GRACE-DS: a Guarded Reward-guided Agent Correction Environment in Data Science
Pith reviewed 2026-06-27 03:39 UTC · model grok-4.3
The pith
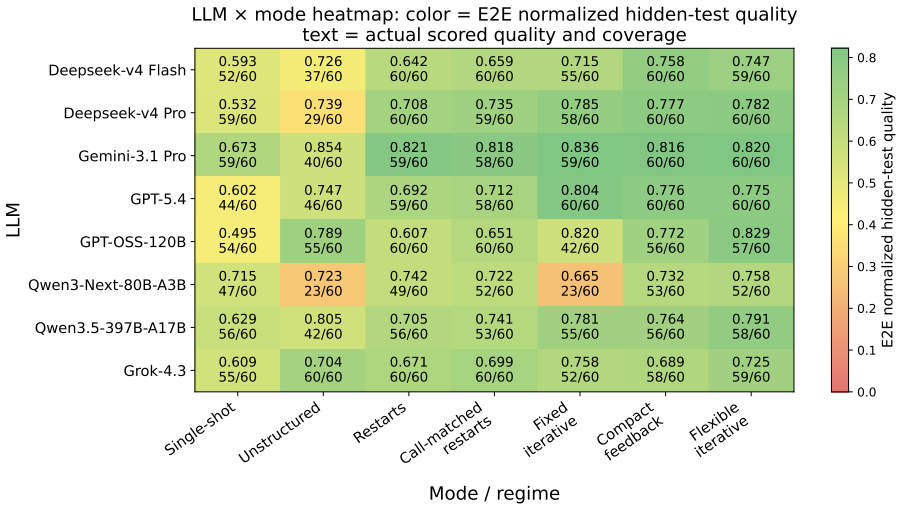
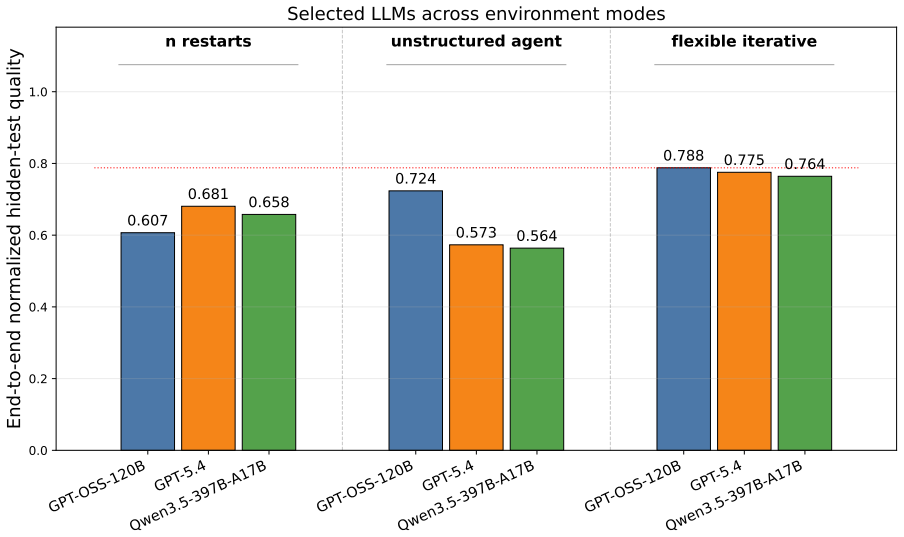
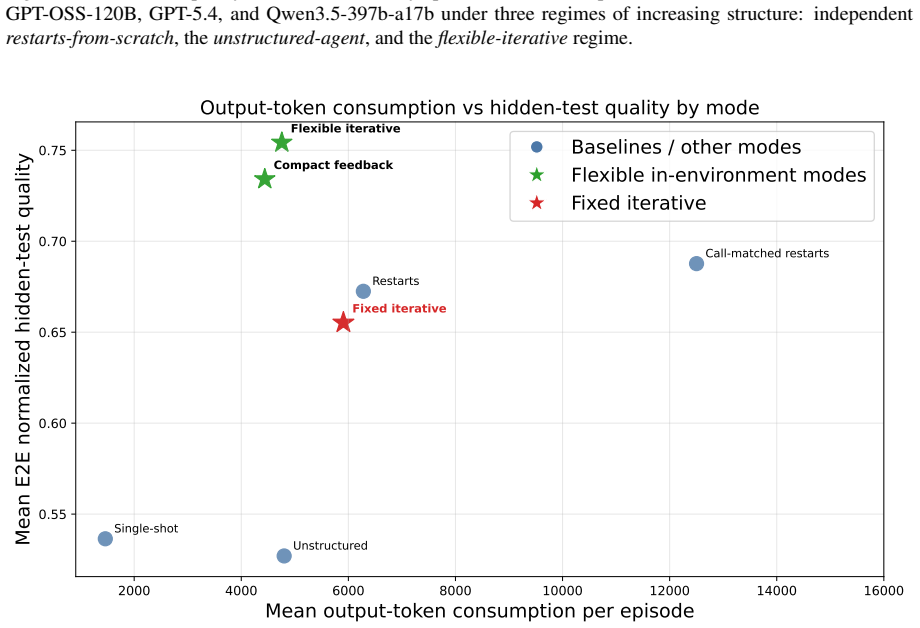
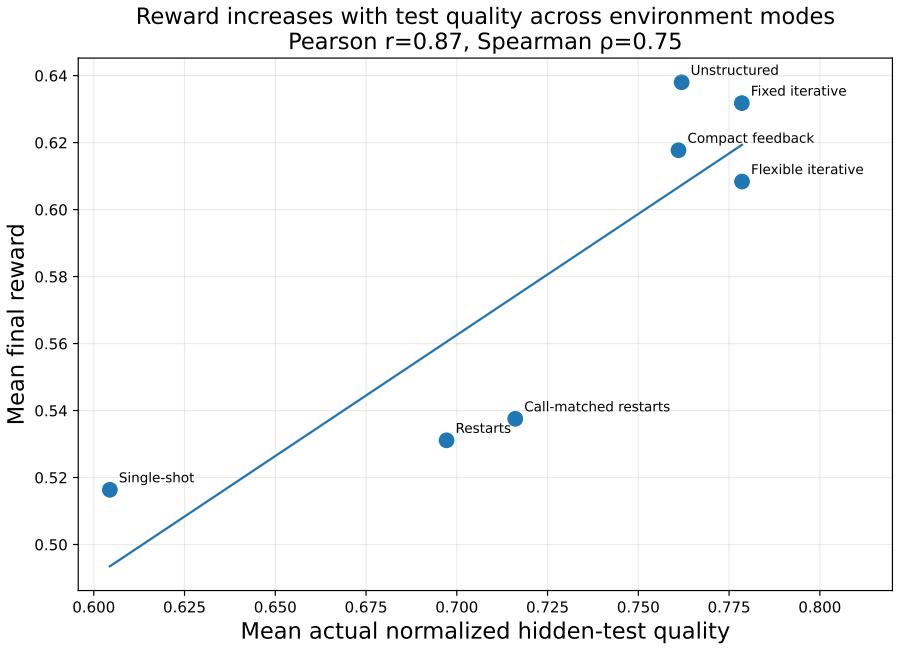
Flexible iterative interaction yields higher quality AutoML workflows than single-shot or unstructured approaches in a guarded evaluation setup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
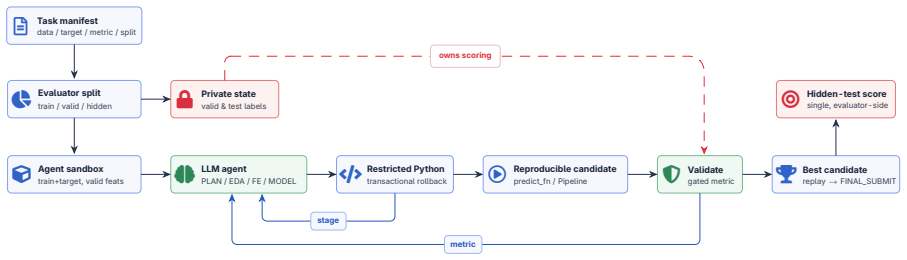
GRACE-DS is a Guarded Reward-guided Agent Correction Environment in Data Science for pre-deployment evaluation of LLM-powered AutoML agents. It exposes agents to realistic workflow stages from planning and data inspection through feature engineering, model development, validation, and code repair to final submission, while hidden executable validators measure not only final predictive performance but also leakage avoidance, reproducibility, protocol validity, correction behavior, and reward alignment. The strongest structured regime, flexible iterative interaction, achieves higher end-to-end normalized hidden-test quality than single-shot generation, unstructured interaction, and restart-bas
What carries the argument
GRACE-DS environment with hidden executable validators that score agents on leakage avoidance, reproducibility, protocol validity, correction behavior, and reward alignment during full data-science workflows.
