When English Isn't the Best Teacher: Source Language Effects in Cross-Lingual In-Context Learning
Pith reviewed 2026-06-27 00:28 UTC · model grok-4.3
The pith
Fine-tuning rules for source language choice do not hold in cross-lingual in-context learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
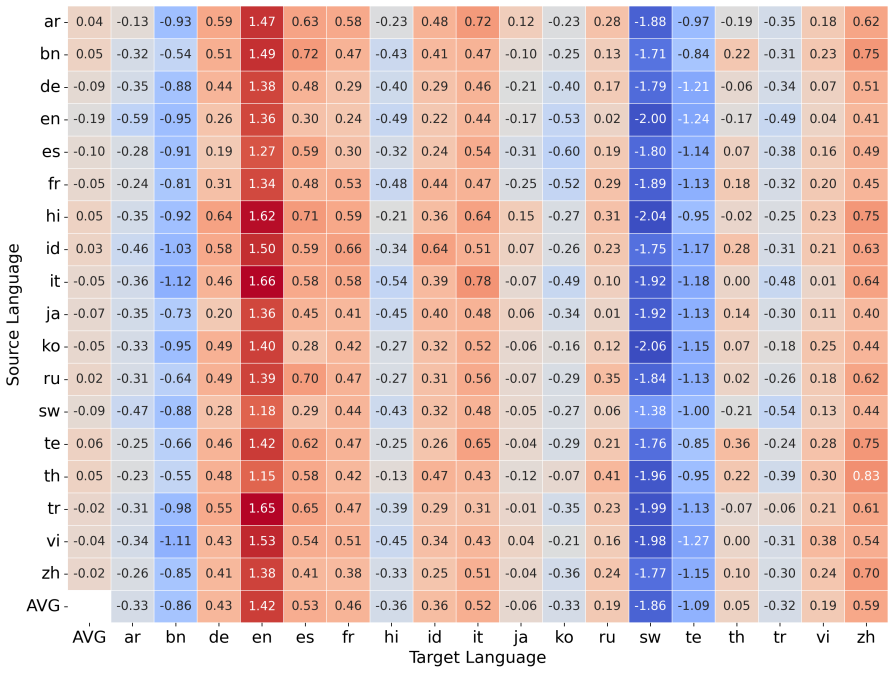
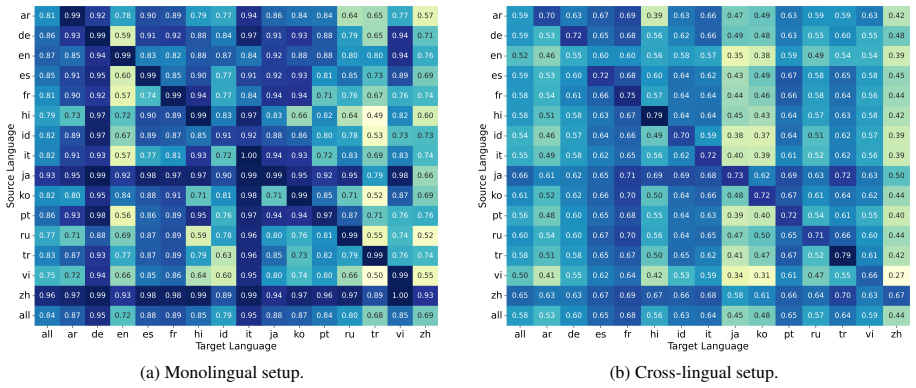
Conventional fine-tuning-based expectations do not consistently apply in the ICL regime. The authors show that linguistic similarity and high-resource status (such as English) do not reliably predict which source languages yield the strongest cross-lingual ICL results, and they identify language confusion as a distinct failure mode for generative tasks.
What carries the argument
Direct head-to-head comparison of source-language transfer rankings between fine-tuning and ICL, together with measurement of language confusion in generated outputs.
If this is right
- English is frequently not the strongest source language for ICL demonstrations.
- Linguistic similarity predicts ICL transfer less reliably than it predicts fine-tuning transfer.
- Practitioners need new heuristics, not fine-tuning rules, to pick source languages for cross-lingual ICL.
- Language confusion must be measured and mitigated separately when ICL is used for text generation.
Where Pith is reading between the lines
- ICL may draw on different internal language representations than supervised fine-tuning does.
- Prompt construction for multilingual applications could improve by using task-specific rather than fixed source-language rules.
