EyeMVP: OCT-Informed Fundus Representation Learning via Paired CFP--OCT Pretraining
Pith reviewed 2026-06-30 10:20 UTC · model grok-4.3
The pith
Paired CFP-OCT pretraining transfers depth information into color fundus photography features for stronger single-modality diagnosis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EyeMVP shows that cross-modal masked reconstruction from paired CFP-OCT data can enrich CFP features with OCT-associated supervision, producing representations that support accurate CFP-only inference on tasks where depth information matters.
What carries the argument
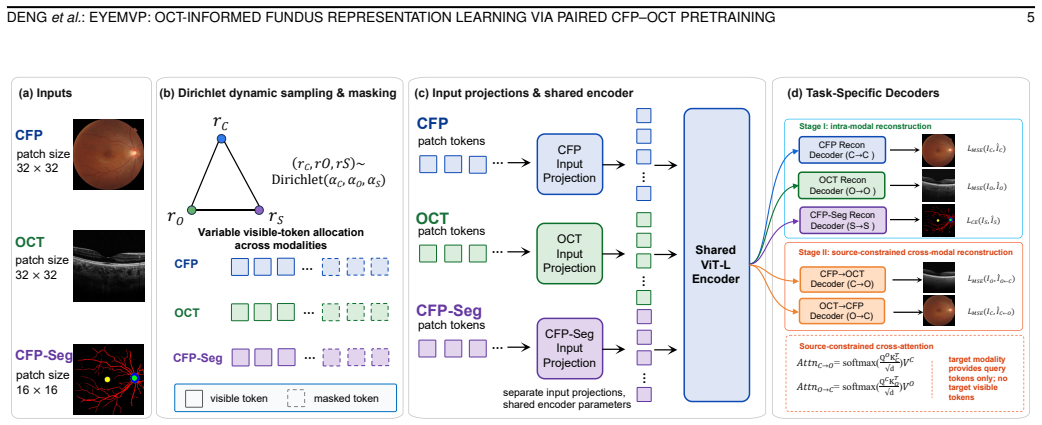
Cross-modal masked reconstruction paired with source-constrained cross-attention and CFP-derived structural masks that accommodate non-aligned CFP and OCT geometry.
If this is right
- The model attains AUROCs of 0.923 for macular edema and 0.867 for myopic macular schisis using only CFP at inference.
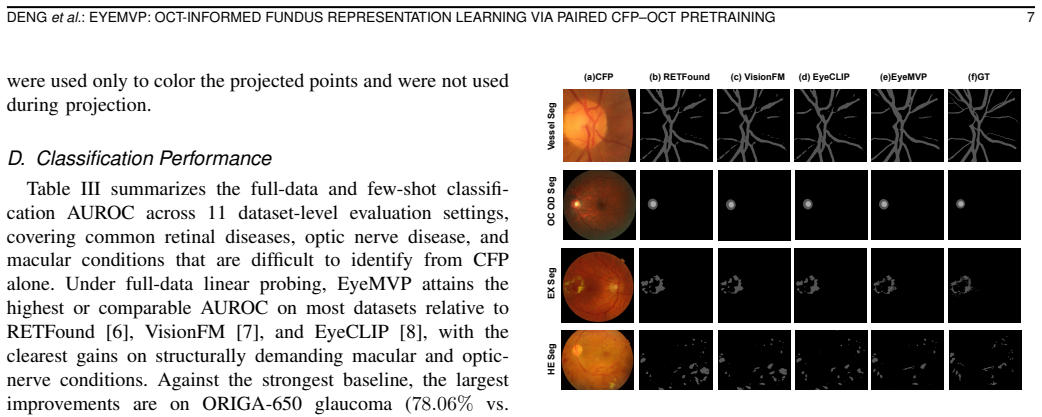
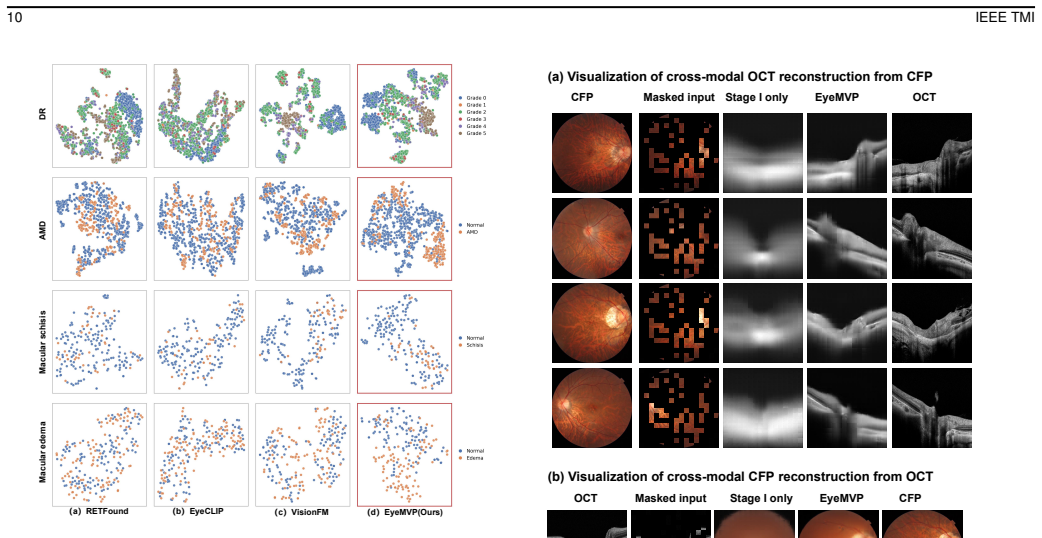
- Consistent performance gains appear on macular and optic-nerve tasks across both classification and segmentation.
