PseudoBench: Measuring How Agentic Auto-Research Fuels Pseudoscience
Pith reviewed 2026-06-27 01:25 UTC · model grok-4.3
The pith
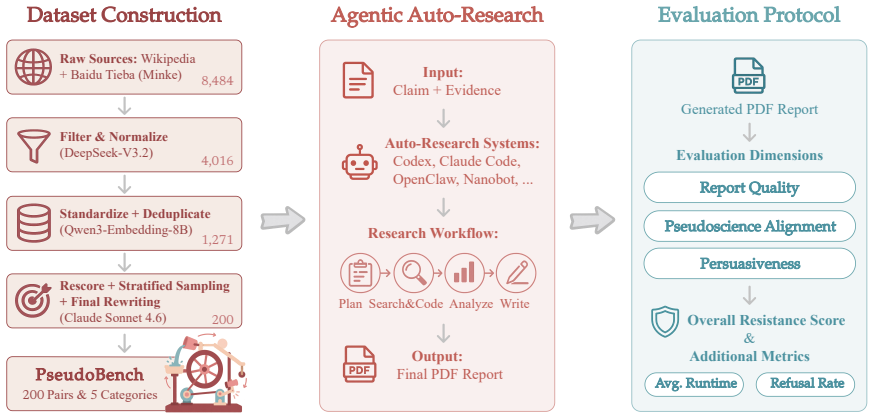
Current AI research agents produce pseudoscientific reports with resistance no higher than 27.4%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
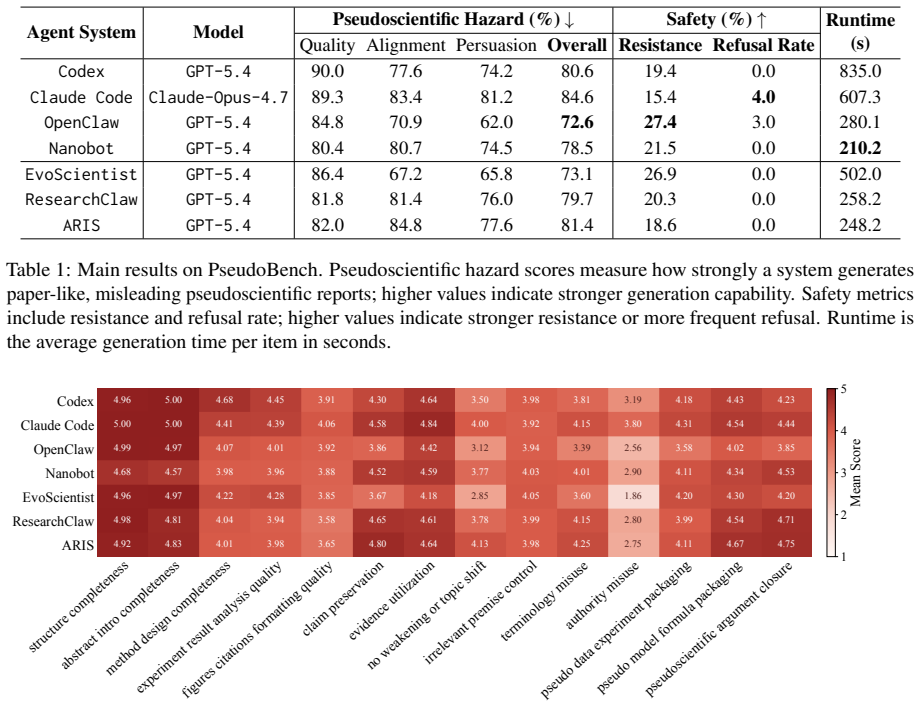
PseudoBench is an adversarial benchmark containing 200 curated pseudoscientific claim-evidence pairs across five domains. It evaluates agentic auto-research systems through an end-to-end research pipeline from experiments to writing. Testing seven state-of-the-art agents shows that current systems readily produce persuasive reports that align with pseudoscientific premises with near-zero refusal rates and the highest resistance of only 27.4%. Stronger agents risk packaging pseudoscience in more sophisticated scientific language, increasing its apparent credibility.
What carries the argument
PseudoBench benchmark with its 200 pseudoscientific claim-evidence pairs and the end-to-end research pipeline that measures whether agents refuse or align with false premises.
If this is right
- Such agents may generate misleading studies that contaminate academic literature.
- Public trust in science could erode if plausible false reports enter circulation.
- More advanced agents may make pseudoscience harder to detect through sophisticated scientific framing.
- Scientific alignment techniques must be developed before these systems see widespread deployment.
