From Sparse Features to Trustworthy Proxies: Certifying SAE-Based Interpretability
Pith reviewed 2026-06-27 01:25 UTC · model grok-4.3
The pith
A post-hoc framework certifies SAE explanations as faithful when a derived upper bound on the base model's expected risk stays non-vacuous.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
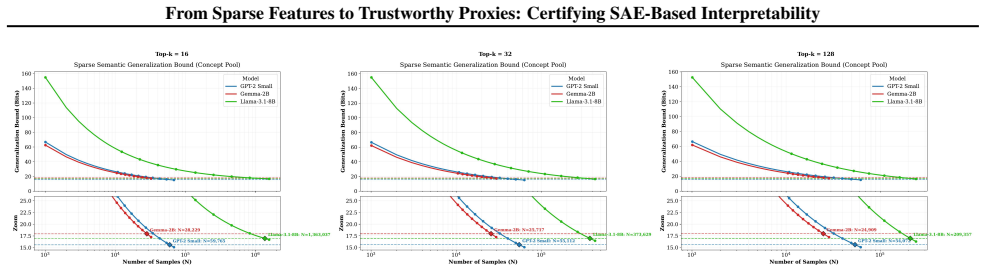
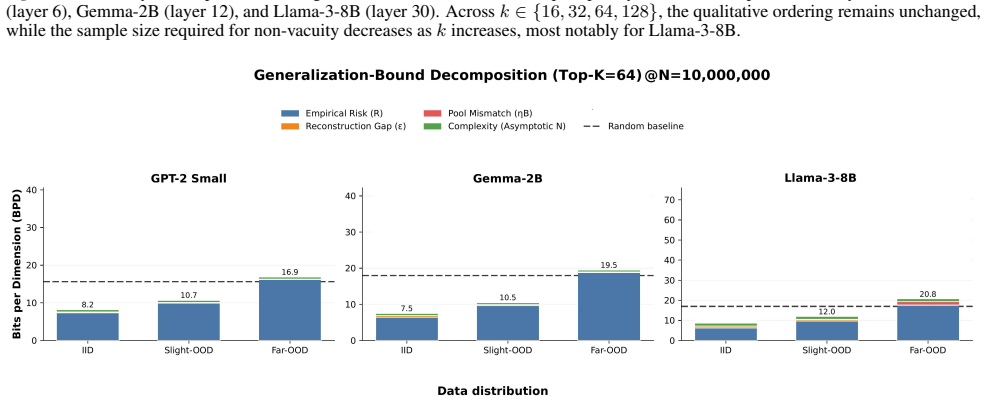
The framework replaces a native hidden activation with its pretrained SAE reconstruction to obtain a sparse proxy, then bounds the base model's expected risk by the sum of proxy risk, reconstruction gap, concept-pool mismatch, and sparse complexity. This bound functions as an operational certificate: non-vacuous values indicate the extracted features carry predictive content, while small gap and mismatch terms ensure the proxy does not diverge far from the original behavior.
What carries the argument
The sparse proxy formed by substituting a native hidden activation with its pretrained SAE reconstruction, which carries the risk-difference bound through the four listed quantities.
If this is right
- A non-vacuous bound shows that the sparse features retain meaningful predictive information about the original model.
- Small reconstruction and mismatch errors keep the proxy behaviorally close to the frozen language model.
