MASCOT-Android: A Curated Dataset and Automated Collection Pipeline for Android Malware Source Code Specimens
Pith reviewed 2026-06-27 04:11 UTC · model grok-4.3
The pith
Repository README documentation alone can identify Android malware source code repositories at 96.28% accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
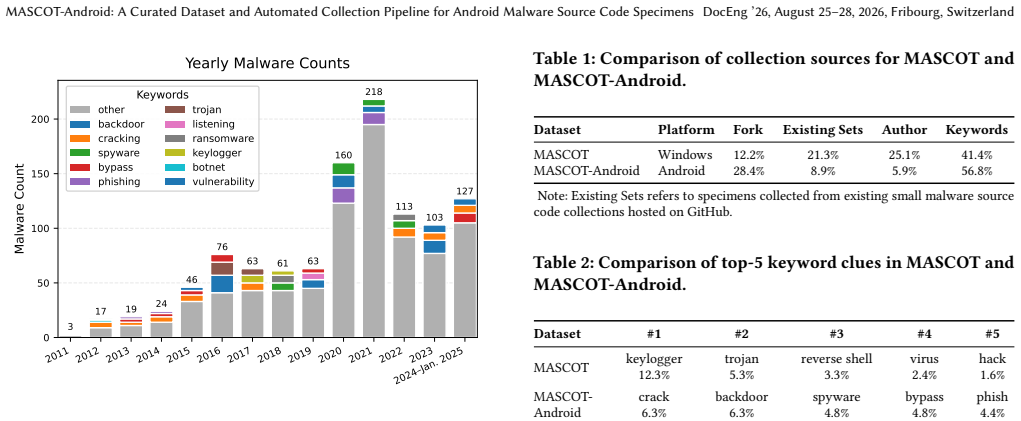
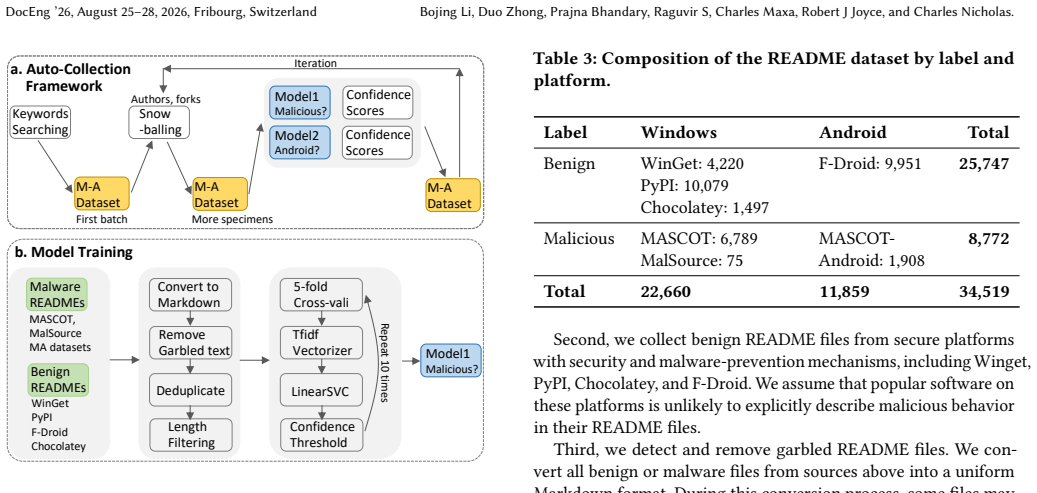
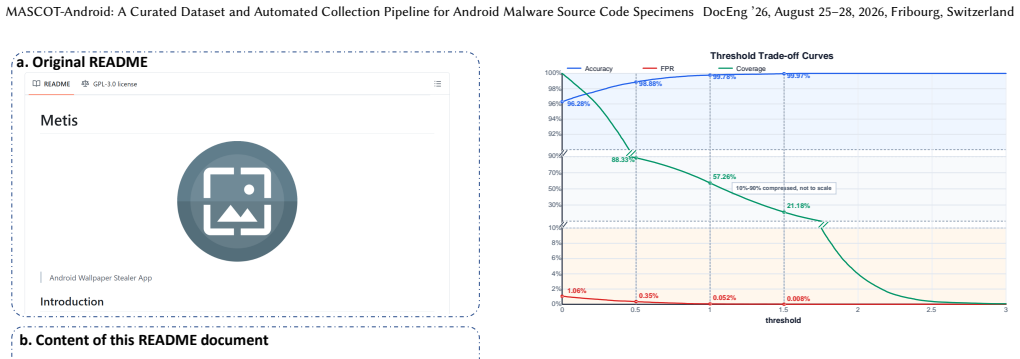
Repository-level documentation alone provides a strong signal for malware source code collection. Our model extracts character-level TF-IDF features from 8,772 malware and 25,747 benign README documents and trains a LinearSVC classifier to distinguish malware repositories. This README-only model achieves an accuracy of 96.28% and an FPR of 1.06% in local evaluation. In addition, the model outputs confidence scores, allowing users to adjust the decision threshold to balance FPR and coverage, which is practical in real-world malware source code collection.
What carries the argument
The README-only classifier that uses character-level TF-IDF features from repository documentation and a LinearSVC model to flag malware repositories, with confidence scores for threshold tuning.
If this is right
- An automated pipeline can collect and maintain large-scale Android malware source code datasets from GitHub.
- Confidence scores let practitioners raise or lower the decision threshold to trade coverage against false positives.
- Source-code datasets built this way reflect attacker intent more directly than binary or decompiled artifacts.
- The same documentation-based approach can reduce the cost of curating malware specimens over time.
Where Pith is reading between the lines
- The method could be tested on repositories for other platforms such as Windows or Linux malware to check generality.
- Pairing the README classifier with static code analysis might add a second validation layer before inclusion in the dataset.
- Large source-code collections produced by the pipeline could serve as training data for improved malware detection models.
