Operator Boosting Produces Pareto-Efficient PDE Surrogates
Pith reviewed 2026-06-27 01:38 UTC · model grok-4.3
The pith
Operator Boosting builds compact neural PDE surrogates by adding tiny residual operators that often improve accuracy per parameter over full-size models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
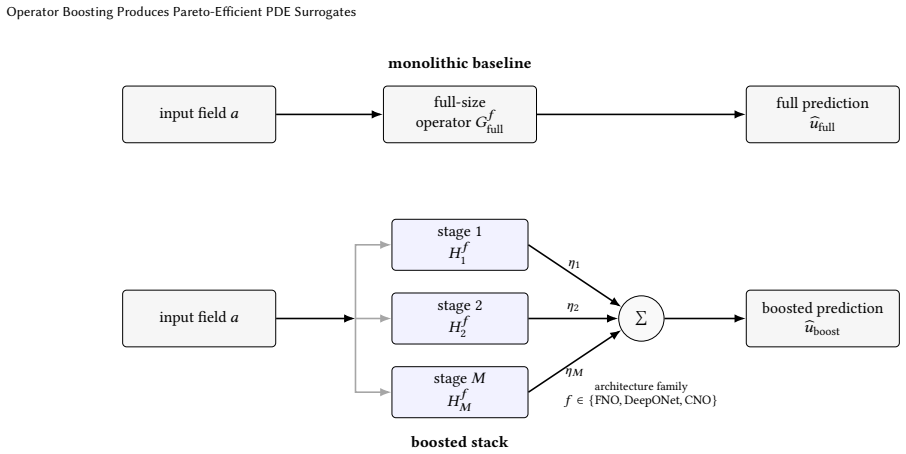
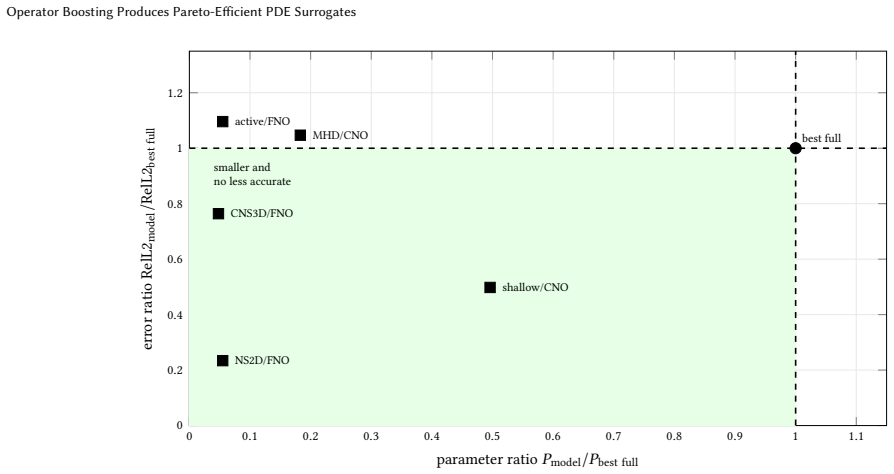
Operator Boosting produces Pareto-efficient PDE surrogates by training sequences of tiny same-family neural operators on residual fields after an initial mean predictor, with validation-selected shrinkage, yielding accuracy gains and 72-95% parameter reduction compared to full-size baselines on most tested benchmarks.
What carries the argument
Operator Boosting: stagewise residual-learning framework that trains tiny same-family neural operators on successive residual fields and applies validation-selected shrinkage for each correction.
If this is right
- Boosted stacks reduce trainable parameters by 72-95 percent across the tested cases.
- Positive mean accuracy gains appear in 21 of 30 dataset-architecture pairs, with 17 having positive confidence intervals.
- Empirical Pareto improvements occur on 7 of 10 completed PDE benchmarks including two-dimensional Navier-Stokes, shallow-water, Darcy flow, and three-dimensional compressible Navier-Stokes.
- The framework applies to FNOs, DeepONets, and CNOs.
