Morpheus: A Morphology-Aware Neural Tokenizer and Word Embedder for Turkish
Pith reviewed 2026-06-26 20:51 UTC · model grok-4.3
The pith
Morpheus is a neural model that detects Turkish morpheme boundaries to produce reversible tokenizations and word embeddings in a single pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
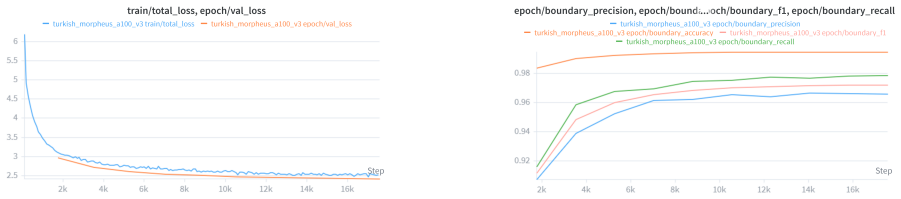
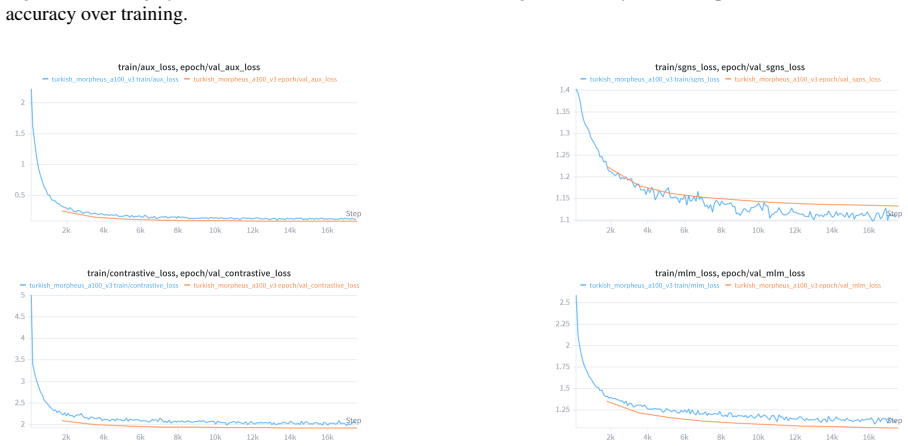
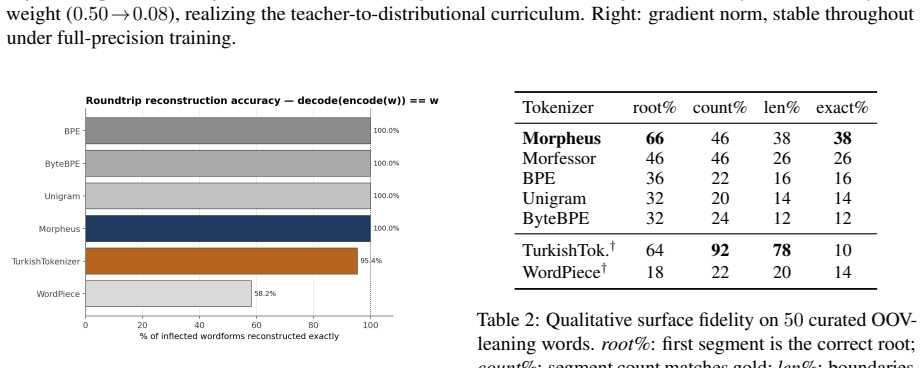
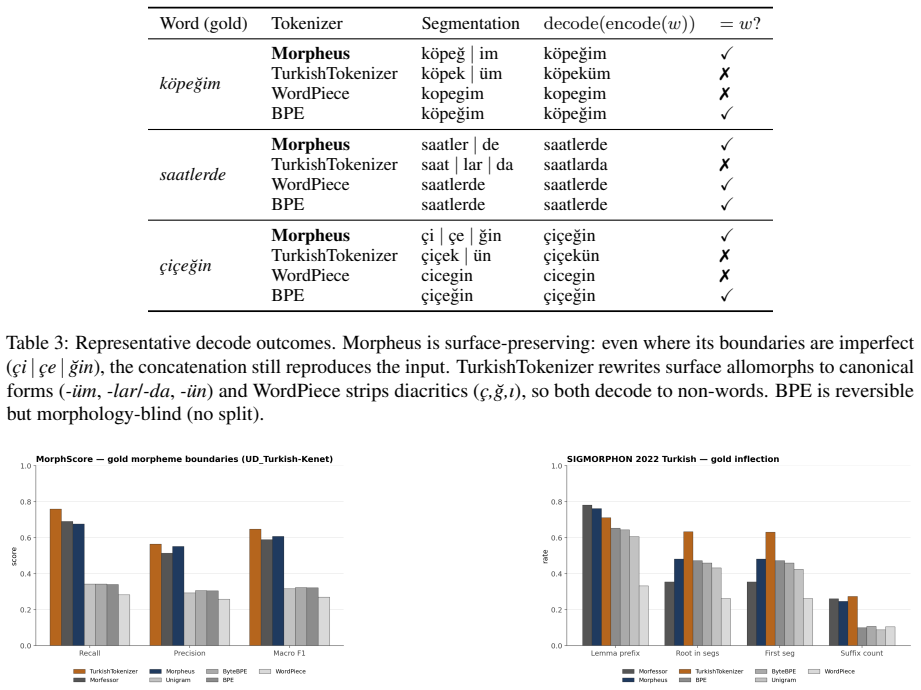
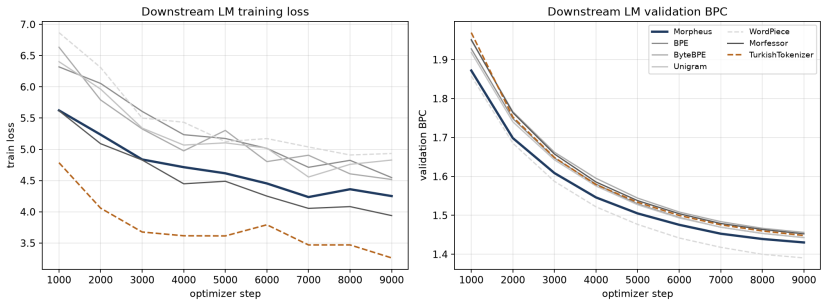
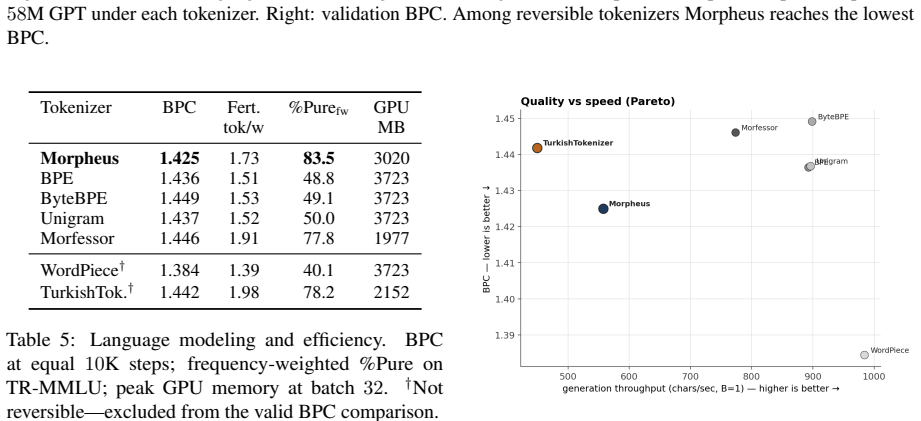
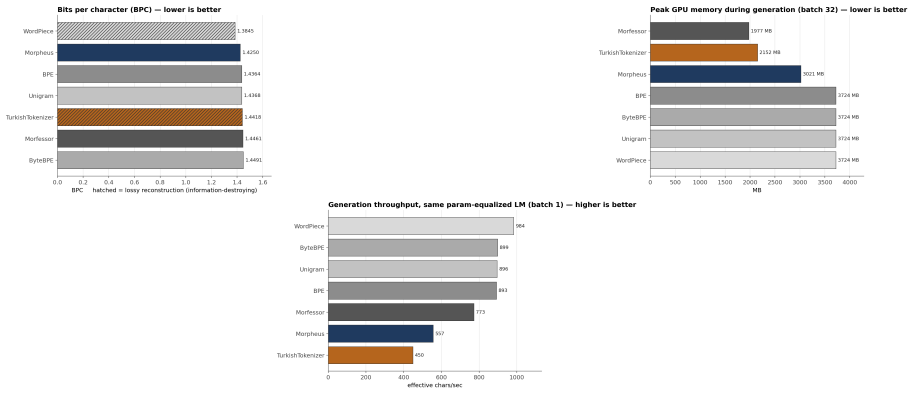
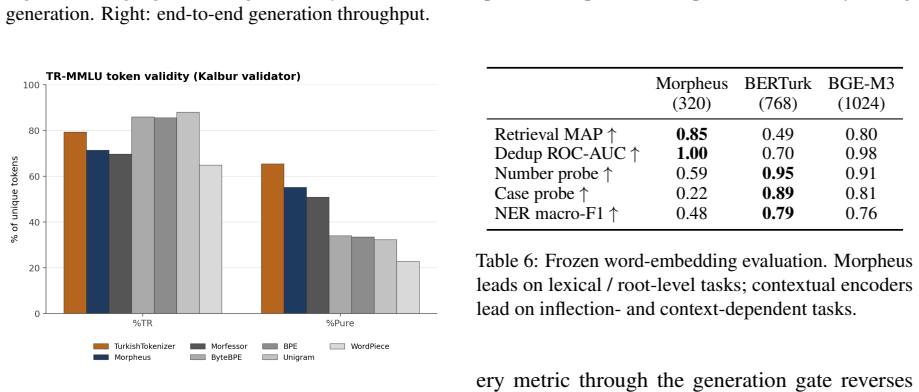
