Recover Semantics First, Generate Better: Improved Latent Modeling for 3D MRI Reconstruction and Cross-Contrast Synthesis
Pith reviewed 2026-06-27 01:02 UTC · model grok-4.3
The pith
Recovering semantics first in latent compression produces better 3D MRI reconstructions and cross-contrast syntheses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
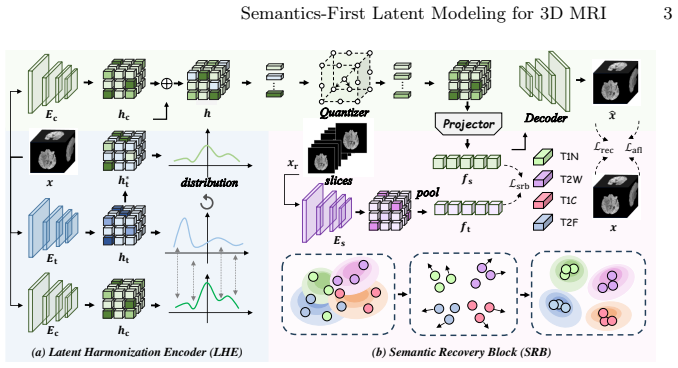
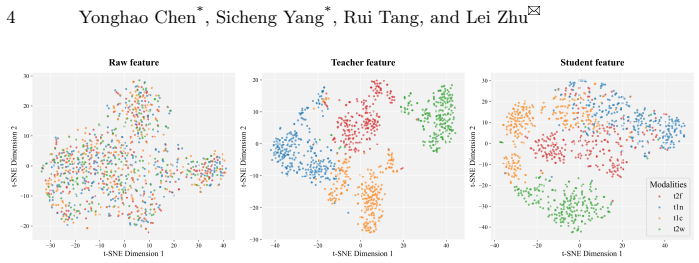
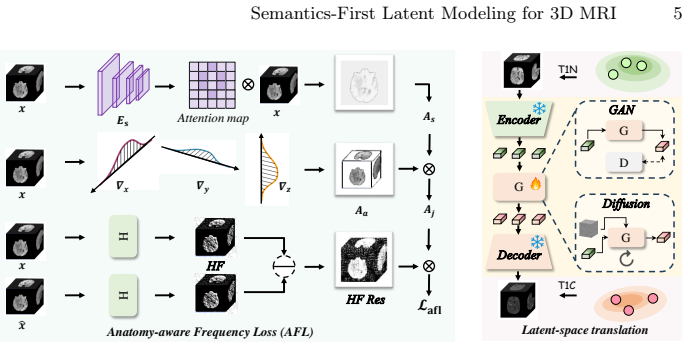
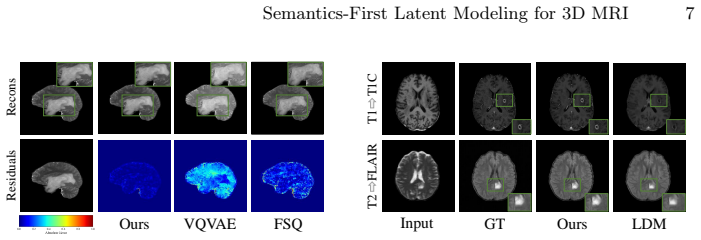
Existing latent compressors for 3D MRI under-preserve long-range coherence, discard semantic content, and produce over-smoothed outputs; the proposed framework counters these problems by first recovering semantics via a Latent Harmonization Encoder that models global anatomical dependencies, a Semantic Recovery Block that injects high-level priors from a self-supervised teacher to improve contrast-aware separability, and an Anatomy-aware Frequency Loss that adaptively retains diagnostically relevant high-frequency structures, yielding measurable gains in reconstruction fidelity and cross-contrast synthesis quality.
What carries the argument
The Semantic Recovery Block (SRB), which injects high-level priors from a self-supervised semantic teacher to restore contrast-aware separability in the compressed latent space.
If this is right
- Latent representations retain long-range anatomical coherence across entire 3D volumes rather than treating slices independently.
- Clinically meaningful semantic distinctions between contrasts remain separable after compression.
- Generative models trained in the improved latent space produce higher-fidelity cross-contrast syntheses without additional architectural changes.