- Some PDE- and architecture-dependent regimes exist where residual boosting fails to offset the compression.
Where Pith is reading between the lines
- The residual-boosting pattern could extend to other surrogate tasks that repeatedly evaluate a map, such as reduced-order modeling in engineering design loops.
- If the same-family tiny operators continue to capture residuals at larger scales, the method might reduce reliance on separate compression stages after training a large model.
- Testing the approach on time-dependent or chaotic PDEs outside the current benchmark set would clarify whether the Pareto gains persist when residuals become harder to approximate.
- The validation-selected shrinkage step suggests a general way to control capacity in any stagewise additive model for function approximation.
- keywords:[
Load-bearing premise
Residual errors after the mean predictor remain learnable by very small versions of the same neural operator family, and validation shrinkage reliably prevents overfitting or instability.
What would settle it
A new PDE or architecture where the boosted stack shows no accuracy gain over the mean predictor alone or produces worse accuracy-parameter trade-offs than a monolithic model of comparable size.
Figures
read the original abstract
Neural operators are widely used as surrogate solution maps for partial differential equations (PDEs), but full-size models can be costly to store, deploy, and evaluate in many-query scientific workflows. This work introduces Operator Boosting, a stagewise residual-learning framework for constructing compact neural-operator surrogates directly, rather than training a large model and compressing it afterward. Starting from the empirical mean predictor in normalized output coordinates, the method trains a sequence of tiny same-family neural operators on residual fields and incorporates each correction through validation-selected shrinkage. We instantiate the framework with Fourier neural operators (FNOs), DeepONets, and convolutional neural operators (CNOs), and compare boosted tiny stacks against full-size monolithic baselines across one-, two-, and three-dimensional PDE benchmarks from PDEBench, APEBench, and The Well. Across 30 dataset-architecture pairs, 21 show positive mean accuracy gains and 17 have positive confidence intervals, while all boosted stacks reduce trainable parameter count by approximately 72-95%. Best-model comparisons show empirical Pareto improvements on 7 of 10 completed PDE benchmarks, including two-dimensional Navier-Stokes, shallow-water dynamics, Darcy flow, one-dimensional transport and reaction systems, and three-dimensional compressible Navier-Stokes. These results show that Operator Boosting often improves the empirical accuracy-parameter Pareto frontier of neural PDE surrogates, while also exposing PDE- and architecture-dependent regimes where residual boosting fails to offset compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Operator Boosting, a stagewise residual-learning framework for constructing compact neural-operator surrogates for PDEs. Starting from the empirical mean predictor in normalized output coordinates, it trains a sequence of tiny same-family neural operators (FNO, DeepONet, CNO) on residual fields and incorporates corrections via validation-selected shrinkage. Across 30 dataset-architecture pairs on PDEBench, APEBench, and The Well benchmarks, it reports positive mean accuracy gains in 21 cases (positive CIs in 17), 72-95% parameter reductions, and empirical Pareto improvements on 7 of 10 completed benchmarks, while noting PDE- and architecture-dependent failure regimes.
Significance. If the empirical results are robust, the work provides a direct construction method for efficient neural PDE surrogates that improves the accuracy-parameter frontier without separate compression, which is useful for many-query scientific workflows. Explicitly identifying regimes where residual boosting fails to offset compression adds practical insight. The use of public benchmarks and multiple architectures is a strength.
major comments (2)
- [Abstract and §3 (stagewise procedure)] Abstract and experimental results: The reported positive gains (21/30) and Pareto improvements (7/10) depend on validation-selected shrinkage and the learnability of residuals by tiny same-family operators, but no ablation studies, sensitivity analysis on shrinkage factors, or verification that residuals remain approximable beyond initial stages are provided; this is load-bearing for the central claim that the method reliably improves the frontier.
