CASPER: Interpretable ResNet based Classifier with FastShap Explainer for Gravitational Wave Detection
Pith reviewed 2026-06-27 02:45 UTC · model grok-4.3
The pith
CASPER pairs a ResNet classifier with FastSHAP to detect gravitational waves at 91% AUC from 260 real LIGO events without synthetic data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
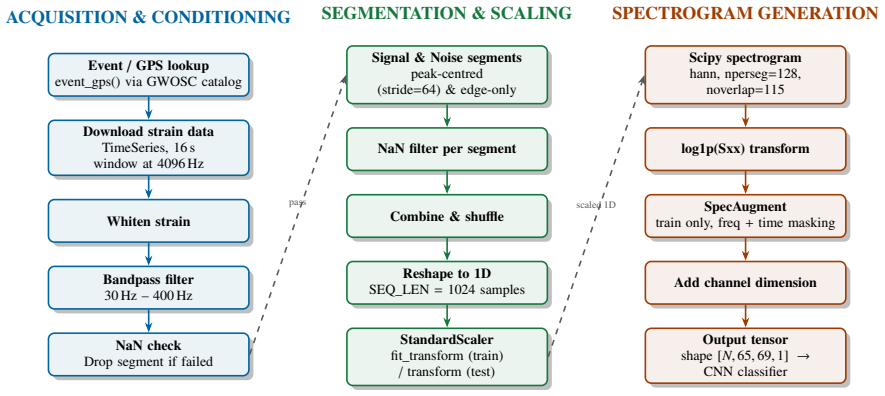
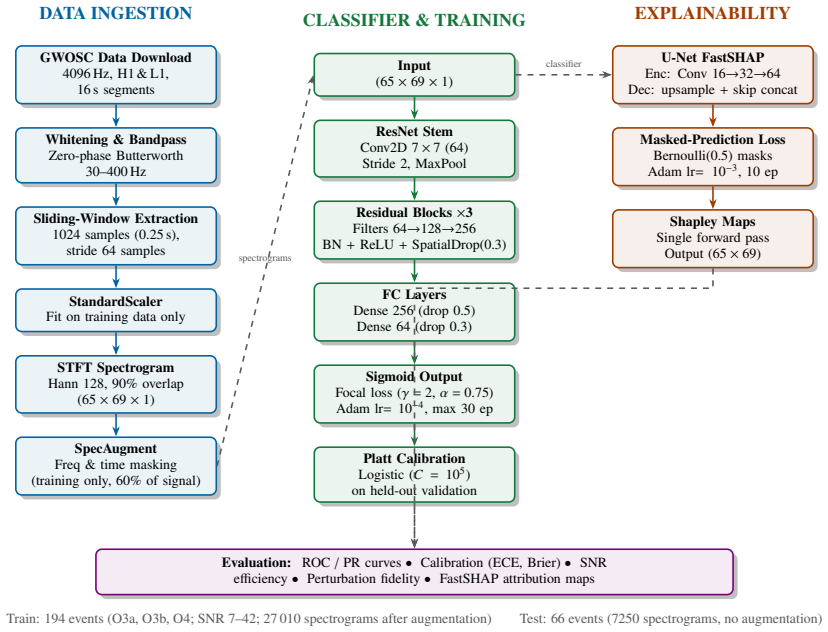
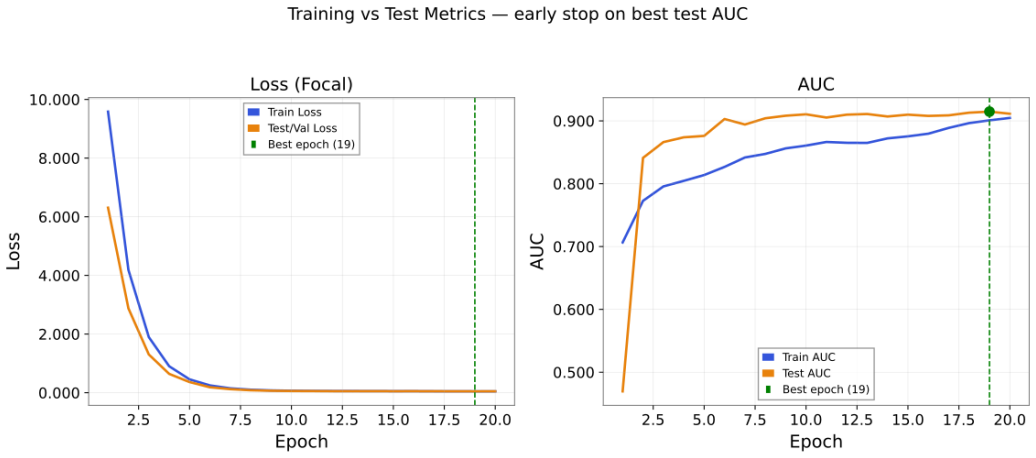
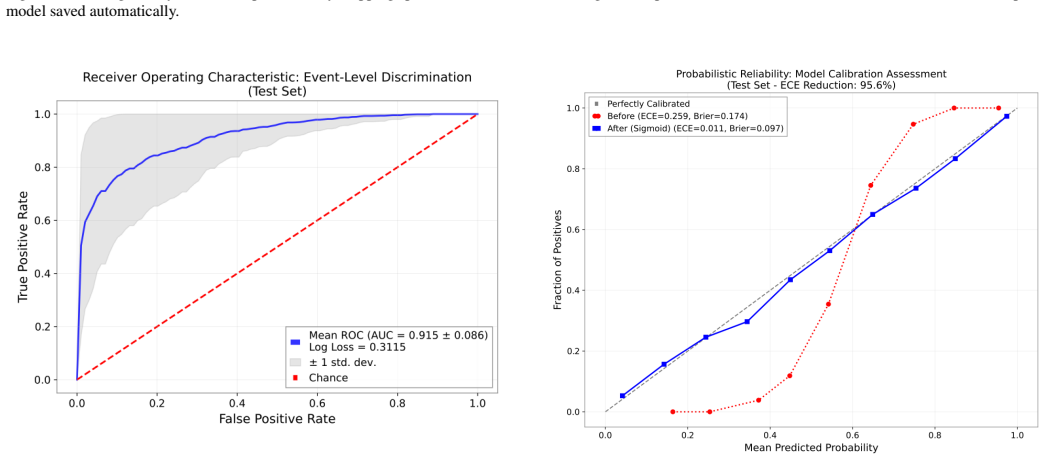
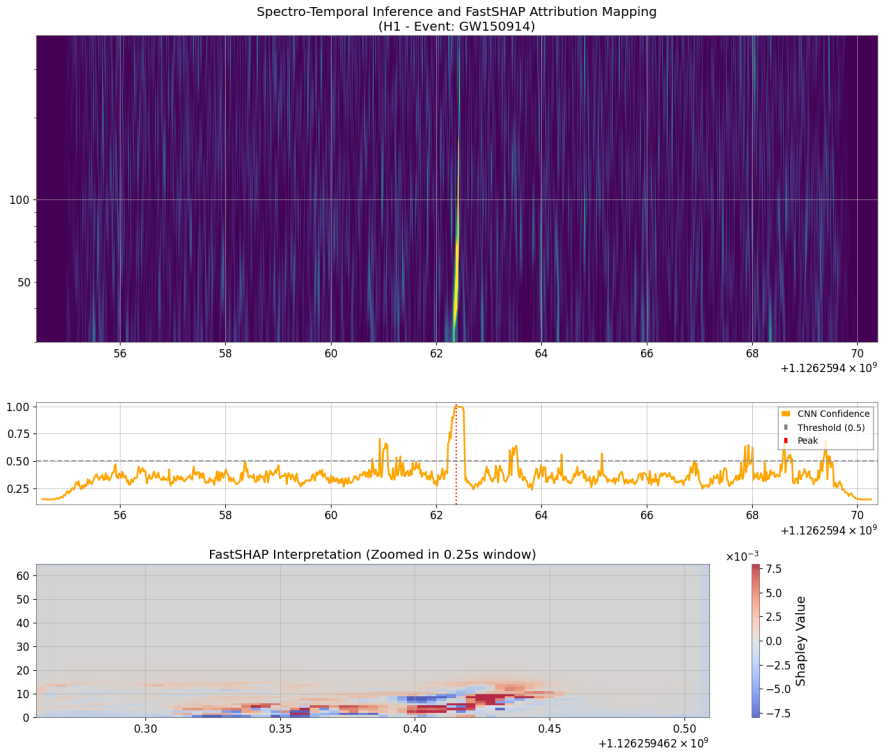
CASPER is an end-to-end pipeline that combines a residual convolutional neural network classifier with a FastSHAP explainer. Trained on 260 distinct real events fetched from the Gravitational Wave Open Science Centre across SNR range 7-42 from both H1 and L1 detectors with no synthetic augmentation, the classifier reaches an AUC of 91 percent with a low false alarm rate. Focal loss and Platt calibration are used to sharpen the decision boundary. The FastSHAP component produces attribution maps that recover the complete chirp morphology and supply detailed visual maps for interpreting the model's decisions. The full pipeline contains fewer parameters than standard deep learning models and req
What carries the argument
The residual convolutional neural network classifier paired with the FastSHAP explainer that produces attribution maps highlighting signal features driving each classification.
