RELIANCE: Curating and Evaluating Reproductive Health Information on Social Media
Pith reviewed 2026-06-27 07:54 UTC · model grok-4.3
The pith
A clinician-annotated dataset of 336 TikTok videos finds nearly 60 percent of the reproductive health information accurate and exposes a 15 percent gap in how LLMs judge full videos versus individual claims.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
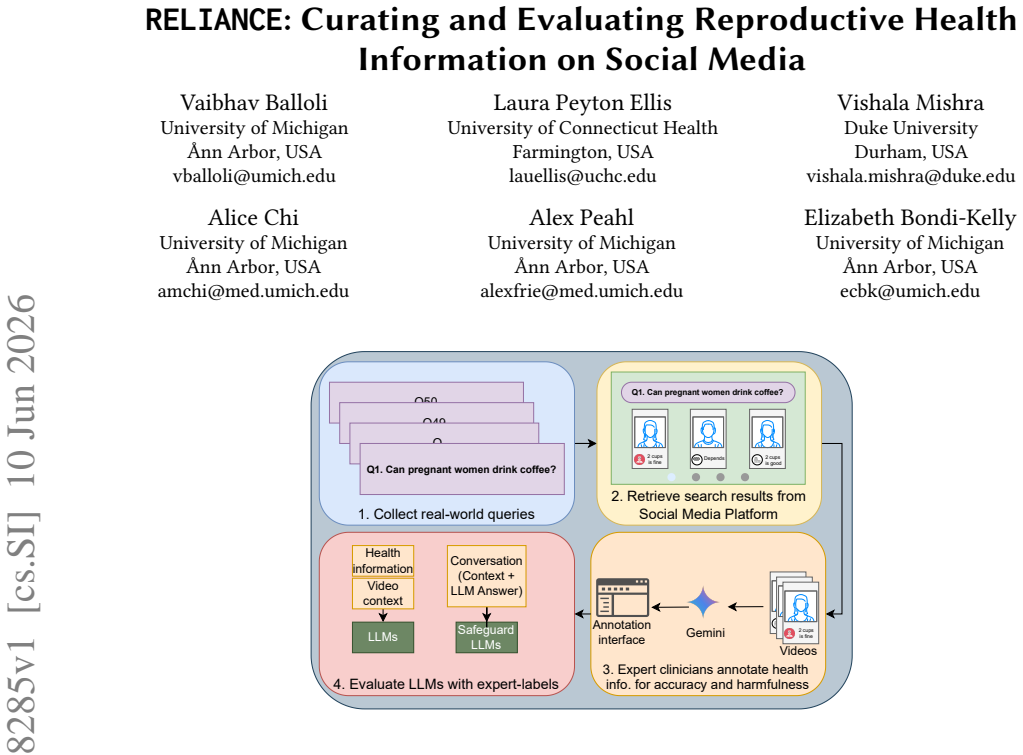
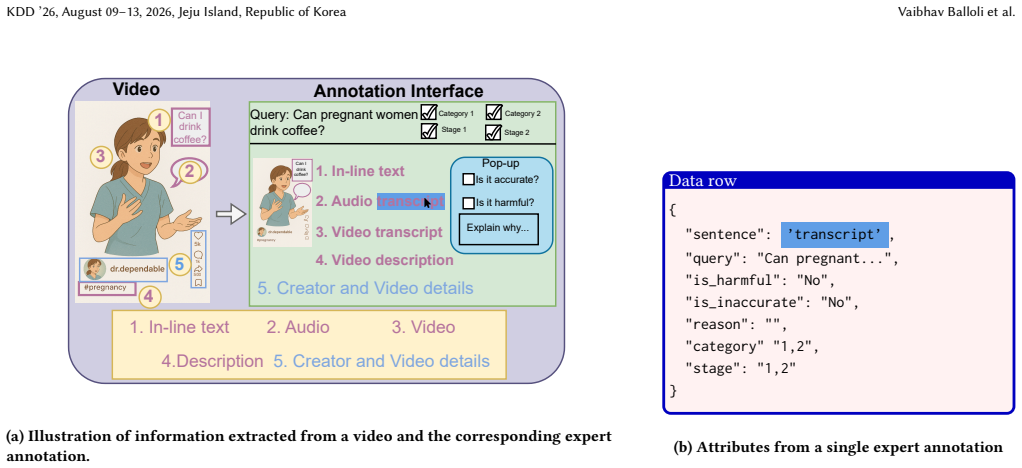