- High-frequency anatomical structures that carry diagnostic value are preserved instead of being smoothed away.
Where Pith is reading between the lines
- The same semantics-first ordering could be tested on other volumetric modalities such as CT or PET where acquisition cost is also high.
- If the self-supervised teacher can be made even lighter, the method might reduce overall training compute while keeping the fidelity gains.
- Reliable synthesis of missing contrasts could shorten clinical MRI protocols by allowing fewer sequences to be acquired per patient.
Load-bearing premise
The self-supervised semantic teacher supplies high-level priors that genuinely improve latent separability without injecting bias or artifacts that would degrade the downstream generative model.
What would settle it
Retraining the full pipeline on the same two public multi-contrast MRI datasets but with the Semantic Recovery Block removed, and finding no drop in reconstruction or synthesis metrics, would falsify the claim that semantic recovery is the decisive improvement.
Figures
read the original abstract
Multi-contrast magnetic resonance imaging (MRI) provides complementary information for clinical diagnosis. However, acquiring all MRI sequences is often time-consuming and costly. Recent generative models perform cross-contrast synthesis to address this issue by inferring absent contrasts from the available ones. Nevertheless, synthesizing 3D MRI presents significant challenges. Due to the massive volume sizes, operating directly in the pixel space is computationally prohibitive; therefore, a common approach is to first compress the 3D volumes into a latent space and subsequently train generative models in that space. We observe that existing compression architectures face several critical issues: they under-preserve long-range anatomical coherence, discard clinically meaningful semantics, and rely on optimization objectives that lead to over-smoothed reconstructions. Ultimately, these shortcomings compromise the performance of subsequent generative models. In this work, we propose a semantics-first latent modeling framework for 3D MRI reconstruction and cross-contrast synthesis. Specifically, we introduce a Latent Harmonization Encoder (LHE) to capture global anatomical dependencies, ensuring coherent volumetric representations. To mitigate semantic degradation during latent compression, we further design a Semantic Recovery Block (SRB) that injects high-level priors from a self-supervised semantic teacher, enhancing contrast-aware separability in the latent space. Additionally, we propose an Anatomy-aware Frequency Loss (AFL) to adaptively preserve diagnostically relevant high-frequency structures. Extensive experiments on two public multi-contrast MRI datasets demonstrate consistent improvements in reconstruction fidelity and cross-contrast synthesis quality. Our code is available at https://github.com/script-Yang/RSF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard latent compression methods for 3D MRI reconstruction and cross-contrast synthesis suffer from insufficient long-range anatomical coherence, loss of clinically meaningful semantics, and over-smoothed outputs that degrade downstream generative performance. To address these issues, the authors introduce a semantics-first framework consisting of a Latent Harmonization Encoder (LHE) to model global volumetric dependencies, a Semantic Recovery Block (SRB) that injects priors from a self-supervised semantic teacher to improve contrast-aware separability, and an Anatomy-aware Frequency Loss (AFL) that adaptively preserves high-frequency diagnostic structures. They report that extensive experiments on two public multi-contrast MRI datasets show consistent gains in reconstruction fidelity and synthesis quality, with code released.
Significance. If the reported empirical gains are robust and reproducible, the work would meaningfully advance latent-space modeling for 3D medical image synthesis by explicitly recovering semantics that are typically discarded in standard autoencoders. This is clinically relevant because accurate anatomical and contrast-specific details directly affect diagnostic utility. The open release of code is a clear strength that supports verification and extension by the community.
minor comments (2)
- Abstract: the claim of 'consistent improvements' is stated without any numerical values, baseline names, or statistical significance indicators. Adding at least one representative metric (e.g., PSNR/SSIM deltas or FID) would strengthen the abstract without lengthening it excessively.
- The description of the self-supervised semantic teacher in the SRB is high-level; a short additional sentence clarifying the exact pre-training objective and how its features are injected (e.g., via concatenation or attention) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our semantics-first latent modeling framework, the recognition of its clinical relevance for 3D MRI reconstruction and synthesis, and the recommendation for minor revision. The emphasis on reproducibility via code release is appreciated.