- EyeMVP matches or exceeds representative retinal foundation models in 15 dataset-level settings under full-data and few-shot regimes.
- In the reader study the model surpasses junior and intermediate ophthalmologists on macular edema and all groups on myopic macular schisis.
Where Pith is reading between the lines
- The same paired-pretraining pattern could be tested on other accessible-versus-informative modality pairs in medical imaging.
- Large multi-hospital paired datasets appear sufficient to bootstrap single-modality models that retain cross-modal benefits.
- The few-shot gains suggest the learned representations may reduce labeled data needs in new clinical sites.
Load-bearing premise
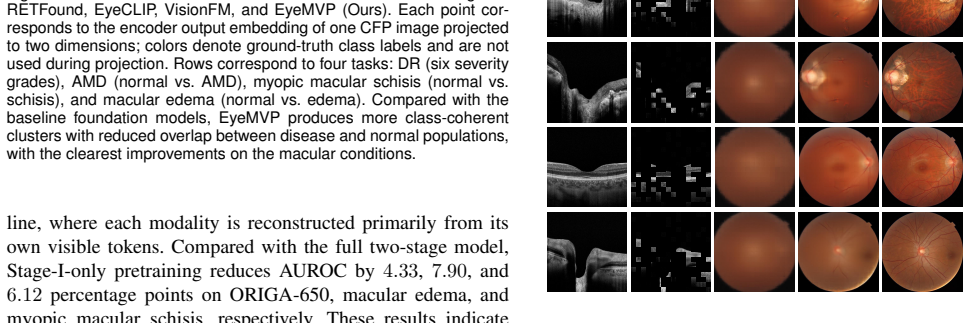
The cross-modal masked reconstruction and source-constrained cross-attention successfully transfer OCT-derived structural information into CFP features despite non-aligned geometry.
What would settle it
An ablation that removes the OCT pretraining component and shows no drop in AUROC on macular edema or myopic macular schisis classification would falsify the transfer claim.