Morpheus presents a neural morpheme-boundary model for Turkish that functions as both a lossless tokenizer and a word embedder. By employing a differentiable Poisson-binomial dynamic program on per-character boundary probabilities, it produces soft memberships during training and exact segments at inference without any string normalization, guaranteeing that decode(encode(w)) equals w. This results in the lowest bits-per-character among reversible tokenizers at 1.425, double the morphological alignment of subword methods with a MorphScore macro-F1 of 0.61 versus about 0.32, and about 19 percent less GPU memory than 64K-vocabulary subword tokenizers. Frozen vectors from the model excel in lex
What carries the argument
The Morpheus neural network that outputs per-character boundary probabilities, converted by a Poisson-binomial dynamic program into morpheme segments and a structured word embedding.
If this is right
- Among reversible tokenizers, Morpheus attains the lowest bits-per-character at 1.425.
- It roughly doubles the gold morphological alignment of the subword family with MorphScore macro-F1 0.61 versus approximately 0.32.
- It uses about 19 percent less GPU memory than 64K-vocabulary subword tokenizers.
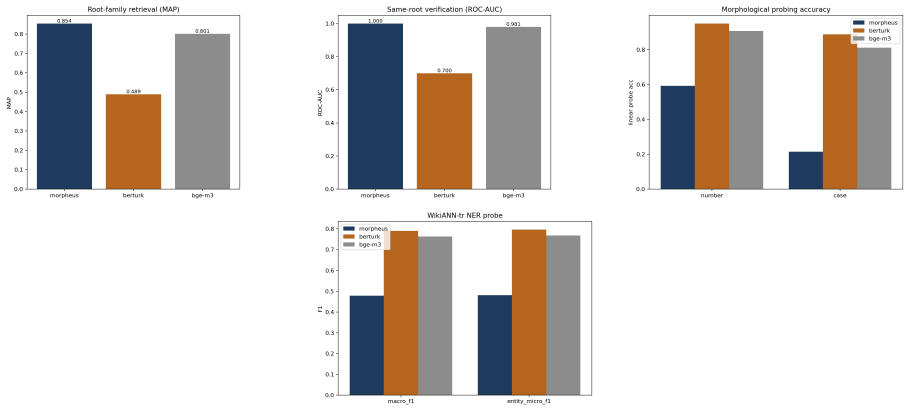
- Frozen Morpheus vectors lead on lexical retrieval with root-family MAP 0.85 and same-root verification with ROC-AUC 1.00.