If this is right
- LLM AutoML agents achieve higher end-to-end normalized hidden-test quality under flexible iterative interaction than under single-shot generation or restart baselines.
- Protocol-valid completion rates rise when agents use the structured iterative regime.
- The environment can assess whether agents meet organization-specific requirements across planning, feature engineering, validation, and code repair stages.
- Performance differences remain consistent when measured over thousands of episodes.
Where Pith is reading between the lines
- Organizations could adopt similar guarded environments to screen agents before live use and reduce risks such as data leakage.
- Extending the validator set to non-tabular domains could test whether the advantage of iterative correction generalizes.
- The focus on reward alignment opens a path for incorporating organization-specific human oversight signals into agent evaluation.
Load-bearing premise
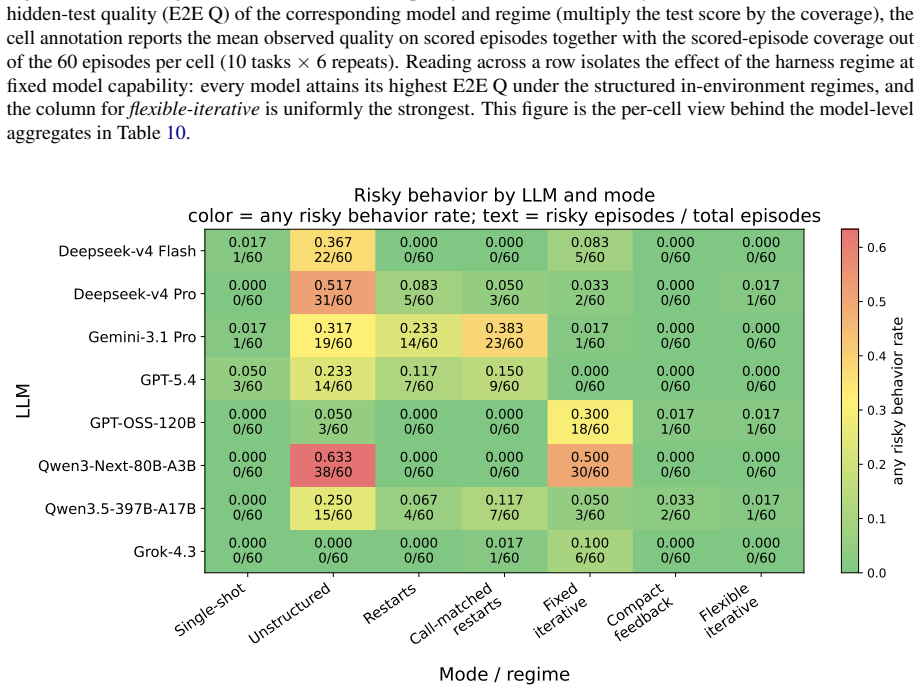
The hidden executable validators accurately and comprehensively measure leakage avoidance, reproducibility, protocol validity, correction behavior, and reward alignment in a manner that corresponds to real organizational production requirements and cannot be gamed by the agents.
What would settle it
An agent that achieves top scores on all GRACE-DS metrics yet produces code that leaks data or fails reproducibility when run outside the guarded environment on the organization's actual data.