Figures
read the original abstract
Color fundus photography (CFP) is the mainstay of large-scale retinal screening, but its diagnostic capacity is limited by the lack of depth-resolved structure, which optical coherence tomography (OCT) provides yet is less accessible at population scale. We present EyeMVP, a cross-modal retinal foundation model that uses paired CFP--OCT pretraining to learn OCT-informed CFP representations while requiring only CFP at inference. Pretrained on 674,893 same-eye same-day CFP--OCT triples from 112,642 patients across eight hospitals, EyeMVP uses cross-modal masked reconstruction to enrich CFP features with OCT-associated supervision, and combines source-constrained cross-attention with CFP-derived structural masks to accommodate the non-aligned geometry of en-face CFP and cross-sectional OCT. Across 15 dataset-level settings spanning classification and segmentation, under both full-data and few-shot regimes, EyeMVP performs on par with or better than representative retinal foundation models, with consistent gains on macular and optic-nerve tasks; it attains AUROCs of 0.923 for macular edema and 0.867 for myopic macular schisis, two conditions poorly resolved in CFP. In an exploratory reader study, EyeMVP surpasses junior and intermediate ophthalmologists but not seniors on macular edema, while exceeding all groups on myopic macular schisis. These results indicate that cross-modal reconstruction can enrich CFP representations with OCT-associated supervision, offering a practical route to stronger CFP-based screening.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents EyeMVP, a cross-modal retinal foundation model pretrained on 674,893 same-eye same-day CFP-OCT triples from 112,642 patients. It employs cross-modal masked reconstruction and source-constrained cross-attention (guided by CFP-derived structural masks) to learn OCT-informed CFP representations usable at inference with only CFP input. The model is evaluated across 15 dataset-level settings for classification and segmentation under full-data and few-shot regimes, reporting AUROCs of 0.923 for macular edema and 0.867 for myopic macular schisis, with performance on par with or better than existing retinal foundation models and gains on macular/optic-nerve tasks.
Significance. If the pretraining demonstrably transfers depth-resolved structural cues from OCT into CFP features despite non-aligned geometries, the work would provide a practical route to stronger population-scale CFP screening for conditions poorly resolved in en-face imaging alone. The scale of the paired pretraining corpus and the reader-study comparison with ophthalmologists are notable strengths that would support clinical relevance if the transfer mechanism is validated.
major comments (3)
- [Abstract and §3] Abstract and §3 (Pretraining Method): The central claim that cross-modal masked reconstruction plus source-constrained cross-attention successfully transfers OCT depth cues into CFP features rests on the attention mechanism accommodating non-aligned en-face vs. cross-sectional geometry; no alignment metrics, attention-map visualizations, or ablation isolating the cross-attention component versus data-scale effects are referenced, leaving open the possibility that reported gains are explained by pretraining volume alone.
- [§4 and Tables] §4 (Experiments) and Table 2/3 (if present): Performance numbers (AUROC 0.923 macular edema, 0.867 myopic macular schisis) are stated without reported validation-split details, number of random seeds, confidence intervals, or statistical tests against baselines; this prevents assessment of whether the consistent gains on macular tasks are robust or sensitive to split choice.
- [§3.2] §3.2 (Source-Constrained Cross-Attention): The description of CFP-derived structural masks guiding attention must include a concrete demonstration (e.g., correlation with OCT thickness maps or reconstruction error stratified by retinal layer) that depth-resolved information is actually encoded; without this, the method's ability to bridge the geometric mismatch remains an unverified assumption.
minor comments (2)
- [Abstract] Abstract: The phrase 'on par with or better than representative retinal foundation models' should be accompanied by the exact list of compared models and their pretraining data sources for immediate clarity.
