LAGO Policy: Latency-Aware Asynchronous Diffusion Policies with Goal-Directed Collision-Free Planning for Smooth Manipulation
Pith reviewed 2026-06-27 00:44 UTC · model grok-4.3
The pith
LAGO Policy adds latency-aware guidance, goal prediction from demonstrations, and spatial-temporal optimization to diffusion policies to fix discontinuities and collisions in asynchronous robot control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
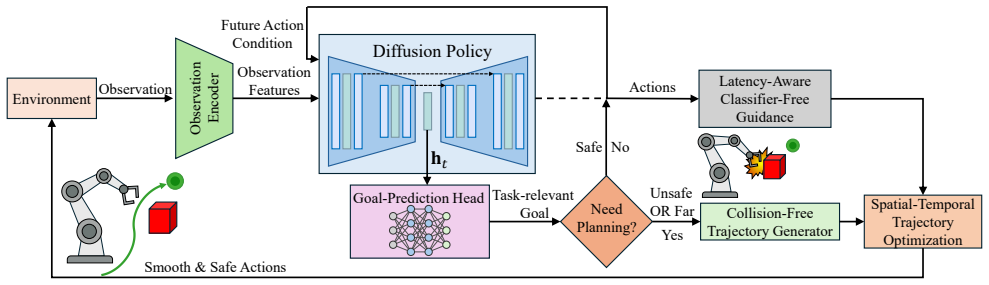
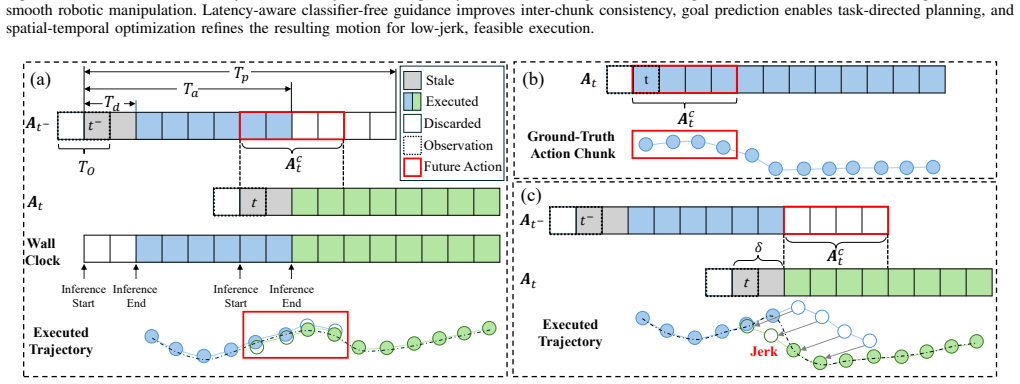
LAGO Policy is a unified asynchronous action-generation framework that integrates trajectory optimization with diffusion policy. It improves inter-chunk consistency via latency-aware classifier-free guidance conditioning on future actions, enables goal-directed collision-free trajectory planning by predicting a task-relevant interaction goal from demonstrations, and applies spatial-temporal trajectory optimization to refine actions for low-jerk and feasible motion.
What carries the argument
LAGO Policy framework that combines latency-aware classifier-free guidance, demonstration-based goal prediction, and spatial-temporal trajectory optimization to enforce consistency and safety in asynchronous diffusion outputs.
If this is right
- Inter-chunk discontinuities are reduced by conditioning on future actions through latency-aware guidance.
- Goal prediction from demonstrations supplies an explicit target for collision-free planning.
- Spatial-temporal optimization converts the conditioned diffusion output into low-jerk feasible motion.