Figures
read the original abstract
We introduce GRACE-DS, a Guarded Reward-guided Agent Correction Environment in Data Science for pre-deployment evaluation of LLM-powered AutoML agents. GRACE-DS is a set of evaluation metrics in an isolated environment that can be applied to tabular ML tasks specific to a particular organization. It exposes agents to realistic workflow stages, from planning and data inspection through feature engineering, model development, validation, and code repair to final submission, while hidden executable validators measure not only final predictive performance but also leakage avoidance, reproducibility, protocol validity, correction behavior, and reward alignment. The strongest structured regime, flexible iterative interaction (our approach), achieves higher end-to-end normalized hidden-test quality than single-shot generation, unstructured interaction, and restart-based baselines, while also improving protocol-valid completion. Validated across more than 7,000 episodes, these results establish GRACE-DS as a robust platform for assessing the capacity of LLM-based AutoML agents to execute machine learning workflows under production-like conditions and in accordance with organization-specific requirements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GRACE-DS, a guarded reward-guided agent correction environment for pre-deployment evaluation of LLM-powered AutoML agents on tabular ML tasks. It exposes agents to workflow stages including planning, data inspection, feature engineering, model development, validation, code repair, and submission, with hidden executable validators assessing leakage avoidance, reproducibility, protocol validity, correction behavior, and reward alignment. The central empirical claim is that the flexible iterative interaction regime outperforms single-shot generation, unstructured interaction, and restart-based baselines on end-to-end normalized hidden-test quality and protocol-valid completion, with results validated across more than 7,000 episodes.
Significance. If the hidden validators are shown to be robust, ungameable, and aligned with real production constraints, GRACE-DS could provide a valuable standardized platform for assessing LLM-based AutoML agents under organization-specific conditions. The scale of evaluation (over 7,000 episodes) is a positive aspect. However, the absence of implementation details on validators, task selection, and statistical controls substantially limits the ability to determine whether the reported superiority reflects genuine capability gains or metric artifacts.
major comments (2)
- [Abstract] Abstract: The abstract states comparative results and episode count but supplies no information on task selection, validator implementation, statistical testing, or controls for confounding factors; the central claim cannot be assessed from the provided text.
- [Abstract] Abstract (and by extension the evaluation framework): The claim that flexible iterative interaction outperforms baselines rests on hidden executable validators correctly scoring leakage avoidance, reproducibility, protocol validity, correction behavior, and reward alignment. No implementation details, adversarial robustness checks, or mapping to real-world organizational constraints are supplied, so reported superiority could be an artifact of metric design.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the abstract and evaluation framework. We address each major comment below and note planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states comparative results and episode count but supplies no information on task selection, validator implementation, statistical testing, or controls for confounding factors; the central claim cannot be assessed from the provided text.
Authors: We agree the abstract is highly condensed to meet length limits and omits these specifics. The full manuscript details task selection from organization-specific tabular datasets (Section 3.1), validator implementation via executable sandbox checks (Section 3.2), and statistical testing with controls for episode-level variance and baseline comparisons (Section 4.3). We will revise the abstract to briefly reference organization-specific tasks, hidden validators for leakage/reproducibility/protocol criteria, and statistical validation across episodes. revision: yes
-
Referee: [Abstract] Abstract (and by extension the evaluation framework): The claim that flexible iterative interaction outperforms baselines rests on hidden executable validators correctly scoring leakage avoidance, reproducibility, protocol validity, correction behavior, and reward alignment. No implementation details, adversarial robustness checks, or mapping to real-world organizational constraints are supplied, so reported superiority could be an artifact of metric design.