Circularity Check
No significant circularity; derivation is self-contained architectural proposal
full rationale
The paper presents an architectural framework (LHE for global dependencies, SRB for semantic injection from a self-supervised teacher, AFL for frequency preservation) whose components are introduced as design choices and whose performance is measured directly via experiments on two external public multi-contrast MRI datasets. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the inputs or to self-citations; the central claims rest on empirical fidelity and synthesis gains rather than internal reductions. The self-supervised teacher is treated as an independent prior whose net effect is externally validated, satisfying the criteria for a non-circular, self-contained method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A self-supervised semantic teacher network can supply high-level priors that enhance contrast-aware separability during latent compression.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y., Cui, Y., Ding, Y., et al.: Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Medical Image Analysis106, 103747 (2025)
Arslan, F., Kabas, B., Dalmaz, O., Ozbey, M., Çukur, T.: Self-consistent recursive diffusion bridge for medical image translation. Medical Image Analysis106, 103747 (2025)
2025
-
[3]
arXiv preprint arXiv:2312.02366 (2023)
Baharoon, M., Qureshi, W., Ouyang, J., Xu, Y., Aljouie, A., Peng, W.: Evaluating general purpose vision foundation models for medical image analysis: An experi- mental study of dinov2 on radiology benchmarks. arXiv preprint arXiv:2312.02366 (2023)
-
[4]
Baid, U., Ghodasara, S., Mohan, S., Bilello, M., Calabrese, E., Colak, E., Farahani, K., Kalpathy-Cramer, J., Kitamura, F.C., Pati, S., et al.: The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classifica- tion. arXiv preprint arXiv:2107.02314 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
John Wiley & Sons (2014)
Brown, R.W., Cheng, Y.C.N., Haacke, E.M., Thompson, M.R., Venkatesan, R.: Magnetic resonance imaging: physical principles and sequence design. John Wiley & Sons (2014)
2014
-
[6]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[7]
IEEE Transactions on Medical Imaging41(10), 2598–2614 (2022)
Dalmaz, O., Yurt, M., Çukur, T.: Resvit: Residual vision transformers for multi- modal medical image synthesis. IEEE Transactions on Medical Imaging41(10), 2598–2614 (2022)
2022
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883 (2021)
2021
-
[10]
Communications of the ACM63(11), 139–144 (2020)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Communications of the ACM63(11), 139–144 (2020)
2020
-
[11]
In: International MICCAI brainlesion workshop
Hatamizadeh, A., Nath, V., Tang, Y., Yang, D., Roth, H.R., Xu, D.: Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images. In: International MICCAI brainlesion workshop. pp. 272–284. Springer (2021) 10 Yonghao Chen *, Sicheng Yang*, Rui Tang, and Lei Zhu
2021
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[13]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[14]
NeuroImage33(1), 115–126 (2006)
Heckemann,R.A.,Hajnal,J.V.,Aljabar,P.,Rueckert,D.,Hammers,A.:Automatic anatomical brain mri segmentation combining label propagation and decision fu- sion. NeuroImage33(1), 115–126 (2006)
2006
-
[15]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi- tional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1125–1134 (2017)
2017
-
[16]
In: Proceedings of the IEEE/CVF international conference on computer vision
Jiang, L., Dai, B., Wu, W., Loy, C.C.: Focal frequency loss for image reconstruc- tion and synthesis. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 13919–13929 (2021)
2021
-
[17]
Medical image analysis69, 101950 (2021)
Kavur, A.E., Gezer, N.S., Barış, M., Aslan, S., Conze, P.H., Groza, V., Pham, D.D., Chatterjee, S., Ernst, P., Özkan, S., et al.: Chaos challenge-combined (ct- mr) healthy abdominal organ segmentation. Medical image analysis69, 101950 (2021)
2021
-
[18]
Scientific reports13(1), 7303 (2023)
Khader, F., Müller-Franzes, G., Tayebi Arasteh, S., Han, T., Haarburger, C., Schulze-Hagen, M., Schad, P., Engelhardt, S., Baeßler, B., Foersch, S., et al.: De- noising diffusion probabilistic models for 3d medical image generation. Scientific reports13(1), 7303 (2023)
2023
-
[19]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Image and Vision Computing p
