Variational Test-time Optimization for Diffusion Synchronization
Pith reviewed 2026-06-27 04:21 UTC · model grok-4.3
The pith
Diffusion synchronization is derived as an optimal control problem that optimizes control variables during sampling to align multiple trajectories while staying close to the pretrained prior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that diffusion synchronization arises naturally from a variational optimal control formulation, in which control inputs are optimized at test time to drive multiple diffusion trajectories toward mutual coherence while remaining close to the original diffusion prior.
What carries the argument
The optimal control formulation that derives synchronization guidance by minimizing a cost balancing trajectory coherence against fidelity to the diffusion prior.
If this is right
- Synchronization no longer requires task-specific tailoring or heuristics.
- The same framework applies to diverse collaborative generation settings when combined with any strong pretrained diffusion model.
- Performance improves consistently across modalities and applications without retraining.
- A principled mathematical foundation replaces ad-hoc guidance mechanisms.
Where Pith is reading between the lines
- The control perspective may transfer to other sampling-based generative methods that currently rely on heuristic alignment.
- Test-time control optimization could be adapted to enforce additional domain constraints such as geometric consistency in 3D tasks.
- The derivation suggests that classical optimal-control techniques might yield further improvements in diffusion sampling efficiency.
Load-bearing premise
The derived optimal control problem can be solved efficiently at test time for arbitrary diffusion models and tasks without large computational cost or unintended deviation from the prior.
What would settle it
A controlled experiment on one of the three evaluated collaborative tasks showing no coherence gain or substantially higher runtime compared with prior heuristic synchronization methods would falsify the practical value of the control-based approach.
Figures












read the original abstract
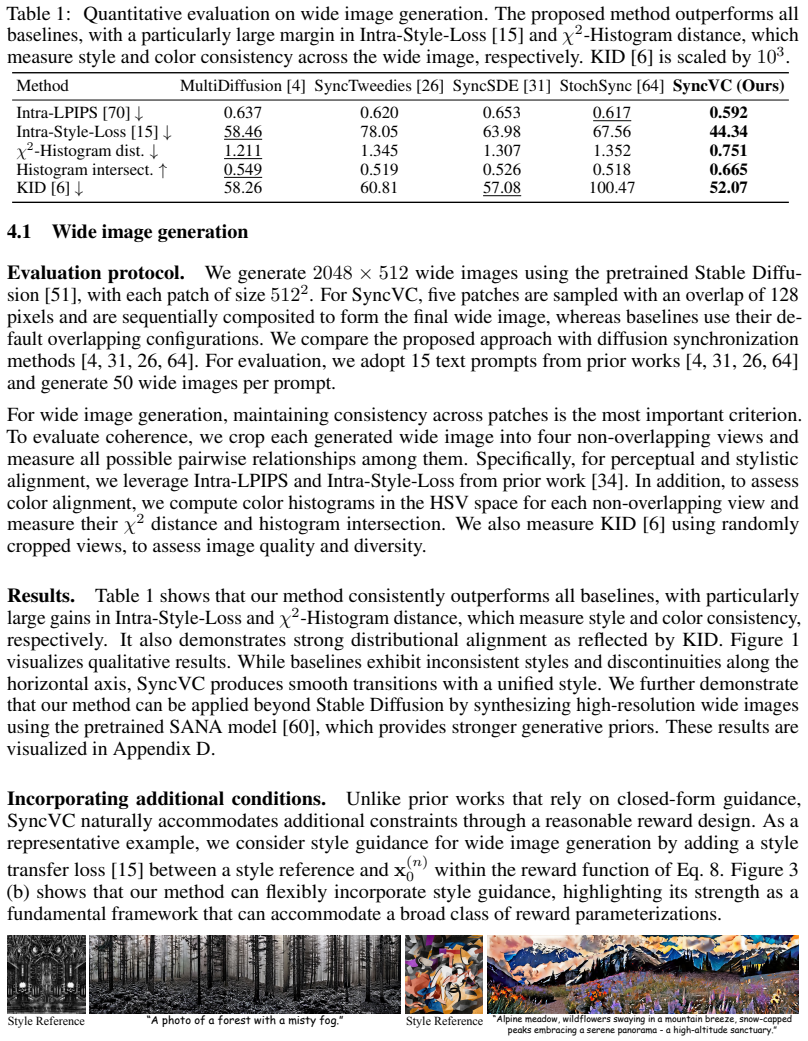
Collaborative generation, which coordinates multiple diffusion trajectories to extend the capabilities of pretrained priors, has emerged as a powerful paradigm for extending the applicability of diffusion models. Among existing approaches, diffusion synchronization provides a scenario-agnostic solution by introducing general guidance mechanisms. However, current synchronization approaches rely heavily on heuristics and still require task-specific tailoring, which limits their generalizability and performance. In this work, we mathematically derive a synchronization framework based on optimal control, providing a principled explanation of diffusion synchronization. During sampling, we optimize control variables to guide multiple trajectories toward coherent solutions while remaining close to the underlying diffusion prior. Our method operates entirely at test-time without additional training, thereby enabling broad applicability across diverse generation scenarios when combined with strong pretrained priors. We demonstrate consistent improvements over baselines on three representative collaborative generation tasks, covering a wide range of modalities and applications. Beyond performance gains, our work establishes a novel foundation for collaborative generation, opening a principled path toward extending pretrained generative models to new collaborative generation settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to mathematically derive a synchronization framework for diffusion models based on optimal control theory. During sampling, control variables are optimized to guide multiple diffusion trajectories toward coherent solutions while remaining close to the underlying diffusion prior. The approach operates entirely at test time with no additional training, enabling broad applicability across collaborative generation tasks when paired with pretrained priors, and reports consistent improvements over baselines on three representative tasks spanning modalities and applications.