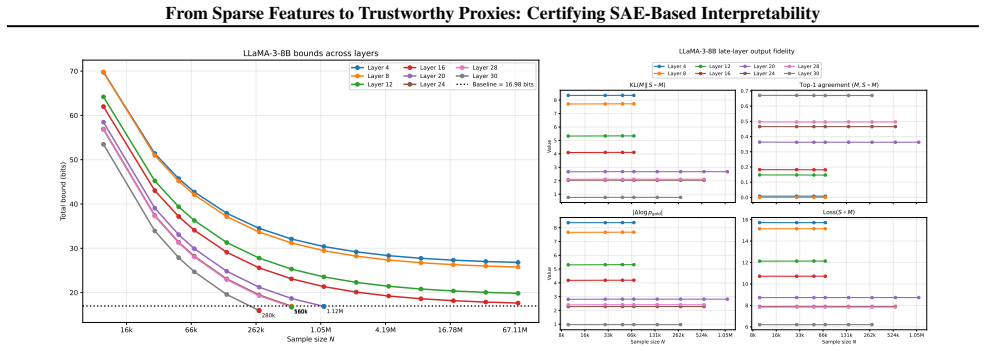
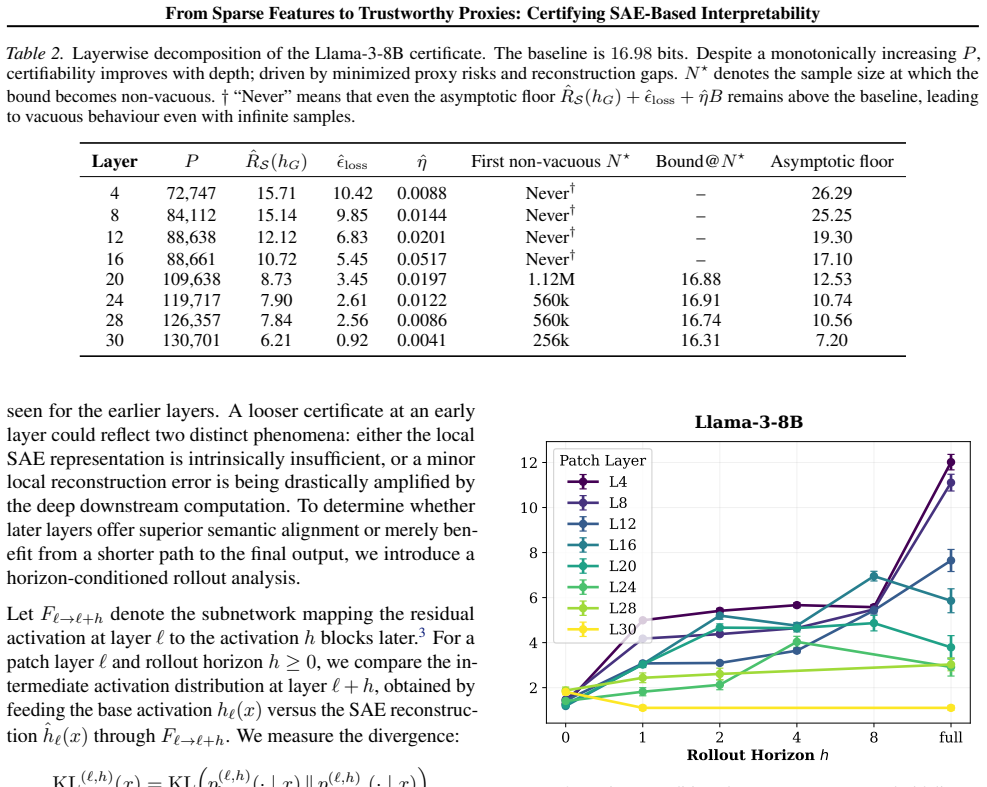
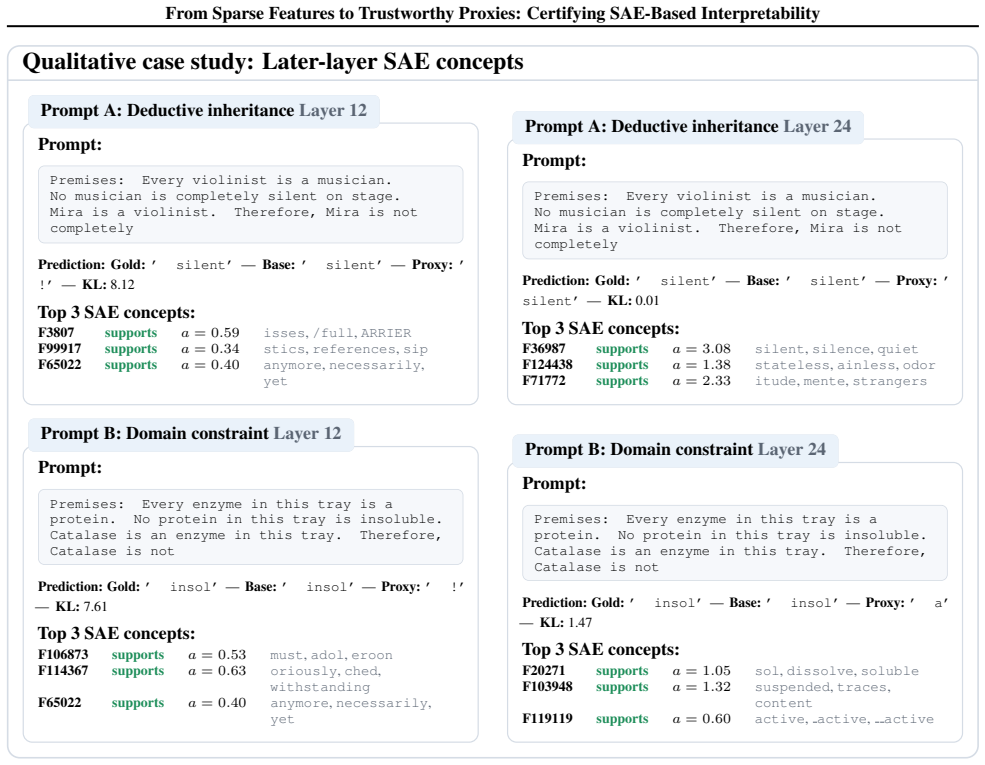
- Later layers in Llama-3-8B become easier to certify because of stronger local fidelity and weaker downstream error amplification.
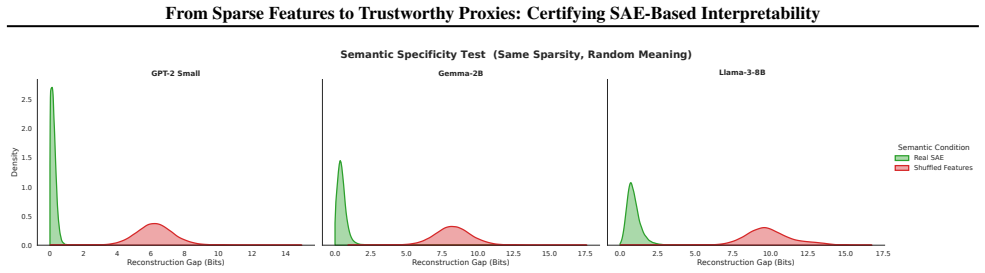
- Feature-shuffling ablations separate genuine semantic alignment from mere statistical sparsity.
Where Pith is reading between the lines
- The same bounding approach could be tested on other post-hoc feature extractors that produce sparse reconstructions.
- The observed depth dependence suggests that certification becomes more practical for higher-level semantic features than for early syntactic ones.
- Model developers could monitor the four quantities during training to decide when an SAE explanation is ready for downstream use.
Load-bearing premise
The risk difference between the original model and the proxy is assumed to be fully captured by the four quantities without extra unmeasured distribution shift.
What would settle it
An observed risk difference larger than the derived bound on held-out data where reconstruction and mismatch errors are both small would falsify the certificate.
Figures

read the original abstract
Sparse autoencoders (SAEs) are increasingly used to extract interpretable features from language models (LMs), yet a central question remains: when can an SAE-based explanation be treated as a faithful view of an underlying frozen LM We study this through a post-hoc generalization framework that certifies the LM via a sparse proxy, obtained by replacing a native hidden activation with its pretrained SAE reconstruction. Our