AIChilles: Automatically Uncovering Hidden Weaknesses in AI-Evolved Systems
Pith reviewed 2026-06-27 04:22 UTC · model grok-4.3
The pith
A tool searches for workloads where AI-evolved programs regress relative to their baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
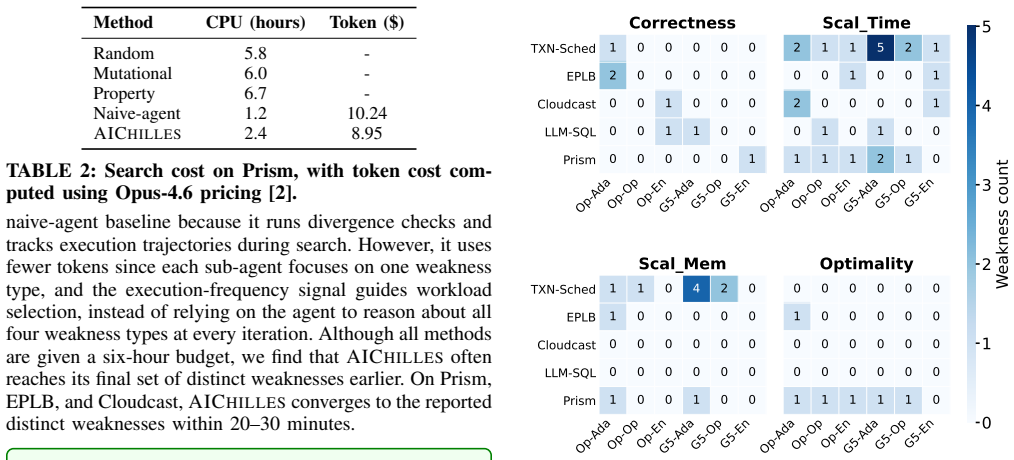
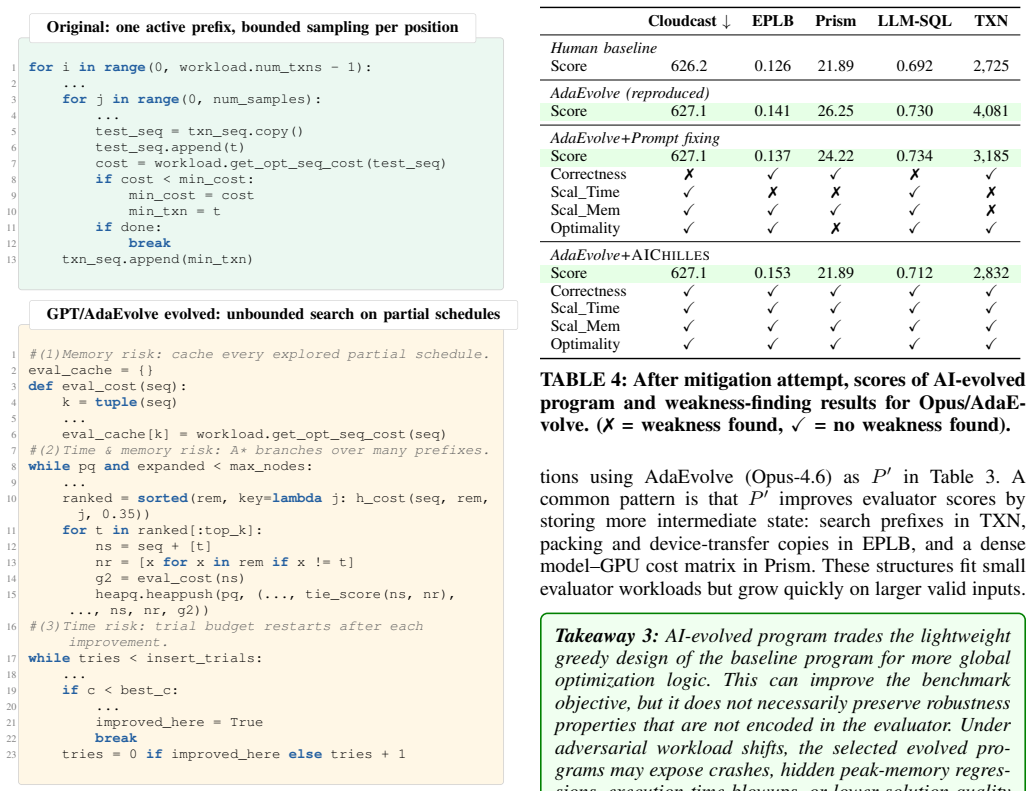
AIChilles takes as input a baseline program P and an AI-evolved program P', then searches for valid workloads where P' regresses relative to P in correctness, runtime, memory usage, or output quality. To handle diversity across applications, weakness types, and bugs, it combines deterministic workload-parameter extraction, agent-based constraint inference, differential oracles, and code-frequency coverage. Across five system applications and thirty AI-evolved programs, the method identifies forty-nine distinct hidden weaknesses. Explicitly including the search in the AI-driven development lifecycle mitigates several of these weaknesses.
