LLM Parameters for Math Across Languages: Shared or Separate?
Pith reviewed 2026-06-27 00:28 UTC · model grok-4.3
The pith
Math-associated parameters in multilingual LLMs exhibit partial cross-lingual overlap concentrated in intermediate layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
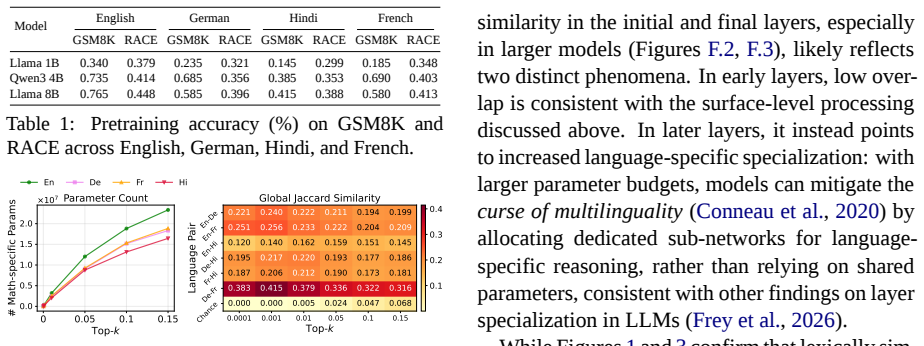
The extracted math-associated parameters exhibit partial cross-lingual overlap, with the strongest overlap concentrated in intermediate model layers. English consistently produces the largest set of math-relevant parameters, whereas lower-resource languages reveal smaller sets of relevant parameters. These results suggest that math-related behavior in multilingual LLMs is neither fully language-invariant nor fully language-specific, but instead exhibits partial cross-lingual parameter overlap with systematic language-dependent differences.
What carries the argument
Cross-lingual mechanistic analysis that localizes and extracts math-associated parameters for comparison of overlap across languages.
Load-bearing premise
The method for localizing and extracting math-associated parameters correctly distinguishes shared from language-specific parameters without substantial interference from other model behaviors or data artifacts.
What would settle it
An experiment in which ablating the identified overlapping parameters in one language produces no measurable change in math performance for another language would falsify the partial-overlap claim.
Figures


read the original abstract
Large language models (LLMs) exhibit substantial cross-lingual variation in mathematical reasoning performance, but it remains unclear whether these differences reflect language-specific parameters or a shared mechanism that manifests differently by language. We present a cross-lingual mechanistic analysis of mathematical reasoning in LLMs, enabling us to localize and compare model parameters that support mathematical reasoning across languages. We find that the extracted math-associated parameters exhibit partial cross-lingual overlap, with the strongest overlap concentrated in intermediate model layers. We further observe that English consistently produces the largest set of math-relevant parameters, whereas lower-resource languages reveal smaller sets of relevant parameters. These results suggest that math-related behavior in multilingual LLMs is neither fully language-invariant nor fully language-specific, but instead exhibits partial cross-lingual parameter overlap with systematic language-dependent differences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a cross-lingual mechanistic analysis of mathematical reasoning in LLMs localizes math-associated parameters showing partial overlap across languages, with strongest overlap in intermediate layers; English yields the largest such set while lower-resource languages yield smaller sets. This leads to the conclusion that math-related behavior is neither fully language-invariant nor fully language-specific but exhibits partial cross-lingual parameter overlap with systematic language-dependent differences.
Significance. If the extraction method is shown to be valid and free of the confounds noted in the stress-test, the result would provide a concrete mechanistic account of how multilingual LLMs implement math reasoning, with implications for model editing, cross-lingual transfer, and targeted improvement of low-resource performance. The layer-wise and resource-level patterns are potentially falsifiable predictions that could be tested in follow-up work.
major comments (1)
- [Abstract] Abstract (and entire manuscript as presented): the central claim of partial cross-lingual overlap rests on an unspecified 'cross-lingual mechanistic analysis' for localizing and extracting math-associated parameters. No description is given of the intervention or localization procedure, the math tasks or datasets used, model sizes, statistical controls, or validation against tokenization differences, training-data imbalance, or general language-modeling activations. Without these details the reported overlap and the English-vs.-lower-resource size difference cannot be distinguished from artifacts.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need for greater methodological transparency. We agree that the abstract is too high-level and that the presentation of the localization procedure requires expansion to allow proper evaluation of the claims. We will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (and entire manuscript as presented): the central claim of partial cross-lingual overlap rests on an unspecified 'cross-lingual mechanistic analysis' for localizing and extracting math-associated parameters. No description is given of the intervention or localization procedure, the math tasks or datasets used, model sizes, statistical controls, or validation against tokenization differences, training-data imbalance, or general language-modeling activations. Without these details the reported overlap and the English-vs.-lower-resource size difference cannot be distinguished from artifacts.
