Robust and Interpretable Adaptation of Equivariant Materials Foundation Models via Sparsity-promoting Fine-tuning
Pith reviewed 2026-06-26 21:37 UTC · model grok-4.3
The pith
Sparsity-promoting fine-tuning adapts E(3)-equivariant materials foundation models by updating only about 3 percent of parameters while matching full fine-tuning performance on energy and force tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
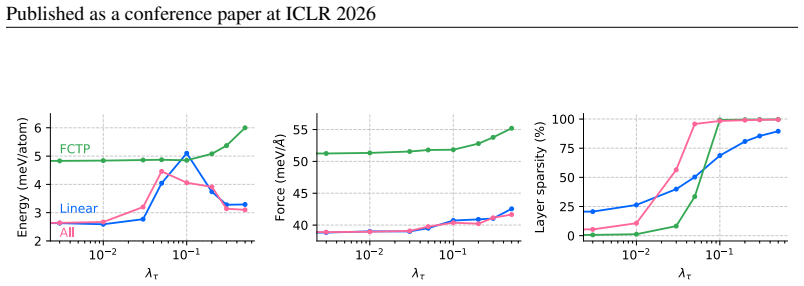
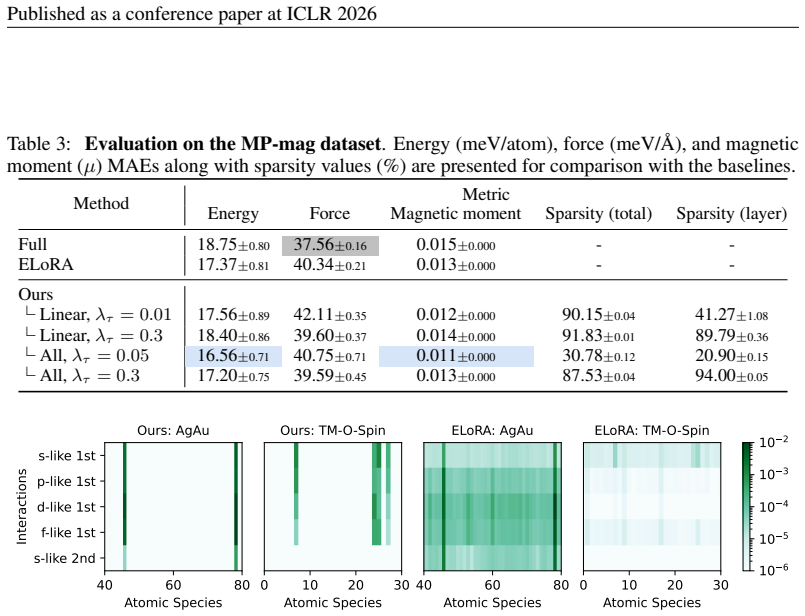
By applying sparsity promotion during fine-tuning, E(3)-equivariant materials foundation models can be adapted to new domains so that performance on energy, force, and magnetic tasks matches or exceeds that of full fine-tuning and equivariant low-rank adaptation, even when only roughly 3 percent of parameters (sometimes as little as 0.5 percent) are updated; the resulting sparsity masks exhibit physically interpretable structure such as enhanced d-orbital weighting in transition-metal systems.
What carries the argument
Sparsity-promoting fine-tuning that selectively updates parameters by exploiting the structural properties of E(3)-equivariant models.
If this is right
- Energy and force predictions on molecular and crystalline benchmarks reach or exceed full fine-tuning accuracy.
- The same procedure transfers to magnetic moment prediction and magnetism-aware total energy modeling.
- Sparsity masks obtained after adaptation display physically meaningful patterns such as increased d-orbital contributions in transition metals.
- Parameter counts as low as 0.5 percent suffice for the reported accuracy levels.
Where Pith is reading between the lines
- The approach may reduce the computational barrier for specializing large foundation models to narrow chemical subspaces.
- Sparsity patterns could serve as a diagnostic tool for identifying which model components encode particular physical interactions.
- Analogous sparsity techniques might be tested on other symmetry-preserving architectures used in physics simulations.