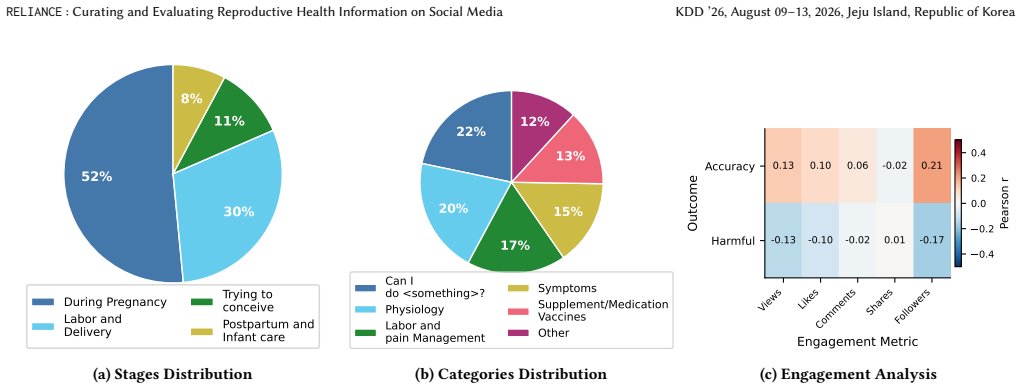
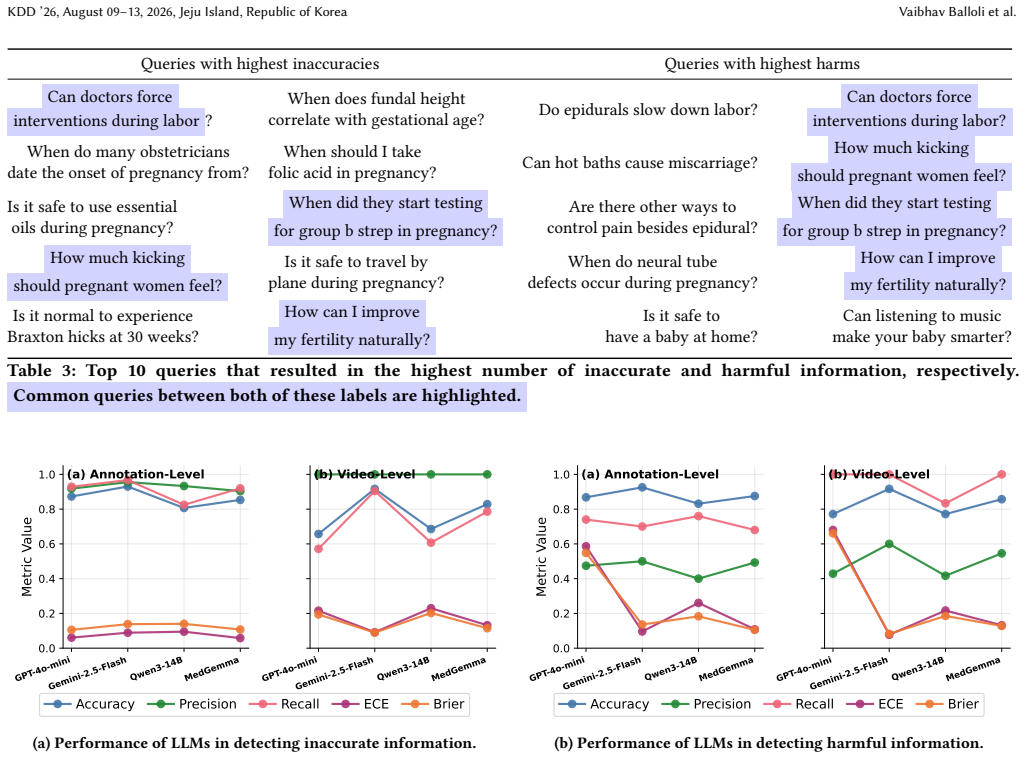
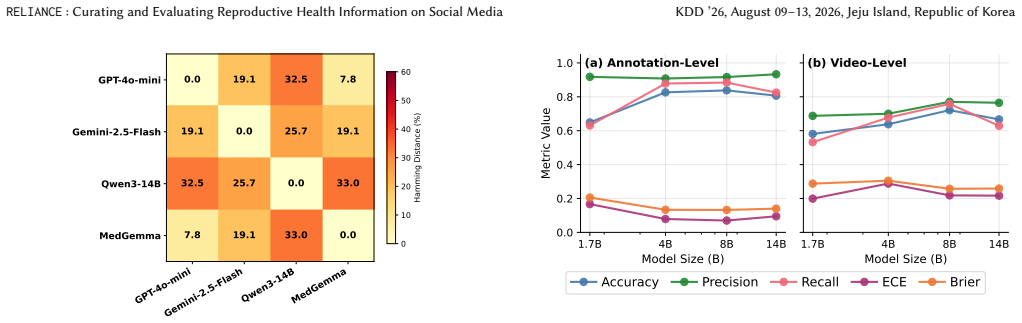
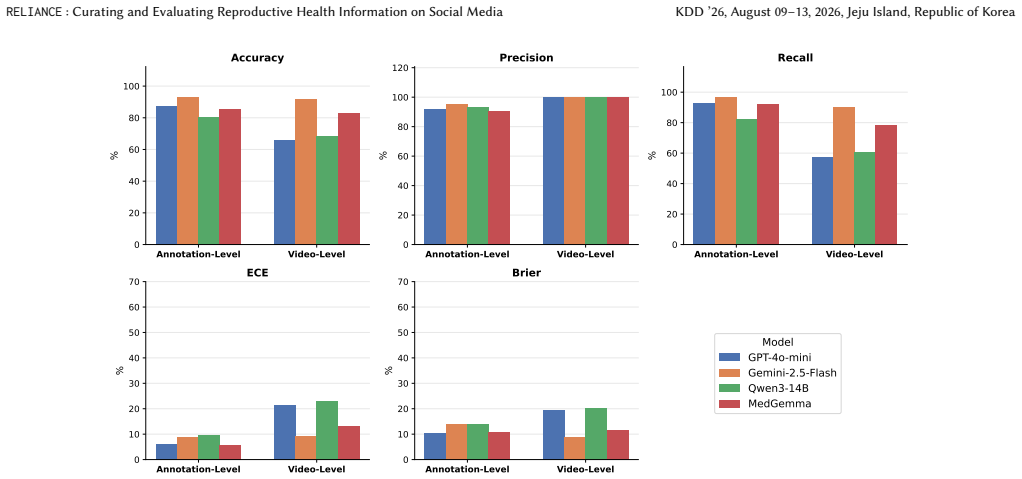
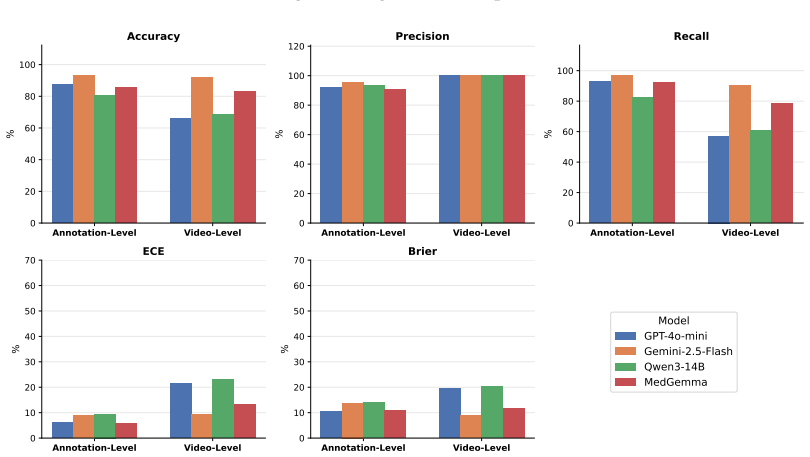
RELIANCE supplies 409 annotated sentences from 336 videos that answer 56 clinician-reviewed queries on pregnancy and postpartum topics; three experts in Obstetrics, Gynecology, and Internal Medicine labeled each sentence for accuracy, producing the finding that nearly 60 percent of the sampled health information is accurate and that LLM evaluators exhibit a 15 percent performance gap between judging specific claims and judging complete video content.
What carries the argument
The RELIANCE dataset, built through clinician review of TikTok video transcripts and full content for accuracy on reproductive health queries.
If this is right
- Platforms and health organizations can treat the 60 percent accuracy rate as a baseline for the amount of reliable versus unreliable reproductive health content currently circulating.
