MOCHI: Motion Enhancement of Collaborative Human-object Interactions
Pith reviewed 2026-06-27 01:19 UTC · model grok-4.3
The pith
MOCHI enhances noisy collaborative human-object interaction data through grasp optimization and diffusion-based motion refinement using single-person priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
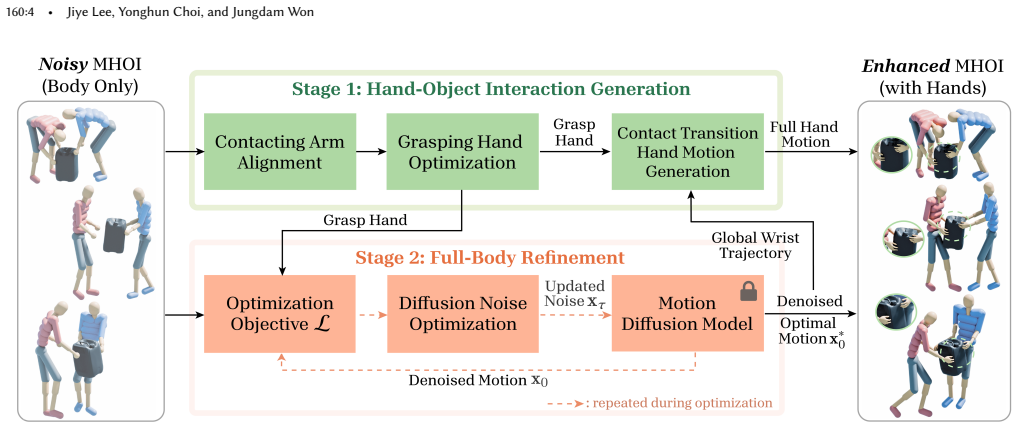
MOCHI is a two-stage pipeline that first generates physically plausible hand grasps through optimization from noisy body input and extends them into complete hand-object sequences, then refines full-body motions for all participants using a diffusion-based noise optimization framework augmented with objectives that encode human-object and human-human interaction information within single-person motion priors.
What carries the argument
Diffusion-based noise optimization framework that encodes human-object and human-human interactions into single-person motion priors.
If this is right
- Works on data from existing capture methods or generative models.
- Robust across varying numbers of participants and interaction types.
- Supports applications such as keyframe-based MHOI creation.
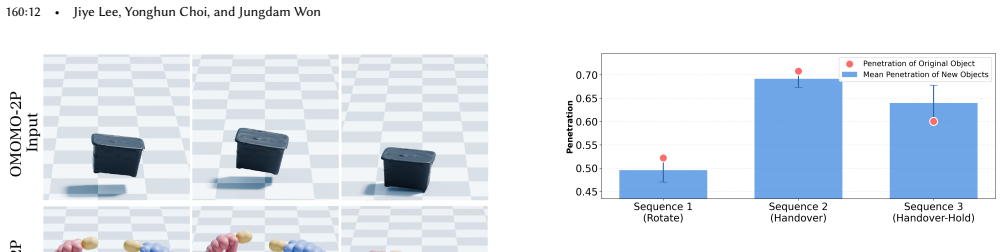
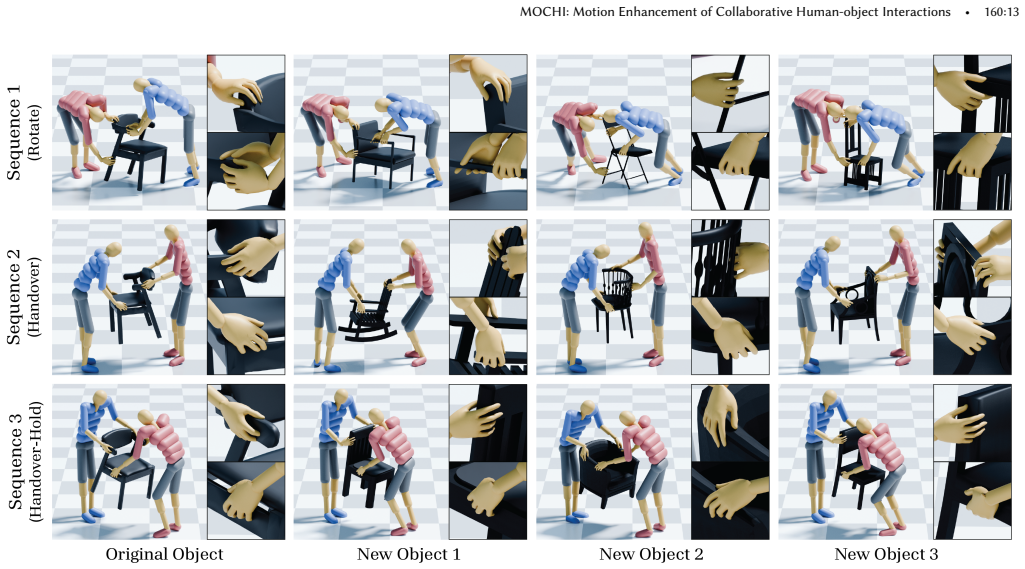
- Enables data augmentation by varying object geometries.