Kui, X., Fan, Z., Ji, Z., Li, Q., Liu, C., Si, W., Zou, B.: A comprehensive survey on magnetic resonance image reconstruction. Image and Vision Computing p. 105832 (2025)
2025
-
[21]
arXiv preprint arXiv:2405.09787 (2024)
LaBella, D., Baid, U., Khanna, O., McBurney-Lin, S., McLean, R., Nedelec, P., Rashid, A., Tahon, N.H., Altes, T., Bhalerao, R., et al.: Analysis of the brats 2023 intracranial meningioma segmentation challenge. arXiv preprint arXiv:2405.09787 (2024)
-
[22]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., et al.: Photo-realistic single image super- resolution using a generative adversarial network. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4681–4690 (2017)
2017
-
[23]
Finite Scalar Quantization: VQ-VAE Made Simple
Mentzer, F., Minnen, D., Agustsson, E., Tschannen, M.: Finite scalar quantization: Vq-vae made simple. arXiv preprint arXiv:2309.15505 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
In: International Workshop on Deep Learning in Medical Image Analysis
Nie, D., Cao, X., Gao, Y., Wang, L., Shen, D.: Estimating ct image from mri data using 3d fully convolutional networks. In: International Workshop on Deep Learning in Medical Image Analysis. pp. 170–178. Springer (2016)
2016
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[26]
In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention
Song, X., Xu, X., Yan, P.: Dino-reg: General purpose image encoder for training- free multi-modal deformable medical image registration. In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention. pp. 608–617. Springer (2024)
2024
-
[27]
Taleb, A., Loetzsch, W., Danz, N., Severin, J., Gaertner, T., Bergner, B., Lippert, C.:3dself-supervisedmethodsformedicalimaging.Advancesinneuralinformation processing systems33, 18158–18172 (2020) Semantics-First Latent Modeling for 3D MRI 11
2020
-
[28]
Advances in neural information processing systems30(2017)
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. Advances in neural information processing systems30(2017)
2017
-
[29]
In: International conference on medical image computing and computer-assisted intervention
Wang, Y., Li, Z., Mei, J., Wei, Z., Liu, L., Wang, C., Sang, S., Yuille, A.L., Xie, C., Zhou, Y.: Swinmm: masked multi-view with swin transformers for 3d medical image segmentation. In: International conference on medical image computing and computer-assisted intervention. pp. 486–496. Springer (2023)
2023
-
[30]
Advances in Neural Information Processing Systems38, 7714–7743 (2026)
Wu, G., Zhang, S., Shi, R., Gao, S., Chen, Z., Wang, L., Chen, Z., Gao, H., Tang, Y., Cheng, M.M., et al.: Representation entanglement for generation: Training dif- fusion transformers is much easier than you think. Advances in Neural Information Processing Systems38, 7714–7743 (2026)
2026
-
[31]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yang, S., Hu, X., Wu, Q., Yang, D.: Vaevq: Enhancing discrete visual tokenization through variational modeling. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 11703–11711 (2026)
2026
-
[32]
arXiv preprint arXiv:2509.00833 (2025)
Yang, S., Wang, H., Xing, Z., Chen, S., Zhu, L.: Segdino: An efficient de- sign for medical and natural image segmentation with dino-v3. arXiv preprint arXiv:2509.00833 (2025)
-
[33]
arXiv preprint arXiv:2601.10124 (2026)
Yang, S., Xing, Z., Zhu, L.: Vq-seg: Vector-quantized token perturbation for semi- supervised medical image segmentation. arXiv preprint arXiv:2601.10124 (2026)
-
[34]
IEEE Transactions on Medical Imaging (2026)
Yang, S., Zhou, H., Yang, Y., Wang, W., Chen, S., Yang, G., Fu, H., Zhu, L.: Lcm-net: Llm-driven cross-modality moe feature fusion network for cancer survival analysis. IEEE Transactions on Medical Imaging (2026)
2026
-
[35]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
In: Proceedings of the IEEE interna- tional conference on computer vision
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE interna- tional conference on computer vision. pp. 2223–2232 (2017)
2017
-
[37]
Computerized Medical Imaging and Graphics 109, 102285 (2023)
Zuo, L., Liu, Y., Xue, Y., Dewey, B.E., Remedios, S.W., Hays, S.P., Bilgel, M., Mowry, E.M., Newsome, S.D., Calabresi, P.A., et al.: Haca3: A unified approach for multi-site mr image harmonization. Computerized Medical Imaging and Graphics 109, 102285 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.