What carries the argument
The combination of deterministic workload-parameter extraction, agent-based constraint inference, differential oracles, and code-frequency coverage, which together locate diverse, valid regression workloads.
If this is right
- Explicitly including the search step in the AI-driven development lifecycle mitigates several weaknesses.
- AI-evolved programs can still exhibit scalability regressions or correctness failures on certain workloads even when average scores improve.
- Automated mechanisms become necessary to check AI-generated code given the speed and volume at which it is produced.
Where Pith is reading between the lines
- Standard benchmark evaluations used to judge AI system evolution may overlook regressions that appear only on specific inputs.
- The same regression-search pattern could apply to other forms of automatically generated code outside systems applications.
- Teams building AI code agents may eventually treat systematic regression search as a required validation stage.
Load-bearing premise
The assumption that deterministic workload extraction, agent-based constraint inference, differential oracles, and code-frequency coverage will reliably surface valid, diverse, and non-spurious regressions without extensive manual validation or per-application tuning.
What would settle it
Applying the method to a collection of AI-evolved programs and finding that the reported weaknesses are mostly invalid on manual review, or that it returns no weaknesses in a collection known to contain regressions.
Figures


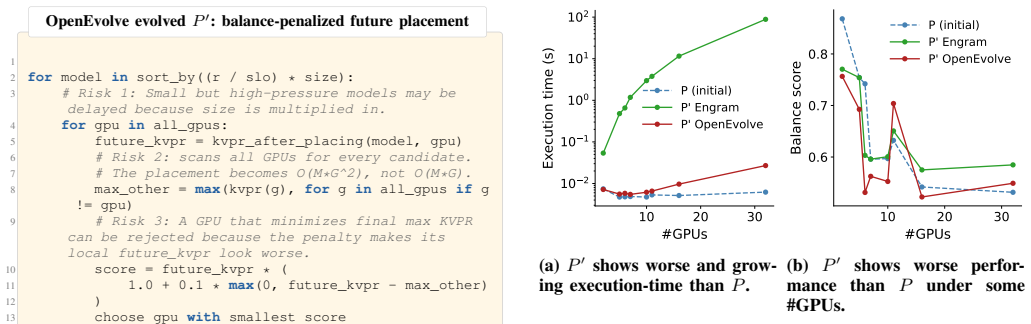
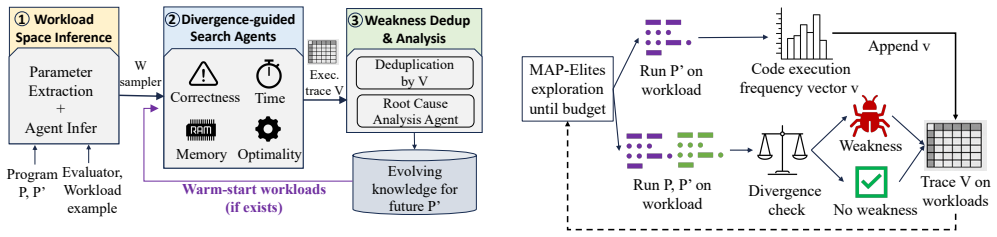

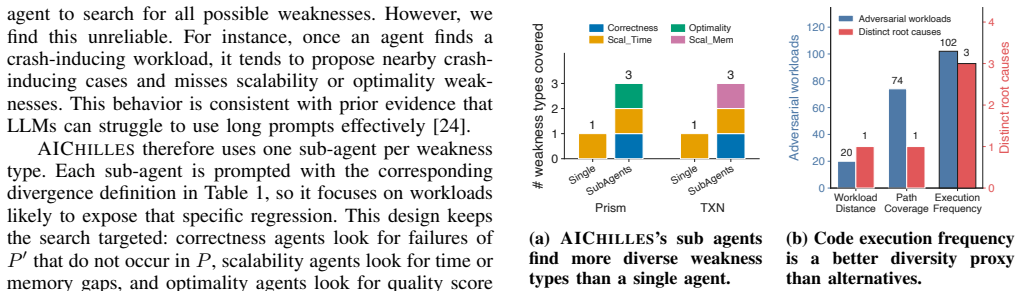

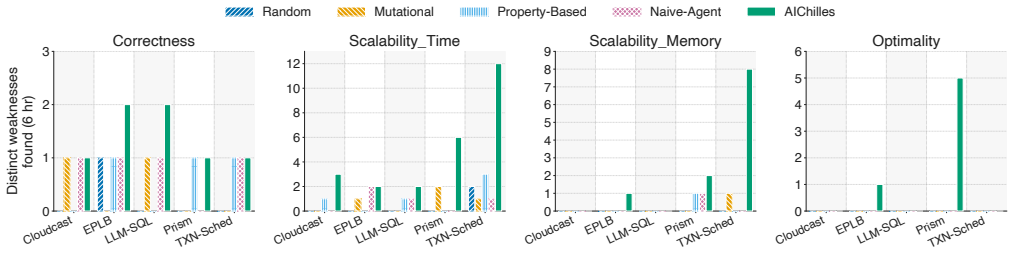

read the original abstract
The computer systems community has recently seen growing interest in AI-driven system evolution, where AI agents iteratively rewrite systems. Frameworks such as AdaEvolve and Engram report 12-60% score improvements over human-designed algorithms. While these results are promising, there are practical concerns if these AI-evolved programs can perform worse on unseen workloads and exhibit scalability regressions. Given the speed and scale of AI-generated code, we need automated mechanisms to uncover such identify hidden weaknesses in AI-evolved systems programs. To this end, we develop AIChilles that