- [§5] §5 (Reader Study): Clarify the number of cases, reader experience definitions (junior/intermediate/senior), and whether the study was conducted on held-out data with the same distribution as the quantitative benchmarks.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to strengthen the presentation of our method and results. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Pretraining Method): The central claim that cross-modal masked reconstruction plus source-constrained cross-attention successfully transfers OCT depth cues into CFP features rests on the attention mechanism accommodating non-aligned en-face vs. cross-sectional geometry; no alignment metrics, attention-map visualizations, or ablation isolating the cross-attention component versus data-scale effects are referenced, leaving open the possibility that reported gains are explained by pretraining volume alone.
Authors: We agree that visualizations and an ablation isolating the cross-attention would provide stronger support for the transfer mechanism. The current results show consistent gains on macular and optic-nerve tasks relative to other foundation models pretrained at comparable scale, but this does not fully rule out data-volume effects. In revision we will add (i) attention-map visualizations illustrating how source-constrained cross-attention aligns CFP regions with OCT-derived structure and (ii) an ablation comparing the full model against a masked-reconstruction baseline without the cross-attention module. Alignment metrics are not applicable in the strict pixel sense because the modalities have fundamentally different geometries; the method is explicitly designed to operate without such alignment. revision: yes
-
Referee: [§4 and Tables] §4 (Experiments) and Table 2/3 (if present): Performance numbers (AUROC 0.923 macular edema, 0.867 myopic macular schisis) are stated without reported validation-split details, number of random seeds, confidence intervals, or statistical tests against baselines; this prevents assessment of whether the consistent gains on macular tasks are robust or sensitive to split choice.
Authors: The observation is correct; the manuscript reports single-split point estimates. In the revised version we will (i) specify the exact train/validation/test splits used for each of the 15 settings, (ii) report means and standard deviations (or 95% confidence intervals) over at least three random seeds, and (iii) add statistical comparisons (DeLong tests for AUROC, paired t-tests for other metrics) against the strongest baselines to quantify whether the observed macular-task gains are statistically significant. revision: yes
-
Referee: [§3.2] §3.2 (Source-Constrained Cross-Attention): The description of CFP-derived structural masks guiding attention must include a concrete demonstration (e.g., correlation with OCT thickness maps or reconstruction error stratified by retinal layer) that depth-resolved information is actually encoded; without this, the method's ability to bridge the geometric mismatch remains an unverified assumption.
Authors: We accept that a direct empirical link between the masks/attention and depth-resolved OCT quantities would strengthen the claim. While downstream task gains on conditions that require depth information provide indirect evidence, they do not constitute the requested demonstration. In revision we will add an analysis correlating attention weights (or per-layer reconstruction error) with OCT thickness maps and retinal-layer segmentations on a held-out paired subset, thereby verifying that depth-resolved structure is being encoded. revision: yes
Circularity Check
No significant circularity; standard cross-modal pretraining with empirical claims
full rationale
The paper describes a pretraining method on paired CFP-OCT data using cross-modal masked reconstruction and source-constrained cross-attention to learn CFP representations informed by OCT. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or method outline. Performance numbers (e.g., AUROC 0.923) are presented as empirical results from large-scale pretraining rather than reductions by construction. The derivation chain is self-contained against external benchmarks with no patterns from the enumerated circularity types.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Trends in prevalence of blindness and distance and near vision impairment over 30 years: an analysis for the global burden of disease study,