Where Pith is reading between the lines
- If single-person priors can be augmented this way, similar techniques might apply to other multi-agent motion problems like team sports.
- The approach could reduce reliance on specialized multi-person capture equipment.
- Extending the method to real-time applications might improve interactive simulations in VR.
Load-bearing premise
Single-person motion priors can be augmented with additional objectives to encode the mutual anticipation and adjustments in collaborative interactions without introducing breaking artifacts.
What would settle it
Observing whether the optimized motions maintain consistent contacts and smooth trajectories in long sequences of complex multi-person object manipulations that were not used in training.
Figures





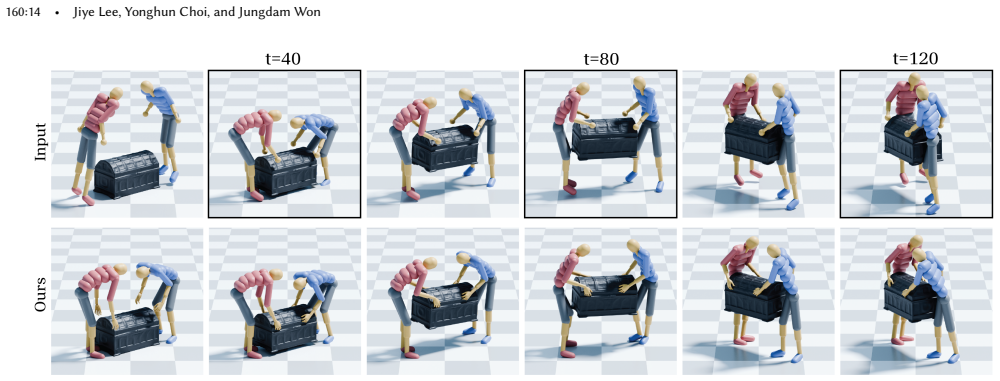
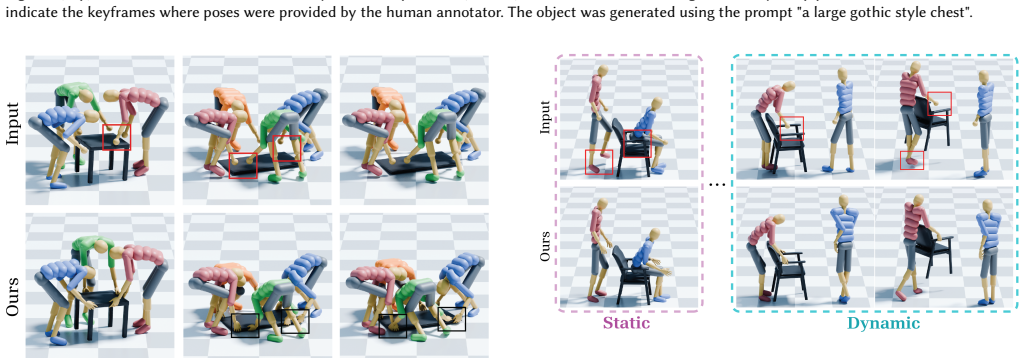
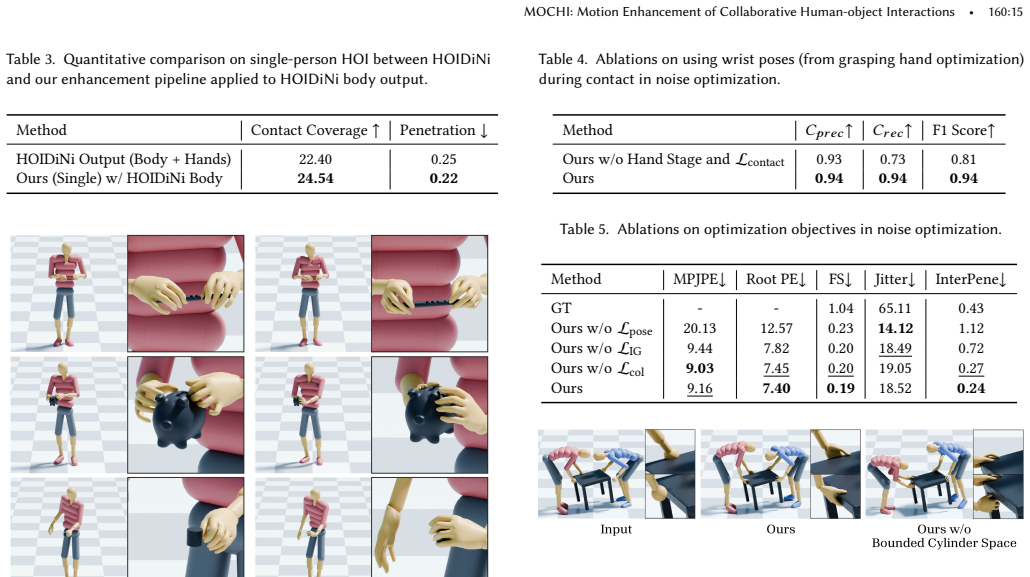

read the original abstract
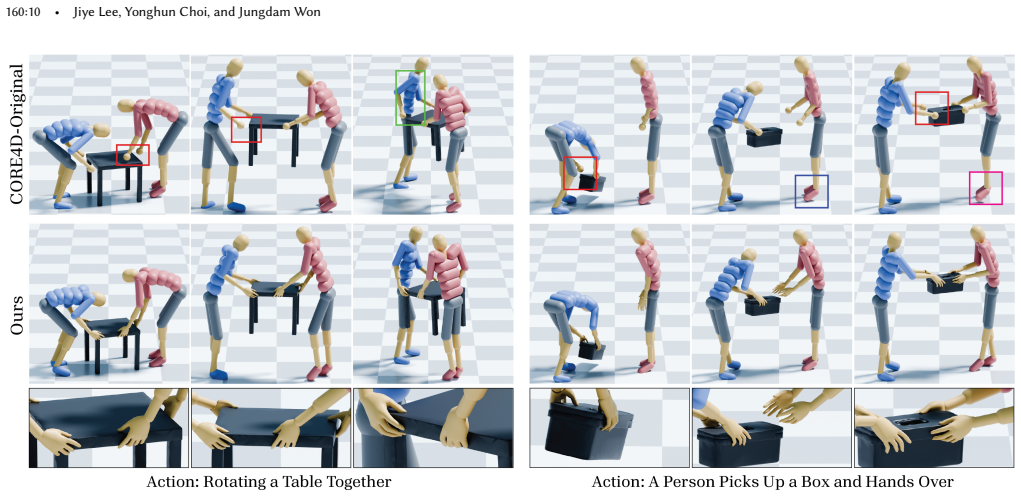
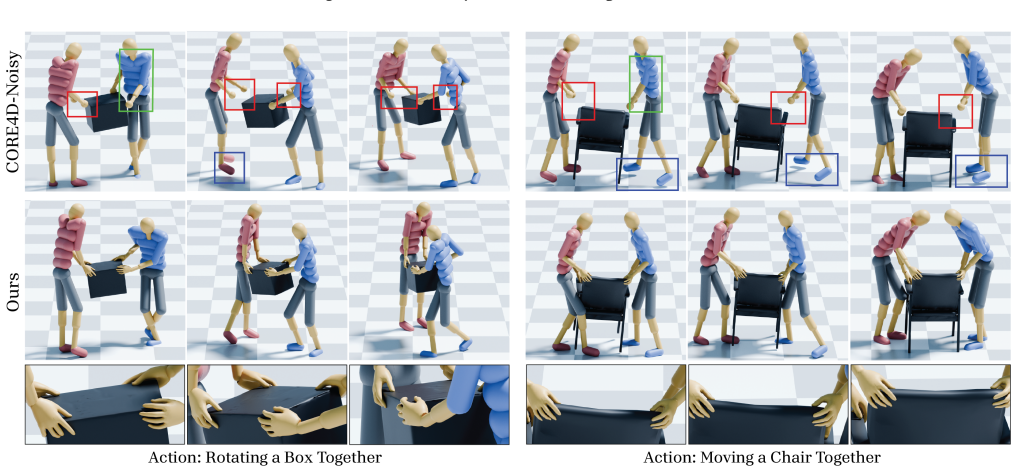
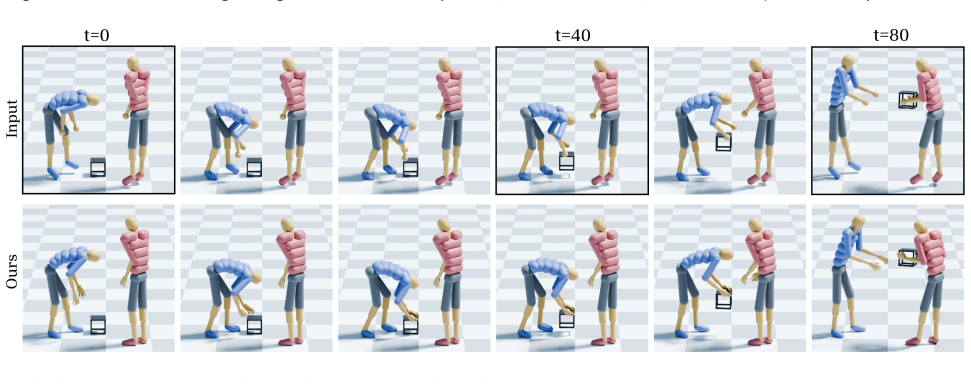
Collaborative human-object interaction shows dynamic and complex movements that require mutual anticipation and continuous adjustment between participants and the shared object. Modeling such collaborative multi-human object interaction (MHOI) scenarios requires high-quality data acquisition as a foundational step; however, this is challenging due to the inherent complexity of MHOI where human-human and human-object interactions occur simultaneously. Such complexity leads to noisy MHOI captures characterized by several artifacts: contact misalignment between hands and objects, motion jitter and temporal inconsistencies in the captured sequences, and missing or incomplete finger-level articulation details. To address these challenges, we present MOCHI (MOtion Enhancement of Collaborative Human-object Interactions), a two-stage framework for enhancing noisy MHOI data. Our approach first generates physically plausible hand grasps through optimization from noisy body input, producing grasps that are both physically plausible and semantically consistent with the body pose, where these optimized grasps are extended into complete hand-object interaction sequences. Consequently, the full-body motion for all participants are refined through a diffusion-based noise optimization framework that uses single-person motion priors. During the optimization process, we introduce optimization objectives to encode human-object and human-human interaction information within these single-person priors. Experimental results demonstrate the effectiveness of our pipeline across diverse MHOI data, either acquired by existing capture methods or synthesized by generative models. We further show robustness of our system across varying numbers of participants and types of interactions, and demonstrate various applications including keyframe-based MHOI creation and data augmentation through varying object geometries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
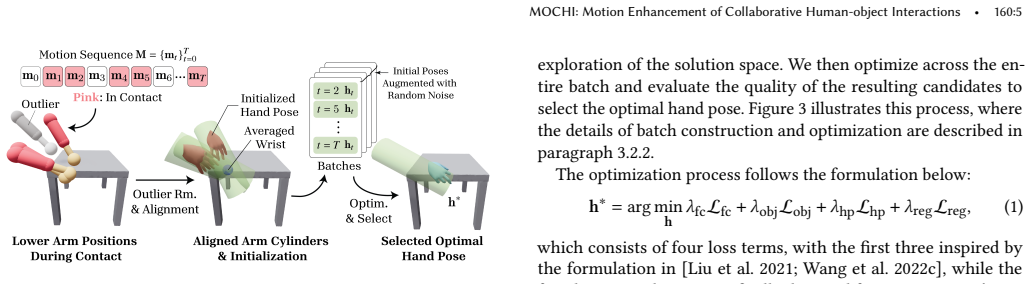
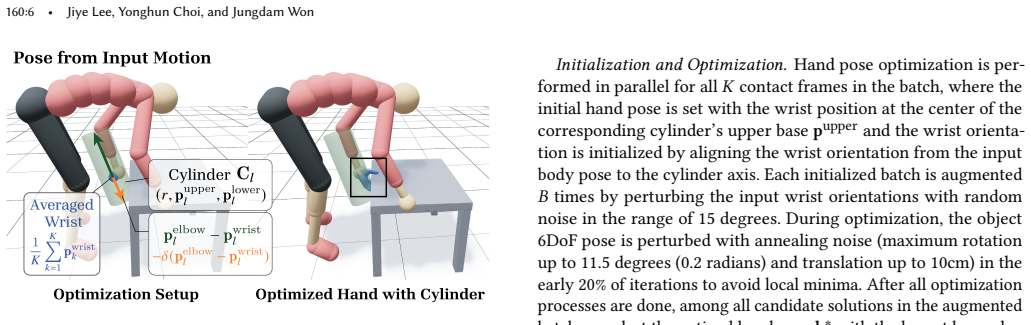
Summary. The paper introduces MOCHI, a two-stage framework for enhancing noisy collaborative multi-human object interaction (MHOI) captures. Stage 1 optimizes physically plausible and semantically consistent hand grasps from noisy body inputs and extends them into full hand-object sequences. Stage 2 refines full-body motions for all participants via diffusion-based noise optimization that augments single-person motion priors with additional objectives encoding human-object and human-human interaction information. The authors claim the pipeline is effective on data from existing capture methods or generative models, robust across varying participant counts and interaction types, and enables applications such as keyframe-based MHOI creation and data augmentation via object geometry variation.