- [Abstract] Abstract: The counts of positive gains and CIs are presented without details on error-bar methodology, handling of post-hoc choices, or data exclusions, preventing assessment of whether the 17/30 positive CIs and 7/10 Pareto results are affected by fitting procedures.
minor comments (1)
- [Abstract] The abstract could more explicitly state the typical number of boosting stages and the exact definition of the mean predictor in normalized coordinates.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the robustness of our empirical claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3 (stagewise procedure)] Abstract and experimental results: The reported positive gains (21/30) and Pareto improvements (7/10) depend on validation-selected shrinkage and the learnability of residuals by tiny same-family operators, but no ablation studies, sensitivity analysis on shrinkage factors, or verification that residuals remain approximable beyond initial stages are provided; this is load-bearing for the central claim that the method reliably improves the frontier.
Authors: We agree this is a substantive point. The manuscript reports aggregate performance but does not contain explicit ablations on the shrinkage factor or stage-wise verification that residuals stay approximable by the tiny operators. In revision we will add (i) a sensitivity study over shrinkage values and (ii) residual-norm or per-stage error curves demonstrating that later-stage residuals remain learnable on the tested benchmarks. revision: yes
-
Referee: [Abstract] Abstract: The counts of positive gains and CIs are presented without details on error-bar methodology, handling of post-hoc choices, or data exclusions, preventing assessment of whether the 17/30 positive CIs and 7/10 Pareto results are affected by fitting procedures.
Authors: We acknowledge the abstract omits these statistical details. The revised abstract will briefly state the CI construction method (bootstrap over independent runs) and note that no post-hoc exclusions were performed beyond the public benchmark train/validation/test splits. A full description of the error-bar procedure and any multiplicity considerations will be added to the experimental section. revision: yes
Circularity Check
No significant circularity; purely empirical comparisons on benchmarks
full rationale
The paper introduces Operator Boosting as a stagewise empirical procedure that trains tiny residual operators and applies validation-selected shrinkage, then reports accuracy and parameter-count comparisons against monolithic baselines across PDEBench, APEBench, and The Well. No derivation chain, uniqueness theorem, or first-principles result is presented that reduces by construction to the fitted inputs; all performance claims are direct experimental outcomes on held-out test data. Self-citations, if present, are not load-bearing for any central claim. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anima Anandkumar, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Nikola Kovachki, Zongyi Li, Burigede Liu, and Andrew Stuart. 2019. Neural Oper- ator: Graph Kernel Network for Partial Differential Equations. InICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations. https://openreview.net/forum?id=fg2ZFmXFO3
2019
-
[2]
Peter Benner, Serkan Gugercin, and Karen Willcox. 2015. A Survey of Projection- Based Model Reduction Methods for Parametric Dynamical Systems.SIAM Rev. 57, 4 (2015), 483–531. doi:10.1137/130932715
-
[3]
Leo Breiman. 1996. Bagging Predictors.Machine Learning24 (1996), 123–140. doi:10.1007/BF00058655
-
[4]
Peter Bühlmann and Bin Yu. 2003. Boosting with the 𝐿2 Loss: Regression and Classification.J. Amer. Statist. Assoc.98, 462 (2003), 324–339. doi:10.1198/ 016214503000125
2003
-
[5]
Hesthaven, Yvon Maday, and Jer’onimo Rodr’iguez