R. Bourne, J. D. Steinmetz, S. Flaxman, P. S. Briant, H. R. Taylor, S. Resnikoff, R. J. Casson, A. Abdoli, E. Abu-Gharbieh, A. Afshin, et al., “Trends in prevalence of blindness and distance and near vision impairment over 30 years: an analysis for the global burden of disease study,”The Lancet global health, vol. 9, no. 2, pp. e130–e143, 2021
2021
-
[2]
Mohammadpour,Diagnostics in ocular imaging: cornea, retina, glaucoma and orbit
M. Mohammadpour,Diagnostics in ocular imaging: cornea, retina, glaucoma and orbit. Cham: Springer Nature, 2020
2020
-
[3]
Self-supervised representation learning: Introduction, advances, and challenges,
L. Ericsson, H. Gouk, C. C. Loy, and T. M. Hospedales, “Self-supervised representation learning: Introduction, advances, and challenges,”IEEE Signal Processing Magazine, vol. 39, no. 3, pp. 42–62, 2022
2022
-
[4]
Contrastive representation learning: A framework and review,
P. H. Le-Khac, G. Healy, and A. F. Smeaton, “Contrastive representation learning: A framework and review,”Ieee Access, vol. 8, pp. 193907– 193934, 2020. 12 IEEE TMI
2020
-
[5]
Ophglm: An ophthalmology large language-and- vision assistant,
Z. Deng, W. Gao, C. Chen, Z. Niu, Z. Gong, R. Zhang, Z. Cao, F. Li, Z. Ma, W. Wei,et al., “Ophglm: An ophthalmology large language-and- vision assistant,”Artificial Intelligence in Medicine, vol. 157, p. 103001, 2024
2024
-
[6]
A foundation model for generalizable disease detection from retinal images,
Y . Zhou, M. A. Chia, S. K. Wagner, M. S. Ayhan, D. J. Williamson, R. R. Struyven, T. Liu, M. Xu, M. G. Lozano, P. Woodward-Court, et al., “A foundation model for generalizable disease detection from retinal images,”Nature, vol. 622, no. 7981, pp. 156–163, 2023
2023
-
[7]
Development and validation of a multimodal multitask vision foundation model for generalist ophthalmic artificial intelligence,
J. Qiu, J. Wu, H. Wei, P. Shi, M. Zhang, Y . Sun, L. Li, H. Liu, H. Liu, S. Hou,et al., “Development and validation of a multimodal multitask vision foundation model for generalist ophthalmic artificial intelligence,” NEJM AI, vol. 1, no. 12, p. AIoa2300221, 2024
2024
-
[8]
A multimodal visual–language foundation model for computational ophthalmology,
D. Shi, W. Zhang, J. Yang, S. Huang, X. Chen, P. Xu, K. Jin, S. Lin, J. Wei, M. Yusufu,et al., “A multimodal visual–language foundation model for computational ophthalmology,”npj Digital Medicine, vol. 8, no. 1, p. 381, 2025
2025
-
[9]
Eyefound: a multimodal generalist foundation model for ophthalmic imaging,
D. Shi, W. Zhang, X. Chen, Y . Liu, J. Yang, S. Huang, Y . C. Tham, Y . Zheng, and M. He, “Eyefound: a multimodal generalist foundation model for ophthalmic imaging,”arXiv preprint arXiv:2405.11338, 2024
-
[10]
Multimodal foundation model and benchmark for comprehensive reti- nal oct image analysis,
J. Morano, B. Fazekas, E. S ¨ukei, R. Fecso, T. Emre, M. Gumpinger, G. Faustmann, M. Oghbaie, U. Schmidt-Erfurth, and H. Bogunovi ´c, “Multimodal foundation model and benchmark for comprehensive reti- nal oct image analysis,”NPJ Digital Medicine, vol. 8, no. 1, p. 576, 2025
2025
-
[11]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark,et al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, pp. 8748–8763, PmLR, 2021
2021
-
[12]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 16000– 16009, 2022
2022
-
[13]
Multimae: Multi- modal multi-task masked autoencoders,
R. Bachmann, D. Mizrahi, A. Atanov, and A. Zamir, “Multimae: Multi- modal multi-task masked autoencoders,” inEuropean Conference on Computer Vision, pp. 348–367, Springer, 2022
2022
-
[14]
The war on diabetic retinopathy: where are we now?,
T. Y . Wong and C. Sabanayagam, “The war on diabetic retinopathy: where are we now?,”Asia-Pacific Journal of Ophthalmology, vol. 8, no. 6, pp. 448–456, 2019
2019
-
[15]
Pre- dicting optical coherence tomography-derived diabetic macular edema grades from fundus photographs using deep learning,
A. V . Varadarajan, P. Bavishi, P. Raumviboonsuk, P. Chotcomwongse, S. Venugopalan, A. Narayanaswamy, J. Cuadros, K. Kanai, G. Bresnick, M. Tadarati, S. Silpa-Archa, J. Limwattanayingyong, V . Nganthavee, J. Ledsam, P. A. Keane, G. S. Corrado, L. Peng, and D. R. Webster, “Pre- dicting optical coherence tomography-derived diabetic macular edema grades from...
