Dynamic Rollout Editing for Reducing Overthinking in RL-Trained Reasoning Models
Pith reviewed 2026-06-27 01:16 UTC · model grok-4.3
The pith
Editing successful trajectories during GRPO training breaks the feedback loop that amplifies overthinking in reasoning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
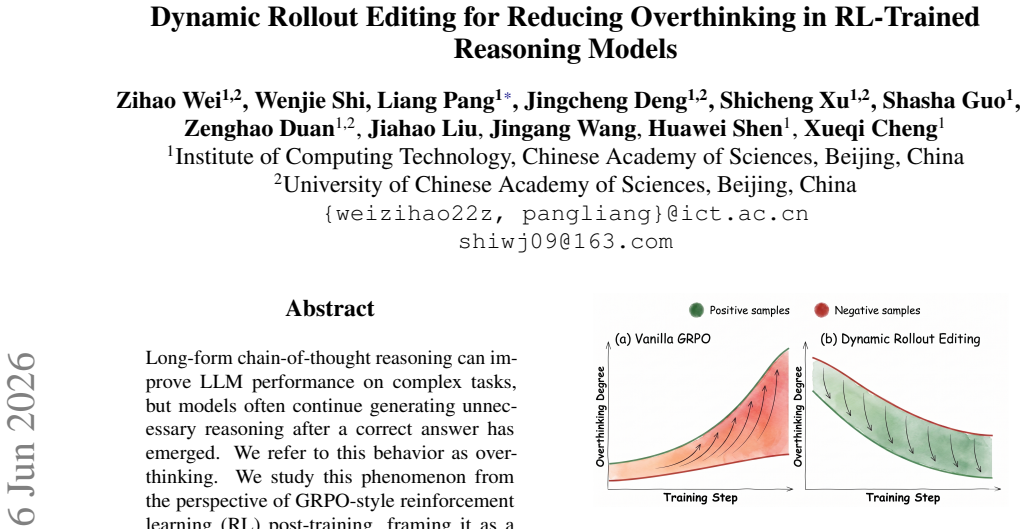
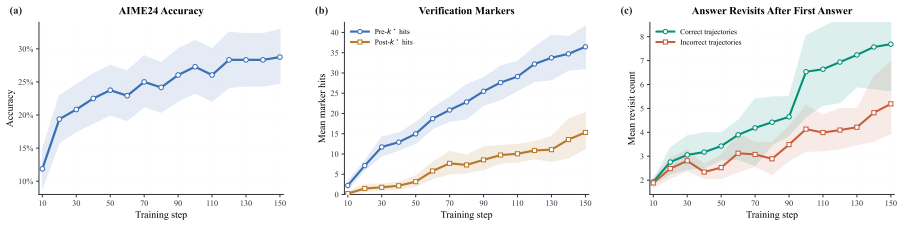
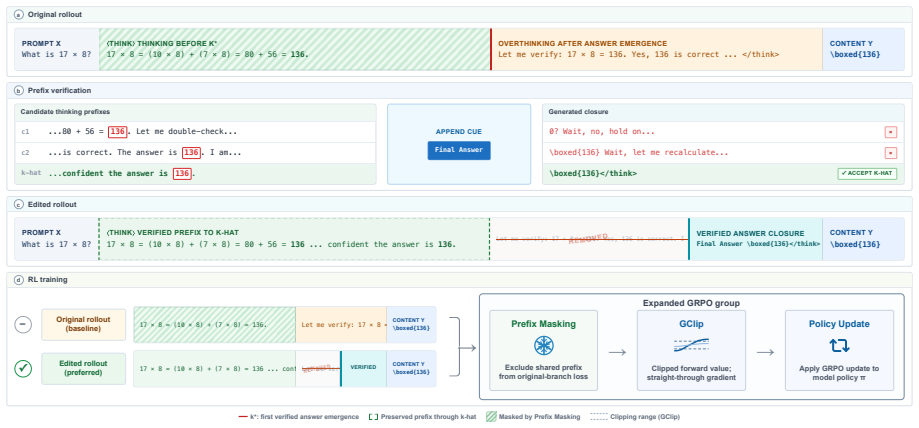
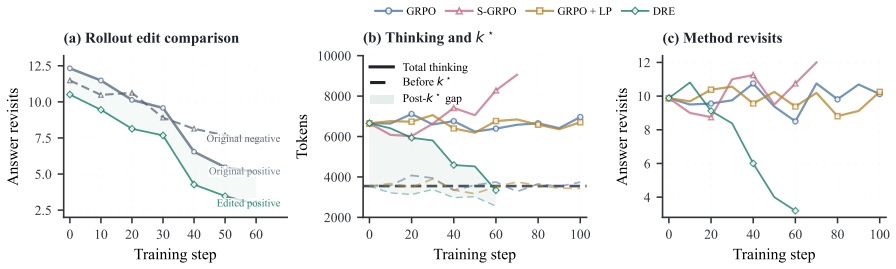
In rollouts sampled at the onset of GRPO training, successful trajectories exhibit a slightly higher degree of overthinking than unsuccessful trajectories for the same prompts. Because GRPO assigns credit at the full-sequence level, both the solution-reaching prefix and the unnecessary continuation receive positive update signal, allowing the initial imbalance to grow into more severe overthinking. Dynamic Rollout Editing preserves the accepted verified prefix, edits the remaining thinking, and prefers the edited trajectory within the same RL group, weakening the preference signal for unnecessary thinking without penalizing the reasoning needed to reach the answer.
What carries the argument
Dynamic Rollout Editing (DRE), which preserves the verified prefix of a successful trajectory, edits the post-answer continuation, and substitutes the edited version when forming preferences inside each RL group.
If this is right
- Training with DRE produces models whose generated chains of thought contain less unnecessary reasoning after the answer has emerged.
- Task performance stays comparable because the solution-reaching prefix remains unchanged and still receives reinforcement.
- The early imbalance between successful and unsuccessful trajectories no longer grows into larger overthinking during later training steps.
- The intervention works across multiple tasks without altering the underlying GRPO update rule.
Where Pith is reading between the lines