- On context- and inflection-dependent tasks such as NER the heavier contextual encoders remain ahead due to the root-centric geometry.
Where Pith is reading between the lines
- The lossless property opens direct use in text generation pipelines where standard subword tokenizers break reversibility.
- The same architecture could be retrained on other agglutinative languages to test whether the boundary-probability approach transfers without language-specific rules.
- Combining the root-centric embeddings with a lightweight contextual layer might close the gap on tasks that require inflection sensitivity.
- The reduced memory footprint suggests the tokenizer could support larger batch sizes or longer sequences in downstream training.
Load-bearing premise
That per-character boundary probabilities learned by the neural network correspond sufficiently to true morpheme boundaries in Turkish to produce the claimed alignment and performance gains when converted via the Poisson-binomial dynamic program.
What would settle it
Running the trained model on a fresh set of 500 Turkish words with expert-annotated morpheme boundaries and checking whether the resulting MorphScore macro-F1 falls below 0.5 or the bits-per-character exceeds 1.5.
Figures

read the original abstract
Turkish is agglutinative: meaning is carried by morphemes, yet the subword tokenizers that drive modern language models split words by corpus statistics, fragmenting semantically loaded suffixes and -- in the case of WordPiece and rule-based analyzers -- failing to decode their output back to the original text. This paper presents \textbf{Morpheus}, a neural morpheme-boundary model for Turkish that is at once a lossless, morphology-aware tokenizer and a word-embedding producer. A differentiable Poisson-binomial dynamic program turns per-character boundary probabilities into soft morpheme memberships during training and exact segments at inference, with no string normalization, so $\mathrm{decode}(\mathrm{encode}(w)) = w$ holds by construction. Because the model is neural, the same forward pass that tokenizes also emits a structured word embedding. Among reversible tokenizers -- the only ones valid for generation -- Morpheus attains the lowest bits-per-character ($1.425$), roughly doubles the gold morphological alignment of the subword family (MorphScore macro-F1 $0.61$ vs.\ ${\sim}0.32$), and uses ${\sim}19\%$ less GPU memory than 64K-vocabulary subword tokenizers. As an embedder, frozen Morpheus vectors lead on lexical retrieval (root-family MAP $0.85$) and same-root verification (ROC-AUC $1.00$), surpassing the multilingual retriever BGE-M3 and BERTurk; on context- and inflection-dependent tasks (NER, case/number probing) the heavier contextual encoders remain ahead -- a trade-off we attribute to Morpheus's root-centric geometry. Code: https://github.com/lonewolf-rd/TurkishMorpheus; model: https://huggingface.co/lonewolflab/Morpheus-TR-50K; interactive demo: https://huggingface.co/spaces/lonewolflab/morpheus-tr-demo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Morpheus, a neural model for Turkish that predicts per-character morpheme-boundary probabilities and converts them via a differentiable Poisson-binomial dynamic program into soft segments for training and exact, reversible segments at inference. It claims to function simultaneously as a lossless tokenizer (decode(encode(w)) = w by construction) and a word embedder, reporting the lowest BPC (1.425) among reversible tokenizers, roughly doubled MorphScore macro-F1 (0.61 vs. ~0.32), ~19% lower GPU memory than 64K subword models, and leading results on root-family MAP (0.85) and same-root verification (ROC-AUC 1.00) when embeddings are frozen.
Significance. If the central claims hold after verification of training details and gold-alignment construction, the work would supply a morphology-aware, reversible alternative to corpus-statistic subword tokenizers for agglutinative languages, with direct benefits for generation fidelity and root-centric lexical representations.
major comments (2)
- [Abstract] The abstract states that the model is trained on per-character boundary probabilities but provides no information on the supervision signal (supervised morphological labels vs. unsupervised objectives), loss terms, or how gold morphological alignments for MorphScore were constructed. This information is required to determine whether the reported MorphScore and embedding gains follow from genuine morpheme recovery or from properties of the Poisson-binomial DP plus neural architecture.