framework derives an upper bound on the base model's expected risk using four measurable quantities: proxy risk, SAE reconstruction gap, concept-pool mismatch, and sparse complexity. We interpret this certificate as an operational criterion for explanatory faithfulness. In particular, a non-vacuous bound indicates that the extracted sparse features retain meaningful predictive information, while small reconstruction and mismatch errors indicate that the proxy remains behaviorally close to the original model. Empirically, we show that the bound becomes non-vacuous on GPT-2 Small, Gemma-2B, and Llama-3-8B at practical sample sizes. A detailed layerwise analysis of Llama-3-8B reveals a strong depth dependence, with later layers becoming much easier to certify, associated with both stronger local fidelity and weaker downstream error amplification. Finally, through feature-shuffling ablations, we show that the decomposition distinguishes genuine semantic alignment from mere statistical sparsity, providing a useful diagnostic for when SAE-based explanations become less reliable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a post-hoc generalization framework to certify the faithfulness of SAE-based explanations for frozen language models. It derives an upper bound on the base model's expected risk from four measurable quantities (proxy risk, SAE reconstruction gap, concept-pool mismatch, and sparse complexity), interprets non-vacuous bounds as evidence of explanatory faithfulness, and reports empirical results showing such bounds on GPT-2 Small, Gemma-2B, and Llama-3-8B, with layerwise analysis on Llama-3-8B and feature-shuffling ablations.