Significance. If the central claims hold with rigorous quantitative support, the work would be significant for computer vision and graphics by providing a practical method to improve the quality of MHOI datasets, a known bottleneck for modeling complex collaborative dynamics. The combination of grasp optimization with diffusion priors augmented by interaction objectives represents a targeted approach to artifact removal while attempting to preserve multi-agent coordination; successful validation could directly benefit downstream tasks in animation, robotics, and interaction synthesis.
major comments (3)
- [Abstract] Abstract: the central claims of effectiveness and robustness across participant numbers and interaction types are asserted without any quantitative metrics, baseline comparisons, error bars, or ablation results; this absence makes it impossible to assess whether the pipeline actually preserves collaborative dynamics or merely removes local artifacts.
- [Method (diffusion-based noise optimization framework)] Diffusion-based refinement stage (described in the method): the approach augments single-person motion priors with high-level objectives for contact consistency and semantic alignment, but provides no derivation or validation showing that these objectives encode mutual anticipation and continuous inter-participant adjustment rather than only local constraints; because the priors originate from individual motion data, this gap is load-bearing for the claim that refined motions maintain collaborative dynamics across diverse interaction types.
- [Experiments] Experimental results section: the robustness claim across varying numbers of participants and interaction types requires explicit cross-condition quantitative evaluation (e.g., metrics stratified by participant count or interaction category) with statistical significance; without such breakdowns or comparisons to single-person-only baselines, the added interaction objectives' contribution cannot be isolated.
minor comments (2)
- [Stage 1] The description of how optimized grasps are 'extended into complete hand-object interaction sequences' lacks implementation details on temporal consistency enforcement.
- [Method] Notation for the interaction objectives (e.g., weights on human-object vs. human-human terms) should be formalized with explicit equations to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We will revise the manuscript to strengthen the presentation of quantitative results and provide additional clarifications in the method and experiments sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of effectiveness and robustness across participant numbers and interaction types are asserted without any quantitative metrics, baseline comparisons, error bars, or ablation results; this absence makes it impossible to assess whether the pipeline actually preserves collaborative dynamics or merely removes local artifacts.
Authors: The abstract summarizes the paper's claims, while detailed quantitative support, including metrics, baselines, and ablations, is provided in the experiments section. We agree this could be better highlighted and will update the abstract to include key quantitative findings on effectiveness and robustness. revision: yes
-
Referee: [Method (diffusion-based noise optimization framework)] Diffusion-based refinement stage (described in the method): the approach augments single-person motion priors with high-level objectives for contact consistency and semantic alignment, but provides no derivation or validation showing that these objectives encode mutual anticipation and continuous inter-participant adjustment rather than only local constraints; because the priors originate from individual motion data, this gap is load-bearing for the claim that refined motions maintain collaborative dynamics across diverse interaction types.
Authors: The interaction objectives are specifically designed to couple the motions of multiple participants through shared contact and semantic terms, thereby encoding collaborative dynamics beyond local constraints. We will add further explanation and examples in the revised method section to validate how these objectives promote inter-participant adjustment. revision: partial
-
Referee: [Experiments] Experimental results section: the robustness claim across varying numbers of participants and interaction types requires explicit cross-condition quantitative evaluation (e.g., metrics stratified by participant count or interaction category) with statistical significance; without such breakdowns or comparisons to single-person-only baselines, the added interaction objectives' contribution cannot be isolated.