Load-bearing premise
The built-in symmetries of E(3)-equivariant models allow a sparsity-promoting procedure to identify a small set of parameters whose updates suffice for downstream accuracy.
What would settle it
A controlled experiment on a standard molecular benchmark in which the sparsity-tuned model shows statistically significant worse energy or force errors than full fine-tuning would falsify the performance claim.
Figures
read the original abstract
Pre-trained materials foundation models, or machine learning interatomic potentials, leverage general physicochemical knowledge to effectively approximate potential energy surfaces. However, they often require domain-specific calibration due to physicochemical diversity as well as mismatches between practical computational settings and those used in constructing the pre-training data. To address this, we propose a sparsity-promoting fine-tuning method that selectively updates model parameters by exploiting the structural properties of E(3)-equivariant materials foundation models. On energy and force prediction tasks across molecular and crystalline benchmarks, our method matches or surpasses full fine-tuning and equivariant low-rank adaptation while updating only $\sim$3~\% of parameters, and in some cases as little as $\sim$0.5~\%. Beyond energy and force calibration, we further demonstrate task generalizability by applying our method to magnetic moment prediction and magnetism-aware total energy modeling. Finally, analysis of sparsity patterns reveals physically interpretable signatures, such as enhanced $d$-orbital contributions in transition metal systems. Overall, our results establish sparsity-promoting fine-tuning as a flexible and interpretable method for domain specialization of equivariant materials foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a sparsity-promoting fine-tuning method for E(3)-equivariant materials foundation models. The method exploits the structural properties of these models to selectively update a small fraction of parameters (~3% or less), claiming to match or exceed the performance of full fine-tuning and equivariant low-rank adaptation on energy and force prediction tasks for molecular and crystalline systems. It also demonstrates generalization to magnetic moment prediction and magnetism-aware energy modeling, with sparsity patterns providing physically interpretable insights, such as enhanced d-orbital contributions in transition metal systems.
Significance. If the empirical results hold with the reported quantitative support, this work offers a practical route to efficient domain adaptation of large equivariant foundation models in materials science. The combination of parameter efficiency, performance parity with full fine-tuning, task generalizability, and physical interpretability of sparsity patterns represents a meaningful advance over standard adaptation techniques like LoRA, particularly for resource-constrained fine-tuning scenarios.
minor comments (2)
- [Abstract] Abstract: the performance claims would be strengthened by including at least one concrete quantitative example (e.g., MAE or force RMSE values with error bars) rather than the qualitative statement of matching or surpassing baselines.
- [Methods] The description of how sparsity promotion exploits E(3)-equivariance would benefit from a brief schematic or pseudocode in the methods section to clarify the selective update mechanism.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. The assessment accurately captures the contributions of sparsity-promoting fine-tuning for E(3)-equivariant materials foundation models. No major comments were listed in the report.
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical sparsity-promoting fine-tuning method for E(3)-equivariant materials models and reports benchmark performance (energy/force prediction matching full fine-tuning at ~3% or fewer updated parameters). No derivations, equations, or first-principles results are presented that reduce claimed outcomes to inputs by construction. The approach applies existing equivariant structure via sparsity; performance claims rest on external benchmarks rather than self-referential fitting or self-citation chains. This is a standard empirical adaptation paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kingma and Max Welling , title =