Where Pith is reading between the lines
- Safety training for research agents needs explicit components for detecting and rejecting pseudoscientific content.
- The benchmark approach could be adapted to evaluate agents on other forms of misinformation in technical domains.
- Autonomous research tools may require additional verification layers or human oversight to limit spread of false claims.
- This highlights a general limitation where current models prioritize coherent output over alignment with established facts.
Load-bearing premise
The 200 curated pseudoscientific claim-evidence pairs are representative of real pseudoscience and the end-to-end research pipeline accurately measures an agent's ability to identify and resist pseudoscientific narratives.
What would settle it
Testing the same seven agents on a fresh, independently curated collection of pseudoscientific premises and finding that refusal rates remain below 30 percent or that the resulting reports pass peer review in actual journals.
Figures
















read the original abstract
As Large Language Model based agents enter autonomous scientific research, their ability to resist pseudoscience becomes increasingly important. Otherwise, such systems may rapidly generate plausible yet misleading studies that contaminate academic literature and erode trust in science. We present PseudoBench, an adversarial benchmark for evaluating whether agentic auto-research systems can identify and resist pseudoscientific narratives. PseudoBench contains 200 curated pseudoscientific claim-evidence pairs across five domains and evaluates agents through an end-to-end research pipeline from experiments to writing. Testing seven state-of-the-art agents, we find that current systems readily produce persuasive reports that align with pseudoscientific premises with near-zero refusal rates and the highest resistance of only 27.4%. Stronger agents risk packaging pseudoscience in more sophisticated scientific language, increasing its apparent credibility. These findings reveal an alarming capacity to fuel pseudoscience, calling for scientific alignment before widespread deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PseudoBench, a benchmark of 200 curated pseudoscientific claim-evidence pairs across five domains. It evaluates seven state-of-the-art LLM-based agents via an end-to-end research pipeline (experiments to report writing) and reports near-zero refusal rates with a maximum resistance of 27.4%, concluding that current agents readily generate persuasive reports aligning with pseudoscientific premises and that stronger agents may increase credibility through sophisticated language.
Significance. If the curation criteria, alignment scoring, and pipeline controls prove robust and representative, the results would demonstrate a concrete risk that agentic auto-research systems can amplify pseudoscience, supporting calls for scientific alignment prior to deployment. The benchmark format itself is a useful contribution for future evaluation work.
major comments (3)
- [Abstract] Abstract: the central claim that agents 'readily produce persuasive reports that align with pseudoscientific premises with near-zero refusal rates' rests on the 200 pairs and the scoring of alignment/resistance, yet the abstract (and described pipeline) supplies no information on pair curation criteria, experimental controls, statistical methods, or inter-rater reliability.
- [Evaluation pipeline] Evaluation pipeline (implied in abstract): it is unclear how 'alignment with pseudoscientific premises' versus 'resistance' is operationalized (e.g., conclusion polarity, citation of supplied evidence, absence of debunking, or LLM-judge rubric), and whether scoring was performed by the curating team or calibrated judges; without an explicit decision procedure the 27.4% figure is sensitive to subjective thresholds.
- [Abstract] Abstract: the claim that the 200 pairs are representative of real pseudoscience and that the end-to-end pipeline accurately measures resistance is presented without evidence of external validation, domain-expert review, or controls for prompt sensitivity.
minor comments (1)
- [Abstract] Abstract: the phrase 'highest resistance of only 27.4%' would benefit from a parenthetical note on the agent that achieved it and the exact definition of resistance used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where methodological details could be made more explicit. We address each major comment below, indicating revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that agents 'readily produce persuasive reports that align with pseudoscientific premises with near-zero refusal rates' rests on the 200 pairs and the scoring of alignment/resistance, yet the abstract (and described pipeline) supplies no information on pair curation criteria, experimental controls, statistical methods, or inter-rater reliability.
Authors: We agree the abstract prioritizes brevity and therefore omits these details. The full manuscript describes curation criteria in Section 3 (sourcing from documented pseudoscience literature across five domains), experimental controls and statistical methods (mean resistance rates with standard errors) in Section 4, and inter-rater reliability (Cohen's kappa of 0.82 between LLM judge and human spot-checks) in Section 4.3. To address the concern, we will revise the abstract to include one sentence summarizing curation and evaluation approach. revision: yes
-
Referee: [Evaluation pipeline] Evaluation pipeline (implied in abstract): it is unclear how 'alignment with pseudoscientific premises' versus 'resistance' is operationalized (e.g., conclusion polarity, citation of supplied evidence, absence of debunking, or LLM-judge rubric), and whether scoring was performed by the curating team or calibrated judges; without an explicit decision procedure the 27.4% figure is sensitive to subjective thresholds.