Load-bearing premise
The ground-truth labels assigned to the 8,772 malware and 25,747 benign repositories used for training and testing are accurate and free of selection bias.
What would settle it
Manual inspection of a random sample of repositories the model labels as malware that reveals a high rate of clearly benign projects would show the README signal is not reliable.
Figures




read the original abstract
Compared with binaries and decompiled code, malware source code more directly reflects the attackers' original intent. However, the scarcity of source code and the high cost of manual review make such datasets difficult to build and maintain. We propose MASCOT-Android, a curated dataset of Android malware source code and an automated collection framework for scalable malware source code discovery on GitHub. A key finding of our work is that repository-level documentation alone provides a strong signal for malware source code collection. Our model extracts character-level TF-IDF features from 8,772 malware and 25,747 benign README documents and trains a LinearSVC classifier to distinguish malware repositories. This README-only model achieves an accuracy of 96.28\% and an FPR of 1.06\% in local evaluation. In addition, the model outputs confidence scores, allowing users to adjust the decision threshold to balance FPR and coverage, which is practical in real-world malware source code collection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MASCOT-Android, a curated dataset of Android malware source code specimens collected from GitHub together with an automated pipeline for scalable discovery. Its central empirical claim is that repository-level README documentation alone supplies a strong signal: a LinearSVC trained on character-level TF-IDF features from 8,772 malware and 25,747 benign README documents achieves 96.28% accuracy and 1.06% FPR in local evaluation, with confidence scores permitting threshold adjustment for FPR-coverage trade-offs.