- LLM-based fact-checking systems must be tested on full video context rather than isolated claims if they are to be deployed in reproductive health.
- The annotation protocol and dataset release provide a reusable template for creating similar ground-truth collections on other social platforms or in other health domains.
Where Pith is reading between the lines
- Extending the same clinician-review process to short-form video on additional platforms would allow direct comparison of accuracy rates across services.
- The observed gap between claim-level and video-level evaluation suggests that training data for LLMs should include more examples of holistic content assessment.
- Health professionals could use the dataset to identify the most common categories of inaccurate claims and target public-education efforts accordingly.
Load-bearing premise
The 56 queries and 336 videos chosen for annotation are representative of the wider reproductive health content on TikTok, and the three clinicians' labels supply a reliable ground truth.
What would settle it
A larger-scale annotation effort using thousands of additional videos drawn from a wider query pool that yields a materially different accuracy rate or larger inter-clinician disagreement would undermine the reported 60 percent figure and the 15 percent LLM gap.
Figures



read the original abstract
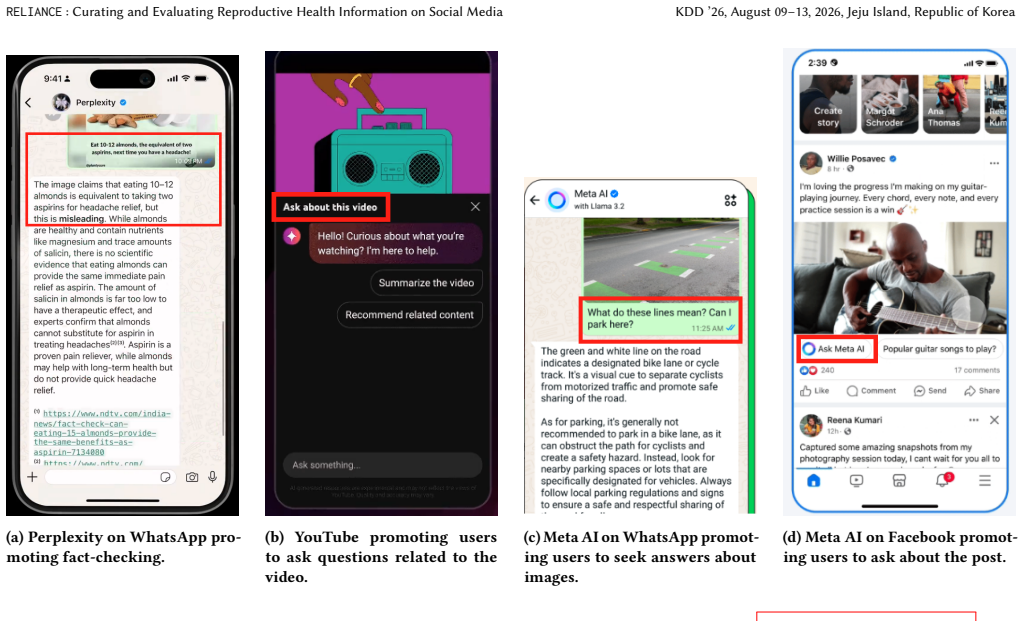
Social media platforms like TikTok have become a key source of health information, with studies reporting inaccuracies in posts. As Large Language Model (LLM) providers increasingly integrate LLMs into digital platforms to fact-check content (e.g., Grok and Perplexity on X and WhatsApp, respectively) and are being used by people to fact-check information, deploying these systems in critical areas such as reproductive health without rigorous evaluation can cause serious harm. We introduce RELIANCE, an expert-annotated dataset of health information on TikTok surrounding pregnancy and postpartum queries, serving as both an analysis of the reproductive health information landscape and an evaluation of LLMs' capabilities in fact-checking this content. Our dataset comprises 409 annotated sentences from 336 videos across 56 clinician-reviewed queries, annotated by three expert clinicians in Obstetrics, Gynecology, and Internal Medicine. Our findings reveal that nearly 60\% of the health information in the videos we sampled is accurate. Furthermore, LLM evaluations reveal a gap between evaluating specific claims and evaluating the entire content (15\%). We believe that our methodology, dataset, and tool will support the machine learning community in improving LLMs for important domains with real-world data, extending to other platforms and languages, and helping the health community further understand the information landscape on social media. Our dataset and code are made available at https://realize-lab.github.io/RELIANCE/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RELIANCE, an expert-annotated dataset of 409 sentences from 336 TikTok videos across 56 clinician-reviewed pregnancy and postpartum queries, annotated by three clinicians in Obstetrics, Gynecology, and Internal Medicine. It reports that nearly 60% of the sampled health information is accurate and identifies a 15% performance gap for LLMs between evaluating specific claims versus entire video content. The work positions the dataset as both an analysis of the reproductive health information landscape on social media and a benchmark for LLM fact-checking, with code and data released.