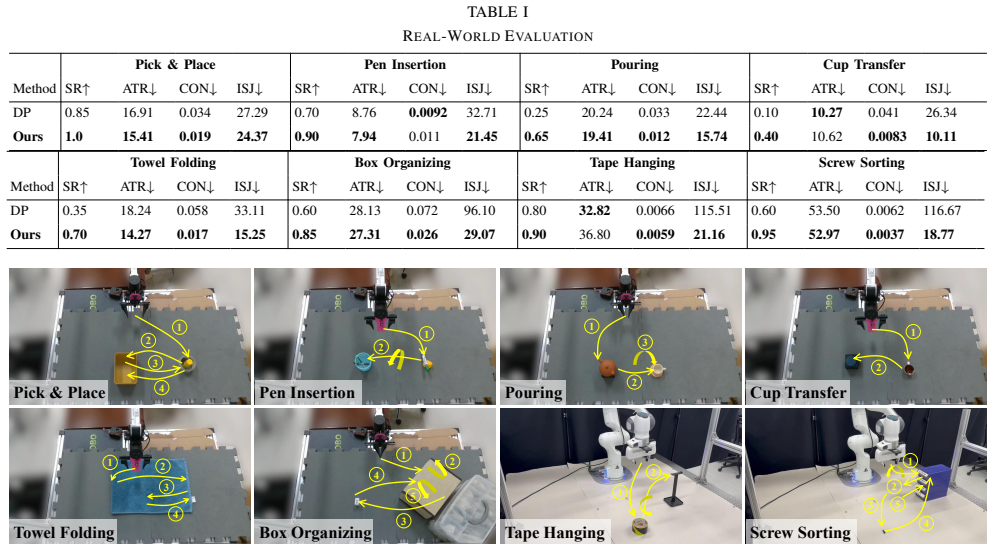
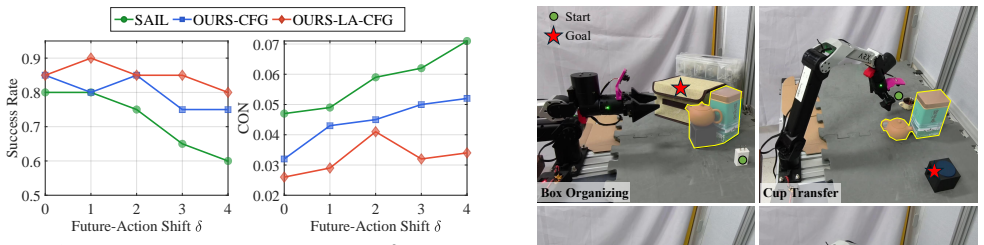
- High task success rates are observed across challenging real-world manipulation tasks.
Where Pith is reading between the lines
- The same conditioning-plus-optimization pattern could be tested on non-diffusion asynchronous controllers to isolate whether the benefit is specific to diffusion models.
- If goal prediction proves stable across scene variations, the method might reduce reliance on real-time depth sensing for basic avoidance.
- A direct next measurement would be the reduction in peak jerk and collision rate when the optimization stage is ablated while keeping the guidance and goal components fixed.
Load-bearing premise
Predicting a task-relevant interaction goal from demonstrations together with latency-aware conditioning and trajectory optimization will reliably produce collision-free feasible motions without introducing new discontinuities or failures in real-world scenes.
What would settle it
A real-world trial in which the predicted goal leads the optimized trajectory into an unmodeled obstacle or produces visible jerk at chunk boundaries would falsify the claim of reliable smooth collision-free execution.
Figures




read the original abstract
Diffusion-based visuomotor policies deployed with asynchronous inference often exhibit inter-chunk discontinuities and lack explicit mechanisms for obstacle-aware execution, leading to jerky motions and collisions that hinder reliable manipulation in real-world scenes. To address these issues, we propose LAGO Policy, a unified asynchronous action-generation framework that integrates trajectory optimization with diffusion policy for smooth and safe execution. LAGO Policy improves inter-chunk consistency via latency-aware classifier-free guidance conditioning on future actions. It further enables goal-directed collision-free trajectory planning by predicting a task-relevant interaction goal from demonstrations. Finally, spatial-temporal trajectory optimization refines the actions to be executed for low-jerk and feasible motion. Extensive real-world experiments demonstrate that LAGO Policy achieves smooth collision-free execution with high task success across challenging manipulation tasks. Project Website: https://lago-policy.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LAGO Policy, an asynchronous diffusion-based visuomotor policy framework that combines latency-aware classifier-free guidance conditioning on future actions, prediction of a task-relevant interaction goal from demonstrations, and spatial-temporal trajectory optimization to produce smooth, collision-free, low-jerk motions. The central claim is that this unified approach resolves inter-chunk discontinuities and obstacle-unaware execution in real-world robotic manipulation, with extensive experiments demonstrating high task success across challenging tasks.