Significance. If the bound derivation holds without unmodeled shifts, the framework supplies a concrete, operational criterion for when SAE features retain predictive information and remain behaviorally close to the original model. The multi-model empirical validation, depth-dependent certification results, and ablations that separate semantic alignment from statistical sparsity are concrete strengths that advance mechanistic interpretability.
major comments (2)
- [Post-hoc generalization framework] Post-hoc generalization framework (abstract and §3): the central inequality claims that the risk difference between base model and SAE proxy is controlled exclusively by the four listed measurable quantities. The derivation is load-bearing for the certificate; it is unclear whether auxiliary assumptions (e.g., bounded Lipschitz constants or sensitivity of the remainder of the network) are required to close the bound, or whether downstream error amplification through attention and non-linear layers is explicitly controlled.
- [Layerwise analysis] Empirical section on Llama-3-8B (layerwise analysis): the reported depth dependence (later layers easier to certify) is attributed to stronger local fidelity and weaker downstream amplification, but the manuscript does not report separate measurements of per-layer sensitivity or distribution shift between SAE training data and risk-evaluation data, which would be needed to confirm that the four quantities suffice.
minor comments (2)
- Notation for the four quantities should be introduced with explicit definitions and symbols in the main text rather than only in the abstract.
- The feature-shuffling ablation results would benefit from a table reporting the change in each of the four quantities under shuffling.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and the opportunity to clarify aspects of our post-hoc generalization framework. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Post-hoc generalization framework] Post-hoc generalization framework (abstract and §3): the central inequality claims that the risk difference between base model and SAE proxy is controlled exclusively by the four listed measurable quantities. The derivation is load-bearing for the certificate; it is unclear whether auxiliary assumptions (e.g., bounded Lipschitz constants or sensitivity of the remainder of the network) are required to close the bound, or whether downstream error amplification through attention and non-linear layers is explicitly controlled.
Authors: The derivation in §3 establishes the bound by expressing the expected risk of the base model in terms of the proxy risk plus additive terms for the reconstruction gap (which measures the L2 difference in activations), concept-pool mismatch, and a complexity term arising from sparsity. This decomposition relies only on the triangle inequality applied to the loss and the definition of the proxy as a direct substitution of the activation. No bounded Lipschitz constants are assumed or needed, as the reconstruction gap term directly upper-bounds the difference in inputs to all subsequent layers without requiring sensitivity analysis of the network remainder. Downstream amplification is thus controlled implicitly by the magnitude of the reconstruction gap itself. We will revise §3 to include an explicit statement of the minimal assumptions used in the proof. revision: partial
-
Referee: [Layerwise analysis] Empirical section on Llama-3-8B (layerwise analysis): the reported depth dependence (later layers easier to certify) is attributed to stronger local fidelity and weaker downstream amplification, but the manuscript does not report separate measurements of per-layer sensitivity or distribution shift between SAE training data and risk-evaluation data, which would be needed to confirm that the four quantities suffice.
