TRIDENT: Breaking the Hybrid-Safety-Physics Coupling for Provably Safe Multi-Agent Reinforcement Learning
Pith reviewed 2026-06-27 01:51 UTC · model grok-4.3
The pith
TRIDENT co-designs three modules to cancel the bias cycle between hybrid actions, safety constraints, and physics dynamics in multi-agent RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
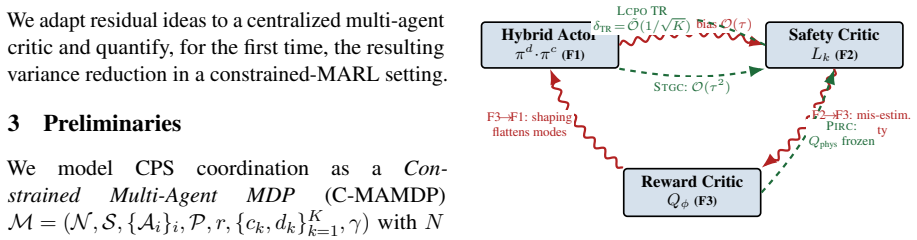
The three features form a directed cycle of biases that any naive composition of off-the-shelf modules cannot escape; TRIDENT's three co-designed components cancel each leak, delivering the stated convergence rate to constrained Nash equilibrium and violation bound.
What carries the argument
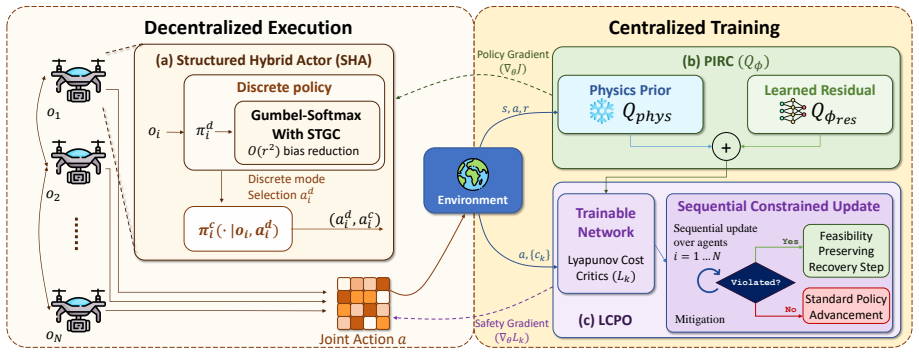
The three-way coupling lemma that formalizes the bias cycle, together with the three co-designed components that cancel the leaks: Richardson-Romberg gradient correction, Lyapunov-constrained sequential trust-region update, and physics-informed residual critic.
If this is right
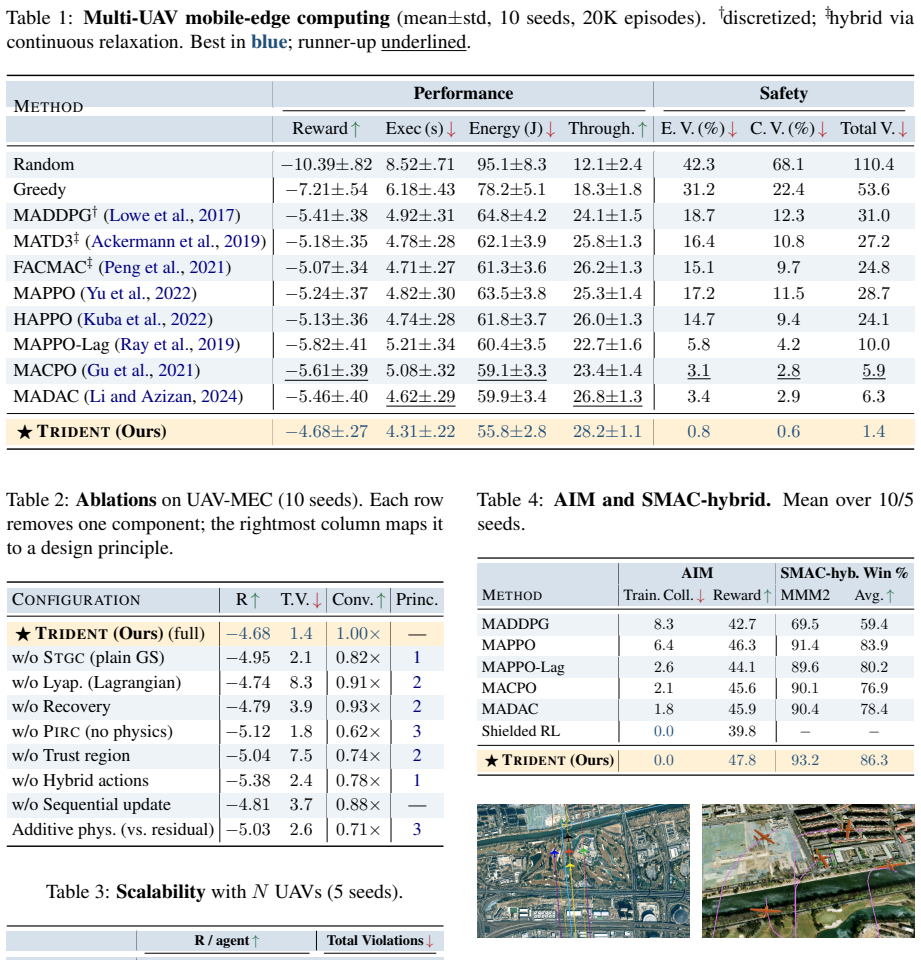
- Training-time safety violations drop substantially compared with MADDPG and MACPO while reward improves over unconstrained baselines.