Significance. If the experimental results and component contributions hold under scrutiny, the integration of goal-directed planning with diffusion policies could meaningfully advance reliable deployment of visuomotor policies by addressing smoothness and safety, a persistent barrier in real-robot applications.
major comments (3)
- [Abstract] Abstract: the claim that 'extensive real-world experiments demonstrate... high task success' provides no quantitative metrics, baselines, error bars, success rates, or statistical details, so the central empirical claim cannot be evaluated.
- [Method (trajectory optimization)] The manuscript provides no formulation (objective, constraints, or solver) for the spatial-temporal trajectory optimization step, which is load-bearing for the collision-free and low-jerk guarantees when scenes deviate from the demonstration distribution.
- [Method (goal prediction)] No description is given of the goal predictor (representation, training loss, or architecture), nor any ablation isolating its contribution versus the diffusion policy alone; this directly affects the generalization claim in the skeptic's weakest assumption.
minor comments (1)
- [Abstract] The abstract references a project website but does not indicate whether videos, code, or additional quantitative results are available there to support the claims.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'extensive real-world experiments demonstrate... high task success' provides no quantitative metrics, baselines, error bars, success rates, or statistical details, so the central empirical claim cannot be evaluated.
Authors: We agree that the abstract would be strengthened by including quantitative metrics. In the revised version we will update the abstract to report key results such as task success rates, baseline comparisons, and any available statistical details from the real-world experiments. revision: yes
-
Referee: [Method (trajectory optimization)] The manuscript provides no formulation (objective, constraints, or solver) for the spatial-temporal trajectory optimization step, which is load-bearing for the collision-free and low-jerk guarantees when scenes deviate from the demonstration distribution.
Authors: The referee correctly identifies that the explicit mathematical formulation (objective, constraints, and solver) of the spatial-temporal trajectory optimization is not provided. We will add the complete formulation to the method section in the revision to clarify how collision-free and low-jerk execution is achieved. revision: yes
-
Referee: [Method (goal prediction)] No description is given of the goal predictor (representation, training loss, or architecture), nor any ablation isolating its contribution versus the diffusion policy alone; this directly affects the generalization claim in the skeptic's weakest assumption.