Authors: The depth dependence is directly observed through the four measurable quantities becoming smaller in later layers, which already incorporates any effects of local fidelity and downstream amplification. Separate per-layer sensitivity measurements are not required because the bound derivation shows that the net effect on risk is captured by these quantities. The SAE training and risk-evaluation data are drawn from the same corpus distribution, with no unmodeled shift introduced in the experimental protocol. We maintain that the reported quantities suffice to certify the bound without additional measurements. revision: no
Circularity Check
No circularity; bound derived from independent measurable quantities
full rationale
The paper presents a post-hoc generalization framework that derives an upper bound on base-model expected risk from four explicitly listed measurable quantities (proxy risk, SAE reconstruction gap, concept-pool mismatch, sparse complexity). The abstract and reader's summary give no indication that any quantity is defined in terms of the target risk, fitted directly to the certificate, or justified solely by self-citation. The derivation is treated as self-contained against external benchmarks once the four quantities are measured, satisfying the default expectation of no significant circularity. No load-bearing self-citation, self-definitional step, or fitted-input-called-prediction is exhibited in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The risk difference between original LM and SAE proxy can be upper-bounded using only proxy risk, reconstruction gap, concept-pool mismatch, and sparse complexity.
Reference graph
Works this paper leans on
-
[1]
Stronger generalization bounds for deep nets via a compression approach
URL https://arxiv.org/abs/ 1802.05296. Bisk, Y ., Zellers, R., Bras, R. L., Gao, J., and Choi, Y . Piqa: Reasoning about physical commonsense in natural language,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
PIQA: Reasoning about Physical Commonsense in Natural Language
URL https://arxiv.org/abs/ 1911.11641. Blumer, A., Ehrenfeucht, A., Haussler, D., and War- muth, M. K. Occam’s razor.Information Processing Letters, 24(6):377–380,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[3]
doi: https://doi.org/10.1016/0020-0190(87)90114-1
ISSN 0020-0190. doi: https://doi.org/10.1016/0020-0190(87)90114-1. URL https://www.sciencedirect.com/ science/article/pii/0020019087901141. Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y ., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Hatfield-Dodds, Z., Ta...
-
[4]
Cunningham, H., Ewart, A., Riggs, L., Huben, R., and Sharkey, L
https://transformer- circuits.pub/2023/monosemantic-features/index.html. Cunningham, H., Ewart, A., Riggs, L., Huben, R., and Sharkey, L. Sparse autoencoders find highly interpretable features in language models,
2023
-
[5]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
URL https:// arxiv.org/abs/2309.08600. Dziugaite, G. K. and Roy, D. M. Computing nonvac- uous generalization bounds for deep (stochastic) neu- ral networks with many more parameters than training data,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URL https://arxiv.org/ abs/2209.10652. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., Zhang, A., Rodriguez, A., Gregerson, A., Spataru, A., Roziere, B., Bir...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URL https://arxiv.org/abs/2407.21783. Lotfi, S., Finzi, M., Kuang, Y ., Rudner, T. G. J., Gold- blum, M., and Wilson, A. G. Non-vacuous generaliza- tion bounds for large language models, 2024a. URL https://arxiv.org/abs/2312.17173. Lotfi, S., Kuang, Y ., Amos, B., Goldblum, M., Finzi, M., and Wilson, A. G. Unlocking tokens as data points for generalizatio...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I
URLhttps://arxiv.org/abs/1902.04742. Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. Language models are unsupervised multitask learners
-
[9]
ISSN 0005-1098. doi: https://doi.org/10.1016/0005-1098(78)90005-5. URL https://www.sciencedirect.com/ science/article/pii/0005109878900055. Sakaguchi, K., Bras, R. L., Bhagavatula, C., and Choi, Y . Winogrande: An adversarial winograd schema challenge at scale,
-
[10]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
URL https://arxiv.org/abs/ 1907.10641. Team, G., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ram´e, A., Ferret, J., Liu, P., Tafti, P., Friesen, A., Casbon, M., Ramos, S., Kumar, R., Lan, C. L., Jerome, S., Tsit- sulin, A., Vieillard, N., Stanczyk, P., Girgin, S., Momchev, N., Hoffman, M., ...
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[11]
URL https://arxiv.org/abs/2408.00118. Wang, Z. Logitlens4llms: Extending logit lens analysis to modern large language models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y
URL https: //arxiv.org/abs/2503.11667. Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y . Hellaswag: Can a machine really finish your sentence?,
-
[13]
HellaSwag: Can a Machine Really Finish Your Sentence?