- [Abstract] The headline embedding results (root-family MAP 0.85, ROC-AUC 1.00) are obtained with frozen Morpheus vectors; the manuscript must clarify whether these vectors are the structured embeddings emitted by the same forward pass that produces the segments, and whether any additional projection or pooling is applied before the retrieval and verification tasks.
minor comments (1)
- [Abstract] The abstract cites specific numeric results (BPC 1.425, MorphScore 0.61, memory reduction ~19%) without referencing the corresponding tables or experimental sections that would allow direct verification of the baselines and evaluation protocols.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity on the points raised.
read point-by-point responses
-
Referee: [Abstract] The abstract states that the model is trained on per-character boundary probabilities but provides no information on the supervision signal (supervised morphological labels vs. unsupervised objectives), loss terms, or how gold morphological alignments for MorphScore were constructed. This information is required to determine whether the reported MorphScore and embedding gains follow from genuine morpheme recovery or from properties of the Poisson-binomial DP plus neural architecture.
Authors: We agree the abstract is too concise on these points. The full manuscript (Section 3.2) specifies supervised training on per-character morpheme-boundary labels produced by the Zemberek morphological analyzer for Turkish, with a binary cross-entropy loss on the boundary probabilities combined with the differentiable Poisson-binomial DP objective. Gold alignments for MorphScore are obtained by character-level alignment of the analyzer's morpheme segmentations. We will expand the abstract with a brief clause noting the supervised boundary supervision and the analyzer-based gold construction. revision: yes
-
Referee: [Abstract] The headline embedding results (root-family MAP 0.85, ROC-AUC 1.00) are obtained with frozen Morpheus vectors; the manuscript must clarify whether these vectors are the structured embeddings emitted by the same forward pass that produces the segments, and whether any additional projection or pooling is applied before the retrieval and verification tasks.
Authors: The reported vectors are the structured embeddings emitted directly by the same neural forward pass that produces the per-character boundary probabilities (i.e., the word-encoder output prior to the DP). No additional projection or pooling is applied before the retrieval and verification tasks. We will add an explicit clarification sentence to the abstract and the experimental section describing the embedding extraction. revision: yes
Circularity Check
No circularity: empirical metrics are measured outcomes, not reductions by construction
full rationale
The abstract and claims contain no equations, derivations, or self-citations that reduce reported quantities (BPC 1.425, MorphScore 0.61, MAP 0.85, ROC-AUC 1.00) to fitted parameters or prior author results. Reversibility is stated as holding by construction via the DP, which is a design property rather than a circular prediction of performance. All headline numbers are presented as external evaluations against gold morphological alignments and retrieval benchmarks, with no load-bearing step that collapses to self-definition or fitted-input renaming. The derivation chain is therefore self-contained against the stated external metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Per-character boundary probabilities produced by the neural network align with true morpheme boundaries sufficiently to improve alignment metrics.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Neural Machine Translation of Rare Words with Subword Units , author =. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[2]
Kudo, Taku and Richardson, John , booktitle =
-
[3]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates , author =. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[4]
ACM Transactions on Speech and Language Processing , volume =
Unsupervised Models for Morpheme Segmentation and Morphology Learning , author =. ACM Transactions on Speech and Language Processing , volume =
-
[5]
Structure , year =
Zemberek, an Open Source NLP Framework for Turkic Languages , author =. Structure , year =
-
[6]
Schweter, Stefan , year =. doi:10.5281/zenodo.3770924 , url =
-
[7]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =
-
[8]
Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng , journal =
-
[9]