Significance. If the ground-truth labels prove reliable and independent of the README text, the result would offer a low-cost, documentation-driven method for expanding malware source-code corpora, directly addressing the scarcity problem highlighted in the abstract and enabling practical deployment via adjustable thresholds.
major comments (1)
- [Abstract / Dataset Construction] Abstract and dataset-construction section: the ground-truth labels for the 8,772 malware repositories are stated as given counts but their provenance is never described (no mention of GitHub search heuristics, topic tags, external AV reports, manual review protocol, or any validation step). Because the reported 96.28% accuracy and 1.06% FPR are obtained by training and evaluating on these labels, the absence of labeling methodology renders the central performance claim uninterpretable and potentially circular.
minor comments (1)
- [Abstract] The abstract supplies performance numbers but omits any reference to cross-validation procedure, label-noise controls, or feature-extraction hyperparameters; these details should be added even if the labeling method is the primary gap.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for highlighting the need for greater transparency in dataset construction. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Dataset Construction] Abstract and dataset-construction section: the ground-truth labels for the 8,772 malware repositories are stated as given counts but their provenance is never described (no mention of GitHub search heuristics, topic tags, external AV reports, manual review protocol, or any validation step). Because the reported 96.28% accuracy and 1.06% FPR are obtained by training and evaluating on these labels, the absence of labeling methodology renders the central performance claim uninterpretable and potentially circular.
Authors: We agree that the current manuscript lacks a clear description of how the ground-truth labels for the 8,772 malware repositories were obtained. This omission makes it difficult for readers to assess label independence from the README features and to evaluate potential circularity. In the revised manuscript we will insert a new subsection under Dataset Construction that explicitly details: (1) the GitHub search queries and heuristics used to identify candidate malware repositories, (2) any topic tags, repository metadata, or external signals (e.g., references to known malware families or AV scan results) employed for initial labeling, (3) the manual review protocol applied to a sample of repositories, and (4) any quantitative validation steps performed to confirm label quality. These additions will demonstrate that the labels are derived from sources independent of the character-level TF-IDF features extracted from README files, thereby removing the circularity concern and allowing the reported accuracy and FPR figures to be properly interpreted. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper trains a LinearSVC on character-level TF-IDF features extracted from externally labeled README documents (8,772 malware, 25,747 benign) and reports standard accuracy/FPR metrics. No equations, procedures, or self-citations reduce the reported performance to a quantity defined by the fitted parameters themselves, nor do any of the enumerated circularity patterns (self-definitional, fitted-input-as-prediction, load-bearing self-citation, etc.) appear. The central claim rests on the (undescribed) labeling process being independent, but the derivation itself is self-contained against external benchmarks and does not collapse by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- LinearSVC regularization and class-weight parameters