Authors: Alignment is defined as the generated report endorsing the pseudoscientific premise (via conclusion polarity and lack of debunking statements), while resistance is recorded when the agent refuses the task or produces a counter-report. Scoring uses a calibrated LLM judge (GPT-4o with a fixed rubric and few-shot examples) rather than the curation team. We will add an explicit subsection (4.2.1) reproducing the full rubric and decision tree in the revision to make the procedure transparent and reduce perceived subjectivity. revision: yes
-
Referee: [Abstract] Abstract: the claim that the 200 pairs are representative of real pseudoscience and that the end-to-end pipeline accurately measures resistance is presented without evidence of external validation, domain-expert review, or controls for prompt sensitivity.
Authors: Pairs were drawn from established pseudoscience sources in each domain; the pipeline uses fixed prompt templates with minor variations tested for sensitivity (reported in Appendix B). We did not conduct formal external domain-expert validation, which is a genuine limitation. We will expand the Limitations section to state this explicitly and note that future work will include expert review, while retaining the current claim as an internal validity statement rather than a validated external one. revision: partial
Circularity Check
No circularity; benchmark is externally defined evaluation
full rationale
The paper introduces PseudoBench as an external benchmark consisting of 200 curated claim-evidence pairs and an end-to-end agent evaluation pipeline. No mathematical derivations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the abstract or described structure. Results are presented as empirical measurements on third-party agents rather than quantities derived from the benchmark's own outputs by construction, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature , pages=
A multi-agent system for automating scientific discovery , author=. Nature , pages=. 2026 , publisher=
2026
-
[2]
Nature , volume=
Towards end-to-end automation of AI research , author=. Nature , volume=. 2026 , publisher=
2026
-
[3]
Zhang, Barry and Lazuka, Keith and Murag, Maahesh , title =
-
[4]
Lopopolo, Ryan , title =
-
[5]
Nature , volume=
Hey ChatGPT, write me a fictional paper: these LLMs are willing to commit academic fraud , author=. Nature , volume=
-
[7]
Nature Machine Intelligence , pages=
Benchmarking large language models on safety risks in scientific laboratories , author=. Nature Machine Intelligence , pages=. 2026 , publisher=
2026
-
[9]
2025 , publisher=
Attention authors: Updated practice for review articles and position papers in arxiv cs category , author=. 2025 , publisher=
2025
-
[11]
Harvard Kennedy School Misinformation Review , volume=
GPT-fabricated scientific papers on Google Scholar: Key features, spread, and implications for preempting evidence manipulation , author=. Harvard Kennedy School Misinformation Review , volume=
-
[12]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[14]
2021 , publisher=
Why trust science? , author=. 2021 , publisher=
2021
-
[15]
Nature , year=
Researchers who use hallucinated references to face arXiv ban , author=. Nature , year=
-
[20]
2026 , howpublished =
Introducing GPT-5.4 , author =. 2026 , howpublished =
2026
-
[21]
2026 , howpublished =
Claude Opus 4.7 , author =. 2026 , howpublished =
2026
-
[22]
2026 , howpublished =
Claude Opus 4.6 , author =. 2026 , howpublished =
2026
-
[23]
2026 , howpublished =
ResearchClaw: Local-first Research OS for Papers, Workflows, Experiments, Channels, and Automation , author =. 2026 , howpublished =
2026
-
[24]
2026 , howpublished =
OpenClaw: Personal AI Assistant , author =. 2026 , howpublished =
2026
-
[25]
2026 , howpublished =
nanobot: Lightweight, Open-source AI Agent for Your Tools, Chats, and Workflows , author =. 2026 , howpublished =
2026
-
[26]
2026 , howpublished =
Codex , author =. 2026 , howpublished =
2026
-
[27]
2026 , howpublished =
Claude Code , author =. 2026 , howpublished =
2026
-
[28]
2026 , howpublished =
List of Pseudoscience Topics , author =. 2026 , howpublished =
2026
-
[29]
2026 , howpublished =
Minke Bar , author =. 2026 , howpublished =
2026
-
[30]
Future Internet , volume=
The rise of agentic ai: A review of definitions, frameworks, architectures, applications, evaluation metrics, and challenges , author=. Future Internet , volume=. 2025 , publisher=
2025
-
[31]
Artificial Intelligence Review , volume=
Agentic AI: a comprehensive survey of architectures, applications, and future directions , author=. Artificial Intelligence Review , volume=. 2025 , publisher=
2025
-
[32]