Su, Jianlin and Lu, Yu and Pan, Shengfeng and Murtadha, Ahmed and Wen, Bo and Liu, Yunfeng , journal =
-
[10]
Proceedings of the ACL-02 Workshop on Morphological and Phonological Learning (SIGPHON) , pages =
Unsupervised Discovery of Morphemes , author =. Proceedings of the ACL-02 Workshop on Morphological and Phonological Learning (SIGPHON) , pages =
-
[11]
Impact of Tokenization on Language Models: An Analysis for
Toraman, Cagri and Yilmaz, Eyup Halit and. Impact of Tokenization on Language Models: An Analysis for. ACM Transactions on Asian and Low-Resource Language Information Processing , volume =
-
[12]
Effect of Tokenization Granularity for
Kaya, Yi. Effect of Tokenization Granularity for. Intelligent Systems with Applications , volume =
-
[13]
Altinok, Duygu , journal =. Optimal
-
[16]
Ali and Fincan, Ali Arda and G
Bayram, M. Ali and Fincan, Ali Arda and G. Tokenization Standards and Evaluation in Natural Language Processing: A Comparative Analysis of Large Language Models on. 2025 33rd Signal Processing and Communications Applications Conference (SIU) , year =
2025
-
[18]
Gulgonul, Senol , year =
-
[19]
Ahmet Af s n Ak n and Mehmet D \"u ndar Ak n. 2007. Zemberek, an open source NLP framework for Turkic languages. Structure
2007
-
[20]
Duygu Altinok. 2026. Optimal Turkish subword strategies at scale: Systematic evaluation of data--vocabulary--morphology interplay. arXiv preprint arXiv:2602.06942
arXiv 2026
-
[21]
M. Ali Bayram, Ali Arda Fincan, Ahmet Semih G \"u m \"u s , Sercan Karaka s , Banu Diri, Sava s Y ld r m, and Demircan C elik. 2025a. Tokens with meaning: A hybrid tokenization approach for Turkish. arXiv preprint arXiv:2508.14292
-
[22]
M. Ali Bayram, Ali Arda Fincan, Ahmet Semih G \"u m \"u s , Sercan Karaka s , Banu Diri, and Sava s Y ld r m. 2025b. Tokenization standards for linguistic integrity: Turkish as a benchmark. arXiv preprint arXiv:2502.07057
-
[23]
Ali Bayram, Ali Arda Fincan, Ahmet Semih G \"u m \"u s , Sercan Karaka s , Banu Diri, and Sava s Y ld r m
M. Ali Bayram, Ali Arda Fincan, Ahmet Semih G \"u m \"u s , Sercan Karaka s , Banu Diri, and Sava s Y ld r m. 2025c. Tokenization standards and evaluation in natural language processing: A comparative analysis of large language models on Turkish. In 2025 33rd Signal Processing and Communications Applications Conference (SIU). IEEE
2025
-
[24]
Ali Bayram, Banu Diri, and Sava s Y ld r m
M. Ali Bayram, Banu Diri, and Sava s Y ld r m. 2026. Adapting multilingual embedding models to Turkish via cross-lingual tokenizer surgery and offline distillation. arXiv preprint arXiv:2605.29992
Pith/arXiv arXiv 2026
-
[25]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. BGE M3 -embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216
Pith/arXiv arXiv 2024
-
[26]
Mathias Creutz and Krista Lagus. 2002. Unsupervised discovery of morphemes. In Proceedings of the ACL-02 Workshop on Morphological and Phonological Learning (SIGPHON), pages 21--30
2002
-
[27]
Mathias Creutz and Krista Lagus. 2007. Unsupervised models for morpheme segmentation and morphology learning. ACM Transactions on Speech and Language Processing, 4(1):1--34
2007
-
[28]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT : Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL, pages 4171--4186
2019
-
[29]
Senol Gulgonul. 2025. HeceTokenizer : A syllable-based tokenization approach for Turkish retrieval. Preprint
2025
-
[30]
C \"u neyd Tantu g
Yi g it Bekir Kaya and A. C \"u neyd Tantu g . 2024. Effect of tokenization granularity for Turkish large language models. Intelligent Systems with Applications, 21:200335
2024
-
[31]
Taku Kudo. 2018. Subword regularization: Improving neural network translation models with multiple subword candidates. In Proceedings of ACL, pages 66--75
2018
-
[32]
Taku Kudo and John Richardson. 2018. SentencePiece : A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of EMNLP: System Demonstrations, pages 66--71
2018
-
[33]
Stefan Schweter. 2020. BERTurk -- BERT models for Turkish. Zenodo
2020
-
[34]
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural machine translation of rare words with subword units. In Proceedings of ACL, pages 1715--1725
2016
-
[35]
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2021. RoFormer : Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864
Pith/arXiv arXiv 2021
-
[36]
Cagri Toraman, Eyup Halit Yilmaz, Furkan S ah nu c , and Oguzhan Ozcelik. 2023. Impact of tokenization on language models: An analysis for Turkish. ACM Transactions on Asian and Low-Resource Language Information Processing, 22(4):1--21
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.