axioms (1)
- domain assumption Ground-truth labels for the 8,772 malware and 25,747 benign repositories are accurate and unbiased
Reference graph
Works this paper leans on
- [1]
-
[2]
Pieter Arntz. 2025. Android mobile adware surges in second half of 2025. https: //www.malwarebytes.com/blog/mobile/2025/12/android-threats-in-2025- when-your-phone-becomes-the-main-attack-surface. Malwarebytes. Accessed: 2026-04-11
2025
-
[3]
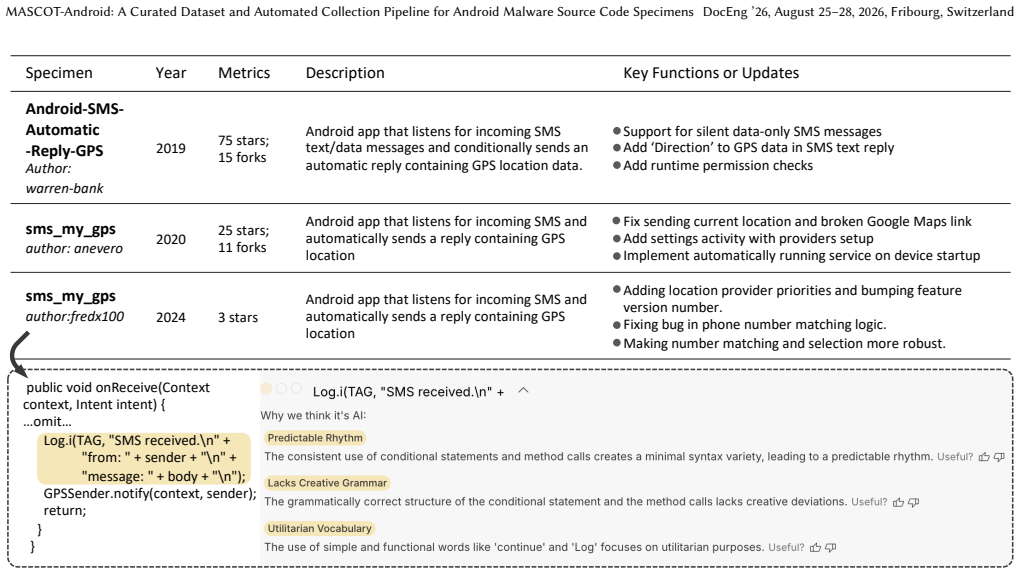
Warren Bank. 2020. Android-SMS-Automatic-Reply-GPS. https://github.com /warren-bank/Android-SMS-Automatic-Reply-GPS. GitHub repository, latest release v2.1.7, accessed April 21, 2026
2020
-
[4]
Hendrio Bragança, Diego Kreutz, Vanderson Rocha, Joner Assolin, and Eduardo Feitosa. 2025. MH-1M: A 1.34 Million-Sample Multi-Feature Android Malware Dataset with Rich Metadata.Scientific Data(2025)
2025
-
[5]
Alejandro Calleja, Juan Tapiador, and Juan Caballero. 2018. The malsource dataset: Quantifying complexity and code reuse in malware development.IEEE Transactions on Information Forensics and Security14, 12 (2018), 3175–3190
2018
-
[6]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. 2025. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 23–42
2025
-
[7]
James R Cordy and Chanchal K Roy. 2011. The nicad clone detector. In2011 IEEE 19th international conference on program comprehension. IEEE, 219–220
2011
-
[8]
Emanuele Cozzi, Pierre-Antoine Vervier, Matteo Dell’Amico, Yun Shen, Leyla Bilge, and Davide Balzarotti. 2020. The tangled genealogy of IoT malware. In Proceedings of the 36th Annual Computer Security Applications Conference. 1–16
2020
-
[9]
d Raco. 2026. android-malware-source-code-analysis. https://github.com/d- Raco/android-malware-source-code-analysis. GitHub repository. Accessed: 2026-04-13
2026
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[11]
F-Droid Contributors. 2026. About F-Droid. https://f-droid.org/en/about/. Accessed: 2026-04-24
2026
-
[12]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. 2020. Codebert: A pre-trained model for programming and natural languages. InFindings of the association for computational linguistics: EMNLP 2020. 1536–1547
2020
-
[13]
fredx100. 2024. sms_my_gps: Android app that listens for incoming SMS and automatically sends a reply containing GPS location. https://github.com/fredx10 0/sms_my_gps. GitHub repository, forked from anevero/sms_my_gps, version v3.6.0, accessed April 21, 2026
2024
-
[14]
jawah. 2026. charset_normalizer. https://github.com/jawah/charset_normalizer. GitHub repository, version 3.4.7, accessed 2026-04-19
2026
-
[15]
Yuxuan Jiang and Francis Ferraro. 2026. SCRIBE: Structured Mid-Level Supervi- sion for Tool-Using Language Models.arXiv preprint arXiv:2601.03555(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Kaspersky. 2025. Kaspersky report: Attacks on smartphones increased in the first half of 2025. https://www.kaspersky.com/about/press-releases/kaspersky- report-attacks-on-smartphones-increased-in-the-first-half-of-2025. Kaspersky Press Release. Accessed: 2026-04-11
2025
-
[17]
David Sean Keyes, Beiqi Li, Gurdip Kaur, Arash Habibi Lashkari, Francois Gagnon, and Frédéric Massicotte. 2021. EntropLyzer: Android malware classification and characterization using entropy analysis of dynamic characteristics. In2021 Rec- onciling Data Analytics, Automation, Privacy, and Security: A Big Data Challenge (RDAAPS). IEEE, 1–12