2018
-
[16]
From machine to machine: An oct-trained deep learning algorithm for objective quan- tification of glaucomatous damage in fundus photographs,
F. A. Medeiros, A. A. Jammal, and A. C. Thompson, “From machine to machine: An oct-trained deep learning algorithm for objective quan- tification of glaucomatous damage in fundus photographs,” 2018
2018
-
[17]
Multieye: Dataset and benchmark for oct-enhanced retinal disease recognition from fundus images,
L. Wang, C. Qi, C. Ou, L. An, M. Jin, X. Kong, and X. Li, “Multieye: Dataset and benchmark for oct-enhanced retinal disease recognition from fundus images,”IEEE Transactions on Medical Imaging, 2024
2024
-
[18]
A foundation language-image model of the retina (flair): Encoding expert knowledge in text supervision,
J. Silva-Rodriguez, H. Chakor, R. Kobbi, J. Dolz, and I. B. Ayed, “A foundation language-image model of the retina (flair): Encoding expert knowledge in text supervision,”Medical Image Analysis, vol. 99, p. 103357, 2025
2025
-
[19]
Crossmae: Cross-modality masked autoencoders for region- aware audio-visual pre-training,
Y . Guo, S. Sun, S. Ma, K. Zheng, X. Bao, S. Ma, W. Zou, and Y . Zheng, “Crossmae: Cross-modality masked autoencoders for region- aware audio-visual pre-training,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 26721– 26731, 2024
2024
-
[20]
Multi-modal masked autoencoders for medical vision-and-language pre-training,
Z. Chen, Y . Du, J. Hu, Y . Liu, G. Li, X. Wan, and T.-H. Chang, “Multi-modal masked autoencoders for medical vision-and-language pre-training,” 2022
2022
-
[21]
Acquire continuous and precise score for fundus image quality assessment: Fthnet and fqs dataset,
Z. Gong, Z. Deng, R. Gan, Z. Niu, L. Chen, C. Huang, J. Liang, W. Gao, F. Li, S. Zhang,et al., “Acquire continuous and precise score for fundus image quality assessment: Fthnet and fqs dataset,”Scientific Reports, vol. 15, no. 1, p. 40524, 2025
2025
-
[22]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pp. 234–241, Springer, 2015
2015
-
[23]
Unet++: Redesigning skip connections to exploit multiscale features in image segmentation,
Z. Zhou, M. M. R. Siddiquee, N. Tajbakhsh, and J. Liang, “Unet++: Redesigning skip connections to exploit multiscale features in image segmentation,”IEEE transactions on medical imaging, vol. 39, no. 6, pp. 1856–1867, 2019
2019
-
[24]
Attention U-Net: Learning Where to Look for the Pancreas
O. Oktay, J. Schlemper, L. L. Folgoc, M. Lee, M. Heinrich, K. Misawa, K. Mori, S. McDonagh, N. Y . Hammerla, B. Kainz,et al., “Atten- tion u-net: Learning where to look for the pancreas,”arXiv preprint arXiv:1804.03999, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Ftsegnet: A novel transformer-based fundus tumor segmentation model guided by pre-trained classification results,
Z. Deng, Z. Gong, W. Gao, J. Yang, L. Shao, F. Li, W. Wei, and L. Ma, “Ftsegnet: A novel transformer-based fundus tumor segmentation model guided by pre-trained classification results,” in2024 IEEE International Symposium on Biomedical Imaging (ISBI), pp. 1–5, IEEE, 2024
2024
-
[26]
A fundus image dataset for ai-based artery-vein vessel segmentation,