If this is right
- The classifier achieves 91 percent AUC and low false alarm rates on real detector data without synthetic augmentation.
- FastSHAP attribution maps recover the complete chirp morphology and supply visual interpretations of decisions.
- Focal loss and Platt calibration improve the decision boundary and generalization.
- The pipeline uses fewer parameters than standard deep learning models and runs on standard CPUs.
- It supplies an interpretable alternative to matched filtering that does not require pre-computed waveform templates.
Where Pith is reading between the lines
- If the attribution maps reliably isolate physical signal features, the same pipeline could be tested on other transient signals in noisy time-series data.
- The CPU-only design opens the possibility of running the detector on modest hardware at multiple observatory sites.
- Retraining on events from additional detectors would test whether the model has learned detector-specific noise patterns.
Load-bearing premise
The 260 real events from H1 and L1 across the given SNR range are sufficient to produce a model that generalizes to new real detector noise and avoids class overlap or train-test mismatch.
What would settle it
A held-out set of additional real LIGO events in the same SNR range where the model drops well below 91 percent AUC or shows elevated false alarms would falsify the generalization claim.
Figures


read the original abstract
Traditional matched filtering has been the standard for Gravitational waves (GW) detection ever since LIGO was established, even though it requires pre-computed waveform templates and provides no accounts of information about which signal drove the decision of classification. Deep-learning alternatives showed competitive sensitivity, but system biasesincluding class overlap, imbalanced class weighting, limited sample variation, and traintest mismatchcontinue to cause problems with generalisation in real detector noise. We introduce CASPER-Classification with Attribution via ShaPlEy in Residual neural networks, an end-to-end pipeline combining residual convolutional neural network (CNN) classifier with a FastSHAP explainer. 260 distinct events from the Gravitational Wave open Science Centre were fetched across SNR range of 7-42 from both H1 and L1 detectors with no synthetic augmentation. The classifier achieves AUC (Area Under Curve) of 91% across the model with a low false alarm rate. Focal Loss and Platt Calibration were used to improve decision boundary and generalisation. FastSHAP attribution maps recover the complete chirp morphology and provides detailed maps for a visual interpretation of the decision. The complete pipeline contains fewer parameters than standard deep learning models and requires no hardware except a standard CPU making our model an effective lightweight pipeline for Gravitational Wave Detection under real life conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CASPER, an end-to-end pipeline that combines a residual CNN classifier with a FastSHAP explainer for gravitational wave detection. It trains on 260 distinct real events fetched from GWOSC (SNR range 7-42, H1 and L1 detectors, no synthetic augmentation), reports an AUC of 91% with low false alarm rate using Focal Loss and Platt Calibration, claims that FastSHAP attribution maps recover complete chirp morphology for visual interpretability, and asserts that the pipeline has fewer parameters than standard deep learning models and runs on standard CPU hardware.
Significance. If the performance and generalization claims hold under rigorous validation, the work could offer a lightweight, interpretable alternative to matched filtering that provides visual explanations of classification decisions. The focus on real (non-augmented) data and CPU-only execution addresses practical constraints in gravitational wave analysis pipelines.
major comments (3)
- [Abstract / Methods] Abstract and Methods (dataset description): Training relies on exactly 260 distinct real events with no synthetic augmentation or large accompanying noise corpus. This scale is insufficient to substantiate generalizability claims in the presence of the very biases the abstract enumerates (class overlap, imbalance, limited sample variation, train-test mismatch), as standard GW deep-learning pipelines require 10^4–10^6 samples to achieve robustness against non-stationary detector noise.
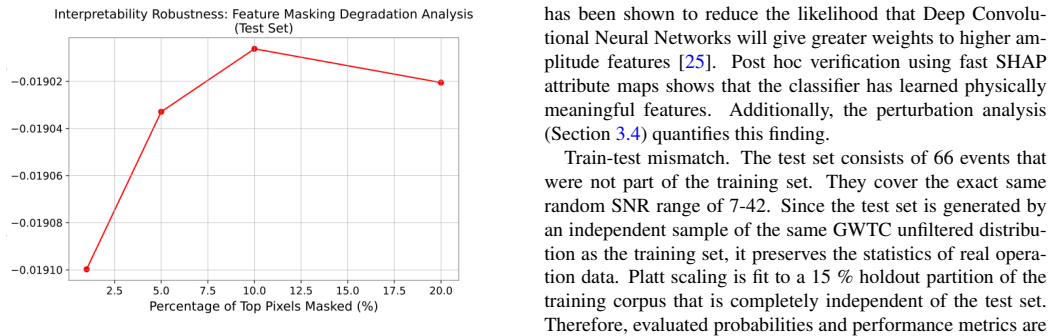
- [Results] Results section: The 91% AUC, low false-alarm-rate, and chirp-recovery claims are presented without baseline comparisons, cross-validation procedure, error bars, statistical significance tests, or explicit handling of the listed biases. No quantitative metrics accompany the FastSHAP attribution maps beyond visual inspection.