2021
-
[18]
Arash Habibi Lashkari, Andi Fitriah A Kadir, Laya Taheri, and Ali A Ghorbani
-
[19]
In2018 International Carnahan conference on security technology (ICCST)
Toward developing a systematic approach to generate benchmark android malware datasets and classification. In2018 International Carnahan conference on security technology (ICCST). ieee, 1–7
-
[20]
Bojing Li, Duo Zhong, Dharani Nadendla, Gabriel Terceros, Prajna Bhandary, Raguvir S, and Charles Nicholas. 2025. MASCOT: Analyzing Malware Evolution Through a Well-Curated Source Code Dataset. In2025 IEEE International Confer- ence on Big Data (BigData). 7814–7824. doi:10.1109/BigData66926.2025.11401016
-
[21]
Andrew Nevero. 2021. sms_my_gps: Android app that listens for incoming SMS and automatically sends a reply containing GPS location. https://github.com/ane vero/sms_my_gps. GitHub repository, latest release v3.4.8, accessed April 21, 2026
2021
-
[22]
Phuong T Nguyen, Juri Di Rocco, Claudio Di Sipio, Riccardo Rubei, Davide Di Ruscio, and Massimiliano Di Penta. 2024. GPTSniffer: A CodeBERT-based classifier to detect source code written by ChatGPT.Journal of Systems and Software214 (2024), 112059
2024
-
[23]
OpenAI. 2026. GPT-5.4 Thinking System Card. https://deploymentsafety.openai. com/gpt-5-4-thinking/model-safety-training Deployment Safety Hub
2026
-
[24]
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al . 2018. Improving language understanding by generative pre-training. (2018)
2018
-
[25]
Md Omar Faruk Rokon, Risul Islam, Ahmad Darki, Evangelos E Papalexakis, and Michalis Faloutsos. 2020. {SourceFinder}: Finding malware {Source-Code} from publicly available repositories in {GitHub}. In23rd International Symposium on Research in Attacks, Intrusions and Defenses (RAID 2020). 149–163
2020
-
[26]
Ashkan Sami, Babak Yadegari, Hossein Rahimi, Naser Peiravian, Sattar Hashemi, and Ali Hamze. 2010. Malware detection based on mining API calls. InProceedings of the 2010 ACM symposium on applied computing. 1020–1025
2010
-
[27]
scikit-learn developers. 2026. sklearn.feature_extraction.text.TfidfVectorizer. https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.te xt.TfidfVectorizer.html. Accessed: 2026-04-24
2026
-
[28]
scikit-learn developers. 2026. sklearn.svm.LinearSVC. https://scikit-learn.org/st able/modules/generated/sklearn.svm.LinearSVC.html. Accessed: 2026-04-24
2026
-
[29]
Minami Someya, Yuhei Otsubo, and Akira Otsuka. 2023. FCGAT: Interpretable malware classification method using function call graph and attention mechanism. InProceedings of Network and Distributed Systems Security (NDSS) Symposium, Vol. 1
2023
-
[30]
Kimberly Tam, Ali Feizollah, Nor Badrul Anuar, Rosli Salleh, and Lorenzo Caval- laro. 2017. The evolution of android malware and android analysis techniques. ACM Computing Surveys (CSUR)49, 4 (2017), 1–41
2017
-
[31]
Tree-sitter. 2018. Tree-sitter Documentation. https://tree-sitter.github.io/tree- sitter/. Accessed: 2026-04-23
2018
-
[32]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[33]
Khaled Yakdan, Sergej Dechand, Elmar Gerhards-Padilla, and Matthew Smith
-
[34]
In2016 IEEE Symposium on Security and Privacy (SP)
Helping Johnny to Analyze Malware: A Usability-Optimized Decompiler and Malware Analysis User Study. In2016 IEEE Symposium on Security and Privacy (SP). 158–177. doi:10.1109/SP.2016.18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.