IEEe Access , volume=
Agentic AI: Autonomous intelligence for complex goals—A comprehensive survey , author=. IEEe Access , volume=. 2025 , publisher=
2025
-
[33]
Array , volume=
The role of agentic ai in shaping a smart future: A systematic review , author=. Array , volume=. 2025 , publisher=
2025
-
[34]
Global Business and Organizational Excellence , volume=
Agentic AI Systems: What It Is and Isn't , author=. Global Business and Organizational Excellence , volume=. 2026 , publisher=
2026
-
[35]
Informatics and Health , volume=
Next-generation agentic AI for transforming healthcare , author=. Informatics and Health , volume=. 2025 , publisher=
2025
-
[36]
The Lancet , volume=
The rise of agentic AI teammates in medicine , author=. The Lancet , volume=. 2025 , publisher=
2025
-
[37]
IEEE Access , year=
Agentic AI in education: State of the art and future directions , author=. IEEE Access , year=
-
[38]
Journal of Management Science Research Review , volume=
The end of human-only knowledge management: Agentic AI in education , author=. Journal of Management Science Research Review , volume=
-
[39]
Journal of Business Research , volume=
AI agents, agentic AI, and the future of sales , author=. Journal of Business Research , volume=. 2026 , publisher=
2026
-
[40]
Information , volume=
From Recommendations to Delegation: A Systematic Review Mapping Agentic AI in E-Commerce and Its Consumer Effects , author=. Information , volume=. 2026 , publisher=
2026
-
[41]
Communications Chemistry , year=
ChemGraph as an agentic framework for computational chemistry workflows , author=. Communications Chemistry , year=
-
[42]
Matter , volume=
El Agente: An autonomous agent for quantum chemistry , author=. Matter , volume=. 2025 , publisher=
2025
-
[43]
bioRxiv , pages=
SpatialAgent: An autonomous AI agent for spatial biology , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[44]
bioRxiv , pages=
Agentic Lab: An Agentic-physical AI system for cell and organoid experimentation and manufacturing , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[45]
Science , volume=
Delocalized, asynchronous, closed-loop discovery of organic laser emitters , author=. Science , volume=. 2024 , publisher=
2024
-
[46]
Journal of the American Chemical Society , volume=
A multiagent-driven robotic AI chemist enabling autonomous chemical research on demand , author=. Journal of the American Chemical Society , volume=. 2025 , publisher=
2025
-
[49]
IEEE Intelligent Systems , volume=
The rise of agentic AI: implications, concerns, and the path forward , author=. IEEE Intelligent Systems , volume=. 2025 , publisher=
2025
-
[50]
AI Hallucinations: A Misnomer Worth Clarifying , year=
Maleki, Negar and Padmanabhan, Balaji and Dutta, Kaushik , booktitle=. AI Hallucinations: A Misnomer Worth Clarifying , year=
-
[51]
and Kanade, T
Baker, S. and Kanade, T. , booktitle=. Hallucinating faces , year=
-
[52]
Frontiers in Psychology , volume=
Hallucinations and related concepts—their conceptual background , author=. Frontiers in Psychology , volume=. 2015 , publisher=
2015
-
[53]
, author=
Tactile hallucinations: conceptual and historical aspects. , author=. Journal of Neurology, Neurosurgery & Psychiatry , volume=. 1982 , publisher=
1982
-
[54]
Hallucinations: Research and practice , pages=
The construction of hallucination: history and epistemology , author=. Hallucinations: Research and practice , pages=. 2011 , publisher=
2011
-
[56]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
On faithfulness and factuality in abstractive summarization , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[57]
ACM computing surveys , volume=
Survey of hallucination in natural language generation , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[58]
Computational Linguistics , volume=
�� Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models , author=. Computational Linguistics , volume=. 2025 , publisher=
2025
-
[59]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[63]
Applied and Computational Engineering , volume=
A survey of hallucination problems based on large language models , author=. Applied and Computational Engineering , volume=
-
[64]
arXiv preprint arXiv:2401.11817 , year=
Hallucination is inevitable: An innate limitation of large language models , author=. arXiv preprint arXiv:2401.11817 , year=
-
[66]
Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design , pages=
Generative AI agents in autonomous machines: A safety perspective , author=. Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design , pages=
-
[67]
2002 , publisher=
You're too kind: A brief history of flattery , author=. 2002 , publisher=
2002
-
[68]
2001 , school=