Significance. If the sampling supports generalization, the dataset offers a concrete, expert-annotated resource for evaluating LLMs on reproductive health content from TikTok, addressing a timely need as LLMs are integrated into fact-checking tools. The open release of the dataset and code is a clear strength that enables reproducibility and extension to other platforms or languages.
major comments (3)
- [Methods (query curation)] Methods section on query curation: the 56 clinician-reviewed queries are described only as 'clinician-reviewed' with no account of the initial query pool, selection criteria, stratification by search volume or popularity, or how they represent typical user searches; this directly undermines the claim that the 60% accuracy figure characterizes the broader reproductive health information landscape on TikTok.
- [Methods (video sampling)] Methods section on video sampling: the procedure for selecting the 336 videos per query (top-N results, random sample, date range, or other) is unspecified, so the accuracy statistic and the LLM evaluation's relevance to real-world use rest on an uncharacterized convenience sample.
- [Results (LLM evaluation)] Results (LLM evaluation) and annotation protocol: the 15% gap between claim-level and content-level evaluation is reported without details on how 'entire content' evaluation was operationalized by clinicians, inter-annotator agreement statistics, or exclusion criteria, making it impossible to verify that the gap is reliably measured and load-bearing for the LLM assessment claim.
minor comments (2)
- [Abstract] Abstract and §1: the sentence count (409) and video count (336) are stated without an explicit mapping or table showing how many sentences per video were annotated on average.
- [Discussion] The paper should add a limitations subsection clarifying the scope of the TikTok-only, English-language, pregnancy/postpartum focus.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments, which highlight important areas for improving the clarity and rigor of our methods and results sections. We address each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: Methods section on query curation: the 56 clinician-reviewed queries are described only as 'clinician-reviewed' with no account of the initial query pool, selection criteria, stratification by search volume or popularity, or how they represent typical user searches; this directly undermines the claim that the 60% accuracy figure characterizes the broader reproductive health information landscape on TikTok.
Authors: We agree that the current description is insufficient and that the 60% accuracy statistic should not be presented as characterizing the broader landscape without qualification. In the revised manuscript we will expand the Methods section to describe the initial query pool (common pregnancy/postpartum search terms drawn from public health resources), the clinician review process used to finalize the 56 queries, and any stratification or popularity considerations applied. We will also revise the abstract and results to explicitly limit the scope of the accuracy claim to the sampled queries rather than implying broad generalization. revision: yes
-
Referee: Methods section on video sampling: the procedure for selecting the 336 videos per query (top-N results, random sample, date range, or other) is unspecified, so the accuracy statistic and the LLM evaluation's relevance to real-world use rest on an uncharacterized convenience sample.
Authors: We acknowledge that the video sampling procedure must be fully specified. In the revision we will add a detailed description of how videos were retrieved for each query (including search parameters, ranking method, date range, and number of videos collected per query) so that readers can assess the nature of the sample. We will also note any limitations regarding representativeness. revision: yes
-
Referee: Results (LLM evaluation) and annotation protocol: the 15% gap between claim-level and content-level evaluation is reported without details on how 'entire content' evaluation was operationalized by clinicians, inter-annotator agreement statistics, or exclusion criteria, making it impossible to verify that the gap is reliably measured and load-bearing for the LLM assessment claim.