Diederik P. Kingma and Max Welling , title =
-
[2]
and Sham, L
Kohn, W. and Sham, L. J. , year =. Self-. Physical Review , volume =
-
[3]
The Journal of chemical physics , volume=
Neural network models of potential energy surfaces , author=. The Journal of chemical physics , volume=. 1995 , publisher=
1995
-
[4]
Chemical physics letters , volume=
Description of the potential energy surface of the water dimer with an artificial neural network , author=. Chemical physics letters , volume=. 1997 , publisher=
1997
-
[5]
Chemical Physics Letters , volume=
Representing high-dimensional potential-energy surfaces for reactions at surfaces by neural networks , author=. Chemical Physics Letters , volume=. 2004 , publisher=
2004
-
[6]
The Journal of chemical physics , volume=
Using neural networks to represent potential surfaces as sums of products , author=. The Journal of chemical physics , volume=. 2006 , publisher=
2006
-
[7]
Physical Review B—Condensed Matter and Materials Physics , volume=
Nonadiabatic effects in the dissociation of oxygen molecules at the Al (111) surface , author=. Physical Review B—Condensed Matter and Materials Physics , volume=. 2008 , publisher=
2008
-
[8]
The Journal of chemical physics , volume=
Cis→ trans, trans→ cis isomerizations and N--O bond dissociation of nitrous acid (HONO) on an ab initio potential surface obtained by novelty sampling and feed-forward neural network fitting , author=. The Journal of chemical physics , volume=. 2008 , publisher=
2008
-
[9]
The Journal of chemical physics , volume=
Development of generalized potential-energy surfaces using many-body expansions, neural networks, and moiety energy approximations , author=. The Journal of chemical physics , volume=. 2009 , publisher=
2009
-
[10]
Convolutional networks on graphs for learning molecular fingerprints , author=
-
[11]
and Riley, Patrick F
Gilmer, Justin and Schoenholz, Samuel S. and Riley, Patrick F. and Vinyals, Oriol and Dahl, George E. , year =. Neural
-
[12]
Tensor field networks: Rotation-and translation-equivariant neural networks for 3d point clouds , author=. arXiv:1802.08219 , year=
-
[13]
Clebsch--gordan nets: a fully fourier space spherical convolutional neural network , author=
-
[14]
Unke, Oliver T and Meuwly, Markus , journal=. Phys. 2019 , publisher=
2019
-
[15]
E (n) equivariant graph neural networks , author=
-
[16]
Riebesell, Janosh and Goodall, Rhys E. A. and Benner, Philipp and Chiang, Yuan and Deng, Bowen and Ceder, Gerbrand and Asta, Mark and Lee, Alpha A. and Jain, Anubhav and Persson, Kristin A. , title=. Nature Machine Intelligence , year=
-
[17]
The open molecules 2025 (omol25) dataset, evaluations, and models , author=. arXiv:2505.08762 , year=
arXiv 2025
- [18]
-
[19]
2022 , journal =
E(3)-Equivariant Graph Neural Networks for Data-Efficient and Accurate Interatomic Potentials , author =. 2022 , journal =
2022
-
[20]
High-Performance Training and Inference for Deep Equivariant Interatomic Potentials , author =. 2025 , month = apr, number =. 2504.16068 , primaryclass =
arXiv 2025
-
[21]
and Chmiela, Stefan and Gastegger, Michael and Schütt, Kristof T
Unke, Oliver T. and Chmiela, Stefan and Gastegger, Michael and Schütt, Kristof T. and Sauceda, Huziel E. and Müller, Klaus-Robert , year =
-
[22]
Nature Communications , volume=
Learning local equivariant representations for large-scale atomistic dynamics , author=. Nature Communications , volume=. 2023 , publisher=
2023
-
[23]
Equiformer: Equivariant Graph Attention Transformer for 3D Atomistic Graphs , author=
-
[24]
Batatia, Ilyes and Kovacs, David P and Simm, Gregor and Ortner, Christoph and Cs
-
[25]
and Kovács, Dávid P
Batatia, Ilyes and Benner, Philipp and Chiang, Yuan and Elena, Alin M. and Kovács, Dávid P. and Riebesell, Janosh and Advincula, Xavier R. and Asta, Mark and Avaylon, Matthew and Baldwin, William J. and Berger, Fabian and Bernstein, Noam and Bhowmik, Arghya and Bigi, Filippo and Blau, Samuel M. and Cărare, Vlad and Ceriotti, Michele and Chong, Sanggyu and...