Authors: We acknowledge that the goal predictor's representation, training loss, architecture, and an isolating ablation are not described. We will add these details along with an ablation study in the revised manuscript to support the generalization claims. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper proposes LAGO Policy as a framework integrating diffusion policies with latency-aware guidance, goal prediction from demonstrations, and spatial-temporal trajectory optimization. No equations, first-principles derivations, fitted parameters presented as predictions, or self-citation load-bearing uniqueness theorems appear in the abstract or method description. Claims rest on real-world experimental results rather than any reduction of outputs to inputs by construction, so the approach is self-contained with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhaoet al., “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,”arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
C. Panet al., “Much Ado About Noising: Dispelling the Myths of Generative Robotic Control,”arXiv preprint arXiv:2512.01809, 2026
-
[3]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Y . Zeet al., “3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations,”arXiv preprint arXiv:2403.03954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Hierarchical Diffusion Policy: Manipulation Tra- jectory Generation via Contact Guidance,
D. Wanget al., “Hierarchical Diffusion Policy: Manipulation Tra- jectory Generation via Contact Guidance,”IEEE Transactions on Robotics, vol. 41, pp. 2086–2104, 2025
2086
-
[5]
Fast Policy Synthesis with Vari- able Noise Diffusion Models,
S. H. Høeg, Y . Du, and O. Egeland, “Fast Policy Synthesis with Vari- able Noise Diffusion Models,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 4821–4828
2025
-
[6]
SAIL: Faster-than-Demonstration Execution of Imitation Learning Policies,
N. R. Arachchigeet al., “SAIL: Faster-than-Demonstration Execution of Imitation Learning Policies,” inConference on Robot Learning. PMLR, 2025, pp. 721–749
2025
-
[7]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-Free Diffusion Guidance,”arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Denoising Diffusion Probabilistic Models,
J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
2020
-
[9]
Planning with Diffusion for Flexible Behavior Synthesis,
M. Janneret al., “Planning with Diffusion for Flexible Behavior Synthesis,” inProceedings of the 39th International Conference on Machine Learning, vol. 162. PMLR, 2022, pp. 9902–9915
2022
-
[10]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,
C. Chiet al., “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[11]
J. Tanget al., “VLASH: Real-Time VLAs via Future-State-Aware Asynchronous Inference,”arXiv preprint arXiv:2512.01031, 2025
-
[12]
Scalable Diffusion Models with Transform- ers,
W. Peebles and S. Xie, “Scalable Diffusion Models with Transform- ers,” in2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4172–4182
2023
-
[13]
Training-Time Action Conditioning for Efficient Real- Time Chunking,
K. Blacket al., “Training-Time Action Conditioning for Efficient Real- Time Chunking,”arXiv preprint arXiv:2512.05964, 2025
-
[14]
Language-Guided Object-Centric Diffusion Policy for Generalizable and Collision-Aware Manipulation,
H. Liet al., “Language-Guided Object-Centric Diffusion Policy for Generalizable and Collision-Aware Manipulation,” in2025 IEEE In- ternational Conference on Robotics and Automation (ICRA), 2025, pp. 12 834–12 841
2025
-
[15]
VLSA: Vision-Language-Action Models with Plug-and-Play Safety Constraint Layer
S. Huet al., “VLSA: Vision-Language-Action Models with Plug-and- Play Safety Constraint Layer,”arXiv preprint arXiv:2512.11891, 2025
work page internal anchor Pith review arXiv 2025
-
[16]
RAIL: Reachability-Aided Imitation Learning for Safe Policy Execution,
W. Junget al., “RAIL: Reachability-Aided Imitation Learning for Safe Policy Execution,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 3582–3589
2025
-
[17]
FiLM: Visual Reasoning with a General Conditioning Layer,
E. Perezet al., “FiLM: Visual Reasoning with a General Conditioning Layer,” inProceedings of the AAAI conference on artificial intelli- gence, vol. 32, no. 1, 2018
2018
-
[18]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising Diffusion Implicit Models,”arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[19]
U-Net: Convolutional Net- works for Biomedical Image Segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional Net- works for Biomedical Image Segmentation,” inInternational Confer- ence on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
2015
-
[20]
EGO-Planner: An ESDF-Free Gradient-Based Local Planner for Quadrotors,
X. Zhouet al., “EGO-Planner: An ESDF-Free Gradient-Based Local Planner for Quadrotors,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 478–485, 2020
2020
-
[21]
A Formal Basis for the Heuristic Determination of Minimum Cost Paths,
P. E. Hart, N. J. Nilsson, and B. Raphael, “A Formal Basis for the Heuristic Determination of Minimum Cost Paths,”IEEE Transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968
1968
-
[22]
Geometrically Constrained Trajectory Optimization for Multicopters,
Z. Wanget al., “Geometrically Constrained Trajectory Optimization for Multicopters,”IEEE Transactions on Robotics, vol. 38, no. 5, pp. 3259–3278, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.