takes as input a baseline program $P$ and an AI-evolved program $P'$, AIChilles searches for valid workloads where $P'$ regresses relative to $P$ in correctness, runtime, memory usage, or output quality. To tackle the diversity in system applications, weakness types and potential bugs, AIChilles combines deterministic workload-parameter extraction, agent-based constraint inference, differential oracles, and code-frequency coverage to discover diverse failures. Across five system applications and 30 AI-evolved programs, AIChilles finds 49 distinct hidden weaknesses. We also show that explicitly including AIChilles in the AI-driven development lifecycle can mitigate several of these weaknesses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AIChilles, an automated tool that takes a baseline program P and an AI-evolved program P' and searches for valid workloads on which P' exhibits regressions relative to P in correctness, runtime, memory usage, or output quality. It combines deterministic workload-parameter extraction, agent-based constraint inference, differential oracles, and code-frequency coverage to handle diversity across applications. The central empirical result is the discovery of 49 distinct hidden weaknesses across five system applications and 30 AI-evolved programs; the paper also claims that explicitly including AIChilles in the AI-driven development lifecycle can mitigate several weaknesses.
Significance. If the 49 reported weaknesses can be shown to be valid, non-spurious regressions on workloads satisfying the original specification, the work would be significant for the growing area of AI-driven system evolution. It directly addresses the practical risk that AI-evolved programs (which report 12-60% gains) may regress on unseen workloads, and the proposed integration into the development loop offers a concrete path to improved reliability.
major comments (2)
- [Evaluation/Results] Evaluation/Results section: The headline claim of 49 distinct hidden weaknesses is not accompanied by quantitative validation of workload realism, false-positive rates, number of discarded candidates, or independent verification that agent-inferred constraints produce legal inputs and that oracle differences reflect genuine defects rather than oracle bugs or constraint violations. This directly undermines the central empirical result.