Authors: We have evaluated on data with varying participant counts and interaction types, with overall results supporting robustness. To address the request for stratified evaluation, we will include additional breakdowns by participant number and interaction type in the experiments section, along with comparisons to single-person baselines and statistical analysis. revision: yes
Circularity Check
No circularity in derivation; method uses external priors plus new objectives
full rationale
The paper describes a two-stage pipeline: (1) optimization to produce physically plausible grasps from noisy body input, (2) diffusion-based refinement of full-body motion that starts from single-person motion priors and augments them with human-object and human-human interaction objectives. No equation or step equates a claimed output (enhanced collaborative motion) to its inputs by construction, nor does any load-bearing claim rest on a self-citation chain or fitted parameter renamed as prediction. The priors are external; the added objectives are presented as novel constraints. The experimental claims rest on qualitative/quantitative evaluation against capture artifacts rather than on any self-referential reduction. This is the normal non-circular case for a methods paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights on interaction objectives
axioms (1)
- domain assumption Single-person motion priors remain a useful base when augmented with interaction terms for collaborative multi-person scenarios
Reference graph
Works this paper leans on
-
[1]
ACM Trans
Object Motion Guided Human Motion Synthesis , author=. ACM Trans. Graph. , volume=
-
[2]
ECCV , year=
Controllable human-object interaction synthesis , author=. ECCV , year=
-
[3]
ICCV , year=
Human-object interaction from human-level instructions , author=. ICCV , year=
-
[4]
arXiv preprint arXiv:2506.15625 , year=
Hoidini: Human-object interaction through diffusion noise optimization , author=. arXiv preprint arXiv:2506.15625 , year=
-
[5]
Xu, Sirui and Li, Zhengyuan and Wang, Yu-Xiong and Gui, Liang-Yan , booktitle=
-
[6]
arXiv preprint arXiv:2403.11237 , year=
FORCE: Physics-aware Human-object Interaction , author=. arXiv preprint arXiv:2403.11237 , year=
-
[7]
ECCV , year =
COUCH: Towards Controllable Human-Chair Interactions , author =. ECCV , year =
-
[8]
CVPR , year=
Sapien: A simulated part-based interactive environment , author=. CVPR , year=
-
[9]
, author=
Neural state machine for character-scene interactions. , author=. ACM Trans. Graph. , volume=
-
[10]
ICCV , year =
Stochastic Scene-Aware Motion Prediction , author =. ICCV , year =
-
[11]
AAAI , year=
Learning to sit: Synthesizing human-chair interactions via hierarchical control , author=. AAAI , year=
-
[12]
ACM Trans
Model predictive control with a visuomotor system for physics-based character animation , author=. ACM Trans. Graph. , volume=
-
[13]
ACM Trans
Learning to use chopsticks in diverse gripping styles , author=. ACM Trans. Graph. , volume=
-
[14]
ACM Trans
Catch & Carry: reusable neural controllers for vision-guided whole-body tasks , author=. ACM Trans. Graph. , volume=
-
[15]
2022 , booktitle =
Lee, Seunghwan and Chang, Phil Sik and Lee, Jehee , title =. 2022 , booktitle =
2022
-
[16]
ACM SIGGRAPH 2023 Conference Proceedings , year=
Synthesizing physical character-scene interactions , author=. ACM SIGGRAPH 2023 Conference Proceedings , year=
2023
-
[17]
ACM SIGGRAPH 2023 Conference Proceedings , year=
Pmp: Learning to physically interact with environments using part-wise motion priors , author=. ACM SIGGRAPH 2023 Conference Proceedings , year=
2023
-
[18]
CVPR , year=
Circle: Capture in rich contextual environments , author=. CVPR , year=
-
[19]
ECCV , year=
Gimo: Gaze-informed human motion prediction in context , author=. ECCV , year=
-
[20]
CVPR , year=
Scaling up dynamic human-scene interaction modeling , author=. CVPR , year=
-
[21]
arXiv preprint arXiv:2406.19353 , year=
Core4d: A 4d human-object-human interaction dataset for collaborative object rearrangement , author=. arXiv preprint arXiv:2406.19353 , year=
-
[22]
CVPR , year=
Behave: Dataset and method for tracking human object interactions , author=. CVPR , year=
-
[23]
arXiv preprint arXiv:2401.10232 , year=