Authors: We agree that the annotation protocol for entire-content evaluation requires additional detail. In the revised manuscript we will expand the relevant section to describe how clinicians operationalized full-video assessment, report inter-annotator agreement statistics (or explain why they were not computed), and list any exclusion criteria applied. This will allow readers to evaluate the reliability of the reported 15% gap. revision: yes
Circularity Check
Empirical dataset curation and evaluation with no derivations or self-referential loops
full rationale
The paper performs data collection from TikTok, clinician annotation of 409 sentences across 336 videos, direct percentage calculation of accuracy, and separate LLM evaluation experiments. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text. The 60% accuracy figure is a straightforward aggregate of the three-clinician annotations on the sampled content, not a reduction of any prior result or definition. Representativeness concerns affect external validity but do not constitute circularity under the specified patterns, as there are no self-definitional steps, fitted-input predictions, or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
B. L. Aaron, K. E. Neff, J. Wu, F. Cai, J. J. Swartz, and L. P. Burns. Labor induction in the age of tiktok: what are influencers teaching patients about oxytocin infusion? American journal of obstetrics & gynecology MFM, 5(11), 2023
2023
-
[2]
M. L. Antheunis, K. Tates, and T. E. Nieboer. Patients’ and health professionals’ use of social media in health care: motives, barriers and expectations.Patient education and counseling, 92(3):426–431, 2013
2013
-
[3]
Antoniak, A
M. Antoniak, A. Naik, C. S. Alvarado, L. L. Wang, and I. Y. Chen. Nlp for maternal healthcare: Perspectives and guiding principles in the age of llms. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 1446–1463, 2024
2024
-
[4]
R. K. Arora, J. Wei, R. S. Hicks, P. Bowman, J. Quiñonero-Candela, F. Tsim- pourlas, M. Sharman, M. Shah, A. Vallone, A. Beutel, J. Heidecke, and K. Sing- hal. Healthbench: Evaluating large language models towards improved human health. https://cdn.openai.com/pdf/bd7a39d5-9e9f-47b3-903c-8b847ca650c7/ healthbench_paper.pdf#page=1.35, 2025. URL https://cdn....
2025
-
[5]
Auxier and M
B. Auxier and M. Anderson. Social media use in 2021. https://www.pewresearch. org/internet/2021/04/07/social-media-use-in-2021/, 2021. URL https://www. pewresearch.org/internet/2021/04/07/social-media-use-in-2021/
2021
-
[6]
V. Balloli, J. Erickson, X. Li, E. MacMurray van Liemt, A. Friedman Peahl, and E. Bondi-Kelly. ”Where is this coming from?” Uncovering Trustworthiness Ideals in AI-powered Peripartum Information Seeking. InProceedings of the 2026 ACM Conference on Fairness, Accountability, and Transparency, 2026. doi: 10.1145/3805689.3812277
-
[7]
A. M. Buck and D. F. Ralston. I didn’t sign up for your research study: The ethics of using “public” data.Computers and Composition, 61:102655, 2021
2021
-
[8]
Budak, B
C. Budak, B. Nyhan, D. M. Rothschild, E. Thorson, and D. J. Watts. Misunder- standing the harms of online misinformation.Nature, 630(8015):45–53, 2024
2024
-
[9]
C. Chen and K. Shu. Can llm-generated misinformation be detected?arXiv preprint arXiv:2309.13788, 2023
-
[10]
J. Chen, Y. Wang, et al. Social media use for health purposes: systematic review. Journal of medical Internet research, 23(5):e17917, 2021
2021
-
[11]
De Choudhury, M
M. De Choudhury, M. R. Morris, and R. W. White. Seeking and sharing health information online: comparing search engines and social media. InProceedings of the SIGCHI conference on human factors in computing systems, pages 1365–1376, 2014
2014
-
[12]
R. Dorn, L. Kezar, F. Morstatter, and K. Lerman. Harmful speech detection by language models exhibits gender-queer dialect bias. InProceedings of the 4th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization, pages 1–12, 2024
2024
-
[13]
A. G. Dunn, K. D. Mandl, and E. Coiera. Social media interventions for precision public health: promises and risks.NPJ digital medicine, 1(1):47, 2018
2018
-
[14]
K. Eddy. https://www.pewresearch.org/short-reads/2024/12/20/8-facts-about- americans-and-tiktok/, 2024. URL https://www.pewresearch.org/short-reads/ 2024/12/20/8-facts-about-americans-and-tiktok/