Z. Deng, W. Gao, Z. Gong, R. Gan, L. Chen, S. Zhang, and L. Ma, “A fundus image dataset for ai-based artery-vein vessel segmentation,” Scientific Data, vol. 12, no. 1, p. 1298, 2025
2025
-
[27]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly,et al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition, pp. 248–255, Ieee, 2009
2009
-
[29]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Automated analysis of retinal images for detection of referable diabetic retinopathy,
M. D. Abr `amoff, J. C. Folk, D. P. Han, J. D. Walker, D. F. Williams, S. R. Russell, P. Massin, B. Cochener, P. Gain, L. Tang,et al., “Automated analysis of retinal images for detection of referable diabetic retinopathy,” JAMA ophthalmology, vol. 131, no. 3, pp. 351–357, 2013
2013
-
[31]
Indian diabetic retinopathy image dataset (idrid): a database for diabetic retinopathy screening research,
P. Porwal, S. Pachade, R. Kamble, M. Kokare, G. Deshmukh, V . Sa- hasrabuddhe, and F. Meriaudeau, “Indian diabetic retinopathy image dataset (idrid): a database for diabetic retinopathy screening research,” Data, vol. 3, no. 3, p. 25, 2018
2018
-
[32]
Adam: Automatic detection challenge on age- related macular degeneration,
H. Fu, F. Li, J. I. Orlando, H. Bogunovi ´c, X. Sun, J. Liao, Y . Xu, S. Zhang, and X. Zhang, “Adam: Automatic detection challenge on age- related macular degeneration,” 2020
2020
-
[33]
Dataset: Origa dataset,
J. L. F. Yin, “Dataset: Origa dataset,” 2024
2024
-
[34]
Refuge challenge: A unified framework for evaluating automated methods for glaucoma assessment from fundus photographs,
J. I. Orlando, H. Fu, J. B. Breda, K. Van Keer, D. R. Bathula, A. Diaz- Pinto, R. Fang, P.-A. Heng, J. Kim, J. Lee,et al., “Refuge challenge: A unified framework for evaluating automated methods for glaucoma assessment from fundus photographs,”Medical image analysis, vol. 59, p. 101570, 2020
2020
-
[35]
Palm: Pathologic myopia challenge,
H. Fu, F. Li, J. I. Orlando, H. Bogunovi ´c, X. Sun, J. Liao, Y . Xu, S. Zhang, and X. Zhang, “Palm: Pathologic myopia challenge,” 2019
2019
-
[36]
International competition on ocular disease intelligent recognition.,
“International competition on ocular disease intelligent recognition.,” 2019
2019
-
[37]
Ridge-based vessel segmentation in color images of the retina,
J. Staal, M. Abramoff, M. Niemeijer, M. Viergever, and B. van Gin- neken, “Ridge-based vessel segmentation in color images of the retina,” IEEE Transactions on Medical Imaging, vol. 23, no. 4, pp. 501–509, 2004
2004
-
[38]
Teleophta: Machine learning and image processing methods for teleophthalmology,
E. Decenciere, G. Cazuguel, X. Zhang, G. Thibault, J.-C. Klein, F. Meyer, B. Marcotegui, G. Quellec, M. Lamard, R. Danno,et al., “Teleophta: Machine learning and image processing methods for teleophthalmology,”Irbm, vol. 34, no. 2, pp. 196–203, 2013
2013
-
[39]
A convnet for the 2020s,
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11976–11986, 2022
2022
-
[40]
Visualizing data using t-SNE,
L. van der Maaten and G. Hinton, “Visualizing data using t-SNE,” Journal of Machine Learning Research, vol. 9, no. 86, pp. 2579–2605, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.