- [Methodology] Methodology section on agent-based constraint inference and differential oracles: No details are provided on how the correctness of these LLM-driven components is ensured or measured (e.g., via manual audits, discarded-candidate statistics, or cross-checks against domain-specific oracles), yet the pipeline's ability to surface valid regressions depends entirely on them.
minor comments (1)
- [Abstract] Abstract contains a grammatical error ('uncover such identify hidden weaknesses').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validation of the empirical claims and the LLM-driven components. We address each major comment below and will revise the manuscript to incorporate additional details and quantitative evidence.
read point-by-point responses
-
Referee: [Evaluation/Results] Evaluation/Results section: The headline claim of 49 distinct hidden weaknesses is not accompanied by quantitative validation of workload realism, false-positive rates, number of discarded candidates, or independent verification that agent-inferred constraints produce legal inputs and that oracle differences reflect genuine defects rather than oracle bugs or constraint violations. This directly undermines the central empirical result.
Authors: We agree that the current manuscript lacks explicit quantitative validation metrics for workload realism, false-positive rates, and discarded candidates. The 49 weaknesses were surfaced via differential oracles that compare P' against P on workloads satisfying the extracted constraints, with distinctness defined by unique failure signatures across applications. However, no false-positive statistics or manual verification counts are reported. In revision we will add a dedicated subsection reporting: total candidate workloads generated per application, number and reasons for discards (constraint violation or oracle inconsistency), and results of manual audit on a 20% random sample of the 49 weaknesses confirming they are genuine regressions on legal inputs. This directly addresses the concern. revision: yes
-
Referee: [Methodology] Methodology section on agent-based constraint inference and differential oracles: No details are provided on how the correctness of these LLM-driven components is ensured or measured (e.g., via manual audits, discarded-candidate statistics, or cross-checks against domain-specific oracles), yet the pipeline's ability to surface valid regressions depends entirely on them.
Authors: The manuscript describes the agent-based constraint inference and differential oracles at a high level but does not detail correctness assurance mechanisms. We will expand the Methodology section to include: the specific prompt templates and iterative refinement strategy used by the agent, any self-consistency or cross-check steps against domain oracles, and statistics on inferences that were manually reviewed or discarded during pipeline execution. These additions will clarify how the components were validated in practice. revision: yes
Circularity Check
No circularity: empirical tool description with no derivations or fitted predictions
full rationale
The paper presents an empirical system (AIChilles) for discovering weaknesses in AI-evolved programs via workload generation and differential testing. It reports concrete counts (49 weaknesses across 30 programs) from running the tool, without any equations, first-principles derivations, parameter fitting, or predictions that reduce to inputs by construction. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify core claims. The evaluation is self-contained against external benchmarks (the 30 AI-evolved programs), satisfying the criteria for a non-circular empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-defining systems
ANDERSON, T., MAHAJAN, R., PETER, S.,ANDZETTLEMOYER, L. Self-defining systems
-
[2]
Introducing claude opus 4.6
ANTHROPIC. Introducing claude opus 4.6. https://www.anthropic. com/news/claude-opus-4-6, 2026
2026
-
[3]
Nautilus: Fishing for deep bugs with grammars
ASCHERMANN, C., FRASSETTO, T., HOLZ, T., JAUERNIG, P., SADEGHI, A.-R.,ANDTEUCHERT, D. Nautilus: Fishing for deep bugs with grammars. InNDSS(2019), vol. 19, p. 337
2019
-
[4]
Fudge: fuzz driver generation at scale
BABI ´C, D., BUCUR, S., CHEN, Y., IVAN ˇCI ´C, F., KING, T., KUSANO, M., LEMIEUX, C., SZEKERES, L.,ANDWANG, W. Fudge: fuzz driver generation at scale. InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering(New York, NY , USA, 2019), ESEC/FSE 2019, Association fo...