- If the early imbalance is the main driver, similar prefix-preserving edits could be tested on other sequence-level RL algorithms that assign credit to full trajectories.
- Shorter output lengths at inference time would reduce both latency and compute cost for deployed reasoning models.
- DRE might combine with existing decoding-time stopping rules to produce additive reductions in overthinking.
Load-bearing premise
Successful trajectories already contain slightly more overthinking than unsuccessful ones at the start of GRPO training, supplying the seed for an amplifying feedback loop.
What would settle it
Running standard GRPO training and measuring that the degree of overthinking does not increase across training steps, or running DRE and finding no measurable drop in overthinking relative to the baseline.
Figures
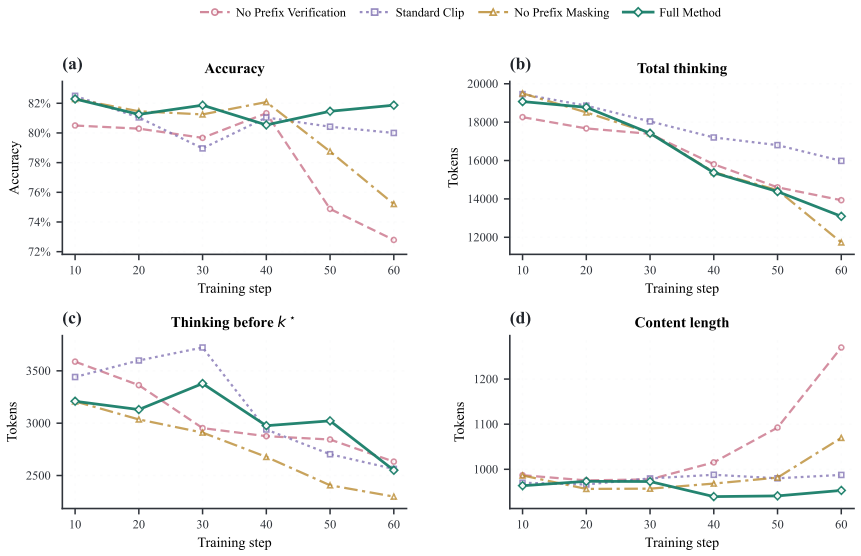
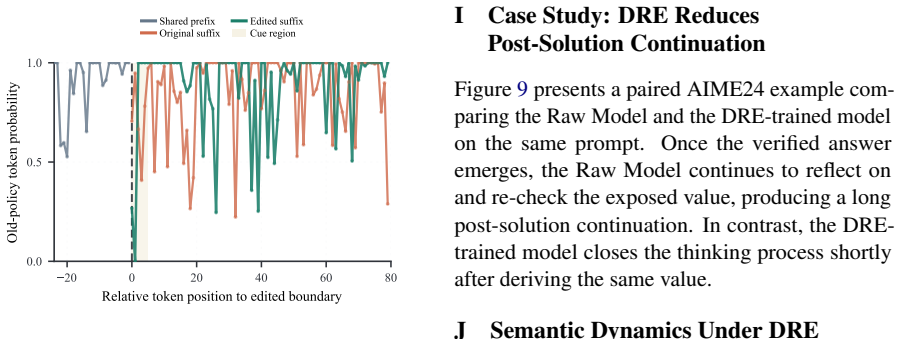



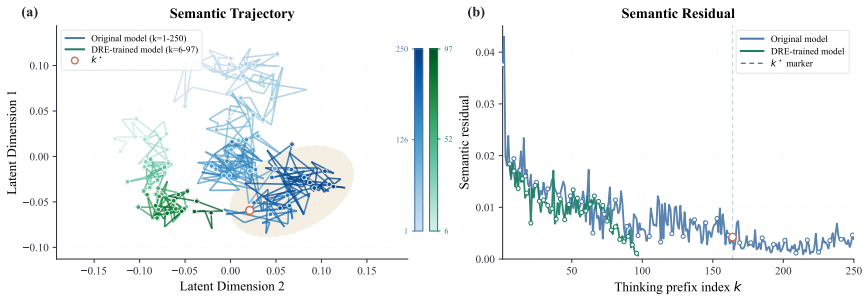
read the original abstract
Long-form chain-of-thought reasoning can improve LLM performance on complex tasks, but models often continue generating unnecessary reasoning after a correct answer has emerged. We refer to this behavior as overthinking. We study this phenomenon from the perspective of GRPO-style reinforcement learning (RL) post-training, framing it as a training-time credit-assignment problem rather than merely a decoding-time stopping problem. In rollouts sampled at the onset of GRPO training, we observe that successful trajectories can exhibit a slightly higher degree of overthinking than unsuccessful trajectories for the same prompts. This early imbalance provides a starting point for an undesirable feedback loop: because GRPO assigns sequence-level credit, it cannot distinguish the solution-reaching prefix from the unnecessary continuation that lengthens a successful trajectory. Both receive positive update signal, allowing the initial imbalance to grow into more severe overthinking during training. To address this issue, we introduce Dynamic Rollout Editing (DRE), a training-time intervention for successful trajectories that continue thinking after answer emergence. DRE preserves the accepted verified prefix, edits the remaining thinking, and prefers the edited trajectory within the same RL group, weakening the preference signal for unnecessary thinking without penalizing the reasoning needed to reach the answer. Experiments across diverse tasks show the effectiveness of DRE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper observes that at the onset of GRPO training, successful trajectories exhibit a slightly higher degree of overthinking than unsuccessful ones for the same prompts. This early imbalance is argued to initiate an undesirable feedback loop because GRPO's sequence-level credit assignment cannot separate the solution-reaching prefix from unnecessary post-answer continuation. The authors propose Dynamic Rollout Editing (DRE), which preserves the verified prefix of successful trajectories, edits the remaining thinking, and prefers the edited trajectory within the same RL group to weaken the preference signal for overthinking. Experiments across diverse tasks are claimed to demonstrate DRE's effectiveness.
Significance. If the initial imbalance is empirically confirmed and DRE reliably reduces overthinking without degrading answer quality, the approach would supply a training-time mechanism to counteract a specific credit-assignment pathology in sequence-level RL methods such as GRPO, potentially improving the efficiency of reasoning-model post-training.
major comments (3)
- [Abstract] Abstract: the central empirical premise that 'successful trajectories can exhibit a slightly higher degree of overthinking than unsuccessful trajectories' is stated only qualitatively, with no definition of overthinking, no token-count or length metrics, no statistical tests, no prompt counts, and no variance across tasks. This observation is load-bearing for the claimed feedback loop and the motivation for DRE.