Yanlai Chen, Jan S. Hesthaven, Yvon Maday, and Jer’onimo Rodr’iguez. 2010. Certified Reduced Basis Methods and Output Bounds for the Harmonic Maxwell’s Equations.SIAM Journal on Scientific Computing32, 2 (2010), 970–996. doi:10. 1137/09075250X
2010
-
[6]
Jonathan Frankle and Michael Carbin. 2019. The Lottery Ticket Hypothesis: Find- ing Sparse, Trainable Neural Networks. InInternational Conference on Learning Representations. https://openreview.net/forum?id=rJl-b3RcF7
2019
-
[7]
Yoav Freund and Robert E. Schapire. 1997. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting.J. Comput. System Sci.55, 1 (1997), 119–139. doi:10.1006/jcss.1997.1504
-
[8]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton
Jerome H. Friedman. 2001. Greedy Function Approximation: A Gradient Boosting Machine.The Annals of Statistics29, 5 (Oct. 2001), 1189–1232. doi:10.1214/aos/ 1013203451
-
[9]
Jerome H. Friedman. 2002. Stochastic Gradient Boosting.Computational Statistics & Data Analysis38, 4 (2002), 367–378. doi:10.1016/S0167-9473(01)00065-2
-
[10]
Song Han, Huizi Mao, and William J. Dally. 2016. Deep Compression: Compress- ing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv:1510.00149 [cs.CV] https://arxiv.org/abs/1510.00149
Pith/arXiv arXiv 2016
-
[11]
L. K. Hansen and P. Salamon. 1990. Neural Network Ensembles.IEEE Transactions on Pattern Analysis and Machine Intelligence12, 10 (Oct. 1990), 993–1001. doi:10. 1109/34.58871
1990
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Resid- ual Learning for Image Recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 770–778. doi:10.1109/CVPR.2016.90
-
[13]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the Knowledge in a Neural Network. arXiv:1503.02531 [stat.ML] https://arxiv.org/abs/1503.02531
Pith/arXiv arXiv 2015
-
[14]
William Howes, Jason Yoo, Kazuma Kobayashi, Subhankar Sarkar, Farid Ahmed, Souvik Chakraborty, and Syed Bahauddin Alam. 2026. Real-Time Sensing of Inaccessible Physical Fields via an Edge-Deployable Hardware-Portable Graph Neural Operator. arXiv:2604.01802 [cs.LG] https://arxiv.org/abs/2604.01802
Pith/arXiv arXiv 2026
-
[15]
Felix Koehler, Simon Niedermayr, rüdiger westermann, and Nils Thuerey. 2024. APEBench: A Benchmark for Autoregressive Neural Emulators of PDEs. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview.net/forum?id=iWc0qE116u
2024
-
[16]
Jean Kossaifi, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, and Anima Anandkumar. 2024. Multi-Grid Tensorized Fourier Neural Operator for High- 8 Operator Boosting Produces Pareto-Efficient PDE Surrogates Resolution PDEs.Transactions on Machine Learning Research(2024). https: //openreview.net/forum?id=AWiDlO63bH
2024
-
[17]
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. 2023. Neural Operator: Learning Maps Between Function Spaces With Applications to PDEs.Journal of Machine Learning Research24, 89 (2023), 1–97. http://jmlr.org/papers/v24/21- 1524.html
2023
-
[18]
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. Sim- ple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles. In Proceedings of the 31st International Conference on Neural Information Processing Systems. Curran Associates Inc., 6405–6416
2017
-
[19]
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar
-
[20]
http: //jmlr.org/papers/v24/23-0064.html
Fourier Neural Operator with Learned Deformations for PDEs on General Geometries.Journal of Machine Learning Research24, 388 (2023), 1–26. http: //jmlr.org/papers/v24/23-0064.html
2023
-
[21]
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, An- drew Stuart, Kaushik Bhattacharya, and Anima Anandkumar. 2020. Multi- pole Graph Neural Operator for Parametric Partial Differential Equations. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ran- zato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33. Curran ...