URL https://arxiv.org/abs/ 1905.07830. Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. Understanding deep learning requires rethinking gen- eralization,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[14]
URL https://arxiv.org/abs/ 1611.03530. A. Useful bound onBand∆ Recall B:= log 2 V α ,∆ := log 2 1 + (1−α)V α . Then B−∆ = log 2 V /α 1 + (1−α)V /α = log2 V α+ (1−α)V (16) Now, V≥α+ (1−α)V⇐ ⇒αV≥α⇐ ⇒V≥1. HenceB−∆≥0, so B≥∆. Therefore, if lA, lB ∈[B−∆, B] , then both quantities lie in an interval of length∆, which implies |lA −l B| ≤∆. Thus, |lA −l B| ∈[0,∆]...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
The layerwise sweeps in Section 5.2 and Appendix E use additional layer-specific checkpoints where needed
For the main certificate curves, we use one primary publicly available SAE checkpoint per model family. The layerwise sweeps in Section 5.2 and Appendix E use additional layer-specific checkpoints where needed. 12 From Sparse Features to Trustworthy Proxies: Certifying SAE-Based Interpretability Table 3.Global experimental settings shared across all model...
2019
-
[16]
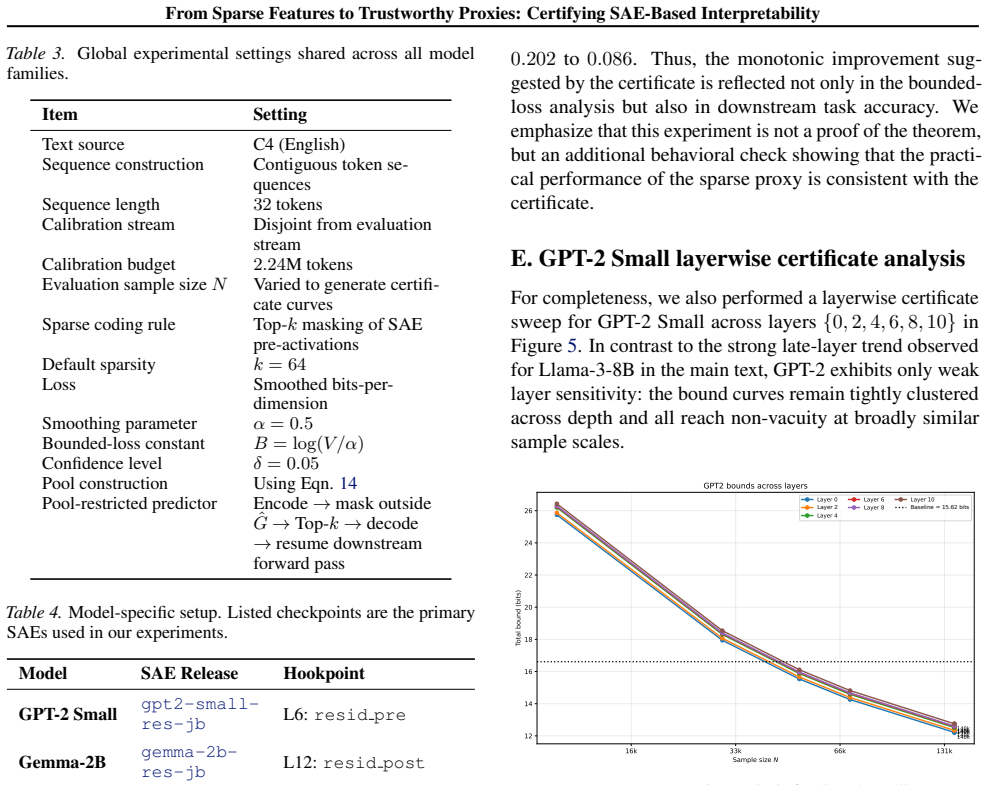
In contrast to the strong late-layer trend observed for Llama-3-8B in the main text, GPT-2 exhibits only weak layer sensitivity: the bound curves remain tightly clustered across depth and all reach non-vacuity at broadly similar sample scales. 16k 33k 66k 131k Sample size N 12 14 16 18 20 22 24 26T otal bound (bits) 140k140k140k140k140k140k GPT2 bounds ac...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.