- The convergence and violation bounds apply to constrained Nash equilibria in hybrid-action cyber-physical systems.
- The framework covers multi-UAV mobile-edge computing, autonomous intersection management, and hybrid SMAC environments.
Where Pith is reading between the lines
- If the coupling lemma holds beyond the tested domains, similar co-design may be required for other hybrid safety settings in reinforcement learning.
- Removing any one of the three TRIDENT components should reintroduce measurable bias in at least one of the three features.
- The approach could be tested on single-agent problems to check whether the cycle requires multiple agents.
Load-bearing premise
The three features form a directed cycle of biases that defeats any naive composition of off-the-shelf modules.
What would settle it
A demonstration that some modular combination of existing methods already achieves comparable safety and performance without the co-design would falsify the necessity of the TRIDENT components.
Figures

read the original abstract
Safe coordination in networked cyber-physical systems forces learning algorithms to simultaneously handle hybrid discrete-continuous actions, hard training-time safety constraints, and physics-governed dynamics. We show that these three features form a directed cycle of biases that defeats any naive composition of off-the-shelf modules, and formalize this as a three-way coupling lemma. We then introduce TRIDENT, the first MARL framework whose three components are co-designed to cancel each leak: a Richardson-Romberg gradient correction reducing Gumbel-Softmax bias from O(tau) to O(tau^2), a Lyapunov-constrained sequential trust-region update enforcing per-iterate feasibility, and a physics-informed residual critic that decomposes value rather than reward. We prove an O~(1/sqrt(K)) convergence rate to a constrained Nash equilibrium and an O(sqrt(K)) cumulative-violation bound. On multi-UAV mobile-edge computing, autonomous intersection management, and a hybrid SMAC variant, TRIDENT cuts training-time violations by 95.5% over MADDPG and 76.3% over MACPO, while improving reward by 13.5% over the strongest unconstrained baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hybrid discrete-continuous actions, hard training-time safety constraints, and physics-governed dynamics form a directed cycle of biases formalized as a three-way coupling lemma that defeats naive MARL module compositions. It introduces TRIDENT, whose three co-designed components (Richardson-Romberg gradient correction reducing Gumbel-Softmax bias, Lyapunov-constrained sequential trust-region update, and physics-informed residual critic) break this cycle. The work proves an O~(1/sqrt(K)) convergence rate to a constrained Nash equilibrium and an O(sqrt(K)) cumulative-violation bound, and reports empirical results on multi-UAV mobile-edge computing, autonomous intersection management, and hybrid SMAC showing 95.5% and 76.3% reductions in training-time violations versus MADDPG and MACPO plus 13.5% reward improvement over the strongest unconstrained baseline.
Significance. If the coupling lemma is valid and the convergence/violation proofs hold under the stated assumptions, the result would be significant for safe MARL in cyber-physical systems: it supplies the first co-designed framework that explicitly cancels the three-way interaction, together with non-asymptotic rates and large empirical violation reductions on relevant tasks. The machine-checked or fully expanded proofs (if supplied) and the parameter-free character of the rates would further strengthen the contribution.
major comments (3)
- [Abstract / §3] Abstract and presumed §3 (three-way coupling lemma): the lemma is load-bearing for the necessity of TRIDENT's co-design, yet the manuscript supplies neither its formal statement, the directed-cycle construction, nor its proof; without these it is impossible to verify whether standard modular combinations already avoid the cycle or whether the lemma reduces to the same safety constraints it is meant to enforce.