Parahome: Parameterizing everyday home activities towards 3d generative modeling of human-object interactions , author=. arXiv preprint arXiv:2401.10232 , year=
-
[24]
ECCV , year=
Nymeria: A massive collection of multimodal egocentric daily motion in the wild , author=. ECCV , year=
-
[25]
arXiv preprint arXiv:2404.00299 , year=
HOI-M3: Capture Multiple Humans and Objects Interaction within Contextual Environment , author=. arXiv preprint arXiv:2404.00299 , year=
-
[26]
Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation , year=
Tiling motion patches , author=. Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation , year=
-
[27]
ACM SIGGRAPH 2006 Papers , year=
Motion patches: building blocks for virtual environments annotated with motion data , author=. ACM SIGGRAPH 2006 Papers , year=
2006
-
[28]
ACM Transactions on Graphics (TOG) , year=
Interaction patches for multi-character animation , author=. ACM Transactions on Graphics (TOG) , year=
-
[29]
Proceedings of the 2007 ACM symposium on Virtual reality software and technology , year=
Simulating competitive interactions using singly captured motions , author=. Proceedings of the 2007 ACM symposium on Virtual reality software and technology , year=
2007
-
[30]
Proceedings of the 2008 Symposium on interactive 3D Graphics and Games , year=
Simulating interactions of avatars in high dimensional state space , author=. Proceedings of the 2008 Symposium on interactive 3D Graphics and Games , year=
2008
-
[31]
IEEE TVCG , year=
Simulating multiple character interactions with collaborative and adversarial goals , author=. IEEE TVCG , year=
-
[32]
Proceedings of the 2006 ACM SIGGRAPH/Eurographics symposium on Computer animation , year=
Composition of complex optimal multi-character motions , author=. Proceedings of the 2006 ACM SIGGRAPH/Eurographics symposium on Computer animation , year=
2006
-
[33]
European Conference on Computer Vision , year=
Remos: 3d motion-conditioned reaction synthesis for two-person interactions , author=. European Conference on Computer Vision , year=
-
[34]
IJCV , year=
Intergen: Diffusion-based multi-human motion generation under complex interactions , author=. IJCV , year=
-
[35]
CVPR , year=
Inter-x: Towards versatile human-human interaction analysis , author=. CVPR , year=
-
[36]
ACM Transactions on Graphics (TOG) , year=
Neural animation layering for synthesizing martial arts movements , author=. ACM Transactions on Graphics (TOG) , year=
-
[37]
arXiv preprint arXiv:2303.01418 , year=
Human motion diffusion as a generative prior , author=. arXiv preprint arXiv:2303.01418 , year=
-
[38]
CVPR , year=
Towards social artificial intelligence: Nonverbal social signal prediction in a triadic interaction , author=. CVPR , year=
-
[39]
ACM Transactions on Graphics (TOG) , year=
Generating and ranking diverse multi-character interactions , author=. ACM Transactions on Graphics (TOG) , year=
-
[40]
ACM Transactions on Graphics (TOG) , year=
Control strategies for physically simulated characters performing two-player competitive sports , author=. ACM Transactions on Graphics (TOG) , year=
-
[41]
ICCV , year =
Locomotion-Action-Manipulation: Synthesizing Human-Scene Interactions in Complex 3D Environments , author =. ICCV , year =
-
[42]
CVPR , year=
Synthesizing long-term 3d human motion and interaction in 3d scenes , author=. CVPR , year=
-
[43]
CVPR , year=
Towards Diverse and Natural Scene-aware 3D Human Motion Synthesis , author=. CVPR , year=
-
[44]
ECCV , year=
Long-term human motion prediction with scene context , author=. ECCV , year=
-
[45]
CVPR , year=
Scene-aware Generative Network for Human Motion Synthesis , author=. CVPR , year=
-
[46]
NeurIPS , year=
Humanise: Language-conditioned human motion generation in 3d scenes , author=. NeurIPS , year=
-
[47]
ACM SIGGRAPH Asia 2024 Conference Proceedings , year=
Autonomous character-scene interaction synthesis from text instruction , author=. ACM SIGGRAPH Asia 2024 Conference Proceedings , year=
2024
-
[48]
arXiv preprint arXiv:2503.19901 , year=
TokenHSI: Unified Synthesis of Physical Human-Scene Interactions through Task Tokenization , author=. arXiv preprint arXiv:2503.19901 , year=
-
[49]
ACM SIGGRAPH 2023 Conference Proceedings , year=