Significance. If the optimal-control derivation holds and the test-time optimization proves stable and efficient, the work supplies a principled foundation for diffusion synchronization that reduces reliance on heuristics. The test-time-only nature and claimed generality across tasks are strengths, as is the explicit framing as a variational optimization problem that stays close to the diffusion prior.
minor comments (2)
- The abstract states improvements on three tasks but does not specify the quantitative metrics or effect sizes; the results section should include these details with error bars or statistical tests to support the 'consistent improvements' claim.
- Notation for the control variables and the variational objective should be introduced with explicit definitions early in the method section to improve readability for readers unfamiliar with optimal-control formulations in diffusion.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation of minor revision. The referee's summary accurately captures the core contributions of our work.
Circularity Check
Derivation is self-contained with no circular reductions
full rationale
The paper presents a mathematical derivation of an optimal-control-based synchronization framework for diffusion models, with control variables optimized at test time to align trajectories while staying close to the prior. The provided abstract and description contain no equations or steps that reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations. The claim of a 'principled explanation' is framed as an independent derivation rather than a renaming or ansatz imported from prior author work. No specific reduction (e.g., a prediction equivalent to an input fit) is exhibited. This is the expected outcome for a derivation paper whose central steps are not shown to collapse into their own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optimal control theory can be applied to guide diffusion sampling trajectories
Reference graph
Works this paper leans on
-
[1]
Deepfloyd if.https://github.com/deep-floyd/IF, 2023
DeepFloyd Lab at StabilityAI. Deepfloyd if.https://github.com/deep-floyd/IF, 2023
2023
-
[2]
V oronoi diagrams—a survey of a fundamental geometric data structure.ACM computing surveys (CSUR), 1991
Franz Aurenhammer. V oronoi diagrams—a survey of a fundamental geometric data structure.ACM computing surveys (CSUR), 1991
1991
-
[3]
Adaptive diffusion guidance via stochastic optimal control.AISTATS, 2026
Iskander Azangulov, Peter Potaptchik, Qinyu Li, Eddie Aamari, George Deligiannidis, and Judith Rousseau. Adaptive diffusion guidance via stochastic optimal control.AISTATS, 2026
2026
-
[4]
Multidiffusion: Fusing diffusion paths for controlled image generation.ICML, 2023
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. Multidiffusion: Fusing diffusion paths for controlled image generation.ICML, 2023
2023
-
[5]
An optimal control perspective on diffusion-based generative modeling.TMLR, 2024
Julius Berner, Lorenz Richter, and Karen Ullrich. An optimal control perspective on diffusion-based generative modeling.TMLR, 2024
2024
-
[6]
Demystifying mmd gans
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans. ICLR, 2018
2018
-
[7]
L-magic: language model assisted generation of images with coherence
Zhipeng Cai, Matthias Mueller, Reiner Birkl, Diana Wofk, Shao-Yen Tseng, Junda Cheng, Gabriela Ben-Melech Stan, Vasudev Lai, and Michael Paulitsch. L-magic: language model assisted generation of images with coherence. InCVPR, 2024
2024
-
[8]
Text2tex: Text-driven texture synthesis via diffusion models
Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, and Matthias Nießner. Text2tex: Text-driven texture synthesis via diffusion models. InICCV, 2023
2023
-
[9]
Susskind, and Shuangfei Zhai
Tianrong Chen, Jiatao Gu, Laurent Dinh, Evangelos Theodorou, Joshua M. Susskind, and Shuangfei Zhai. Generative modeling with phase stochastic bridge. InICLR, 2024. 10
2024
-
[10]
Flexible motion in-betweening with diffusion models
Setareh Cohan, Guy Tevet, Daniele Reda, Xue Bin Peng, and Michiel van de Panne. Flexible motion in-betweening with diffusion models. InSIGGRAPH, 2024
2024
-
[11]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. arXiv:2212.08051, 2022
-
[12]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat GANs on image synthesis. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,NeurIPS, 2021
2021
-
[13]
Flexpainter: Flexible and multi-view consistent texture generation
Yan Dongyu, Leyi Wu, Jiantao Lin, Luozhou Wang, Tianshuo Xu, Zhifei Chen, Zhen Yang, Lie Xu, Shunsi Zhang, and Yingcong Chen. Flexpainter: Flexible and multi-view consistent texture generation. arXiv:2506.02620, 2025
-
[14]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InICML, 2024
2024
-
[15]
Image style transfer using convolutional neural networks
Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. InCVPR, 2016
2016
-
[16]
Visual anagrams: Generating multi-view optical illusions with diffusion models
Daniel Geng, Inbum Park, and Andrew Owens. Visual anagrams: Generating multi-view optical illusions with diffusion models. InCVPR, 2024
2024
-
[17]
Geyfman, F
D. Geyfman, F. Draxler, J. N. Groeneveld, H. Lee, T. Karaletsos, and S. Mandt. Calibrated test-time guidance for bayesian inference. InICML, 2026
2026
-
[18]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.NIPS, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.NIPS, 2017
2017
-
[19]
Denoising diffusion probabilistic models.NeurIPS, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.NeurIPS, 2020
2020
-
[20]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS Workshop on Deep Generative Models and Downstream Applications, 2021
2021
-
[21]
Video diffusion models.NeurIPS, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.NeurIPS, 2022
2022
-
[22]
Symbolic music generation with non-differentiable rule guided diffusion.ICML, 2024
Yujia Huang, Adishree Ghatare, Yuanzhe Liu, Ziniu Hu, Qinsheng Zhang, Chandramouli S Sastry, Siddharth Gururani, Sageev Oore, and Yisong Yue. Symbolic music generation with non-differentiable rule guided diffusion.ICML, 2024
2024
-
[23]
Stochastic optimal control theory.ICML, 2008
HJ Kappen. Stochastic optimal control theory.ICML, 2008
2008
-
[24]
Guided motion diffusion for controllable human motion synthesis
Korrawe Karunratanakul, Konpat Preechakul, Supasorn Suwajanakorn, and Siyu Tang. Guided motion diffusion for controllable human motion synthesis. InICCV, 2023
2023
-
[25]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InICCV, 2021
2021
-
[26]
Synctweedies: A general generative framework based on synchronized diffusions.NeurIPS, 2024
Jaihoon Kim, Juil Koo, Kyeongmin Yeo, and Minhyuk Sung. Synctweedies: A general generative framework based on synchronized diffusions.NeurIPS, 2024
2024
-
[27]
Adam: A method for stochastic optimization.ICLR, 2015
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.ICLR, 2015
2015
-
[28]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[29]
Modular primitives for high-performance differentiable rendering.ACM TOG, 2020
Samuli Laine, Janne Hellsten, Tero Karras, Yeongho Seol, Jaakko Lehtinen, and Timo Aila. Modular primitives for high-performance differentiable rendering.ACM TOG, 2020
2020
-
[30]
D. Le, T. Pham, S. Lee, C. Clark, A. Kembhavi, S. Mandt, R. Krishna, and J. Lu. One diffusion to generate them all. InCVPR, 2025
2025
-
[31]
Syncsde: A probabilistic framework for diffusion synchronization
Hyunjun Lee, Hyunsoo Lee, and Sookwan Han. Syncsde: A probabilistic framework for diffusion synchronization. InCVPR, 2025
2025
-