- [Abstract] Abstract: The statement that the pipeline 'contains fewer parameters than standard deep learning models' is unsupported by any parameter counts, architecture table, or direct comparison.
minor comments (2)
- [Abstract] Abstract contains typographical errors: 'system biasesincluding' (missing space), 'traintest mismatch' (hyphenation), and subject-verb disagreement in 'FastSHAP attribution maps recover ... and provides'.
- [Abstract] The abstract asserts 'low false alarm rate' without defining the operating threshold or providing the corresponding precision-recall or ROC operating point.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key gaps in validation, statistical rigor, and support for claims. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods (dataset description): Training relies on exactly 260 distinct real events with no synthetic augmentation or large accompanying noise corpus. This scale is insufficient to substantiate generalizability claims in the presence of the very biases the abstract enumerates (class overlap, imbalance, limited sample variation, train-test mismatch), as standard GW deep-learning pipelines require 10^4–10^6 samples to achieve robustness against non-stationary detector noise.
Authors: We agree that 260 real events without augmentation is a small scale that weakens generalizability claims, especially given the biases listed in the abstract. The design choice prioritized unaugmented real detector data over synthetic augmentation, but this limitation must be stated more explicitly. We will revise the abstract and methods to temper generalizability language, add a dedicated limitations paragraph discussing sample size and bias mitigation via focal loss and Platt scaling, and outline plans for larger datasets in future work. revision: yes
-
Referee: [Results] Results section: The 91% AUC, low false-alarm-rate, and chirp-recovery claims are presented without baseline comparisons, cross-validation procedure, error bars, statistical significance tests, or explicit handling of the listed biases. No quantitative metrics accompany the FastSHAP attribution maps beyond visual inspection.
Authors: These omissions are valid concerns. The revised manuscript will detail the cross-validation procedure, include error bars and statistical tests where feasible, add baseline comparisons (e.g., to simple matched-filtering thresholds or other lightweight CNNs), and introduce quantitative metrics for attribution maps such as the percentage of positive attribution overlapping expected chirp time-frequency support. revision: yes
-
Referee: [Abstract] Abstract: The statement that the pipeline 'contains fewer parameters than standard deep learning models' is unsupported by any parameter counts, architecture table, or direct comparison.
Authors: We will add an architecture table with exact parameter counts for CASPER and direct comparisons to standard models (e.g., ResNet-18/50 variants and other GW detection CNNs) in the methods or results section, and update the abstract accordingly. revision: yes
Circularity Check
No circularity: empirical ML performance on fetched events, no derivations or self-referential reductions
full rationale
The paper presents an end-to-end ML pipeline (ResNet classifier + FastSHAP) trained on 260 real GWOSC events and reports an empirical AUC of 91%. No equations, first-principles derivations, or predictions appear that reduce the reported metrics to fitted inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing. The performance claim is a direct empirical result on the described dataset, consistent with the reader's assessment of score 2 (or lower). Standard data-scale concerns are separate from circularity analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P., et al
