Rational Sparse Autoencoder
Pith reviewed 2026-06-27 04:26 UTC · model grok-4.3
The pith
Trainable rational functions replace fixed nonlinearities in sparse autoencoders and improve reconstruction and downstream metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The RSAE replaces the fixed encoder activation with a trainable rational function. It is realized through a two-stage pipeline that copies baseline SAE weights, obtains rational coefficients via relaxed Remez exchange on synthetic data, calibrates scale parameters, and then fine-tunes under the standard sparsity-regularized reconstruction objective. On residual-stream activations of three open-weight language models and across three baseline activation families, the RSAE strictly improves both reconstruction-side metrics and downstream-behavior metrics after fine-tuning, without sacrificing feature-level interpretability under sparse probing, with gains consistent across host models, baselin
What carries the argument
The trainable rational function used as the encoder nonlinearity, which supplies a richer function class that uniformly approximates the activation primitives of existing SAE families while adapting to observed pre-activation geometry.
If this is right
- RSAE achieves a better reconstruction-versus-sparsity trade-off than fixed-activation baselines.
- Downstream-behavior metrics improve while feature interpretability under sparse probing is preserved.
- Gains remain consistent across all tested host language models, baseline activation families, and sparsity levels.
- The method adds only a small number of scalar parameters per autoencoder and completes in minutes on consumer hardware.
- The rational activation can be initialized to match any of the three standard SAE families before adaptation.
Where Pith is reading between the lines
- Rational activations could be tested as drop-in replacements in other sparse coding or dictionary-learning settings beyond SAEs.
- The same two-stage Remez-plus-fine-tuning pipeline might be applied to learn other parametric activation families for interpretability tools.
- If rational functions adapt to pre-activation geometry, they may surface feature types that fixed nonlinearities systematically miss in language-model residuals.
- Scaling the approach to larger models would require checking whether the added parameters remain negligible relative to total SAE size.
Load-bearing premise
The two-stage initialization with relaxed Remez on synthetic data plus scale calibration, followed by standard fine-tuning, reliably yields a rational function that outperforms the original fixed nonlinearity without introducing new instabilities or metric-specific artifacts.
What would settle it
Apply the RSAE pipeline to residual-stream activations from one of the three tested language models; if after fine-tuning the reconstruction error or any downstream-behavior metric fails to improve over the corresponding baseline SAE on the same data, the central empirical claim is false.
Figures
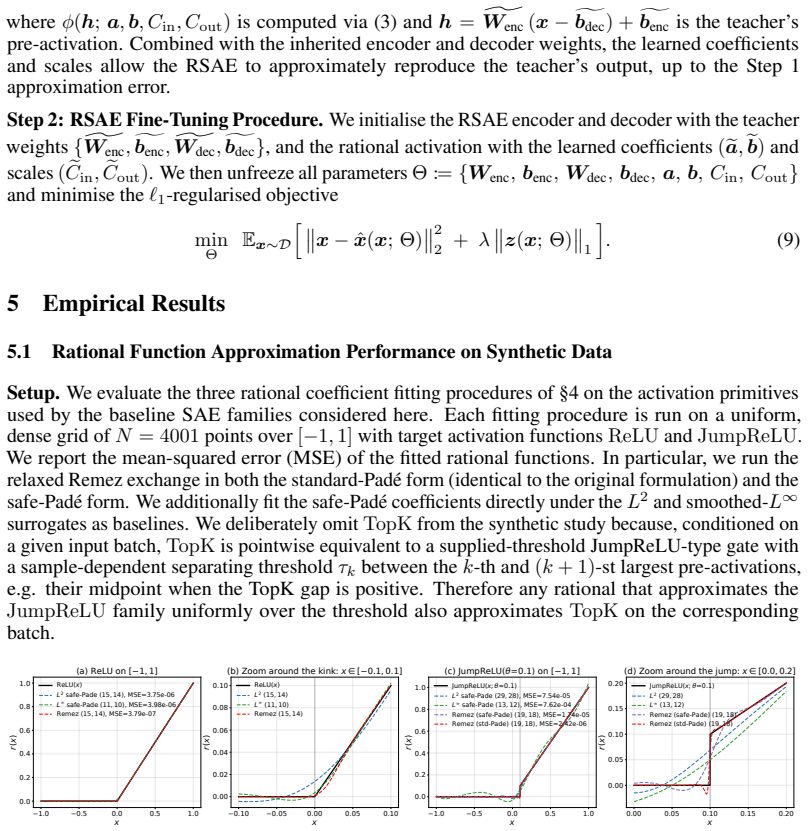

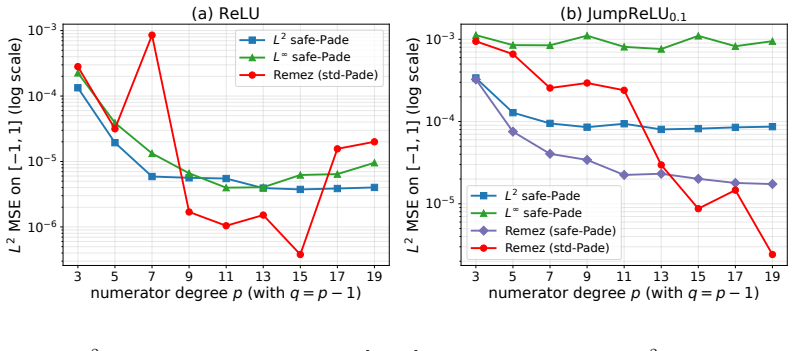
read the original abstract
Sparse autoencoders (SAEs) are standard tools for mechanistic interpretability, but current SAE families are constrained by fixed encoder nonlinearities such as ReLU, JumpReLU, and TopK. This hard-codes a particular sparsity mechanism into the model and can distort the reconstruction-versus-sparsity trade-off. We introduce the Rational Sparse Autoencoder (RSAE), which replaces the fixed encoder activation with a trainable rational function. Rational activations are flexible enough to uniformly approximate the activation primitives used by existing SAE families on compact domains (for TopK, the thresholded gate obtained after a separating top-k threshold is supplied), while also providing a richer function class for adapting to the observed pre-activation geometry. We realise this idea through a two-stage pipeline: an initialisation procedure that copies the pre-trained baseline SAE weights, plugs in rational coefficients obtained by the relaxed Remez exchange on synthetic