Ternary Mamba: Grouped Quantization-Aware Training of W1.58A16 State Space Models
Pith reviewed 2026-06-27 00:52 UTC · model grok-4.3
The pith
A pretrained Mamba-2 checkpoint can be turned into a ternary model with grouped QAT and distillation using only 102 million tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Grouped quantization-aware training with knowledge distillation from a frozen FP16 teacher applied to a pretrained Mamba-2 1.3B checkpoint yields a W1.58A16 model that occupies 744 MB instead of 2,687 MB and reaches 48.1 percent average zero-shot accuracy on seven tasks after 102 million tokens, coming within 0.9 percentage points of Bi-Mamba while using roughly one-thousandth the marginal token budget of from-scratch ternary training.
What carries the argument
Grouped quantization-aware training that jointly optimizes quantization scales and model weights under a distillation loss from the frozen FP16 teacher, which counters zero-ratio collapse during the SSM recurrence.
If this is right
- Model size drops from 2,687 MB to 744 MB while zero-shot accuracy on the seven-task average reaches 48.1 percent.
- Total training cost is limited to 4 GPU-hours on one H100.
- Post-training correction methods that work for transformers produce large accuracy drops because errors accumulate through the SSM recurrence.
- Zero-ratio collapse appears only in the QAT-from-pretrained regime and must be managed by the grouped scale updates.
- The marginal token requirement falls by a factor of roughly 1,000 relative to the 150 billion tokens used in earlier from-scratch ternary SSM training.
Where Pith is reading between the lines
- The same grouped QAT recipe may allow rapid adaptation of other pretrained SSM variants to ternary weights without repeating full pretraining.
- Because the method works from an existing checkpoint, it opens the possibility of periodic on-device fine-tuning of compressed models when new data arrives.
- The observed failure of transformer post-hoc fixes points to the need for recurrence-aware quantization analysis tools that are not yet standard.
- If the 0.3 percentage point gap to Bi-Mamba can be closed with modest extra tokens, the approach would make ternary SSMs competitive for latency-critical applications.
Load-bearing premise
That the recurrent dynamics of the SSM allow the teacher signal to recover performance even after the quantization scales have been learned and the zero ratio has stabilized.
What would settle it
Running the identical 102 million token budget from a random initialization instead of the pretrained checkpoint and finding that accuracy stays well below 48 percent.
Figures

read the original abstract
State Space Models (SSMs) such as Mamba-2 offer linear-time inference but their memory footprint limits edge deployment. Prior ternary SSM work (Slender-Mamba) trains from scratch on 150B tokens; we show a pretrained checkpoint suffices, reducing the marginal token budget by 1,000x. Using grouped quantization-aware training (QAT) with knowledge distillation from a frozen FP16 teacher, we compress Mamba-2 1.3B to 3.61x (2,687 to 744 MB) and achieve 48.1% zero-shot accuracy (7-task average) in just 102M tokens (4 GPU-hours, single H100) -- approaching Bi-Mamba's 48.4% (within +/-0.9pp CI). This QAT-from-pretrained setting reveals zero-ratio collapse, a novel instability caused by learnable quantization scales that does not arise in from-scratch training. We further show that post-hoc correction strategies effective for Transformers fail for SSMs due to error accumulation through the recurrence. These results demonstrate that ternary SSMs do not require expensive from-scratch training: QAT from pretrained checkpoints with KD is a data-efficient alternative.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that grouped quantization-aware training (QAT) with knowledge distillation from a frozen FP16 teacher, starting from a pretrained Mamba-2 1.3B checkpoint, enables effective W1.58A16 compression of state space models. This yields 3.61x size reduction (2687 MB to 744 MB) and 48.1% zero-shot accuracy on a 7-task average using only 102M tokens (4 GPU-hours on one H100), approaching Bi-Mamba's 48.4% within +/-0.9pp CI. The work identifies zero-ratio collapse as a novel instability arising from learnable quantization scales in the QAT-from-pretrained regime (absent in from-scratch training) and shows that post-hoc correction methods effective for Transformers fail for SSMs due to error accumulation through the recurrence. This reduces the marginal token budget by 1000x relative to prior from-scratch ternary SSM training on 150B tokens.