2025
-
[26]
2025 , journal =
Kov. 2025 , journal =
2025
-
[27]
and Ceder, Gerbrand , title=
Deng, Bowen and Zhong, Peichen and Jun, KyuJung and Riebesell, Janosh and Han, Kevin and Bartel, Christopher J. and Ceder, Gerbrand , title=. Nature Machine Intelligence , year=
-
[28]
Nature Computational Science , volume=
A universal graph deep learning interatomic potential for the periodic table , author=. Nature Computational Science , volume=. 2022 , publisher=
2022
-
[29]
Journal of chemical theory and computation , volume=
Scalable parallel algorithm for graph neural network interatomic potentials in molecular dynamics simulations , author=. Journal of chemical theory and computation , volume=. 2024 , publisher=
2024
-
[30]
Orb: A fast, scalable neural network potential , author=. arXiv:2410.22570 , year=
-
[31]
Mattersim: A deep learning atomistic model across elements, temperatures and pressures , author=. arXiv:2405.04967 , year=
-
[32]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=ICLR, year=. Lo
-
[33]
Parameter-efficient transfer learning for NLP , author=
-
[34]
Soft threshold weight reparameterization for learnable sparsity , author=
-
[35]
Adaptergnn: Parameter-efficient fine-tuning improves generalization in gnns , author=
-
[36]
Fang, Taoran and Zhang, Yunchao and YANG, YANG and Wang, Chunping and Chen, Lei , booktitle = NeurIPS, title =
-
[37]
2025 , doi =
Yang, Zhe-Rui and Han, Jindong and Wang, Chang-Dong and Liu, Hao , title =. 2025 , doi =
2025
-
[38]
GeoAda: Efficiently Finetune Geometric Diffusion Models with Equivariant Adapters , author=
-
[39]
Chen Wang and Siyu Hu and Guangming Tan and Weile Jia , booktitle=ICML, year=
-
[40]
Open materials 2024 (omat24) inorganic materials dataset and models , author=. arXiv:2410.12771 , year=
Pith/arXiv arXiv 2024
-
[41]
Cosmos world foundation model platform for physical ai , author=. arXiv:2501.03575 , year=
-
[42]
Gemma: Open models based on gemini research and technology , author=. arXiv:2403.08295 , year=
-
[43]
Journal of Machine Learning Research , year =
Torsten Hoefler and Dan Alistarh and Tal Ben-Nun and Nikoli Dryden and Alexandra Peste , title =. Journal of Machine Learning Research , year =
-
[44]
Pruning Convolutional Neural Networks for Resource Efficient Inference , author=
-
[45]
Wen, Wei and Wu, Chunpeng and Wang, Yandan and Chen, Yiran and Li, Hai , booktitle = NeurIPS, title =
-
[46]
Louizos, Christos and Ullrich, Karen and Welling, Max , booktitle = NeurIPS, title =
-
[47]
Byungseok Roh and JaeWoong Shin and Wuhyun Shin and Saehoon Kim , booktitle=ICLR, year=. Sparse
-
[48]
Han, Song and Pool, Jeff and Tran, John and Dally, William , booktitle = NeurIPS, title =
-
[49]
Pruning Filters for Efficient ConvNets , author=
-
[50]
2015 , booktitle=BMVC, doi=
Data-free Parameter Pruning for Deep Neural Networks , author=. 2015 , booktitle=BMVC, doi=
2015
-
[51]
Rethinking the Value of Network Pruning , author=
-
[52]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks , author=
-
[53]
Efficient Lottery Ticket Finding: Less Data is More , author =
-
[54]
Drawing Early-Bird Tickets: Toward More Efficient Training of Deep Networks , author=
-
[55]
Kingma , booktitle=ICLR, year=
Christos Louizos and Max Welling and Diederik P. Kingma , booktitle=ICLR, year=. Learning Sparse Neural Networks through
-
[56]
Savarese, Pedro and Silva, Hugo and Maire, Michael , booktitle = NeurIPS, title =
-
[57]
Dynamic Sparse Training: Find Efficient Sparse Network From Scratch With Trainable Masked Layers , author=
-
[58]
XIAO, XIA and Wang, Zigeng and Rajasekaran, Sanguthevar , booktitle = NeurIPS, title =
- [59]
-
[60]
Soft Threshold Weight Reparameterization for Learnable Sparsity , author =