data, and calibrates the scale parameters along with the rational coefficients; followed by a fine-tuning step under the standard sparsity-regularised reconstruction objective. Empirically, on residual-stream activations of three open-weight language models and across all three baseline activation families, the RSAE strictly improves on it after the fine-tuning step, both on reconstruction-side metrics and on downstream-behaviour metrics, without sacrificing feature-level interpretability under sparse probing. These gains are consistent across host language models, across baseline activation families, and across the full range of baseline sparsity we tested, while the upgrade itself adds only a handful of scalar parameters per autoencoder and runs in minutes on a single consumer GPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Rational Sparse Autoencoders (RSAEs), which replace the fixed encoder nonlinearity (ReLU, JumpReLU, TopK) in standard SAEs with a trainable rational function. It describes a two-stage procedure—copying baseline weights, initializing rational coefficients via relaxed Remez exchange on synthetic data plus scale calibration, then fine-tuning under the standard sparsity-regularized reconstruction loss—and claims that the resulting RSAEs strictly outperform the original baselines on reconstruction metrics, sparsity, downstream behavior, and sparse-probing interpretability across three language models, three activation families, and a range of sparsity levels, while adding only a few scalar parameters per autoencoder.
Significance. If the attribution to the rational activation class holds after proper controls, the work would provide a lightweight, more flexible activation primitive that can approximate existing SAE nonlinearities while adapting to data geometry. This could meaningfully improve the reconstruction-sparsity frontier in mechanistic interpretability without requiring architectural overhauls, and the minimal parameter overhead plus rapid fine-tuning would make it practically attractive.
major comments (1)
- [Experimental results / evaluation protocol] The central empirical claim attributes performance gains to the trainable rational activation, yet the described pipeline fine-tunes only the RSAE (baseline weights + rational init) and reports no control in which the original baseline SAEs (fixed nonlinearity) receive identical fine-tuning steps and hyperparameters. Without this comparison, it is impossible to separate the effect of the rational function class from the effect of additional optimization on the linear weights. This directly undermines the attribution in the strongest claim and must be addressed with new experiments.
minor comments (2)
- [Abstract / introduction] The abstract states that rational functions 'uniformly approximate the activation primitives used by existing SAE families on compact domains' but does not specify the domain size or the approximation error achieved for each baseline family; a short quantitative statement or reference to a supplementary table would clarify the claim.
- [Methods] Notation for the rational function (numerator/denominator degrees, coefficient vectors) is introduced without an explicit equation; adding a numbered equation in the methods section would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental protocol. The point raised is valid and we will address it directly with additional controls in the revision.
read point-by-point responses
-
Referee: [Experimental results / evaluation protocol] The central empirical claim attributes performance gains to the trainable rational activation, yet the described pipeline fine-tunes only the RSAE (baseline weights + rational init) and reports no control in which the original baseline SAEs (fixed nonlinearity) receive identical fine-tuning steps and hyperparameters. Without this comparison, it is impossible to separate the effect of the rational function class from the effect of additional optimization on the linear weights. This directly undermines the attribution in the strongest claim and must be addressed with new experiments.