Significance. If the empirical results and ablations hold, the work provides a practical, data-efficient path to ternary SSM deployment that avoids the prohibitive cost of from-scratch training. The 1000x token reduction, explicit comparison to Bi-Mamba with CI, and the identification of recurrence-specific quantization instabilities (zero-ratio collapse and failure of post-hoc fixes) are load-bearing contributions that could guide quantization research on recurrent architectures. The use of grouped QAT plus KD from pretrained checkpoints is a reproducible empirical finding with clear baselines.
major comments (3)
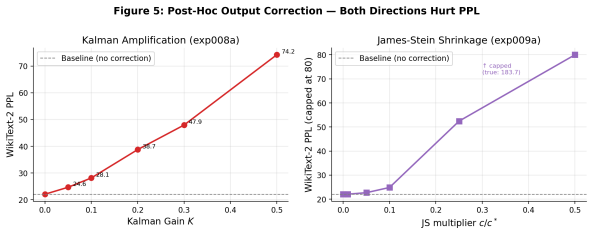
- [§4.3] §4.3 (Post-hoc correction experiments): the central claim that post-hoc strategies fail for SSMs due to recurrence error accumulation is load-bearing for arguing QAT-from-pretrained is necessary, yet the manuscript provides no quantitative measurement of state error propagation (e.g., via controlled injection of quantization noise into the recurrence and tracking of hidden-state drift over sequence length).
- [Table 2] Table 2 and §5.1 (zero-shot results): the 48.1% vs 48.4% comparison is reported with a +/-0.9pp CI, but the text does not specify the number of evaluation runs, task-level variance, or whether the CI accounts for multiple-testing across the 7 tasks; this weakens the claim of statistical parity.
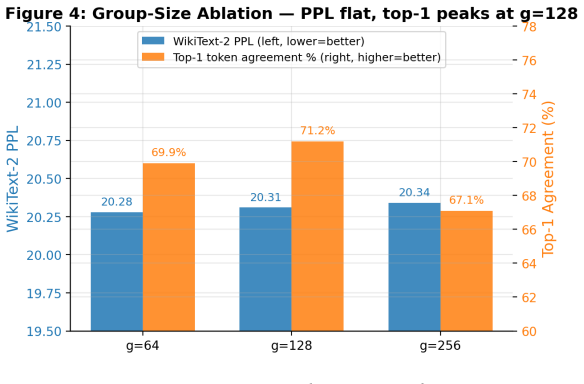
- [§3.2] §3.2 (zero-ratio collapse definition): the novel instability is attributed to learnable quantization scales, but the manuscript does not include an ablation isolating the effect of learnable vs. fixed scales on the observed collapse, leaving open whether the phenomenon is specific to the grouped QAT formulation or more general.
minor comments (3)
- The abstract and §2 reference 'Bi-Mamba' as a baseline without an explicit citation or description of its architecture/training details in the main text; this should be clarified for reproducibility.