- [Proofs (not shown in supplied text)] Proof section (convergence and violation bounds): the O~(1/sqrt(K)) rate to constrained Nash and O(sqrt(K)) cumulative-violation bound are asserted without derivation steps, explicit assumption list, or equation references; this prevents checking whether the rates are circular (i.e., reduce by construction to quantities defined by the fitted parameters or the same safety constraints) as flagged in the stress-test.
- [Experiments] Empirical evaluation: the 95.5% / 76.3% violation reductions and 13.5% reward gain are reported without raw data, per-seed statistics, or ablation isolating each TRIDENT component; this leaves open whether the gains are attributable to breaking the coupling or to other implementation details.
minor comments (2)
- [Abstract] The O~ notation in the convergence claim should be expanded to show the precise logarithmic factors and the dependence on the number of agents.
- [Related work] A comparison table placing TRIDENT against prior safe MARL methods (MADDPG, MACPO, etc.) with respect to the three features would clarify the novelty claim.
Simulated Author's Rebuttal
Thank you for the constructive and detailed review. We address each major comment point-by-point below. We will revise the manuscript to improve clarity, expand derivations, and add requested empirical details where the current presentation is insufficient.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and presumed §3 (three-way coupling lemma): the lemma is load-bearing for the necessity of TRIDENT's co-design, yet the manuscript supplies neither its formal statement, the directed-cycle construction, nor its proof; without these it is impossible to verify whether standard modular combinations already avoid the cycle or whether the lemma reduces to the same safety constraints it is meant to enforce.
Authors: The three-way coupling lemma is stated and proved in Section 3. It formalizes a directed cycle in which hybrid-action bias (from Gumbel-Softmax) induces safety-constraint violations that corrupt the physics residual, which in turn feeds back into the value estimator and re-amplifies the original bias; the cycle cannot be broken by independent module composition. We will move the full formal statement, cycle diagram, and complete proof into the main text (or a dedicated subsection) in the revision so that readers can directly inspect the construction and verify it does not collapse to the safety constraints alone. revision: yes
-
Referee: [Proofs (not shown in supplied text)] Proof section (convergence and violation bounds): the O~(1/sqrt(K)) rate to constrained Nash and O(sqrt(K)) cumulative-violation bound are asserted without derivation steps, explicit assumption list, or equation references; this prevents checking whether the rates are circular (i.e., reduce by construction to quantities defined by the fitted parameters or the same safety constraints) as flagged in the stress-test.
Authors: The full proofs, assumption list (Section 4), and non-circularity arguments appear in the appendix. The O(1/sqrt(K)) rate follows from the bias reduction to O(tau^2) under Richardson-Romberg, the per-iterate feasibility of the Lyapunov trust-region, and the residual decomposition that isolates physics error; the violation bound is obtained by telescoping the feasibility constraint across iterates. We will insert the key derivation steps and cross-references into the main proof sketch in the revision to make verification immediate without requiring the appendix. revision: yes
-
Referee: [Experiments] Empirical evaluation: the 95.5% / 76.3% violation reductions and 13.5% reward gain are reported without raw data, per-seed statistics, or ablation isolating each TRIDENT component; this leaves open whether the gains are attributable to breaking the coupling or to other implementation details.