2019
-
[5]
Klee: unassisted and automatic generation of high-coverage tests for complex systems programs
CADAR, C., DUNBAR, D.,ANDENGLER, D. Klee: unassisted and automatic generation of high-coverage tests for complex systems programs. InProceedings of the 8th USENIX Conference on Op- erating Systems Design and Implementation(USA, 2008), OSDI’08, USENIX Association, p. 209–224
2008
-
[6]
M., DILL, D
CADAR, C., GANESH, V., PAWLOWSKI, P. M., DILL, D. L.,AND ENGLER, D. R. Exe: Automatically generating inputs of death.ACM Trans. Inf. Syst. Secur. 12, 2 (Dec. 2008)
2008
-
[7]
E., SEN, K., ZAHARIA, M., ET AL
CEMRI, M., AGRAWAL, S., GUPTA, A., LIU, S., CHENG, A., MANG, Q., NAREN, A., ERDOGAN, L. E., SEN, K., ZAHARIA, M., ET AL. Adaevolve: Adaptive llm driven zeroth-order optimization. arXiv preprint arXiv:2602.20133(2026)
arXiv 2026
-
[8]
Towards optimal transaction schedul- ing.Proceedings of the VLDB Endowment 17, 11 (2024), 2694–2707
CHENG, A., KABCENELL, A., CHAN, J., SHI, X., BAILIS, P., CROOKS, N.,ANDSTOICA, I. Towards optimal transaction schedul- ing.Proceedings of the VLDB Endowment 17, 11 (2024), 2694–2707
2024
-
[9]
Let the barbarians in: How ai can accelerate systems performance research
CHENG, A., LIU, S., PAN, M., LI, Z., AGARWAL, S., CEMRI, M., WANG, B., KRENTSEL, A., XIA, T., PARK, J.,ET AL. Let the barbarians in: How ai can accelerate systems performance research. arXiv preprint arXiv:2512.14806(2025)
arXiv 2025
-
[10]
Barbarians at the gate: How ai is upending systems research.arXiv preprint arXiv:2510.06189(2025)
CHENG, A., LIU, S., PAN, M., LI, Z., WANG, B., KRENTSEL, A., XIA, T., CEMRI, M., PARK, J., YANG, S.,ET AL. Barbarians at the gate: How ai is upending systems research.arXiv preprint arXiv:2510.06189(2025)
arXiv 2025
-
[11]
Ai-driven research for databases
CHENG, A., NG, H., KABCENELL, A., BAILIS, P., ZAHARIA, M., MA, L., SHI, X.,ANDSTOICA, I. Ai-driven research for databases. arXiv preprint arXiv:2604.06566(2026)
Pith/arXiv arXiv 2026
-
[12]
Quickcheck: a lightweight tool for random testing of haskell programs
CLAESSEN, K.,ANDHUGHES, J. Quickcheck: a lightweight tool for random testing of haskell programs. InProceedings of the fifth ACM SIGPLAN international conference on Functional programming (2000), pp. 268–279
2000
-
[13]
Expert Parallelism Load Balancer (EPLB)
DEEPSEEKAI. Expert Parallelism Load Balancer (EPLB). https: //github.com/deepseek-ai/eplb, 2024
2024
-
[14]
{AFL++}: Combining incremental steps of fuzzing research
FIORALDI, A., MAIER, D., EISSFELDT, H.,ANDHEUSE, M. {AFL++}: Combining incremental steps of fuzzing research. In14th USENIX workshop on offensive technologies (WOOT 20)(2020)
2020
-
[15]
C., ZHANG, D.,ANDBALZAROTTI, D
FIORALDI, A., MAIER, D. C., ZHANG, D.,ANDBALZAROTTI, D. Libafl: A framework to build modular and reusable fuzzers. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security(2022), pp. 1051–1065
2022
-
[16]
Skydiscover: A flexible framework for ai-driven scien- tific and algorithmic discovery
GITHUB. Skydiscover: A flexible framework for ai-driven scien- tific and algorithmic discovery. https://github.com/skydiscover-ai/ skydiscover, 2026
2026
-
[17]
Graphfuzz: Library api fuzzing with lifetime-aware dataflow graphs