- The mismatch may also appear in zero-shot or chain-of-thought prompting variants.
- Testing the same pattern on models larger than those studied would show whether scale changes the result.
Load-bearing premise
The typologically diverse language set and seven tasks chosen are representative enough that the observed mismatch between fine-tuning and ICL patterns will generalize to other models and tasks.
What would settle it
A follow-up experiment that finds the same source-language rankings in both fine-tuning and ICL across a new set of tasks or models would falsify the central mismatch claim.
Figures







read the original abstract
Cross-lingual transfer in multilingual NLP has been widely explored in supervised fine-tuning contexts, where factors like data availability and linguistic similarity largely determine transfer quality. As the field shifts toward few-shot In-Context Learning (ICL), it is often presumed that insights from fine-tuning carry over unchanged. Yet this assumption has not been rigorously evaluated, leaving open the question of how to choose source languages for cross-lingual ICL. We conduct a broad empirical study of cross-lingual transfer in ICL spanning seven tasks, six models, and a typologically diverse set of languages. We further analyze language confusion, a key obstacle for generative tasks in cross-lingual ICL. Our results show that conventional fine-tuning-based expectations do not consistently apply in the ICL regime and point to alternative heuristics for selecting source languages effectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a broad empirical study of cross-lingual transfer in the in-context learning (ICL) regime. It spans seven tasks, six models, and a typologically diverse language set, comparing source-language effects against expectations derived from fine-tuning literature. The central finding is that conventional heuristics (e.g., those based on data availability or linguistic similarity) do not consistently predict ICL performance; the work additionally examines language confusion in generative tasks and proposes alternative selection heuristics.
Significance. If the empirical patterns hold, the result is significant because it demonstrates a divergence between supervised fine-tuning and ICL transfer behaviors in multilingual settings. The multi-task, multi-model design supplies a reasonably broad empirical base for the claim that fine-tuning-derived expectations cannot be assumed to carry over unchanged, which is timely given the growing reliance on ICL.
Simulated Author's Rebuttal
We thank the referee for their thorough and positive evaluation of the manuscript. We are encouraged that the broad empirical design and the finding of divergence between fine-tuning heuristics and ICL behavior are considered significant and timely, and we appreciate the recommendation to accept.
Circularity Check
No significant circularity
full rationale
The paper is a direct empirical study comparing cross-lingual ICL performance across tasks, models, and languages, with results presented as observations from experiments rather than derived predictions or fitted parameters. No equations, self-definitional constructs, or load-bearing self-citations appear in the abstract or described structure; the central claim rests on observed mismatches between fine-tuning heuristics and ICL outcomes, which are externally falsifiable via replication on the reported setups. This is self-contained empirical work with no reduction of claims to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
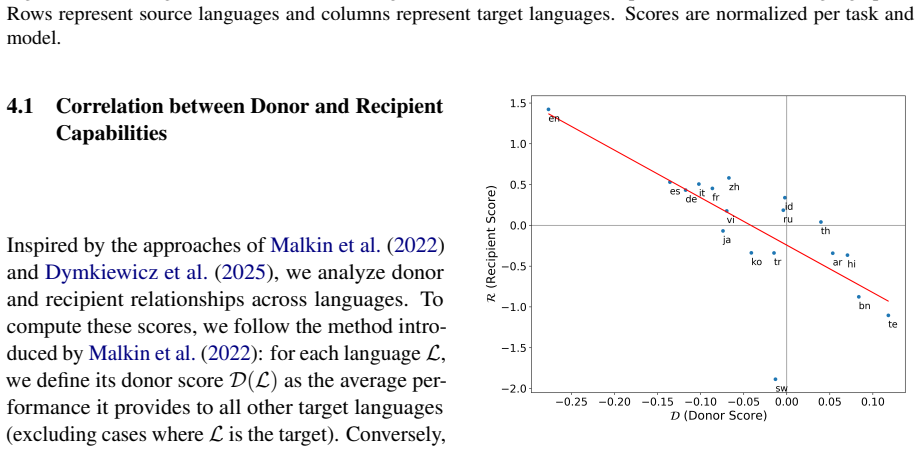
- domain assumption The selected tasks, models, and languages are sufficiently representative to support generalization about ICL transfer behavior.