Abbott, B. P., et al. 2016,Phys. Rev. Lett., 116, 061102
2016
-
[2]
P., et al
Abbott, B. P., et al. 2017,Phys. Rev. Lett., 119, 161101
2017
-
[3]
2021,Phys
Abbott, R., et al. 2021,Phys. Rev. X, 11, 021053
2021
-
[4]
2023,Phys
Abbott, R., et al. 2023,Phys. Rev. X, 13, 041039
2023
-
[5]
G., Brady, P
Allen, B., Anderson, W. G., Brady, P. R., Brown, D. A., & Creighton, J. D. E. 2012,Phys. Rev. D, 85, 122006
2012
-
[6]
Dhurandhar, S. V . & Sathyaprakash, B. S. 1994,Phys. Rev. D, 49, 1707
1994
-
[7]
Owen, B. J. & Sathyaprakash, B. S. 1999,Phys. Rev. D, 60, 022002
1999
-
[8]
& Huerta, E
George, D. & Huerta, E. A. 2018,Phys. Rev. D, 97, 044039
2018
-
[9]
2018,Phys
Gabbard, H., Williams, M., Hayes, F., & Messenger, C. 2018,Phys. Rev. Lett., 120, 141103 8
2018
-
[10]
D., Kilbertus, N., Harry, I., & Schölkopf, B
Gebhard, T. D., Kilbertus, N., Harry, I., & Schölkopf, B. 2019,Phys. Rev. D, 100, 063015
2019
-
[11]
2020,Sci
Corizzo, R., Ceci, M., Zdravevski, E., & Japkowicz, N. 2020,Sci. Rep., 10, 20681
2020
-
[12]
2022,Phys
Yan, Z., et al. 2022,Phys. Rev. D, 105, 043006
2022
- [13]
-
[14]
C., Wills, L., Saleem, M., Moreno, E., et al
Marx, E., Benoit, W., Gunny, A., Omer, R., Chatterjee, D., Venterea, R. C., Wills, L., Saleem, M., Moreno, E., et al. 2023,Phys. Rev. D, 108, 102004
2023
-
[15]
Beheshtipour, B., & Papa, M. A. 2021,Phys. Rev. D, 103, 064027
2021
-
[16]
2022,Proc
Jethani, N., Sudarshan, M., Covert, I., Lee, S.-I., & Ran- ganath, R. 2022,Proc. AISTATS, PMLR 151
2022
-
[17]
Vallisneri, M., et al. 2015,J. Phys.: Conf. Ser., 610, 012021
2015
-
[18]
M., et al
Macleod, D. M., et al. 2021,SoftwareX, 13, 100657
2021
-
[19]
1930,Exp
Butterworth, S. 1930,Exp. Wireless Wireless Eng., 7, 536
1930
-
[20]
S., et al
Park, D. S., et al. 2019,Proc. Interspeech, 2613
2019
-
[21]
2017,Proc
Lin, T.-Y ., Goyal, P., Girshick, R., He, K., & Dollár, P. 2017,Proc. ICCV, 2999
2017
-
[22]
& Walker, M
Davis, D. & Walker, M. 2021,Galaxies, 10, 12
2021
-
[23]
2019,Class
Cabero, M., et al. 2019,Class. Quant. Grav., 36, 155010
2019
-
[24]
Pedregosa, F., et al. 2011,J. Mach. Learn. Res., 12, 2825
2011
-
[25]
2016,Proc
He, K., Zhang, X., Ren, S., & Sun, J. 2016,Proc. CVPR, 770
2016
-
[26]
& Szegedy, C
Ioffe, S. & Szegedy, C. 2015,Proc. ICML, PMLR 37, 448
2015
-
[27]
2015,Proc
Tompson, J., Goroshin, R., Jain, A., LeCun, Y ., & Bregler, C. 2015,Proc. CVPR, 4060
2015
-
[28]
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. 2014,J. Mach. Learn. Res., 15, 1929
2014
-
[29]
Kingma, D. P. & Ba, J. 2015,Proc. ICLR 2015, arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[30]
2015,Proc
Ronneberger, O., Fischer, P., & Brox, T. 2015,Proc. MIC- CAI, LNCS 9351, 234
2015
-
[31]
Platt, J. C. 1999, inAdvances in Large Margin Classifiers, MIT Press, 61
1999
-
[32]
& Caruana, R
Niculescu-Mizil, A. & Caruana, R. 2005,Proc. ICML, 625
2005
-
[33]
Guo, C., Pleiss, G., Sun, Y ., & Weinberger, K. Q. 2017, Proc. ICML, PMLR 70, 1321
2017
-
[34]
A Horizon Study for Cosmic Explorer: Science, Observatories, and Community
Evans, M., et al. 2021, arXiv:2109.09882 [astro-ph.IM]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
B., Ohme, F., & Nitz, A
Schäfer, M. B., Ohme, F., & Nitz, A. H. 2020,Phys. Rev. D, 102, 063015
2020
-
[36]
2017,Phys
Messick, C., et al. 2017,Phys. Rev. D, 95, 042001
2017
-
[37]
2023,Phys
Nousi, P., et al. 2023,Phys. Rev. D, 108, 024022 9 Appendix A. Training Hyperparameters Table A.4: Training hyperparameters and model resource summary for CASPER. Parameter Value ResNet CNN Classifier Optimizer Adam [29] Initial learning rate 10 −4 Batch size 64 Max epochs 30 Early stopping Patience 8, monitor: val_auc LR reduction Patience 4, factor 0.5 ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.