GREEN, H.,ANDAVGERINOS, T. Graphfuzz: Library api fuzzing with lifetime-aware dataflow graphs. InProceedings of the 44th International Conference on Software Engineering(2022), pp. 1070– 1081
2022
-
[18]
HAMADANIAN, P., KARIMI, P., NASR-ESFAHANY, A., NOOR- BAKHSH, K., CHANDLER, J., PARANDEHGHEIBI, A., ALIZADEH, M.,ANDBALAKRISHNAN, H. Glia: A human-inspired ai for automated systems design and optimization.arXiv preprint arXiv:2510.27176(2025)
Pith/arXiv arXiv 2025
-
[19]
Hypothesis: a property-based testing library for python
HYPOTHESIS. Hypothesis: a property-based testing library for python. https://github.com/HypothesisWorks/hypothesis/, 2025
2025
-
[20]
KARIMI, P., NOORBAKHSH, K., ALIZADEH, M.,ANDBALAKRISH- NAN, H. Improving coherence and persistence in agentic ai for system optimization.arXiv preprint arXiv:2603.21321(2026)
arXiv 2026
-
[21]
H., GONZALEZ, J., ZHANG, H.,ANDSTOICA, I
KWON, W., LI, Z., ZHUANG, S., SHENG, Y., ZHENG, L., YU, C. H., GONZALEZ, J., ZHANG, H.,ANDSTOICA, I. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles (2023), pp. 611–626
2023
-
[22]
Perffuzz: Automatically generating pathological inputs
LEMIEUX, C., PADHYE, R., SEN, K.,ANDSONG, D. Perffuzz: Automatically generating pathological inputs. InProceedings of the 27th ACM SIGSOFT international symposium on software testing and analysis(2018), pp. 254–265
2018
-
[23]
Spider: Fuzzing for stateful performance issues in the onos software-defined network controller
LI, A., PADHYE, R.,ANDSEKAR, V. Spider: Fuzzing for stateful performance issues in the onos software-defined network controller. In2025 IEEE Conference on Software Testing, Verification and Validation (ICST)(2025), IEEE, pp. 1–12
2025
-
[24]
F., LIN, K., HEWITT, J., PARANJAPE, A., BEVILACQUA, M., PETRONI, F.,ANDLIANG, P
LIU, N. F., LIN, K., HEWITT, J., PARANJAPE, A., BEVILACQUA, M., PETRONI, F.,ANDLIANG, P. Lost in the middle: How language models use long contexts.CoRR abs/2307.03172(2023)
Pith/arXiv arXiv 2023
- [25]
-
[26]
G., PATEL, L., CAO, S., MO, X., STOICA, I., GONZALEZ, J
LIU, S., BISWAL, A., KAMSETTY, A., CHENG, A., SCHROEDER, L. G., PATEL, L., CAO, S., MO, X., STOICA, I., GONZALEZ, J. E., ET AL. Optimizing llm queries in relational data analytics workloads. Proceedings of Machine Learning and Systems 7(2025)
2025
-
[27]
P., FREDRIKSEN, L.,ANDSO, B
MILLER, B. P., FREDRIKSEN, L.,ANDSO, B. An empirical study of the reliability of unix utilities.Communications of the ACM 33, 12 (1990), 32–44
1990
-
[28]
Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909(2015)
MOURET, J.-B.,ANDCLUNE, J. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909(2015)
Pith/arXiv arXiv 2015
-
[29]
L.,ANDGRUNSKE, L
NGUYEN, H. L.,ANDGRUNSKE, L. Bedivfuzz: integrating behav- ioral diversity into generator-based fuzzing. InProceedings of the 44th International Conference on Software Engineering(New York, NY , USA, 2022), ICSE ’22, Association for Computing Machinery, p. 249–261
2022
-
[30]
Z., SHIROBOKOV, S., KOZLOVSKII, B., RUIZ, F
NOVIKOV, A., V ˜U, N., EISENBERGER, M., DUPONT, E., HUANG, P.-S., WAGNER, A. Z., SHIROBOKOV, S., KOZLOVSKII, B., RUIZ, F. J., MEHRABIAN, A.,ET AL. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131 (2025)
Pith/arXiv arXiv 2025
-
[31]
Introducing gpt-5