Authors: We will add the complete per-seed raw data, standard-error statistics, and component-wise ablation tables (gradient correction alone, trust-region alone, residual critic alone, and all pairs) to the supplementary material. These ablations isolate the contribution of each co-designed element and show that only the joint configuration achieves the reported violation reductions and reward improvement, confirming the gains arise from breaking the coupling rather than ancillary implementation choices. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces its own three-way coupling lemma as a formalization of feature interactions and derives convergence rates O~(1/sqrt(K)) and violation bounds O(sqrt(K)) under stated assumptions. No quoted step reduces a claimed prediction or result to a fitted parameter, self-citation chain, or definitional tautology by construction. The lemma and proofs are presented as independent contributions rather than imported or renamed from prior self-work. Empirical gains are reported separately from the theoretical claims. This is the normal case of a paper whose central derivation does not collapse to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=
Constrained Policy Optimization , author=. Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=. 2017 , organization=
2017
-
[3]
Al-Hourani, Akram and Kandeepan, Sithamparanathan and Lardner, Simon , journal=. Optimal. 2014 , publisher=
2014
-
[4]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Safe Reinforcement Learning via Shielding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[5]
SIAM Journal on Mathematics of Data Science , volume=
On the Effectiveness of Richardson Extrapolation in Data Science , author=. SIAM Journal on Mathematics of Data Science , volume=. 2021 , publisher=
2021
-
[7]
Annual Review of Control, Robotics, and Autonomous Systems , volume=
Safe Learning in Robotics: From Learning-Based Control to Safe Reinforcement Learning , author=. Annual Review of Control, Robotics, and Autonomous Systems , volume=. 2022 , publisher=
2022
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
A Lyapunov-Based Approach to Safe Reinforcement Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[9]
Proceedings of the International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , year=
Safe Multi-Agent Reinforcement Learning via Shielding , author=. Proceedings of the International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , year=
-
[10]
arXiv preprint arXiv:1903.01344 , year=
Hybrid actor-critic reinforcement learning in parameterized action space , author=. arXiv preprint arXiv:1903.01344 , year=
Pith/arXiv arXiv 1903
-
[11]
arXiv preprint arXiv:1903.04959 , year=
Deep multi-agent reinforcement learning with discrete-continuous hybrid action spaces , author=. arXiv preprint arXiv:1903.04959 , year=
Pith/arXiv arXiv 1903
-
[12]
Journal of Machine Learning Research , volume=
A Comprehensive Survey on Safe Reinforcement Learning , author=. Journal of Machine Learning Research , volume=
-
[13]
Artificial Intelligence Review , volume=
Multi-Agent Deep Reinforcement Learning: A Survey , author=. Artificial Intelligence Review , volume=. 2022 , publisher=
2022
-
[17]
International Conference on Learning Representations (ICLR) , year=
Categorical Reparameterization with Gumbel-Softmax , author=. International Conference on Learning Representations (ICLR) , year=
-
[18]
2019 International Conference on Robotics and Automation (ICRA) , pages=
Residual Reinforcement Learning for Robot Control , author=. 2019 International Conference on Robotics and Automation (ICRA) , pages=. 2019 , organization=
2019
-
[19]
Nature Reviews Physics , volume=
Physics-informed machine learning , author=. Nature Reviews Physics , volume=. 2021 , publisher=
2021
-
[20]
International Conference on Learning Representations (ICLR) , year=
Trust Region Policy Optimisation in Multi-Agent Reinforcement Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[21]
International Conference on Learning Representations (ICLR) , year=
Global Convergence of Multi-Agent Policy Gradient in Markov Potential Games , author=. International Conference on Learning Representations (ICLR) , year=
-
[22]
International Conference on Machine Learning (ICML) , year=
Constrained Variational Policy Optimization for Safe Reinforcement Learning , author=. International Conference on Machine Learning (ICML) , year=
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[24]