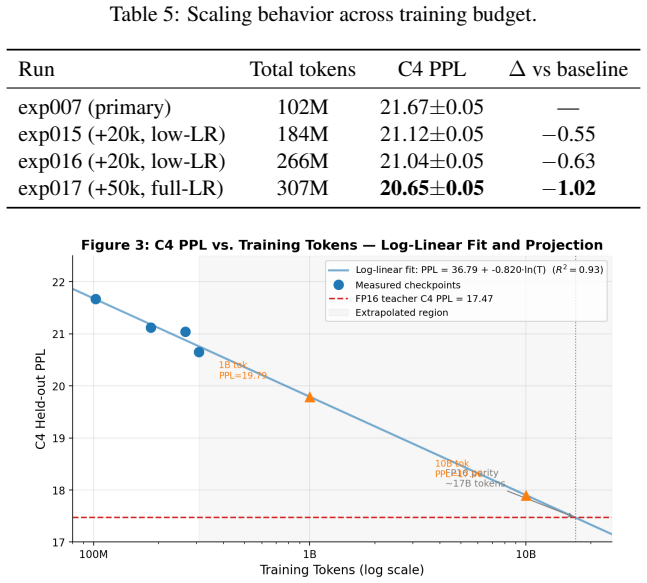
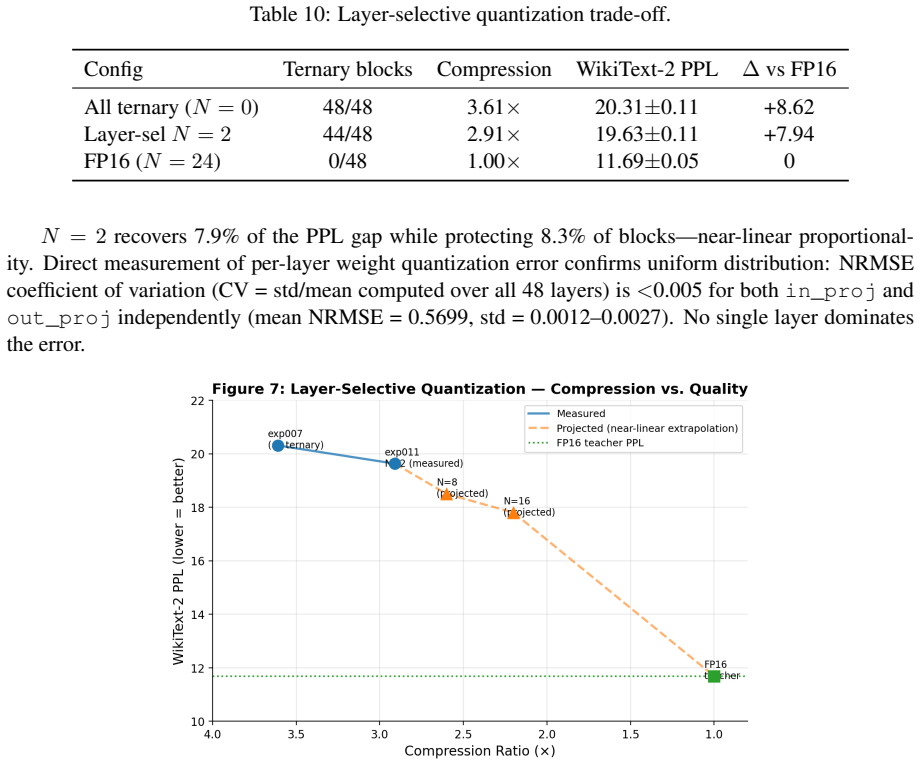
- [Figure 3] Figure 3 (zero-ratio collapse visualization): the y-axis scaling and legend placement make it difficult to read the exact zero-ratio values at convergence; consider adding a table of final ratios.
- The token budget comparison (150B vs 102M) assumes identical model size and task distribution between Slender-Mamba and the current experiments; a short note confirming this would strengthen the 1000x claim.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments. We address each major point below and commit to revisions that strengthen the manuscript without misrepresenting the existing results.
read point-by-point responses
-
Referee: [§4.3] §4.3 (Post-hoc correction experiments): the central claim that post-hoc strategies fail for SSMs due to recurrence error accumulation is load-bearing for arguing QAT-from-pretrained is necessary, yet the manuscript provides no quantitative measurement of state error propagation (e.g., via controlled injection of quantization noise into the recurrence and tracking of hidden-state drift over sequence length).
Authors: We agree that a direct quantitative measurement of state error propagation would provide stronger support for the recurrence-specific claim. In the revised manuscript we will add a controlled experiment that injects synthetic quantization noise into the hidden states and tracks drift in hidden-state norms over increasing sequence lengths, with direct comparison to Transformer baselines. revision: yes
-
Referee: [Table 2] Table 2 and §5.1 (zero-shot results): the 48.1% vs 48.4% comparison is reported with a +/-0.9pp CI, but the text does not specify the number of evaluation runs, task-level variance, or whether the CI accounts for multiple-testing across the 7 tasks; this weakens the claim of statistical parity.