[32]
Conditional score guidance for text-driven image-to-image translation.NeurIPS, 2023
Hyunsoo Lee, Minsoo Kang, and Bohyung Han. Conditional score guidance for text-driven image-to-image translation.NeurIPS, 2023. 11
2023
-
[33]
Grid diffusion models for text-to-video generation
Taegyeong Lee, Soyeong Kwon, and Taehwan Kim. Grid diffusion models for text-to-video generation. In CVPR, 2024
2024
-
[34]
Syncdiffusion: Coherent montage via synchronized joint diffusions.NeurIPS, 2023
Yuseung Lee, Kunho Kim, Hyunjin Kim, and Minhyuk Sung. Syncdiffusion: Coherent montage via synchronized joint diffusions.NeurIPS, 2023
2023
-
[35]
Solving inverse problems via diffusion optimal control.NeurIPS, 2024
Henry Li and Marcus Pereira. Solving inverse problems via diffusion optimal control.NeurIPS, 2024
2024
-
[36]
Flow matching for generative modeling.ICLR, 2023
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.ICLR, 2023
2023
-
[37]
Audioldm: Text-to-audio generation with latent diffusion models.ICML, 2023
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audioldm: Text-to-audio generation with latent diffusion models.ICML, 2023
2023
-
[38]
Flashaudio: Rectified flow for fast and high-fidelity text-to-audio generation
Huadai Liu, Jialei Wang, Rongjie Huang, Yang Liu, Heng Lu, Zhou Zhao, and Wei Xue. Flashaudio: Rectified flow for fast and high-fidelity text-to-audio generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, 2025
2025
-
[39]
Flow straight and fast: Learning to generate and transfer data with rectified flow.ICLR, 2023
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.ICLR, 2023
2023
-
[40]
Text-guided texturing by synchronized multi-view diffusion.SIGGRAPH Asia, 2024
Yuxin Liu, Minshan Xie, Hanyuan Liu, and Tien-Tsin Wong. Text-guided texturing by synchronized multi-view diffusion.SIGGRAPH Asia, 2024
2024
-
[41]
Pandey and S
K. Pandey and S. Mandt. A complete recipe for diffusion generative models. InICCV, 2023
2023
-
[42]
Pandey, R
K. Pandey, R. Yang, and S. Mandt. Fast samplers for inverse problems in iterative refinement models. In NeurIPS, 2024
2024
-
[43]
Varia- tional control for guidance in diffusion models.ICML, 2025
Kushagra Pandey, Farrin Marouf Sofian, Felix Draxler, Theofanis Karaletsos, and Stephan Mandt. Varia- tional control for guidance in diffusion models.ICML, 2025
2025
-
[44]
Pytorch: An imperative style, high-performance deep learning library.NeurIPS, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.NeurIPS, 2019
2019
-
[45]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. In ICLR, 2024
2024
-
[46]
Dreamfusion: Text-to-3d using 2d diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. ICLR, 2023
2023
-
[47]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021
2021
-
[48]
Accelerating 3D Deep Learning with PyTorch3D
Nikhila Ravi, Jeremy Reizenstein, David Novotny, Taylor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. Accelerating 3d deep learning with pytorch3d.arXiv:2007.08501, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[49]
Texture: Text-guided texturing of 3d shapes
Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, and Daniel Cohen-Or. Texture: Text-guided texturing of 3d shapes. InSIGGRAPH, 2023
2023
-
[50]
An empirical bayes approach to statistics.Breakthroughs in Statistics: F oundations and basic theory, 1992
Herbert E Robbins. An empirical bayes approach to statistics.Breakthroughs in Statistics: F oundations and basic theory, 1992
1992
-
[51]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[52]
RB-modulation: Training-free stylization using reference-based modulation
Litu Rout, Yujia Chen, Nataniel Ruiz, Abhishek Kumar, Constantine Caramanis, Sanjay Shakkottai, and Wen-Sheng Chu. RB-modulation: Training-free stylization using reference-based modulation. InICLR, 2025
2025
-
[53]
Photorealistic text-to- image diffusion models with deep language understanding.NeurIPS, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to- image diffusion models with deep language understanding.NeurIPS, 2022