Authors: Implementation details for the validators (executable checks for each criterion in the guarded environment) appear in Section 3.2 of the manuscript. We did not conduct explicit adversarial robustness tests or provide fine-grained mappings to individual organizational constraints beyond the described production-like workflow. This is a genuine limitation that could affect interpretation of the results. We will add a limitations subsection discussing metric design risks and outline future robustness evaluations while retaining the 7,000+ episode empirical comparison. revision: partial
Circularity Check
No circularity: empirical comparison with no derivations or self-referential reductions
full rationale
The paper describes an empirical evaluation framework (GRACE-DS) that compares interaction regimes on hidden-test metrics across >7000 episodes. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text or abstract. The central claim rests on experimental outcomes rather than any reduction to inputs by construction. The noted weakness in validator robustness is an assumption-validity issue, not a circularity issue per the analysis rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Red Teaming Language Models with Language Models
Ethan Perez and Saffron Huang and H. Francis Song and Trevor Cai and Roman Ring and John Aslanides and Amelia Glaese and Nat McAleese and Geoffrey Irving , title =. CoRR , volume =. 2022 , url =. 2202.03286 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
2023 , articleno =
Lai, Yuhang and Li, Chengxi and Wang, Yiming and Zhang, Tianyi and Zhong, Ruiqi and Zettlemoyer, Luke and Yih, Wen-tau and Fried, Daniel and Wang, Sida and Yu, Tao , booktitle =. 2023 , articleno =
2023
-
[3]
2025 , url =
Liqiang Jing and Zhehui Huang and Xiaoyang Wang and Wenlin Yao and Wenhao Yu and Kaixin Ma and Hongming Zhang and Xinya Du and Dong Yu , booktitle =. 2025 , url =
2025
-
[4]
2024 , url =
Huang, Yiming and Luo, Jianwen and Yu, Yan and Zhang, Yitong and Lei, Fangyu and Wei, Yifan and He, Shizhu and Huang, Lifu and Liu, Xiao and Zhao, Jun and Liu, Kang , booktitle =. 2024 , url =
2024
-
[5]
Dan Zhang and Sining Zhoubian and Min Cai and Fengzu Li and Lekang Yang and Wei Wang and Tianjiao Dong and Ziniu Hu and Jie Tang and Yisong Yue , year=. 2502.13897 , archivePrefix=
-
[6]
2025 , url=
Jun Shern Chan and Neil Chowdhury and Oliver Jaffe and James Aung and Dane Sherburn and Evan Mays and Giulio Starace and Kevin Liu and Leon Maksin and Tejal Patwardhan and Aleksander Madry and Lilian Weng , booktitle=. 2025 , url=
2025
- [7]
-
[8]
2026 , url=
Rushi Qiang and Yuchen Zhuang and Yinghao Li and Dingu Sagar V K and Rongzhi Zhang and ChangHao Li and Ian Shu-Hei Wong and Sherry Yang and Percy Liang and Chao Zhang and Bo Dai , booktitle=. 2026 , url=
2026
-
[9]
2025 , url=
Deepak Nathani and Lovish Madaan and Nicholas Roberts and Nikolay Bashlykov and Ajay Menon and Vincent Moens and Mikhail Plekhanov and Amar Budhiraja and Despoina Magka and Vladislav Vorotilov and Gaurav Chaurasia and Dieuwke Hupkes and Ricardo Silveira Cabral and Tatiana Shavrina and Jakob Nicolaus Foerster and Yoram Bachrach and William Yang Wang and Ro...
2025
-
[10]
Fan Nie and Junlin Wang and Harper Hua and Federico Bianchi and Yongchan Kwon and Zhenting Qi and Owen Queen and Shang Zhu and James Zou , year=. 2601.16344 , archivePrefix=
-
[11]
2024 , url =
Huang, Qian and Vora, Jian and Liang, Percy and Leskovec, Jure , booktitle =. 2024 , url =
2024
-
[12]
2024 , articleno =
Hu, Xueyu and Zhao, Ziyu and Wei, Shuang and Chai, Ziwei and Ma, Qianli and Wang, Guoyin and Wang, Xuwu and Su, Jing and Xu, Jingjing and Zhu, Ming and Cheng, Yao and Yuan, Jianbo and Li, Jiwei and Kuang, Kun and Yang, Yang and Yang, Hongxia and Wu, Fei , booktitle =. 2024 , articleno =