Authors: We will revise §5.1 and the caption of Table 2 to explicitly state the number of evaluation runs used to compute the CI, report task-level standard deviations, and confirm that the interval incorporates a correction for multiple testing across the seven tasks. revision: yes
-
Referee: [§3.2] §3.2 (zero-ratio collapse definition): the novel instability is attributed to learnable quantization scales, but the manuscript does not include an ablation isolating the effect of learnable vs. fixed scales on the observed collapse, leaving open whether the phenomenon is specific to the grouped QAT formulation or more general.
Authors: We will add a targeted ablation in §3.2 that compares zero-ratio collapse when quantization scales are learnable versus held fixed (initialized from the pretrained checkpoint) under otherwise identical QAT-from-pretrained conditions. This will isolate the contribution of learnable scales. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports empirical outcomes of grouped QAT with KD on a pretrained Mamba-2 checkpoint, including measured compression (3.61x), token count (102M), accuracy (48.1%), and comparisons to baselines such as Bi-Mamba. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the inputs; the zero-ratio collapse and recurrence-error observations are presented as experimental findings rather than self-defined predictions. No load-bearing self-citations or uniqueness theorems appear in the abstract or described claims. The work is therefore self-contained as an empirical demonstration.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable quantization scales
axioms (1)
- domain assumption Knowledge distillation from a frozen FP16 teacher improves ternary quantization outcomes for SSMs.
invented entities (1)
-
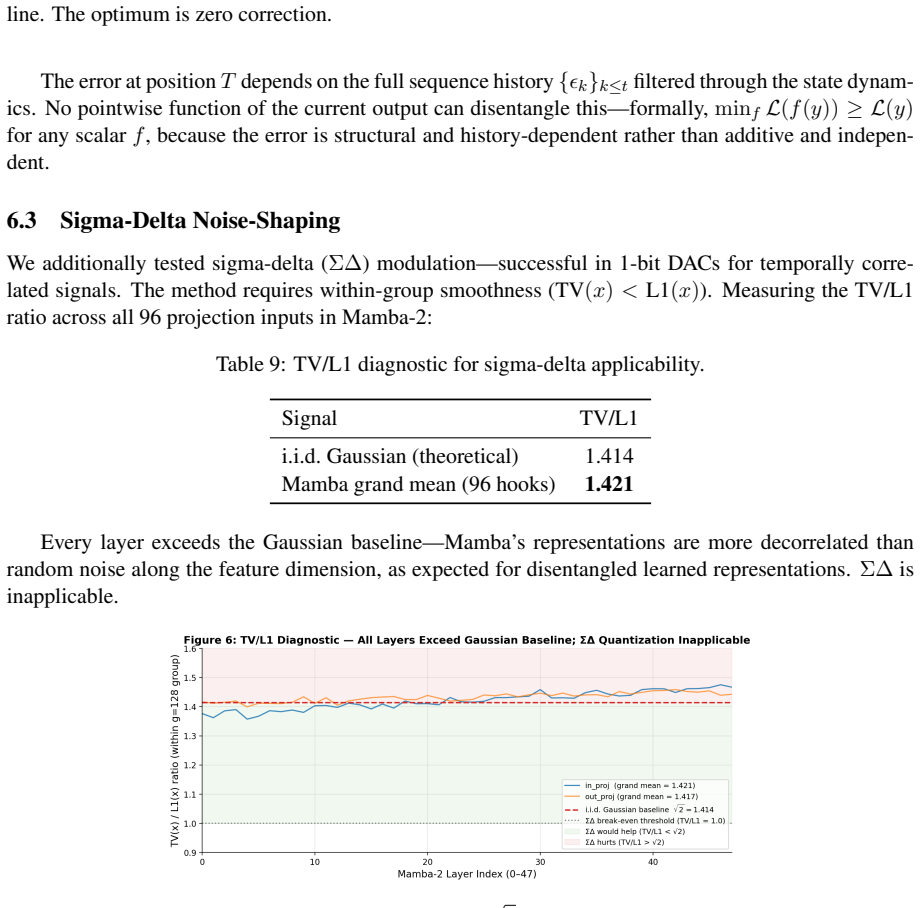
zero-ratio collapse
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[2]
Hung-Yi Chiang, Hung-Yueh Guo, Zhewei Chang, Andreas Gerstlauer, and Diana Ding. Quamba2: Robust and efficient post-training quantization for selective state space models.arXiv preprint arXiv:2503.22879, 2025. 9
-
[3]
Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[4]
Hung-Yueh Guo, Zhewei Chang, Anthony Todd, Yushu Lu, Han Cheng, Andreas Gerstlauer, and Diana Ding. Quamba: A post-training quantization recipe for selective state space models.arXiv preprint arXiv:2410.13229, 2024
-
[5]
ParetoQ: Scaling laws in extremely low-bit LLM quantization.arXiv preprint arXiv:2502.02631, 2025