2020
-
[22]
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. 2021. Fourier Neural Operator for Parametric Partial Differential Equations. InInternational Conference on Learning Representations. https://openreview.net/forum?id= c8P9NQVtmnO
2021
-
[23]
Jinming Lu, Jiayi Tian, Yequan Zhao, Hai Li, and Zheng Zhang. 2025. Tensor-Compressed and Fully-Quantized Training of Neural PDE Solvers. arXiv:2512.09202 [cs.LG] https://arxiv.org/abs/2512.09202
arXiv 2025
-
[24]
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karni- adakis. 2021. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence3 (2021), 218–
2021
-
[25]
doi:10.1038/s42256-021-00302-5
-
[26]
Llew Mason, Jonathan Baxter, Peter Bartlett, and Marcus Frean. 1999. Boosting Algorithms as Gradient Descent. InAdvances in Neural Information Processing Systems, Vol. 12. MIT Press. https://proceedings.neurips.cc/paper_files/paper/ 1999/file/96a93ba89a5b5c6c226e49b88973f46e-Paper.pdf
1999
-
[27]
Alexander Novikov, Dmitrii Podoprikhin, Anton Osokin, and Dmitry Vetrov
-
[28]
InAdvances in Neural Information Processing Systems, Vol
Tensorizing Neural Networks. InAdvances in Neural Information Processing Systems, Vol. 28. Curran Associates, Inc. https://proceedings.neurips.cc/paper_ files/paper/2015/file/6855456e2fe46a9d49d3d3af4f57443d-Paper.pdf
arXiv 2015
-
[29]
Agocs, Miguel Beneitez, Marsha Berger, Blakesley Burkhart, Stuart B
Ruben Ohana, Michael McCabe, Lucas Meyer, Rudy Morel, Fruzsina J. Agocs, Miguel Beneitez, Marsha Berger, Blakesley Burkhart, Stuart B. Dalziel, Drum- mond B. Fielding, Daniel Fortunato, Jared A. Goldberg, Keiya Hirashima, Yan-Fei Jiang, Rich R. Kerswell, Suryanarayana Maddu, Jonah Miller, Payel Mukhopad- hyay, Stefan S. Nixon, Jeff Shen, Romain Watteaux, ...
-
[30]
Shaoxiang Qin, Fuyuan Lyu, Wenhui Peng, Dingyang Geng, Ju Wang, Xing Tang, Sylvie Leroyer, Naiping Gao, Xue Liu, and Liangzhu Leon Wang. 2024. Toward a Better Understanding of Fourier Neural Operators from a Spectral Perspective. arXiv:2404.07200 [cs.LG] https://arxiv.org/abs/2404.07200
arXiv 2024
-
[31]
Bogdan Raonic, Roberto Molinaro, Tim De Ryck, Tobias Rohner, Francesca Bartolucci, Rima Alaifari, Siddhartha Mishra, and Emmanuel de Bezenac. 2023. Convolutional Neural Operators for robust and accurate learning of PDEs. In Thirty-seventh Conference on Neural Information Processing Systems. https: //openreview.net/forum?id=MtekhXRP4h
2023
-
[32]
Lennon Shikhman. 2026. Diagnosing Failure Modes of Neural Operators Across Diverse PDE Families.Transactions on Machine Learning Research(2026). https: //openreview.net/forum?id=0S1LWZHQYn
2026
-
[33]
Lennon Shikhman. 2026. One Operator to Rule Them All? On Boundary-Indexed Operator Families in Neural PDE Solvers. InAI&PDE: ICLR 2026 Workshop on AI and Partial Differential Equations. https://openreview.net/forum?id= lDjWQ9UxRy
2026
-
[34]
Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Daniel MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. 2022. PDEBench: An Extensive Benchmark for Scientific Machine Learning. InAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agar- wal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, I...
2022
-
[35]
Alasdair Tran, Alexander Mathews, Lexing Xie, and Cheng Soon Ong. 2023. Factorized Fourier Neural Operators. InThe Eleventh International Conference on Learning Representations. https://openreview.net/forum?id=tmIiMPl4IPa
2023
-
[36]
Renbo Tu, Colin White, Jean Kossaifi, Boris Bonev, Gennady Pekhimenko, Kam- yar Azizzadenesheli, and Anima Anandkumar. 2024. Guaranteed Approxima- tion Bounds for Mixed-Precision Neural Operators. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id= QJGj07PD9C
2024
-
[37]
Tong Zhang and Bin Yu. 2005. Boosting with Early Stopping: Convergence and Consistency.The Annals of Statistics33, 4 (Aug. 2005), 1538–1579. doi:10.1214/ 009053605000000255 9 Lennon J. Shikhman A Operator Boosting Pseudo-code Algorithm 1 summarizes the training procedure for a fixed operator family𝑓. Algorithm 1Operator Boosting Require: Training set Dtr,...
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.