- [Abstract] Abstract: no implementation details are supplied for the DRE procedure itself, including how the 'accepted verified prefix' is identified at training time, what concrete editing operation is applied to the post-answer segment, or how the edited trajectory is inserted and preferred inside the GRPO group.
- [Abstract] Abstract: the statement that 'experiments across diverse tasks show the effectiveness of DRE' is unsupported by any reported results, tables, baselines, ablations, or error analysis, so the data support for the central claim cannot be assessed.
minor comments (1)
- The manuscript would benefit from an explicit algorithmic description or pseudocode for the editing and preference steps in DRE.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on the abstract. We agree that the abstract is highly condensed and will revise it to incorporate a concise definition and metric reference for the initial observation, a brief outline of the DRE procedure, and key quantitative experimental highlights. This addresses the concerns while preserving the abstract's brevity. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical premise that 'successful trajectories can exhibit a slightly higher degree of overthinking than unsuccessful trajectories' is stated only qualitatively, with no definition of overthinking, no token-count or length metrics, no statistical tests, no prompt counts, and no variance across tasks. This observation is load-bearing for the claimed feedback loop and the motivation for DRE.
Authors: We agree the abstract states the premise qualitatively. The manuscript defines overthinking explicitly as post-answer continuation after a verified correct answer, measures it via token count of the post-answer segment, and reports the slight increase (with prompt counts and task variance) in the analysis of initial rollouts. To improve self-containment we will revise the abstract to include a one-sentence definition plus mention of the token metric. revision: yes
-
Referee: [Abstract] Abstract: no implementation details are supplied for the DRE procedure itself, including how the 'accepted verified prefix' is identified at training time, what concrete editing operation is applied to the post-answer segment, or how the edited trajectory is inserted and preferred inside the GRPO group.
Authors: The full manuscript details these steps in the method section: the verified prefix is the initial segment up to the first correct answer (identified via verification), the editing operation truncates or replaces the post-answer continuation with a short neutral token sequence, and the edited rollout is inserted into the same GRPO group with an adjusted advantage that weakens the signal for overthinking. We will add a compact description of these three elements to the abstract. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'experiments across diverse tasks show the effectiveness of DRE' is unsupported by any reported results, tables, baselines, ablations, or error analysis, so the data support for the central claim cannot be assessed.
Authors: The abstract summarizes the outcome; the manuscript contains the supporting tables, baselines (standard GRPO), ablations on editing variants, and per-task metrics showing reduced overthinking tokens with no degradation in final accuracy. We will revise the abstract to include one or two representative quantitative results (e.g., average token reduction) to make the claim more concrete. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper describes an empirical observation of early-training overthinking imbalance in GRPO rollouts and introduces DRE as a direct intervention that edits post-answer segments while preserving verified prefixes. No equations, fitted parameters, or self-citations are shown to reduce the central claim or method to a tautology by construction. The motivation rests on a stated qualitative observation rather than a derived result that loops back to itself, and the editing procedure is presented as an independent training-time modification without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GRPO assigns sequence-level credit that cannot distinguish the solution-reaching prefix from the unnecessary continuation
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.12948 , eprinttype =. 2501.12948 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[2]
Nature , volume =
Guo, Daya and Yang, Dejian and Zhang, Haowei and others , title =. Nature , volume =. 2025 , doi =
2025
-
[3]
Aaron Jaech and Adam Kalai and Adam Lerer and Adam Richardson and others , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.16720 , eprinttype =. 2412.16720 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.16720 2024
-
[4]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and...