Byeongwook Heo, Yeonwoo Oh, Dongsoo Park, and Jungwook Yoo. ParetoQ: Scaling laws in extremely low-bit LLM quantization.arXiv preprint arXiv:2502.02631, 2025
-
[6]
Estimation with quadratic loss
William James and Charles Stein. Estimation with quadratic loss. InProceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pages 361–379, 1961
1961
-
[7]
Zhongnan Li, Long Qian, and Ye Yuan. QEP: Quantization error projection for post-training cor- rection.arXiv preprint arXiv:2501.08789, 2025
-
[8]
Zukang Lin, Lirui Chen, Zheyu Yao, Qiang Du, and Song Han. MambaQuant: Quantizing the mamba family with variance alignment rotations.arXiv preprint arXiv:2504.16385, 2025
-
[9]
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. The era of 1-bit LLMs: All large language models are in 1.58 bits.arXiv preprint arXiv:2402.17764, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Alessandro Pierro, Luca Rosenbauer, Annika Kuhn, Bernt Schiele, and Horst Possegger. Mamba- PTQ: Outlier channels in recurrent large language models.arXiv preprint arXiv:2407.12397, 2024
-
[11]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
2020
-
[12]
Shengkun Tang, Yaqing Li, Caiying Leng, Xianjing Zhang, Yao Zhu, Ting Zhao, Di Niu, Mengdi Liu, Shiwei Tang, and Yubo Tian. Bi-mamba: Towards accurate 1-bit state space models.Transac- tions on Machine Learning Research (TMLR), 2025. arXiv:2411.11843
-
[13]
Shijie Yang, Zitao Guo, Zhuocheng Liu, and Meng Yang. TernaryLLM: A lightweight ternary LLM with asymmetric dual learnable ternarization.arXiv preprint arXiv:2406.07177, 2025
-
[14]
Slender-mamba: Fully quantized mamba in 1.58 bits from head to toe
Zekun Yu, Takeshi Kojima, Yutaka Matsuo, and Yusuke Iwasawa. Slender-mamba: Fully quantized mamba in 1.58 bits from head to toe. InProceedings of the 31st International Conference on Computational Linguistics (COLING), pages 4715–4724, 2025
2025
-
[15]
LREC: Low-rank error correction for quantized LLMs.arXiv preprint arXiv:2405.14673, 2024
Yifei Zhang, Yifan Li, Qiang Li, and Wei Gao. LREC: Low-rank error correction for quantized LLMs.arXiv preprint arXiv:2405.14673, 2024. A Extended Results A.1 Training Hyperparameters A.2 Parameter Budget A.3 Negative Result: HG-GSQ Hessian-guided Gumbel-Softmax quantization (targeting top-30% importance weights with differen- tiable discrete optimization...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.