correlating with question difficulty rather than a genuine compositional signal.
Authors: We agree that independent validation of decomposition faithfulness would strengthen the claim. The manuscript reports consistent results using both stated decompositions and those extracted from model CoTs on frontier models, which provides indirect support against a pure artifact explanation. We did not collect human ratings or perform gold sub-answer substitutions. We will revise the discussion to explicitly acknowledge the faithfulness assumption as a limitation and expand details on decomposition construction to address potential correlations with question difficulty. revision: partial
-
Referee: [§5.2] §5.2 (per-question regressions): the cluster-robust p ≤ 10^{-16} for the OC coefficient after controlling for CoT-SC, semantic entropy, and constructed decomposition-aware baselines is load-bearing for the incremental-value claim, yet the construction of those decomposition-aware baselines is not detailed enough to confirm they fully isolate the operadic component from decomposition difficulty.
Authors: We agree that additional detail on baseline construction is warranted to allow readers to assess isolation of the operadic component. The construction is summarized in the appendix, but we will expand the main-text description in §5.2 (and move relevant appendix material forward) to fully specify the features used for decomposition difficulty controls. revision: yes
-
Referee: [§4.3, Table 1] §4.3 and Table 1 (dataset statistics): the four datasets differ substantially in decomposition complexity (HotpotQA vs. MuSiQue), yet no per-dataset statistics on decomposition length, number of steps, or human-rated faithfulness are provided, making it impossible to assess whether the uniform high r for OC is driven by dataset-specific decomposition properties.
Authors: We will add per-dataset statistics on decomposition length and number of steps to a revised Table 1 or new supplementary table in §4.3. Human-rated faithfulness ratings were not collected as part of this study; we will explicitly note this as a limitation and flag it for future work. The uniform high correlations across datasets that vary in complexity, including with model-extracted decompositions, provide supporting evidence for robustness. revision: partial
Circularity Check
No circularity: OC is an independent empirical signal
full rationale
The paper defines operadic consistency (OC) directly as agreement between a model's direct answer to a query and the answer obtained by composing answers to a stated decomposition of that query. It then reports an empirical Pearson correlation between this agreement signal and ground-truth accuracy across datasets, plus incremental predictive value in regression and selective-prediction metrics. None of these quantities are obtained by fitting a parameter to the target accuracy values and relabeling the fit as a prediction, nor does any central claim reduce to a self-citation chain or a definitional equivalence. The decomposition-faithfulness assumption is an interpretive premise required for the signal to be meaningful, but it is not smuggled into the reported statistics by construction; the statistics themselves remain externally falsifiable against held-out accuracy labels.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H allu M easure: Fine-grained Hallucination Measurement Using Chain-of-Thought Reasoning
Akbar, Shayan Ali and Hossain, Md Mosharaf and Wood, Tess and Chin, Si-Chi and Salinas, Erica M and Alvarez, Victor and Cornejo, Erwin. H allu M easure: Fine-grained Hallucination Measurement Using Chain-of-Thought Reasoning. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.837
-
[2]
A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
Jacovi, Alon and Bitton, Yonatan and Bohnet, Bernd and Herzig, Jonathan and Honovich, Or and Tseng, Michael and Collins, Michael and Aharoni, Roee and Geva, Mor. A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume...
-
[3]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[4]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[5]
Advances in Neural Information Processing Systems 37 (NeurIPS 2024) , year=
Uncertainty of Thoughts: Uncertainty-Aware Planning Enhances Information Seeking in Large Language Models , author=. Advances in Neural Information Processing Systems 37 (NeurIPS 2024) , year=
2024
-
[6]
arXiv preprint arXiv:2311.06189 , year=
Syntax-semantics interface: an algebraic model , author=. arXiv preprint arXiv:2311.06189 , year=
-
[7]
Weighted deductive parsing and
Nederhof, Mark-Jan , journal=. Weighted deductive parsing and. 2003 , publisher=
2003
-
[8]
Computational Linguistics , volume=
Semiring parsing , author=. Computational Linguistics , volume=
-
[9]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Buffer of thoughts: Thought-augmented reasoning with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Proceedings of the AAAI conference on artificial intelligence , volume=
Graph of thoughts: Solving elaborate problems with large language models , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[12]
Proceedings of ICLR , year=
Decomposed prompting: A modular approach for solving complex tasks , author=. Proceedings of ICLR , year=
-
[13]
Wolfson, Tomer and Geva, Mor and Gupta, Ankit and Gardner, Matt and Goldberg, Yoav and Deutch, Daniel and Berant, Jonathan , journal=
-
[14]
Proceedings of ICLR , year=
Self-consistency improves chain of thought reasoning in language models , author=. Proceedings of ICLR , year=
-
[15]
Mathematical surveys and monographs , volume=
Operads in algebra, topology and physics , author=. Mathematical surveys and monographs , volume=. 2002 , publisher=
2002
-
[16]
2012 , publisher=