2022
-
[54]
Very deep convolutional networks for large-scale image recogni- tion.ICLR, 2015
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recogni- tion.ICLR, 2015. 12
2015
-
[55]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InICML, 2015
2015
-
[56]
Denoising diffusion implicit models.ICLR, 2021
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.ICLR, 2021
2021
-
[57]
Score-based generative modeling through stochastic differential equations.ICLR, 2021
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.ICLR, 2021
2021
-
[58]
MVDiffusion: Enabling holistic multi-view image generation with correspondence-aware diffusion
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, and Yasutaka Furukawa. MVDiffusion: Enabling holistic multi-view image generation with correspondence-aware diffusion. InNeurIPS, 2023
2023
-
[59]
Human motion diffusion model.ICLR, 2023
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion diffusion model.ICLR, 2023
2023
-
[60]
SANA: Efficient high-resolution text-to-image synthesis with linear diffusion transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, and Song Han. SANA: Efficient high-resolution text-to-image synthesis with linear diffusion transformers. InICLR, 2025
2025
-
[61]
Diffusion-based visual anagram as multi-task learning
Zhiyuan Xu, Yinhe Chen, Huan-ang Gao, Weiyan Zhao, Guiyu Zhang, and Hao Zhao. Diffusion-based visual anagram as multi-task learning. InWACV, 2025
2025
-
[62]
R. Yang, P. Srivastava, and S. Mandt. Diffusion probabilistic modeling for video generation.Entropy, 2023
2023
-
[63]
Cogvideox: Text-to-video diffusion models with an expert transformer.ICLR, 2025
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.ICLR, 2025
2025
-
[64]
Stochsync: Stochastic diffusion synchronization for image generation in arbitrary spaces.ICLR, 2025
Kyeongmin Yeo, Jaihoon Kim, and Minhyuk Sung. Stochsync: Stochastic diffusion synchronization for image generation in arbitrary spaces.ICLR, 2025
2025
-
[65]
Paint-it: Text-to-texture synthesis via deep convolu- tional texture map optimization and physically-based rendering
Kim Youwang, Tae-Hyun Oh, and Gerard Pons-Moll. Paint-it: Text-to-texture synthesis via deep convolu- tional texture map optimization and physically-based rendering. InCVPR, 2024
2024
-
[66]
Paint3d: Paint anything 3d with lighting-less texture diffusion models
Xianfang Zeng, Xin Chen, Zhongqi Qi, Wen Liu, Zibo Zhao, Zhibin Wang, Bin Fu, Yong Liu, and Gang Yu. Paint3d: Paint anything 3d with lighting-less texture diffusion models. InCVPR, 2024
2024
-
[67]
Taming stable diffusion for text to 360 panorama image generation
Cheng Zhang, Qianyi Wu, Camilo Cruz Gambardella, Xiaoshui Huang, Dinh Phung, Wanli Ouyang, and Jianfei Cai. Taming stable diffusion for text to 360 panorama image generation. InCVPR, 2024
2024
-
[68]
Texpainter: Generative mesh texturing with multi-view consistency
Hongkun Zhang, Zherong Pan, Congyi Zhang, Lifeng Zhu, and Xifeng Gao. Texpainter: Generative mesh texturing with multi-view consistency. InSIGGRAPH, 2024
2024
-
[69]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InICCV, 2023
2023
-
[70]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
-
[71]
An overview of multi-task learning.National Science Review, 2018
Yu Zhang and Qiang Yang. An overview of multi-task learning.National Science Review, 2018
2018
-
[72]
A photo of a forest with a misty fog
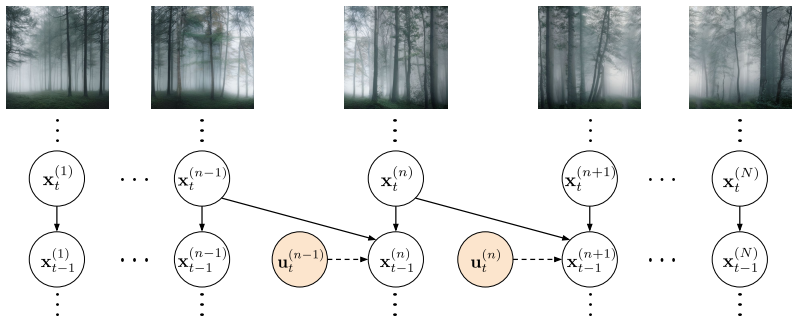
Yu Zhang and Qiang Yang. A survey on multi-task learning.IEEE transactions on knowledge and data engineering, 2021. 13 A Derivation of the ELBO (Eq. 5) LetU:={u (n−1) t }N, T n=2, t=1. The joint generative model factorizes as p(x(1:N) 0:T ,y) =p(y|x (1:N) 0 ) NY n=1 p(x(n) T ) NY n=1 TY t=1 pϕ(x(n) t−1 |x (n) t ),(14) with logp(y|x (1:N) 0 ) =r(y,X)−logZ(...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.