-
[5]
2025 , month =
Gemini 3 Pro Model Card , author =. 2025 , month =
2025
-
[6]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Qiyuan Zhang and Fuyuan Lyu and Zexu Sun and Lei Wang and Weixu Zhang and Zhihan Guo and Yufei Wang and Irwin King and Xue Liu and Chen Ma , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.24235 , eprinttype =. 2503.24235 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.24235 2025
-
[7]
From System 1 to System 2: A Survey of Reasoning Large Language Models
Zhong. From System 1 to System 2:. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.17419 , eprinttype =. 2502.17419 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.17419 2025
-
[8]
Stop Overthinking:
Yang Sui and Yu. Stop Overthinking:. Trans. Mach. Learn. Res. , volume =. 2025 , url =
2025
-
[9]
Harnessing the Reasoning Economy:
Rui Wang and Hongru Wang and Boyang Xue and Jianhui Pang and Shudong Liu and Yi Chen and Jiahao Qiu and Derek Fai Wong and Heng Ji and Kam. Harnessing the Reasoning Economy:. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.24377 , eprinttype =. 2503.24377 , timestamp =
-
[10]
Ping Yu and Jing Xu and Jason Weston and Ilia Kulikov , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.06023 , eprinttype =. 2407.06023 , timestamp =
-
[11]
Yu Kang and Xianghui Sun and Liangyu Chen and Wei Zou , editor =. AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA,. 2025 , url =. doi:10.1609/AAAI.V39I23.34608 , timestamp =
-
[12]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
Heming Xia and Chak Tou Leong and Wenjie Wang and Yongqi Li and Wenjie Li , title =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
2025
-
[13]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
Xinyin Ma and Guangnian Wan and Runpeng Yu and Gongfan Fang and Xinchao Wang , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[14]
Can Language Models Learn to Skip Steps? , booktitle =
Tengxiao Liu and Qipeng Guo and Xiangkun Hu and Cheng Jiayang and Yue Zhang and Xipeng Qiu and Zheng Zhang , editor =. Can Language Models Learn to Skip Steps? , booktitle =. 2024 , url =
2024
-
[15]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.12599 , eprinttype =. 2501.12599 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12599 2025
-
[16]
Haotian Luo and Li Shen and Haiying He and Yibo Wang and Shiwei Liu and Wei Li and Naiqiang Tan and Xiaochun Cao and Dacheng Tao , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.12570 , eprinttype =. 2501.12570 , timestamp =
-
[17]
Second Conference on Language Modeling , year =
Pranjal Aggarwal and Sean Welleck , title =. Second Conference on Language Modeling , year =
-
[18]
Weston and Yuandong Tian , title =
Shibo Hao and Sainbayar Sukhbaatar and DiJia Su and Xian Li and Zhiting Hu and Jason E. Weston and Yuandong Tian , title =. Second Conference on Language Modeling , year =
-
[19]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
Zhenyi Shen and Hanqi Yan and Linhai Zhang and Zhanghao Hu and Yali Du and Yulan He , title =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
2025
-
[20]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Jeffrey Cheng and Benjamin Van Durme , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.13171 , eprinttype =. 2412.13171 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.13171 2024
-
[21]
Niklas Muennighoff and Zitong Yang and Weijia Shi and Xiang Lisa Li and Li Fei. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.19393 , eprinttype =. 2501.19393 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.19393 2025
-
[22]
Token-Budget-Aware LLM Reasoning
Tingxu Han and Zhenting Wang and Chunrong Fang and Shiyu Zhao and Shiqing Ma and Zhenyu Chen , booktitle =. Token-Budget-Aware. 2025 , address =. doi:10.18653/v1/2025.findings-acl.1274 , pages =
-
[23]
Ayeong Lee and Ethan Che and Tianyi Peng , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.01141 , eprinttype =. 2503.01141 , timestamp =
-
[24]
Wenjie Ma and Jingxuan He and Charlie Snell and Tyler Griggs and Sewon Min and Matei Zaharia , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.09858 , eprinttype =. 2504.09858 , timestamp =
-
[25]
ICLR 2025 Workshop on Foundation Models in the Wild , year=
Reasoning Without Self-Doubt: More Efficient Chain-of-Thought Through Certainty Probing , author=. ICLR 2025 Workshop on Foundation Models in the Wild , year=
2025
-
[26]
Runjin Chen and Zhenyu Zhang and Junyuan Hong and Souvik Kundu and Zhangyang Wang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.07986 , eprinttype =. 2504.07986 , timestamp =
-
[27]
The Fourteenth International Conference on Learning Representations,
Chenxu Yang and Qingyi Si and Yongjie Duan and Zheliang Zhu and Chenyu Zhu and Qiaowei Li and Minghui Chen and Zheng Lin and Weiping Wang , title =. The Fourteenth International Conference on Learning Representations,. 2026 , url =
2026
-
[28]
2025 , eprint=
Inverse Scaling in Test-Time Compute , author=. 2025 , eprint=
2025
-
[29]
The Fourteenth International Conference on Learning Representations,
Yuyang Wu and Yifei Wang and Ziyu Ye and Tianqi Du and Stefanie Jegelka and Yisen Wang , title =. The Fourteenth International Conference on Learning Representations,. 2026 , url =
2026
-
[30]
Xin Liu and Lu Wang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.02536 , eprinttype =. 2506.02536 , timestamp =
-
[31]
Advances in Neural Information Processing Systems , volume=
S-grpo: Early exit via reinforcement learning in reasoning models , author =. Advances in Neural Information Processing Systems , volume=
-
[32]
Does Your Reasoning Model Implicitly Know When to Stop Thinking?