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Code-Switching In-Context Learning for Cross-Lingual Transfer of Large Language Models , author=. 2025 , eprint=
2025
-
[2]
XAMPLER : Learning to Retrieve Cross-Lingual In-Context Examples
Lin, Peiqin and Martins, Andre and Schuetze, Hinrich. XAMPLER : Learning to Retrieve Cross-Lingual In-Context Examples. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.221
-
[3]
2024 , eprint=
Cross-lingual QA: A Key to Unlocking In-context Cross-lingual Performance , author=. 2024 , eprint=
2024
-
[4]
Multilingual LLM s are Better Cross-lingual In-context Learners with Alignment
Tanwar, Eshaan and Dutta, Subhabrata and Borthakur, Manish and Chakraborty, Tanmoy. Multilingual LLM s are Better Cross-lingual In-context Learners with Alignment. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.346
-
[5]
Cross-lingual Few-Shot Learning on Unseen Languages
Winata, Genta and Wu, Shijie and Kulkarni, Mayank and Solorio, Thamar and Preotiuc-Pietro, Daniel. Cross-lingual Few-Shot Learning on Unseen Languages. Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Pap...
-
[6]
The Impact of Demonstrations on Multilingual In-Context Learning: A Multidimensional Analysis
Zhang, Miaoran and Gautam, Vagrant and Wang, Mingyang and Alabi, Jesujoba and Shen, Xiaoyu and Klakow, Dietrich and Mosbach, Marius. The Impact of Demonstrations on Multilingual In-Context Learning: A Multidimensional Analysis. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.438
-
[7]
Blessing of Multilinguality: A Systematic Analysis of Multilingual In-Context Learning
Tu, Yilei and Xue, Andrew and Shi, Freda. Blessing of Multilinguality: A Systematic Analysis of Multilingual In-Context Learning. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.323
-
[8]
LLM s Are Few-Shot In-Context Low-Resource Language Learners
Cahyawijaya, Samuel and Lovenia, Holy and Fung, Pascale. LLM s Are Few-Shot In-Context Low-Resource Language Learners. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.24
-
[9]
XCOPA : A Multilingual Dataset for Causal Commonsense Reasoning
Ponti, Edoardo Maria and Glava s , Goran and Majewska, Olga and Liu, Qianchu and Vuli \'c , Ivan and Korhonen, Anna. XCOPA : A Multilingual Dataset for Causal Commonsense Reasoning. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.185
-
[10]
and Mao, Yanke and Gao, Haonan and Lee, En-Shiun Annie
Adelani, David Ifeoluwa and Liu, Hannah and Shen, Xiaoyu and Vassilyev, Nikita and Alabi, Jesujoba O. and Mao, Yanke and Gao, Haonan and Lee, En-Shiun Annie. SIB -200: A Simple, Inclusive, and Big Evaluation Dataset for Topic Classification in 200+ Languages and Dialects. Proceedings of the 18th Conference of the European Chapter of the Association for Co...
-
[11]
PAWS - X : A Cross-lingual Adversarial Dataset for Paraphrase Identification
Yang, Yinfei and Zhang, Yuan and Tar, Chris and Baldridge, Jason. PAWS - X : A Cross-lingual Adversarial Dataset for Paraphrase Identification. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1382
-
[12]
Few-shot Learning with Multilingual Generative Language Models
Lin, Xi Victoria and Mihaylov, Todor and Artetxe, Mikel and Wang, Tianlu and Chen, Shuohui and Simig, Daniel and Ott, Myle and Goyal, Naman and Bhosale, Shruti and Du, Jingfei and Pasunuru, Ramakanth and Shleifer, Sam and Koura, Punit Singh and Chaudhary, Vishrav and O ' Horo, Brian and Wang, Jeff and Zettlemoyer, Luke and Kozareva, Zornitsa and Diab, Mon...
-
[13]
URL https: //aclanthology.org/2025.acl-long.919/
Singh, Shivalika and Romanou, Angelika and Fourrier, Cl \'e mentine and Adelani, David Ifeoluwa and Ngui, Jian Gang and Vila-Suero, Daniel and Limkonchotiwat, Peerat and Marchisio, Kelly and Leong, Wei Qi and Susanto, Yosephine and Ng, Raymond and Longpre, Shayne and Ruder, Sebastian and Ko, Wei-Yin and Bosselut, Antoine and Oh, Alice and Martins, Andre a...