Authors: We agree that the current experiments do not isolate the contribution of the rational activation from the effect of additional fine-tuning on the linear weights. In the revised manuscript we will add the requested control: each baseline SAE (with its original fixed nonlinearity) will be fine-tuned for the same number of steps, using identical optimizer settings, learning rate schedule, sparsity coefficient, and batch size as the corresponding RSAE. We will report reconstruction, sparsity, and downstream metrics for these fine-tuned baselines alongside the RSAE results. This will allow a direct comparison that attributes any remaining gains to the trainable rational function. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks, not self-definition or fitted inputs
full rationale
The paper describes a two-stage initialization (relaxed Remez on synthetic data plus scale calibration) followed by fine-tuning under the standard objective, then reports empirical gains on reconstruction, sparsity, and probing metrics across three models and three activation families. No quoted equations or steps reduce these measured improvements to quantities defined by the fitted rational coefficients themselves, nor do any self-citations serve as load-bearing uniqueness theorems. The initialization draws on standard approximation theory rather than prior author work, and the results are presented as direct comparisons against fixed-nonlinearity baselines on held-out data. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- rational function coefficients
Reference graph
Works this paper leans on
-
[1]
Bart Bussmann, Patrick Leask, and Neel Nanda
URL https://transformer-circuits.pub/2023/ monosemantic-features. Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders.arXiv preprint arXiv:2412.06410,
arXiv 2023
-
[2]
Learning multi-level features with matryoshka sparse autoencoders.arXiv preprint arXiv:2503.17547,
Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. Learning multi-level features with matryoshka sparse autoencoders.arXiv preprint arXiv:2503.17547,
-
[3]
Zhiqian Chen, Feng Chen, Rongjie Lai, Xuchao Zhang, and Chang-Tien Lu. Rational neural networks for approximating jump discontinuities of graph convolution operator.arXiv preprint arXiv:1808.10073,
-
[5]
Introduces the safe- Padé parameterisation
URL https://arxiv.org/abs/2102.09407. Introduces the safe- Padé parameterisation. 11 Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable llm feature circuits.Advances in Neural Information Processing Systems, 37:24375–24410,
-
[6]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. InInternational Conference on Learning Representations, volume 2025, pages 26721–26754,
2025
-
[7]
Sparse autoen- coders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Smith, Aidan Ewart, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models. InInternational Conference on Learning Representations, volume 2024, pages 7827–7845,
2024
-
[8]
Donald J Newman.Approximation with rational functions
arXiv:1907.06732. Donald J Newman.Approximation with rational functions. Number
arXiv 1907
-
[9]
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, Janos Kramar, Rohin Shah, and Neel Nanda. Improving sparse decomposition of language model activations with gated sparse autoencoders.Advances in Neural Information Processing Systems, 37:775–818, 2024a. Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy,...
-
[10]
LessWrong post. Maosen Tang and Alex Townsend. Rational neural networks have expressivity advantages.arXiv preprint arXiv:2602.12390,
-
[11]
Consequently, for every 0< ε <1 , there is a rational function of size O log(1/ε) log(1/δ) that approximates sign on Eδ to uniform error ε
A Detailed Proofs Lemma 1(Zolotarev; rational approximation of sign).For every δ∈(0,1) and n≥1 there is a type-(2n+ 1,2n) rational sn,δ such that supx∈Eδ sign(x)−s n,δ(x) ≤4 exp −π 2n/log(4/δ) . Consequently, for every 0< ε <1 , there is a rational function of size O log(1/ε) log(1/δ) that approximates sign on Eδ to uniform error ε. For deep-layer network...
2017
-
[12]
For an integer m≥1 , take the Zolotarev sign function sm of type (3m,3 m −1) . By the composition property of Zolotarev sign functions, sm can be written as 13 a composition of m rational maps of type (3,2) , so it is represented by a constant-width rational network with internal depthm. As in the proof of Lemma 1 in Boullé et al. [2020], choose the gap p...
2020
-
[13]
Define G(u) := 1 +s(u) 2 , eH(t) := 1 +s(t/2) 2 ,ez i(h;τ k) :=h i eH(h i −τ k)
Applying Lemma 1 tou=t i/2gives a shared scalar rational functionssuch that sup |t|∈[δ,2] sign(t)−s t 2 ≤ε. Define G(u) := 1 +s(u) 2 , eH(t) := 1 +s(t/2) 2 ,ez i(h;τ k) :=h i eH(h i −τ k). 16 Then, for every(h, τ k)∈Ω T δ , |ezi(h;τ k)−z T,i(h;τ k)| ≤ |h i| |eH(h i −τ k)−H(h i −τ k)| ≤ ε 2 ≤ε. For the direct trainable rational-activation implementation, k...
2016
-
[14]
We refer to the safe-Padé form distilled from the standard-Padé Remez fit as Route A
that targets the L∞ minimax objective (7) in the family Q(t) = 1 +P j ϕjtj with signed ϕj; (ii) safe-Padé Remez via warm-start (Route A), in which the converged standard- Padé Remez coefficients are distilled onto the pole-free family Q(t) = 1 + P j |bj||t|j of (3) by least-squares fitting on {tℓ}N ℓ=1; (iii) L2 safe-Padé fit, minimising 1 N P ℓ(r(a,b)(tℓ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.