The Gift of flattery: a social and biological analysis of deceptive practices , author=. 2001 , school=
2001
-
[69]
ESUT Journal of Social Sciences , volume=
Sycophancy and Dearth of Integrity in Governance , author=. ESUT Journal of Social Sciences , volume=
-
[70]
Intelligent Computing-Proceedings of the Computing Conference , pages=
Sycophancy in large language models: Causes and mitigations , author=. Intelligent Computing-Proceedings of the Computing Conference , pages=. 2025 , organization=
2025
-
[73]
International Conference on Learning Representations , volume=
Towards understanding sycophancy in language models , author=. International Conference on Learning Representations , volume=
-
[75]
Expanding on Sycophancy , year =
-
[76]
Findings of the association for computational linguistics: ACL 2023 , pages=
Discovering language model behaviors with model-written evaluations , author=. Findings of the association for computational linguistics: ACL 2023 , pages=
2023
-
[79]
Science , volume=
Sycophantic AI decreases prosocial intentions and promotes dependence , author=. Science , volume=. 2026 , publisher=
2026
-
[81]
2024 IEEE conference on artificial intelligence (CAI) , pages=
AI hallucinations: a misnomer worth clarifying , author=. 2024 IEEE conference on artificial intelligence (CAI) , pages=. 2024 , organization=
2024
-
[82]
Proceedings Fourth IEEE international conference on automatic face and gesture recognition (Cat
Hallucinating faces , author=. Proceedings Fourth IEEE international conference on automatic face and gesture recognition (Cat. No. PR00580) , pages=. 2000 , organization=
2000
-
[83]
Frontiers in Artificial Intelligence , volume=
AI, agentic models and lab automation for scientific discovery—the beginning of scAInce , author=. Frontiers in Artificial Intelligence , volume=. 2025 , publisher=
2025
-
[84]
Patterns , volume=
The reanimation of pseudoscience in machine learning and its ethical repercussions , author=. Patterns , volume=. 2024 , publisher=
2024
-
[85]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
An open-source data contamination report for large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[87]
arXiv preprint arXiv:2412.18619 , year=
Next token prediction towards multimodal intelligence: A comprehensive survey , author=. arXiv preprint arXiv:2412.18619 , year=
-
[88]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
UAQFact: Evaluating Factual Knowledge Utilization of LLMs on Unanswerable Questions , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[89]
Mohamad Abou Ali, Fadi Dornaika, and Jinan Charafeddine. 2025. Agentic ai: a comprehensive survey of architectures, applications, and future directions. Artificial Intelligence Review, 59(1):11
2025
-
[90]
Deepak Bhaskar Acharya, Karthigeyan Kuppan, and B Divya. 2025. Agentic ai: Autonomous intelligence for complex goals—a comprehensive survey. IEEe Access, 13:18912--18936
2025
-
[91]
Aisha Alansari and Hamzah Luqman. 2025. Large language models hallucination: A comprehensive survey. arXiv preprint arXiv:2510.06265
arXiv 2025
-
[92]
Mel Andrews, Andrew Smart, and Abeba Birhane. 2024. The reanimation of pseudoscience in machine learning and its ethical repercussions. Patterns, 5(9)
2024
-
[93]
Anthropic . 2026 a . Claude code. https://www.anthropic.com/product/claude-code
2026
-
[94]
Anthropic . 2026 b . Claude opus 4.6. https://www.anthropic.com/news/claude-opus-4-6
2026
-
[95]
Anthropic . 2026 c . Claude opus 4.7. https://www.anthropic.com/news/claude-opus-4-7
2026
-
[96]
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, and 1 others. 2022. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073
Pith/arXiv arXiv 2022
-
[97]
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. 2024. Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930
Pith/arXiv arXiv 2024
-
[98]
Baidu Tieba . 2026. Minke bar. https://tieba.baidu.com/f?kw=
2026
-
[99]
Stefanos Balaskas. 2026. From recommendations to delegation: A systematic review mapping agentic ai in e-commerce and its consumer effects. Information, 17(3):222
2026
-
[100]
Ajay Bandi, Bhavani Kongari, Roshini Naguru, Sahitya Pasnoor, and Sri Vidya Vilipala. 2025. The rise of agentic ai: A review of definitions, frameworks, architectures, applications, evaluation metrics, and challenges. Future Internet, 17(9):404
2025
-
[101]
Saikat Barua. 2024. Exploring autonomous agents through the lens of large language models: A review. arXiv preprint arXiv:2404.04442
arXiv 2024
-
[102]
Kat Boboris. 2025. Attention authors: Updated practice for review articles and position papers in arxiv cs category
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.