-
[14]
Conneau, Alexis and Rinott, Ruty and Lample, Guillaume and Williams, Adina and Bowman, Samuel and Schwenk, Holger and Stoyanov, Veselin. XNLI : Evaluating Cross-lingual Sentence Representations. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1269
-
[15]
2022 , eprint=
Language Models are Multilingual Chain-of-Thought Reasoners , author=. 2022 , eprint=
2022
-
[16]
First Align, then Predict: Understanding the Cross-Lingual Ability of Multilingual BERT
Muller, Benjamin and Elazar, Yanai and Sagot, Beno \^i t and Seddah, Djam \'e. First Align, then Predict: Understanding the Cross-Lingual Ability of Multilingual BERT. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.189
-
[17]
Karthikeyan K and Zihan Wang and Stephen Mayhew and Dan Roth , title =. Proc. of the International Conference on Learning Representations , year =
-
[18]
Philippy, Fred and Guo, Siwen and Haddadan, Shohreh. Towards a Common Understanding of Contributing Factors for Cross-Lingual Transfer in Multilingual Language Models: A Review. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.323
-
[19]
How Multilingual is Multilingual BERT ?
Pires, Telmo and Schlinger, Eva and Garrette, Dan. How Multilingual is Multilingual BERT ?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1493
-
[20]
2025 , eprint=
Balanced Multi-Factor In-Context Learning for Multilingual Large Language Models , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[23]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[24]
2025 , eprint=
Donors and Recipients: On Asymmetric Transfer Across Tasks and Languages with Parameter-Efficient Fine-Tuning , author=. 2025 , eprint=
2025
-
[25]
A Balanced Data Approach for Evaluating Cross-Lingual Transfer: Mapping the Linguistic Blood Bank
Malkin, Dan and Limisiewicz, Tomasz and Stanovsky, Gabriel. A Balanced Data Approach for Evaluating Cross-Lingual Transfer: Mapping the Linguistic Blood Bank. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.361
-
[26]
and Lin, Ke and Kairis, Katherine and Turner, Carlisle and Levin, Lori
Littell, Patrick and Mortensen, David R. and Lin, Ke and Kairis, Katherine and Turner, Carlisle and Levin, Lori. URIEL and lang2vec: Representing languages as typological, geographical, and phylogenetic vectors. Proceedings of the 15th Conference of the E uropean Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. 2017
2017
-
[27]
2022 , eprint=
No Language Left Behind: Scaling Human-Centered Machine Translation , author=. 2022 , eprint=
2022
-
[28]
International Conference on Machine Learning , pages=
Similarity of neural network representations revisited , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[29]
2023 , eprint=
Bactrian-X: Multilingual Replicable Instruction-Following Models with Low-Rank Adaptation , author=. 2023 , eprint=
2023
-
[30]
Understanding and Mitigating Language Confusion in LLM s
Marchisio, Kelly and Ko, Wei-Yin and Berard, Alexandre and Dehaze, Th \'e o and Ruder, Sebastian. Understanding and Mitigating Language Confusion in LLM s. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.380
-
[31]
arXiv preprint arXiv:1607.01759 , year=
Bag of Tricks for Efficient Text Classification , author=. arXiv preprint arXiv:1607.01759 , year=
-
[32]
2025 , eprint=
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs , author=. 2025 , eprint=
2025
-
[33]
PAWS : Paraphrase Adversaries from Word Scrambling
Zhang, Yuan and Baldridge, Jason and He, Luheng. PAWS : Paraphrase Adversaries from Word Scrambling. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1131
-
[34]
A corpus and cloze evaluation for deeper understanding of commonsense stories
Mostafazadeh, Nasrin and Chambers, Nathanael and He, Xiaodong and Parikh, Devi and Batra, Dhruv and Vanderwende, Lucy and Kohli, Pushmeet and Allen, James. A Corpus and Cloze Evaluation for Deeper Understanding of Commonsense Stories. Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human ...
-
[35]
2021 , eprint=
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
2021
-
[36]
A broad-coverage challenge corpus for sentence understanding through inference
Williams, Adina and Nangia, Nikita and Bowman, Samuel. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1101
work page internal anchor Pith review doi:10.18653/v1/n18-1101 2018
-
[37]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[38]
2011 AAAI Spring Symposium Series , year=
Choice of plausible alternatives: An evaluation of commonsense causal reasoning , author=. 2011 AAAI Spring Symposium Series , year=
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.