2024
-
[15]
Eysenbach, J
G. Eysenbach, J. Powell, M. Englesakis, C. Rizo, and A. Stern. Health related virtual communities and electronic support groups: systematic review of the effects of online peer to peer interactions.Bmj, 328(7449):1166, 2004
2004
-
[16]
Farahbakhsh, A
R. Farahbakhsh, A. Cuevas, and N. Crespi. Characterization of cross-posting activity for professional users across major osns. InProceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015, pages 645–650, 2015
2015
-
[17]
for Disease Control and P
C. for Disease Control and P. (CDC). Hear her campaign. https://www.cdc.gov/ hearher/index.html, 2024
2024
-
[18]
Gottfried and E
J. Gottfried and E. Shearer. News use across social media platforms 2016.Pew Research Center, 2016
2016
-
[19]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Stein- hardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[20]
D. Jin, E. Pan, N. Oufattole, W.-H. Weng, H. Fang, and P. Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
2021
-
[21]
G. J. Johnson and P. J. Ambrose. Neo-tribes: The power and potential of online communities in health care.Communications of the ACM, 49(1):107–113, 2006
2006
-
[22]
Language Models (Mostly) Know What They Know
S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Hatfield-Dodds, N. DasSarma, E. Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Racial disparities in maternal and infant health: Current status and key issues
Kaiser Family Foundation. Racial disparities in maternal and infant health: Current status and key issues. https://www.kff.org/racial-equity-and-health- policy/racial-disparities-in-maternal-and-infant-health-current-status-and- key-issues/, 2025
2025
-
[24]
Kanchan and A
S. Kanchan and A. Gaidhane. Social media role and its impact on public health: a narrative review.Cureus, 15(1), 2023
2023
-
[25]
S. S. Khan, N. A. Cameron, and K. J. Lindley. Pregnancy as an early cardiovascular moment: peripartum cardiovascular health.Circulation research, 132(12):1584– 1606, 2023
2023
-
[26]
M. H. Kwon, S. W. Kwon, R. K. Das, and B. C. Drolet. Obstetric and gynecologic care in tiktok: Top influencers and posts.Reproductive Sciences, 30(10):2889–2892, 2023
2023
-
[27]
Holistic Evaluation of Language Models
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y. Zhang, D. Narayanan, Y. Wu, A. Kumar, et al. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [28]
- [29]
-
[30]
A. . M. Llama Team. The llama 3 herd of models, 2024. URL https://arxiv.org/ abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
N. Mannhardt, E. Bondi-Kelly, B. Lam, H. Mozannar, C. O’Connell, M. Asiedu, A. Buendia, T. Urman, I. B. Riaz, C. E. Ricciardi, et al. Impact of large language model assistance on patients reading clinical notes: a mixed-methods study.arXiv preprint arXiv:2401.09637, 2024
-
[32]
Markov, C
T. Markov, C. Zhang, S. Agarwal, F. E. Nekoul, T. Lee, S. Adler, A. Jiang, and L. Weng. A holistic approach to undesired content detection in the real world. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 15009–15018, 2023
2023
-
[33]
arXiv preprint arXiv:2305.14552 , year=
N. McKenna, T. Li, L. Cheng, M. J. Hosseini, M. Johnson, and M. Steedman. Sources of hallucination by large language models on inference tasks.arXiv preprint arXiv:2305.14552, 2023
-
[34]
More speech and fewer mistakes
Meta. More speech and fewer mistakes. https://about.fb.com/news/2025/01/meta- more-speech-fewer-mistakes/, Jan. 2025
2025
- [35]
-
[36]
Montero, J
A. Montero, J. Montalvo III, A. Kearney, I. Valdes, A. Kirzinger, and L. Hamel. Kff tracking poll on health information and trust: Use of ai for health information and advice.KFF Poll, March, pages 435–444, 2026
2026
-
[37]
National Academies of Sciences, Engineering, and Medicine and others. Overview of research gaps for selected conditions in women’s health research at the national institutes of health: Proceedings of a workshop—in brief.National Academies of Sciences, Engineering, and Medicine; Health and Medicine Division, 2024
2024
-
[38]
Q. C. Nguyen, E. M. Aparicio, M. Jasczynski, A. C. Doig, X. Yue, H. Mane, N. Srikanth, F. X. M. Gutierrez, N. Delcid, X. He, et al. Rosie, a health edu- cation question-and-answer chatbot for new mothers: randomized pilot study. JMIR Formative Research, 8(1):e51361, 2024