Authors: We accept this criticism. The abstract is intentionally concise and therefore omits procedural specifics; the body of the manuscript contains a Methods section that describes the intervention technique, but we agree the description is not sufficiently detailed or prominent for the central claim. In the revision we will (1) expand the abstract with a one-sentence summary of the localization method, (2) add an explicit subsection detailing the intervention procedure, the math tasks and datasets (including how they were translated), the models and sizes examined, and the statistical controls employed, and (3) include new validation experiments that directly test for confounds arising from tokenization, training-data imbalance, and non-math language-modeling activations. These additions will make it possible to evaluate whether the reported overlap exceeds what would be expected from such artifacts. revision: yes
Circularity Check
No significant circularity; empirical localization method stands independent of its outputs
full rationale
The paper reports results from a cross-lingual mechanistic analysis that localizes math-associated parameters and measures their overlap across languages. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided abstract or description. The central claim (partial overlap strongest in intermediate layers, English yielding largest set) is presented as an observation from the analysis rather than a quantity derived by construction from its own inputs. The method itself is not shown to be self-definitional or to smuggle an ansatz via prior self-citation. This is the normal case of an empirical paper whose validity hinges on the soundness of its experimental procedure, not on definitional circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ethics guidelines for trustworthy AI , volume=
High-level expert group on artificial intelligence , author=. Ethics guidelines for trustworthy AI , volume=. 2019 , publisher=
2019
-
[2]
arXiv preprint arXiv:1911.01547 , year=
On the measure of intelligence , author=. arXiv preprint arXiv:1911.01547 , year=
Pith/arXiv arXiv 1911
-
[3]
arXiv preprint arXiv:2402.00157 , year=
Large language models for mathematical reasoning: Progresses and challenges , author=. arXiv preprint arXiv:2402.00157 , year=
-
[4]
arXiv preprint arXiv:2402.15861 , year=
Mathwell: Generating educational math word problems at scale , author=. arXiv preprint arXiv:2402.15861 , year=
-
[5]
arXiv preprint arXiv:2402.00262 , year=
Computational experiments meet large language model based agents: A survey and perspective , author=. arXiv preprint arXiv:2402.00262 , year=
-
[6]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Math neurosurgery: Isolating language models’ math reasoning abilities using only forward passes , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[7]
International Conference on Machine Learning , pages=
Task-specific skill localization in fine-tuned language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[8]
arXiv preprint arXiv:2306.11695 , year=
A simple and effective pruning approach for large language models , author=. arXiv preprint arXiv:2306.11695 , year=
-
[9]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Breaking language barriers in multilingual mathematical reasoning: Insights and observations , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[10]
arXiv preprint arXiv:2501.02448 , year=
Understand, Solve and Translate: Bridging the Multilingual Mathematical Reasoning Gap , author=. arXiv preprint arXiv:2501.02448 , year=
-
[11]
arXiv preprint arXiv:2009.09796 , year=
Multi-task learning with deep neural networks: A survey , author=. arXiv preprint arXiv:2009.09796 , year=
arXiv 2009
-
[12]
International conference on machine learning , pages=
Which tasks should be learned together in multi-task learning? , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[13]
2024 , month = sep, day =
Llama 3.2: Revolutionizing Edge AI and Vision with Open, Customizable Models , author =. 2024 , month = sep, day =
2024
-
[14]
2024 , month = jul, day =
Introducing Llama 3.1: Our Most Capable Models to Date , author =. 2024 , month = jul, day =
2024
-
[15]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[16]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[17]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[18]
arXiv preprint arXiv:1704.04683 , year=
Race: Large-scale reading comprehension dataset from examinations , author=. arXiv preprint arXiv:1704.04683 , year=
-
[19]
arXiv preprint arXiv:2407.21787 , year=
Large language monkeys: Scaling inference compute with repeated sampling , author=. arXiv preprint arXiv:2407.21787 , year=
-
[20]
2011 , publisher=
Comparative Indo-European Linguistics: An Introduction , author=. 2011 , publisher=
2011
-
[21]
arXiv preprint arXiv:2310.10631 , year=
Llemma: An open language model for mathematics , author=. arXiv preprint arXiv:2310.10631 , year=
-
[22]
arXiv preprint arXiv:2506.02126 , year=
Knowledge or Reasoning? A Close Look at How LLMs Think Across Domains , author=. arXiv preprint arXiv:2506.02126 , year=
-
[23]
arXiv preprint arXiv:2601.02996 , year=
Large Reasoning Models Are (Not Yet) Multilingual Latent Reasoners , author=. arXiv preprint arXiv:2601.02996 , year=
-
[24]
arXiv preprint arXiv:2207.04672 , year=
No language left behind: Scaling human-centered machine translation , author=. arXiv preprint arXiv:2207.04672 , year=
-
[25]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[26]
arXiv preprint arXiv:2601.19847 , year=
Identifying and Transferring Reasoning-Critical Neurons: Improving LLM Inference Reliability via Activation Steering , author=. arXiv preprint arXiv:2601.19847 , year=
-
[27]
arXiv preprint arXiv:2507.09185 , year=
Detecting and pruning prominent but detrimental neurons in large language models , author=. arXiv preprint arXiv:2507.09185 , year=
-
[28]
arXiv preprint arXiv:2410.01288 , year=
Mitigating copy bias in in-context learning through neuron pruning , author=. arXiv preprint arXiv:2410.01288 , year=
-
[29]
arXiv preprint arXiv:2101.11109 , year=
First align, then predict: Understanding the cross-lingual ability of multilingual BERT , author=. arXiv preprint arXiv:2101.11109 , year=
-
[30]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Language-specific neurons: The key to multilingual capabilities in large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Unsupervised cross-lingual representation learning at scale , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[32]
arXiv preprint arXiv:2502.21074 , year=
Codi: Compressing chain-of-thought into continuous space via self-distillation , author=. arXiv preprint arXiv:2502.21074 , year=
-
[33]
arXiv preprint arXiv:2406.09265 , year=
Sharing matters: Analysing neurons across languages and tasks in llms , author=. arXiv preprint arXiv:2406.09265 , year=
-
[34]
arXiv preprint arXiv:2603.08391 , year=
Adaptive Loops and Memory in Transformers: Think Harder or Know More? , author=. arXiv preprint arXiv:2603.08391 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.