OPENAI. Introducing gpt-5. https://openai.com/index/ introducing-gpt-5/, 2025
2025
-
[32]
D.,ANDJANA, S
PETSIOS, T., ZHAO, J., KEROMYTIS, A. D.,ANDJANA, S. Slow- fuzz: Automated domain-independent detection of algorithmic com- plexity vulnerabilities. InProceedings of the 2017 ACM SIGSAC con- ference on computer and communications security(2017), pp. 2155– 2168
2017
-
[33]
How BASF Manages Thousands of Supply Chain Decisions with AlphaEvolve’s Agentic Algorithms
PRIESE, B.,ANDNAWALGARIA, A. How BASF Manages Thousands of Supply Chain Decisions with AlphaEvolve’s Agentic Algorithms. https://cloud.google.com/blog/products/ai-machine-learning/ how-basf-manages-thousands-of-supply-chain-decisions-with-alphaevolve, 2026
2026
-
[34]
OpenEvolve
SHARMA, ASANKHAYA. OpenEvolve. https://github.com/ algorithmicsuperintelligence/openevolve, 2025. 14
2025
-
[35]
Cocoevolve: What if a coding agent could optimize your ai systems? https://www.snowflake.com/en/blog/engineering/ optimize-snowflake-ai-systems-cocoevolve/, 2026
SNOWFLAKE. Cocoevolve: What if a coding agent could optimize your ai systems? https://www.snowflake.com/en/blog/engineering/ optimize-snowflake-ai-systems-cocoevolve/, 2026
2026
-
[36]
Gramatron: Effective grammar- aware fuzzing
SRIVASTAVA, P.,ANDPAYER, M. Gramatron: Effective grammar- aware fuzzing. InProceedings of the 30th acm sigsoft international symposium on software testing and analysis(2021), pp. 244–256
2021
-
[37]
Not all coverage measurements are equal: Fuzzing by coverage accounting for input prioritization
WANG, Y., JIA, X., LIU, Y., ZENG, K., BAO, T., WU, D.,ANDSU, P. Not all coverage measurements are equal: Fuzzing by coverage accounting for input prioritization. InNDSS(2020)
2020
-
[38]
E., LIU, V.,ANDSTOICA, I
WOODERS, S., LIU, S., JAIN, P., MO, X., GONZALEZ, J. E., LIU, V.,ANDSTOICA, I. Cloudcast:{High-Throughput},{Cost-Aware} overlay multicast in the cloud. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24)(2024), pp. 281–296
2024
-
[39]
YU, S., XING, J., QIAO, Y., MA, M., LI, Y., WANG, Y., YANG, S., XIE, Z., CAO, S., BAO, K.,ET AL. Prism: Unleashing gpu sharing for cost-efficient multi-llm serving.arXiv preprint arXiv:2505.04021 (2025)
Pith/arXiv arXiv 2025
-
[40]
American fuzzy lop-whitepaper.Retrieved September 1(2016), 2022
ZALEWSKI, M. American fuzzy lop-whitepaper.Retrieved September 1(2016), 2022
2016
-
[41]
A., SMYTZEK, M.,ANDZELLER, A
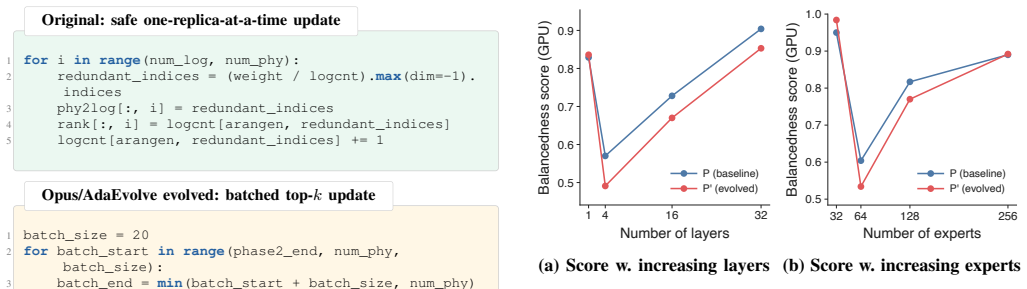
ZAMUDIOAMAYA, J. A., SMYTZEK, M.,ANDZELLER, A. Fan- dango: evolving language-based testing.Proceedings of the ACM on Software Engineering 2, ISSTA (2025), 894–916. 15 TABLE 5: Representative changes made by AI-evolved TXN schedulers. AdaEvolve replaces the original greedy sampler with a global continuous optimizer, while Engram keeps the greedy structure ...
2025
-
[42]
run_workload.pyis a fixed per-app harness
Appendix AICHILLESPrompt Details Prompt 1: Workload Space Inference You are analyzing an ADSO application to infer the full input space for adversarial bug discovery. run_workload.pyis a fixed per-app harness. •This file is fixed andcannot be changed. •It defines the workload dictionary schema. •Parameter names ingrammar_workloadmust exactly match the key...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.