Zixuan Huang and Xin Xia and Yuxi Ren and Jianbin Zheng and Xuanda Wang and Zhixia Zhang and Hongyan Xie and Songshi Liang and Zehao Chen and Xuefeng Xiao and Fuzhen Zhuang and Jianxin Li and Yikun Ban and Deqing Wang , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2602.08354 , eprinttype =. 2602.08354 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.08354 2026
-
[33]
Zilin Xiao and Jaywon Koo and Siru Ouyang and Jefferson Hernandez and Yu Meng and Vicente Ordonez , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.24872 , eprinttype =. 2505.24872 , timestamp =
-
[34]
Shicheng Xu and Liang Pang and Yunchang Zhu and Jia Gu and Zihao Wei and Jingcheng Deng and Feiyang Pan and Huawei Shen and Xueqi Cheng , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.16142 , eprinttype =. 2505.16142 , timestamp =
-
[35]
2025 , eprint=
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models , author=. 2025 , eprint=
2025
-
[36]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2408.03314 , eprinttype =. 2408.03314 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.03314 2024
-
[37]
Forty-second International Conference on Machine Learning,
Xingyu Chen and Jiahao Xu and Tian Liang and Zhiwei He and Jianhui Pang and Dian Yu and Linfeng Song and Qiuzhi Liu and Mengfei Zhou and Zhuosheng Zhang and Rui Wang and Zhaopeng Tu and Haitao Mi and Dong Yu , title =. Forty-second International Conference on Machine Learning,. 2025 , url =
2025
-
[38]
Alejandro Cuadron and Dacheng Li and Wenjie Ma and Xingyao Wang and Yichuan Wang and Siyuan Zhuang and Shu Liu and Luis Gaspar Schroeder and Tian Xia and Huanzhi Mao and Nicholas Thumiger and Aditya Desai and Ion Stoica and Ana Klimovic and Graham Neubig and Joseph E. Gonzalez , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.08235 , eprin...