2024
-
[13]
Alex Egg and Martin Iglesias Goyanes and Friso Kingma and Andreu Mora and Leandro von Werra and Thomas Wolf , year=. 2506.23719 , archivePrefix=
-
[14]
Hanyu Li and Haoyu Liu and Tingyu Zhu and Tianyu Guo and Zeyu Zheng and Xiaotie Deng and Michael I. Jordan , year=. 2505.18223 , archivePrefix=
-
[15]
and Zhu, Lanyi and Merrill, Mike A and Heer, Jeffrey and Althoff, Tim , booktitle =
Gu, Ken and Shang, Ruoxi and Jiang, Ruien and Kuang, Keying and Lin, Richard-John and Lyu, Donghe and Mao, Yue and Pan, Youran and Wu, Teng and Yu, Jiaqian and Zhang, Yikun and Zhang, Tianmai M. and Zhu, Lanyi and Merrill, Mike A and Heer, Jeffrey and Althoff, Tim , booktitle =. 2024 , url =
2024
-
[16]
Baker and Benjamin Burns and Daniel Adu-Ampratwum and Xuhui Huang and Xia Ning and Song Gao and Yu Su and Huan Sun , booktitle=
Ziru Chen and Shijie Chen and Yuting Ning and Qianheng Zhang and Boshi Wang and Botao Yu and Yifei Li and Zeyi Liao and Chen Wei and Zitong Lu and Vishal Dey and Mingyi Xue and Frazier N. Baker and Benjamin Burns and Daniel Adu-Ampratwum and Xuhui Huang and Xia Ning and Song Gao and Yu Su and Huan Sun , booktitle=. 2025 , url=
2025
-
[17]
2025 , url=
Bodhisattwa Prasad Majumder and Harshit Surana and Dhruv Agarwal and Bhavana Dalvi Mishra and Abhijeetsingh Meena and Aryan Prakhar and Tirth Vora and Tushar Khot and Ashish Sabharwal and Peter Clark , booktitle=. 2025 , url=
2025
-
[18]
Gaurav Sahu and Abhay Puri and Juan A. Rodriguez and Amirhossein Abaskohi and Mohammad Chegini and Alexandre Drouin and Perouz Taslakian and Valentina Zantedeschi and Alexandre Lacoste and David Vazquez and Nicolas Chapados and Christopher Pal and Sai Rajeswar and Issam H. Laradji , booktitle=. 2025 , url=
2025
-
[19]
Christine Ye and Sihan Yuan and Suchetha Cooray and Steven Dillmann and Ian L. V. Roque and Dalya Baron and Philipp Frank and Sergio Martin-Alvarez and Nolan Koblischke and Frank J Qu and Diyi Yang and Risa Wechsler and Ioana Ciuc. 2026 , url=
2026
-
[20]
Pieter Gijsbers and Marcos L. P. Bueno and Stefan Coors and Erin LeDell and S. Journal of Machine Learning Research , year =
-
[21]
arXiv preprint arXiv:2402.18679 , year=
Sirui Hong and Yizhang Lin and Bang Liu and Bangbang Liu and Binhao Wu and Ceyao Zhang and Chenxing Wei and Danyang Li and Jiaqi Chen and Jiayi Zhang and Jinlin Wang and Li Zhang and Lingyao Zhang and Min Yang and Mingchen Zhuge and Taicheng Guo and Tuo Zhou and Wei Tao and Xiangru Tang and Xiangtao Lu and Xiawu Zheng and Xinbing Liang and Yaying Fei and ...
-
[22]
2025 , url =
Jiang, Zhengyao and Schmidt, Dominik and Srikanth, Dhruv and Xu, Dixing and Kaplan, Ian and Jacenko, Deniss and Wu, Yuxiang , eprint=. 2025 , url =
2025
-
[23]
2025 , url=
Ivan Rubachev and Nikolay Kartashev and Yury Gorishniy and Artem Babenko , booktitle=. 2025 , url=
2025
-
[24]
Scikit-learn: Machine Learning in
Fabian Pedregosa and Ga. Scikit-learn: Machine Learning in. Journal of Machine Learning Research , year =
-
[25]
Dominik Kreuzberger and Niklas Kühl and Sebastian Hirschl , year=. Machine Learning Operations (. 2205.02302 , archivePrefix=
-
[26]
2024 , howpublished =
Huu Tiep, Nguyen , title =. 2024 , howpublished =
2024
-
[27]
Malware Dataset Generation and Evaluation , year=
Borah, Parthajit and Bhattacharyya, DK and Kalita, JK , booktitle=. Malware Dataset Generation and Evaluation , year=
-
[28]
2021 , howpublished =
Alex Teboul and CDC , title =. 2021 , howpublished =
2021
-
[29]
2026 , howpublished =
Aleksandr Tsymbalov and Danis Zaripov and Artem Epifanov and Anastasiya Palienko , title =. 2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.