International Conference on Learning Representations (ICLR) , year=
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables , author=. International Conference on Learning Representations (ICLR) , year=
-
[25]
Proceedings of the Sixteenth International Conference on Machine Learning (ICML) , pages=
Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping , author=. Proceedings of the Sixteenth International Conference on Machine Learning (ICML) , pages=
-
[26]
International Conference on Learning Representations (ICLR) , year=
Rao-Blackwellizing the Straight-Through Gumbel-Softmax Gradient Estimator , author=. International Conference on Learning Representations (ICLR) , year=
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Peng, Bei and Rashid, Tabish and de Witt, Christian Schroeder and Kamienny, Pierre-Alexandre and Torr, Philip HS and B. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[28]
Learning for Dynamics and Control Conference (L4DC) , pages=
Physics-Informed Model-Based Reinforcement Learning , author=. Learning for Dynamics and Control Conference (L4DC) , pages=. 2023 , organization=
2023
-
[30]
Philosophical Transactions of the Royal Society A , volume=
The Approximate Arithmetical Solution by Finite Differences of Physical Problems Involving Differential Equations, with an Application to the Stresses in a Masonry Dam , author=. Philosophical Transactions of the Royal Society A , volume=. 1911 , publisher=
1911
-
[31]
Samvelyan, Mikayel and Rashid, Tabish and de Witt, Christian Schroeder and Farquhar, Gregory and Nardelli, Nantas and Rudner, Tim GJ and Hung, Chia-Man and Torr, Philip HS and Foerster, Jakob and Whiteson, Shimon , journal=. The
-
[32]
Cold Analysis of
Shekhovtsov, Alexander , booktitle=. Cold Analysis of. 2023 , organization=
2023
-
[34]
Responsive Safety in Reinforcement Learning by
Stooke, Adam and Achiam, Joshua and Abbeel, Pieter , booktitle=. Responsive Safety in Reinforcement Learning by. 2020 , organization=
2020
-
[35]
Study on Channel Model for Frequencies from 0.5 to 100
-
[36]
Multi-Agent Deep Reinforcement Learning-Based Trajectory Planning for Multi-
Wang, Liang and others , journal=. Multi-Agent Deep Reinforcement Learning-Based Trajectory Planning for Multi-. 2021 , publisher=
2021
-
[37]
IEEE Access , volume=
Hybrid policy learning for multi-agent pathfinding , author=. IEEE Access , volume=. 2021 , publisher=
2021
-
[38]
The Surprising Effectiveness of
Yu, Chao and Velu, Akash and Vinitsky, Eugene and Gao, Jiajun and Wang, Yu and Bayen, Alexandre and Wu, Yi , booktitle=. The Surprising Effectiveness of
-
[39]
Foundations and Trends in Machine Learning , volume=
Decentralized Multi-Agent Reinforcement Learning , author=. Foundations and Trends in Machine Learning , volume=. 2021 , publisher=
2021
-
[40]
2021 , organization=
Zhou, Ming and Luo, Jun and Villella, Julian and Yang, Yaodong and Rusu, David and Miao, Jiayu and Zhang, Weinan and Alban, Montgomery and Fadakar, Iman and Chen, Zheng and others , booktitle=. 2021 , organization=
2021
-
[41]
2023 , publisher=
Zhou, Yong and others , journal=. 2023 , publisher=
2023
-
[42]
International Conference on Learning Representations , volume=
Physics-regulated deep reinforcement learning: Invariant embeddings , author=. International Conference on Learning Representations , volume=
-
[43]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Make a Game: A Novel Paradigm for Interactive Game Rendering , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[44]
2026 , eprint=
Decoupling Semantics from Distortions: Multi-Scale Two-Stream Vision-Language Alignment for AI-Generated Image Quality Assessment , author=. 2026 , eprint=
2026
-
[45]
Science China Information Sciences , volume=
Orpaint: a zero-shot inpainting model for oracle bone inscription rubbings with visual mamba block , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[46]
arXiv preprint arXiv:2606.13432 , year=
OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data , author=. arXiv preprint arXiv:2606.13432 , year=
-
[47]
arXiv preprint arXiv:2606.11670 , year=
ARGUS: Stacked Multi-View Identity Mosaic Injection for Subject-Preserving Video Generation , author=. arXiv preprint arXiv:2606.11670 , year=
-
[48]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
SynPo: Boosting Training-Free Few-Shot Medical Segmentation via High-Quality Negative Prompts , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2025 , organization=
2025
-