-
[39]
Bowman , booktitle =
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle =. 2024 , url =
2024
-
[40]
The Thirteenth International Conference on Learning Representations,
Naman Jain and King Han and Alex Gu and Wen. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[41]
Anna Veronika Dorogush and Vasily Ershov and Andrey Gulin , title =. CoRR , volume =. 2018 , url =. 1810.11363 , timestamp =
Pith/arXiv arXiv 2018
-
[42]
Keqin Peng and Liang Ding and Yuanxin Ouyang and Meng Fang and Dacheng Tao , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.23480 , eprinttype =. 2505.23480 , timestamp =
-
[43]
Anqi Zhang and Yulin Chen and Jane Pan and Chen Zhao and Aurojit Panda and Jinyang Li and He He , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.05419 , eprinttype =. 2504.05419 , timestamp =
-
[44]
Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Barcelona, Spain, July 21-26, 2004 - Poster and Demonstration , publisher =
Steven Bird and Edward Loper , title =. Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Barcelona, Spain, July 21-26, 2004 - Poster and Demonstration , publisher =. 2004 , url =
2004
-
[45]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang and Mingxin Li and Dingkun Long and Xin Zhang and Huan Lin and Baosong Yang and Pengjun Xie and An Yang and Dayiheng Liu and Junyang Lin and Fei Huang and Jingren Zhou , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.05176 , eprinttype =. 2506.05176 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[46]
Answer Convergence as a Signal for Early Stopping in Reasoning
Liu, Xin and Wang, Lu. Answer Convergence as a Signal for Early Stopping in Reasoning. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.904
-
[47]
Renliang Sun and Wei Cheng and Dawei Li and Haifeng Chen and Wei Wang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.10103 , eprinttype =. 2510.10103 , timestamp =
-
[48]
Xiao Pu and Michael Saxon and Wenyue Hua and William Yang Wang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.13367 , eprinttype =. 2504.13367 , timestamp =
-
[49]
Introducing. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.18883 , eprinttype =. 2509.18883 , timestamp =
-
[50]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Jiameng Huang and Baijiong Lin and Guhao Feng and Jierun Chen and Di He and Lu Hou , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2026 , url =
2026
-
[51]
Advances in Neural Information Processing Systems , volume =
Does Thinking More Always Help? Mirage of Test-Time Scaling in Reasoning Models , author =. Advances in Neural Information Processing Systems , volume =. 2025 , url =
2025
-
[52]
The Fourteenth International Conference on Learning Representations,
Jinyi Han and Ying Huang and Ying Liao and Haiquan Zhao and Zishang Jiang and Xinyi Wang and Xikun Lu and Guanghao Zhou and Sihang Jiang and Jiaqing Liang and Weikang Zhou and Zeye Sun and Fei Yu and Yanghua Xiao , title =. The Fourteenth International Conference on Learning Representations,. 2026 , url =
2026
-
[53]
Jinyan Su and Jennifer Healey and Preslav Nakov and Claire Cardie , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.00127 , eprinttype =. 2505.00127 , timestamp =
-
[54]
Zihao Wei and Liang Pang and Jiahao Liu and Wenjie Shi and Jingcheng Deng and Shicheng Xu and Zenghao Duan and Fei Sun and Huawei Shen and Xueqi Cheng , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.17627 , eprinttype =
-
[55]
Melody Zixuan Li and Kumar Krishna Agrawal and Arna Ghosh and Komal Kumar Teru and Adam Santoro and Guillaume Lajoie and Blake A. Richards , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.23024 , eprinttype =. 2509.23024 , timestamp =
-
[56]
Dongkyu Cho and Amy B. Z. Zhang and Bilel Fehri and Sheng Wang and Rumi Chunara and Rui Song and Hengrui Cai , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.21549 , eprinttype =. 2509.21549 , timestamp =
-
[57]
Yufa Zhou and Yixiao Wang and Xunjian Yin and Shuyan Zhou and Anru R. Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.09782 , eprinttype =. 2510.09782 , timestamp =
-
[58]
arXiv preprint arXiv:2305.20050 , year=
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
-
[59]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.03300 , eprinttype =. 2402.03300 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[60]
Advances in Neural Information Processing Systems , volume =
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and Yu Yue and Weinan Dai and Tiantian Fan and Gaohong Liu and Juncai Liu and Lingjun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and Jiangjie Che...
2025
-
[61]
Bairu Hou and Yang Zhang and Jiabao Ji and Yujian Liu and Kaizhi Qian and Jacob Andreas and Shiyu Chang , title =. Trans. Mach. Learn. Res. , volume =. 2026 , url =
2026
-
[62]
Advances in Neural Information Processing Systems , volume =
Siye Wu and Jian Xie and Yikai Zhang and Aili Chen and Kai Zhang and Yu Su and Yanghua Xiao , title =. Advances in Neural Information Processing Systems , volume =. 2025 , url =
2025
-
[63]
Rubing Yang and Huajun Bai and Song Liu and Guanghua Yu and Runzhi Fan and Yanbin Dang and Jiejing Zhang and Kai Liu and Jianchen Zhu and Peng Chen , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.24248 , eprinttype =. 2509.24248 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.