Simulation and retargeting of complex multi-character interactions , author=. ACM SIGGRAPH 2023 Conference Proceedings , year=
2023
-
[50]
ACM SIGGRAPH 2010 papers , year=
Spatial relationship preserving character motion adaptation , author=. ACM SIGGRAPH 2010 papers , year=
2010
-
[51]
Denoising Diffusion Implicit Models
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
A cross-dataset study for text-based 3D human motion retrieval , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
Human motion diffusion model , author=. arXiv preprint arXiv:2209.14916 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
CVPR , year=
Optimizing diffusion noise can serve as universal motion priors , author=. CVPR , year=
-
[55]
CVPR , year=
Avatars grow legs: Generating smooth human motion from sparse tracking inputs with diffusion model , author=. CVPR , year=
-
[56]
ACM Transactions on Graphics (TOG) , year=
Robust solving of optical motion capture data by denoising , author=. ACM Transactions on Graphics (TOG) , year=
-
[57]
arXiv preprint arXiv:2505.01425 , year=
GENMO: A GENeralist Model for Human MOtion , author=. arXiv preprint arXiv:2505.01425 , year=
-
[58]
ICCV , year=
Learning motion priors for 4d human body capture in 3d scenes , author=. ICCV , year=
-
[59]
ICCV , year=
Humor: 3d human motion model for robust pose estimation , author=. ICCV , year=
-
[60]
ICCV , year =
Shi, Mingyi and Starke, Sebastian and Ye, Yuting and Komura, Taku and Won, Jungdam , title =. ICCV , year =
-
[61]
CVPR , year =
Zhang, Siwei and Bhatnagar, Bharat Lal and Xu, Yuanlu and Winkler, Alexander and Kadlecek, Petr and Tang, Siyu and Bogo, Federica , title =. CVPR , year =
-
[62]
CVPR , year=
Decoupling Human and Camera Motion from Videos in the Wild , author=. CVPR , year=
-
[63]
2025 , journal=
GENMO: A GENeralist Model for Human MOtion , author=. 2025 , journal=
2025
-
[64]
ACM Transactions on Graphics (TOG) , year=
Phase-functioned neural networks for character control , author=. ACM Transactions on Graphics (TOG) , year=
-
[65]
2022 , journal =
Starke, Sebastian and Mason, Ian and Komura, Taku , title =. 2022 , journal =
2022
-
[66]
NeurIPS , year=
Nemf: Neural motion fields for kinematic animation , author=. NeurIPS , year=
-
[67]
CVPR , year=
Ego-Body Pose Estimation via Ego-Head Pose Estimation , author=. CVPR , year=
-
[68]
ACM Transactions on Graphics (TOG) , year=
Physics-based character controllers using conditional vaes , author=. ACM Transactions on Graphics (TOG) , year=
-
[69]
ACM Transactions on Graphics (TOG) , year=
Character controllers using motion vaes , author=. ACM Transactions on Graphics (TOG) , year=
-
[70]
ICCV , year=
Guided motion diffusion for controllable human motion synthesis , author=. ICCV , year=
-
[71]
ICLR , year=
DartControl: A diffusion-based autoregressive motion model for real-time text-driven motion control , author=. ICLR , year=
-
[72]
arXiv preprint arXiv:2405.11126 , year=
Flexible Motion In-betweening with Diffusion Models , author=. arXiv preprint arXiv:2405.11126 , year=
-
[73]
ICLR , year=
OmniControl: Control Any Joint at Any Time for Human Motion Generation , author=. ICLR , year=
-
[74]
CVPR , year =
Mocap Everyone Everywhere: Lightweight Motion Capture With Smartwatches and a Head-Mounted Camera , author =. CVPR , year =
-
[75]
Pavlakos, Georgios and Choutas, Vasileios and Ghorbani, Nima and Bolkart, Timo and Osman, Ahmed A. A. and Tzionas, Dimitrios and Black, Michael J. , booktitle =. Expressive Body Capture:
-
[76]
ShapeNet: An Information-Rich 3D Model Repository
Shapenet: An information-rich 3d model repository , author=. arXiv preprint arXiv:1512.03012 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
NeurIPS , year=
Denoising diffusion probabilistic models , author=. NeurIPS , year=
-
[78]
CVPR , year=
Contactopt: Optimizing contact to improve grasps , author=. CVPR , year=
-
[79]
Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation
Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation , author=. arXiv preprint arXiv:2210.02697 , year=
-
[80]
IEEE Robotics and Automation Letters , year=
Synthesizing diverse and physically stable grasps with arbitrary hand structures using differentiable force closure estimator , author=. IEEE Robotics and Automation Letters , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.