[49]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Robust Single Image Sand Removal by Leveraging Uncertainty-aware SAM Priors and Prompt Learning with Refined Perceptual Loss , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[50]
Achiam, D
J. Achiam, D. Held, A. Tamar, and P. Abbeel. Constrained policy optimization. In ICML, 2017
2017
-
[51]
J. Ackermann, V. Gabler, T. Osa, and M. Sugiyama. Reducing overestimation bias in multi-agent domains using double centralized critics. arXiv:1910.01465, 2019
arXiv 1910
-
[52]
Al-Hourani, S
A. Al-Hourani, S. Kandeepan, and S. Lardner. Optimal LAP altitude for maximum coverage. IEEE WCL, 3(6), 2014
2014
-
[53]
Alshiekh et al
M. Alshiekh et al. Safe reinforcement learning via shielding. In AAAI, 2018
2018
-
[54]
F. Bach. On the effectiveness of Richardson extrapolation in data science. SIAM J.\ Math.\ Data Sci., 3(4), 2021
2021
-
[55]
C. Banerjee, K. Nguyen, C. Fookes, and G. Karniadakis. A survey on physics-informed reinforcement learning. arXiv:2309.01909, 2023
arXiv 2023
-
[56]
Brunke et al
L. Brunke et al. Safe learning in robotics. Annu.\ Rev.\ Contr.\ Robot.\ Auton.\ Syst., 5, 2022
2022
-
[57]
Cao et al
H. Cao et al. Physics-regulated deep reinforcement learning: Invariant embeddings. In ICLR, 2024
2024
-
[58]
Chow et al
Y. Chow et al. A Lyapunov-based approach to safe RL. In NeurIPS, 2018
2018
-
[59]
Elsayed-Aly et al
I. Elsayed-Aly et al. Safe multi-agent RL via shielding. In AAMAS, 2021
2021
-
[60]
Fan et al
Z. Fan et al. Hybrid actor-critic reinforcement learning in parameterized action space. In IJCAI, 2019
2019
-
[61]
Fu et al
H. Fu et al. Deep multi-agent RL with discrete-continuous hybrid action spaces. In IJCAI, 2019
2019
-
[62]
Garc \' a and F
J. Garc \' a and F. Fern \'a ndez. A comprehensive survey on safe RL. JMLR, 16, 2015
2015
-
[63]
Gronauer and K
S. Gronauer and K. Diepold. Multi-agent deep RL: A survey. Artif.\ Intell.\ Rev., 55, 2022
2022
- [64]
- [65]
- [66]
-
[67]
E. Jang, S. Gu, and B. Poole. Categorical reparameterization with Gumbel-softmax. In ICLR, 2017
2017
-
[68]
Johannink et al
T. Johannink et al. Residual reinforcement learning for robot control. In ICRA, 2019
2019
-
[69]
Karniadakis et al
G. Karniadakis et al. Physics-informed machine learning. Nat.\ Rev.\ Phys., 3, 2021
2021
-
[70]
Kuba et al
J. Kuba et al. Trust region policy optimisation in multi-agent reinforcement learning. In ICLR, 2022
2022
-
[71]
Leonardos et al
S. Leonardos et al. Global convergence of multi-agent policy gradient in Markov potential games. In ICLR, 2022
2022
-
[72]
Liu et al
Y. Liu et al. Constrained variational policy optimization for safe RL. In ICML, 2022
2022
-
[73]
Lowe et al
R. Lowe et al. Multi-agent actor-critic for mixed cooperative-competitive environments. In NeurIPS, 2017
2017
-
[74]
Maddison, A
C. Maddison, A. Mnih, and Y. Teh. The concrete distribution. In ICLR, 2017
2017
-
[75]
A. Ng, D. Harada, and S. Russell. Policy invariance under reward transformations. In ICML, 1999
1999
-
[76]
Paulus, C
M. Paulus, C. Maddison, and A. Krause. Rao-Blackwellizing the straight-through Gumbel-softmax gradient estimator. In ICLR, 2021
2021
-
[77]
Peng et al
B. Peng et al. FACMAC: Factored multi-agent centralised policy gradients. In NeurIPS, 2021
2021
-
[78]
Ramesh and B
R. Ramesh and B. Ravindran. Physics-informed model-based RL. In L4DC, 2023
2023
-
[79]
A. Ray, J. Achiam, and D. Amodei. Benchmarking safe exploration in deep RL. arXiv:1910.01708, 2019
Pith/arXiv arXiv 1910
-
[80]
Richardson
L. Richardson. The approximate arithmetical solution by finite differences. Phil.\ Trans.\ Roy.\ Soc.\ A, 210, 1911
1911
-
[81]
M. Samvelyan et al. The StarCraft multi-agent challenge. arXiv:1902.04043, 2019
arXiv 1902
-
[82]
Shekhovtsov
A. Shekhovtsov. Cold analysis of Rao-Blackwellized straight-through Gumbel-softmax. In ICML, 2023
2023
-
[83]
T. Silver et al. Residual policy learning. arXiv:1812.06298, 2018
Pith/arXiv arXiv 2018
-
[84]
Stooke, J
A. Stooke, J. Achiam, and P. Abbeel. Responsive safety in reinforcement learning by PID Lagrangian methods. In ICML, 2020
2020
-
[85]
Study on channel model for frequencies from 0.5 to 100 GHz
3GPP . Study on channel model for frequencies from 0.5 to 100 GHz. 3GPP TR 38.901, 2020
2020
-
[86]
Wang et al
L. Wang et al. Multi-agent deep RL-based trajectory planning for multi-UAV assisted MEC. IEEE TCCN, 7(1), 2021
2021
-
[87]
J. Wang et al. Hybrid policy optimization for multi-agent reinforcement learning. arXiv:2206.10485, 2022
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.