Algebraic operads , author=. 2012 , publisher=
2012
-
[17]
2026 , note =
Bottman, Nathaniel and Richardson, Kyle , title =. 2026 , note =
2026
-
[18]
International Conference on Learning Representations (
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. International Conference on Learning Representations (
-
[19]
arXiv preprint arXiv:2207.05221 , year=
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
-
[20]
Transactions on Machine Learning Research , year=
Teaching models to express their uncertainty in words , author=. Transactions on Machine Learning Research , year=
-
[21]
EMNLP , year=
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback , author=. EMNLP , year=
-
[22]
ICLR , year=
Let's verify step by step , author=. ICLR , year=
-
[23]
arXiv preprint arXiv:2211.14275 , year=
Solving math word problems with process- and outcome-based feedback , author=. arXiv preprint arXiv:2211.14275 , year=
-
[24]
Nature , volume=
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=
-
[25]
Linguistic Analysis , volume=
Mathematical foundations for a compositional distributional model of meaning , author=. Linguistic Analysis , volume=
-
[26]
NeurIPS , year=
Selective classification for deep neural networks , author=. NeurIPS , year=
-
[27]
Skywork-o1 Open Series , author =. 2024 , publisher =. doi:10.5281/zenodo.16998085 , url =
-
[28]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
Measuring and Narrowing the Compositionality Gap in Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , year =
2023
-
[29]
2024 , note =
Dong, Hanze and Xiong, Wei and Pang, Bo and Wang, Haoxiang and Zhao, Han and Zhou, Yingbo and Jiang, Nan and Sahoo, Doyen and Xiong, Caiming and Zhang, Tong , journal =. 2024 , note =
2024
-
[30]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , series =
Compositional Causal Reasoning Evaluation in Language Models , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , series =
-
[31]
Dua, Dheeru and Wang, Yizhong and Dasigi, Pradeep and Stanovsky, Gabriel and Singh, Sameer and Gardner, Matt , booktitle =
-
[32]
arXiv preprint arXiv:2506.18183 , year =
Mei, Zhiting and Zhang, Christina and Yin, Tenny and Lidard, Justin and Shorinwa, Ola and Majumdar, Anirudha , title =. arXiv preprint arXiv:2506.18183 , year =
-
[33]
arXiv preprint arXiv:2505.14489 , year =
Yoon, Dongkeun and Kim, Seungone and Yang, Sohee and Kim, Sunkyoung and Kim, Soyeon and Kim, Yongil and Choi, Eunbi and Kim, Yireun and Seo, Minjoon , title =. arXiv preprint arXiv:2505.14489 , year =
-
[34]
arXiv preprint arXiv:2504.03579 , year =
Ciosek, Kamil and Felicioni, Nicol\`o and Ghiassian, Sina , title =. arXiv preprint arXiv:2504.03579 , year =
-
[35]
International Conference on Machine Learning (ICML) , year =
Zeng, Thomas and Zhang, Shuibai and Wu, Shutong and Classen, Christian and Chae, Daewon and Ewer, Ethan and Lee, Minjae and Kim, Heeju and Kang, Wonjun and Kunde, Jackson and Fan, Ying and Kim, Jungtaek and Koo, Hyung Il and Ramchandran, Kannan and Papailiopoulos, Dimitris and Lee, Kangwook , title =. International Conference on Machine Learning (ICML) , year =
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Wang, Xinyi and Song, Yiping and Tian, Zhiliang and Liu, Bo and Luo, Tingjin and Huang, Minlie , title =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[37]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , booktitle =
Zhou, Denny and Sch. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models , booktitle =. 2023 , url =. 2205.10625 , archivePrefix =
Pith/arXiv arXiv 2023
-
[38]
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
Wang, Lei and Xu, Wanyu and Lan, Yihuai and Hu, Zhiqiang and Lan, Yunshi and Lee, Roy Ka-Wei and Lim, Ee-Peng , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , address =. doi:10.18653/v1/2023.acl-long.147 , url =. 2305.04091 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.acl-long.147 2023
-
[39]
Turpin, Miles and Michael, Julian and Perez, Ethan and Bowman, Samuel R. , title =. Advances in Neural Information Processing Systems 36 (NeurIPS) , year =. 2305.04388 , archivePrefix =
-
[40]
Measuring Faithfulness in Chain-of-Thought Reasoning , year =
Lanham, Tamera and Chen, Anna and Radhakrishnan, Ansh and Steiner, Benoit and Denison, Carson and Hernandez, Danny and Li, Dustin and Durmus, Esin and Hubinger, Evan and Kernion, Jackson and Luko. Measuring Faithfulness in Chain-of-Thought Reasoning , year =. 2307.13702 , archivePrefix =
-
[41]
Manakul, Potsawee and Liusie, Adian and Gales, Mark J. F. , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2023 , address =. doi:10.18653/v1/2023.emnlp-main.557 , url =. 2303.08896 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.emnlp-main.557 2023
-
[42]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.510 , url =. 2312.08935 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.510 2024
-
[43]
Fong, Brendan and Spivak, David I. , title =. 2019 , publisher =. doi:10.1017/9781108668804 , url =
-
[44]
Position: Categorical Deep Learning is an Algebraic Theory of All Architectures , booktitle =
Gavranovi. Position: Categorical Deep Learning is an Algebraic Theory of All Architectures , booktitle =. 2024 , publisher =. 2402.15332 , archivePrefix =
arXiv 2024
-
[45]
Proceedings of the Third Workshop on Uncertainty-Aware
Podolak, Jakub and Verma, Rajeev , title =. Proceedings of the Third Workshop on Uncertainty-Aware. 2025 , eprint =
2025
- [46]
-
[47]
Biran, Eden and Gottesman, Daniela and Yang, Sohee and Geva, Mor and Globerson, Amir , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =. 2406.12775 , archivePrefix =
arXiv 2024
-
[48]
Lindsey, Jack and Gurnee, Wes and Ameisen, Emmanuel and Chen, Brian and Pearce, Adam and Turner, Nicholas L. and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.