-
[61]
Brunton and Joshua L
Steven L. Brunton and Joshua L. Proctor and J. Nathan Kutz , title =. Proc. of the National Academy of Sciences , volume =
-
[62]
Nathan and Brunton, Steven L
Kaheman, Kadierdan and Kutz, J. Nathan and Brunton, Steven L. , title =. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =
-
[63]
and Brunton, Steven L
Mangan, Niall M. and Brunton, Steven L. and Proctor, Joshua L. and Kutz, J. Nathan , journal=. Inferring Biological Networks by Sparse Identification of Nonlinear Dynamics , year=
-
[64]
Mangan, N. M. and Askham, T. and Brunton, S. L. and Kutz, J. N. and Proctor, J. L. , title =. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume =
-
[65]
Rudy and Steven L
Samuel H. Rudy and Steven L. Brunton and Joshua L. Proctor and J. Nathan Kutz , title =. Science Advances , volume =
-
[66]
Nathan Kutz and Steven L
Kathleen Champion and Bethany Lusch and J. Nathan Kutz and Steven L. Brunton , title =. Proceedings of the National Academy of Sciences , volume =
-
[67]
doi:10.1088/2632-2153/ad450e , year =
Sandberg, Johannes and Voigtmann, Thomas and Devijver, Emilie and Jakse, Noel , title =. doi:10.1088/2632-2153/ad450e , year =
-
[68]
and Ortner, Christoph , title=
Torabi, Tina and Militzer, Matthias and Friedlander, Michael P. and Ortner, Christoph , title=. Machine Learning: Science and Technology , year=
-
[69]
QUANTUM ESPRESSO: a modular and open-source software project for quantum simulations of materials,
Giannozzi, Paolo and Baroni, Stefano and Bonini, Nicola and Calandra, Matteo and Car, Roberto and Cavazzoni, Carlo and Ceresoli, Davide and Chiarotti, Guido L and Cococcioni, Matteo and Dabo, Ismaila and Dal Corso, Andrea and de Gironcoli, Stefano and Fabris, Stefano and Fratesi, Guido and Gebauer, Ralph and Gerstmann, Uwe and Gougoussis, Christos and Kok...
-
[70]
Smith, J. S. and Isayev, O. and Roitberg, A. E. ANI -1: an extensible neural network potential with DFT accuracy at force field computational cost. Chemical Science. 2017
2017
-
[71]
Decoupled Weight Decay Regularization , author=
-
[72]
, year =
Huber, Peter J. , year =. Robust. The Annals of Mathematical Statistics , volume =
-
[73]
Defazio, Aaron and Yang, Xingyu and Mehta, Harsh and Mishchenko, Konstantin and Khaled, Ahmed and Cutkosky, Ashok , booktitle = NeurIPS, title =
-
[74]
2025 , author =
MatterTune: an integrated, user-friendly platform for fine-tuning atomistic foundation models to accelerate materials simulation and discovery , journal =. 2025 , author =
2025
-
[75]
and Allen, Connor S
Radova, Mariia and Stark, Wojciech G. and Allen, Connor S. and Maurer, Reinhard J. and Bart. Fine-tuning foundation models of materials interatomic potentials with frozen transfer learning , journal=. 2025 , volume=
2025
-
[76]
Journal of Applied Physics , volume =
Liu, Xiaoqing and Zeng, Kehan and Luo, Zedong and Wang, Yangshuai and Zhao, Teng and Xu, Zhenli , title =. Journal of Applied Physics , volume =. 2026 , issn =
2026
-
[77]
Distillation of atomistic foundation models across architectures and chemical domains , author=. arXiv:2506.10956 , year=
-
[78]
2025 , journal =
Efficient fine-tuning of foundation atomistic models for reversible polymorphic phase transitions in organic molecular crystals , author=. 2025 , journal =
2025
-
[79]
2021 , journal =
High-Dimensional Neural Network Potentials for Magnetic Systems Using Spin-Dependent Atom-Centered Symmetry Functions , author =. 2021 , journal =
2021
-
[80]
2024 , journal =
An Accurate and Transferable Machine Learning Interatomic Potential for Nickel , author =. 2024 , journal =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.