2024
-
[39]
A. C. of Obstetricians and G. (ACOG). Prenatal care. https://www.acog.org/ programs/redesigning-prenatal-care-initiative, 2020
2020
-
[40]
URL https://platform.openai.com/docs/models/omni-moderation- latest
OpenAI, 2025. URL https://platform.openai.com/docs/models/omni-moderation- latest
2025
- [41]
-
[42]
Automatic Detection of Fake News
V. Pérez-Rosas, B. Kleinberg, A. Lefevre, and R. Mihalcea. Automatic detection of fake news.arXiv preprint arXiv:1708.07104, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [43]
-
[44]
M. Rao. Medfluencing: A new role for physicians in the age of tiktok.Georgetown Medical Review, 6(1), 2022
2022
-
[45]
Renault, M
T. Renault, M. Mosleh, and D. G. Rand. @grok is this true? llm-powered fact- checking on social media, Jan 2026. URL osf.io/preprints/psyarxiv/85quw_v2
2026
-
[46]
K. Saab, T. Tu, W.-H. Weng, R. Tanno, D. Stutz, E. Wulczyn, F. Zhang, T. Strother, C. Park, E. Vedadi, et al. Capabilities of gemini models in medicine.arXiv preprint arXiv:2404.18416, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
A. M. Smith, A. S. Mucedola, and A. Ausness-Ayres. My Video, My Choice: A Quantitative Content Analysis of U.S. OBGYN TikTok Videos in the Post-RoeEra. Women’s Reproductive Health, pages 1–25, Aug. 2024. ISSN 2329-3691, 2329-3713. doi: 10.1080/23293691.2024.2377969. URL https://www.tandfonline.com/doi/full/ 10.1080/23293691.2024.2377969
-
[48]
N. Srikanth, R. Sarkar, H. Mane, E. M. Aparicio, Q. C. Nguyen, R. Rudinger, and J. Boyd-Graber. Pregnant questions: The importance of pragmatic awareness in maternal health question answering.arXiv preprint arXiv:2311.09542, 2023
-
[49]
Stein, Y
K. Stein, Y. Yao, and T. Aitamurto. Examining Communicative Forms in #TikTok- Docs’ Sexual Health Videos.International Journal of Communication, 16(0):23, Feb
-
[50]
URL https://ijoc.org/index.php/ijoc/article/view/18175
ISSN 1932-8036. URL https://ijoc.org/index.php/ijoc/article/view/18175. Number: 0. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Vaibhav Balloli et al
1932
-
[51]
Stephenson, C
S. Stephenson, C. N. Page, M. Wei, A. Kapadia, and F. Roesner. Sharenting on tiktok: Exploring parental sharing behaviors and the discourse around children’s online privacy. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1–17, 2024
2024
-
[52]
Suarez-Lledo and J
V. Suarez-Lledo and J. Alvarez-Galvez. Prevalence of health misinformation on social media: systematic review.Journal of medical Internet research, 23(1):e17187, 2021
2021
- [53]
- [54]
-
[55]
M. Völske, P. Braslavski, M. Hagen, G. Lezina, and B. Stein. What Users Ask a Search Engine: Analyzing One Billion Russian Question Queries. InProceed- ings of the 24th ACM International on Conference on Information and Knowledge Management, pages 1571–1580, Melbourne Australia, Oct. 2015. ACM. ISBN 978-1-4503-3794-6. doi: 10.1145/2806416.2806457. URL htt...
-
[56]
L. Wu, F. Morstatter, K. M. Carley, and H. Liu. Misinformation in social media: definition, manipulation, and detection.ACM SIGKDD explorations newsletter, 21 (2):80–90, 2019
2019
-
[57]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
On Verbalized Confidence Scores for LLMs
D. Yang, Y.-H. H. Tsai, and M. Yamada. On verbalized confidence scores for llms. arXiv preprint arXiv:2412.14737, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
W. Zeng, Y. Liu, R. Mullins, L. Peran, J. Fernandez, H. Harkous, K. Narasimhan, D. Proud, P. Kumar, B. Radharapu, et al. Shieldgemma: Generative ai content moderation based on gemma.arXiv preprint arXiv:2407.21772, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
but the data is already public
M. Zimmer. “but the data is already public”: on the ethics of research in facebook. InThe ethics of information technologies, pages 229–241. Routledge, 2020
2020
-
[61]
Oligohydramnios.. diagnosed with < 5 cm
G. Zuccon, B. Koopman, and J. Palotti. Diagnose this if you can: On the effective- ness of search engines in finding medical self-diagnosis information. InAdvances in Information Retrieval: 37th European Conference on IR Research, ECIR 2015, Vienna, Austria, March 29-April 2, 2015. Proceedings 37, pages 562–567. Springer, 2015. A Design choices and artifa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.