Graph Grounded Cross Attention Transformer Neural Network for Structurally Constrained Full Event Sequence Generation in Predictive Process Monitoring
Pith reviewed 2026-06-26 21:23 UTC · model grok-4.3
The pith
GGATN generates full event sequences respecting process topology and attributes in a single non-autoregressive pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
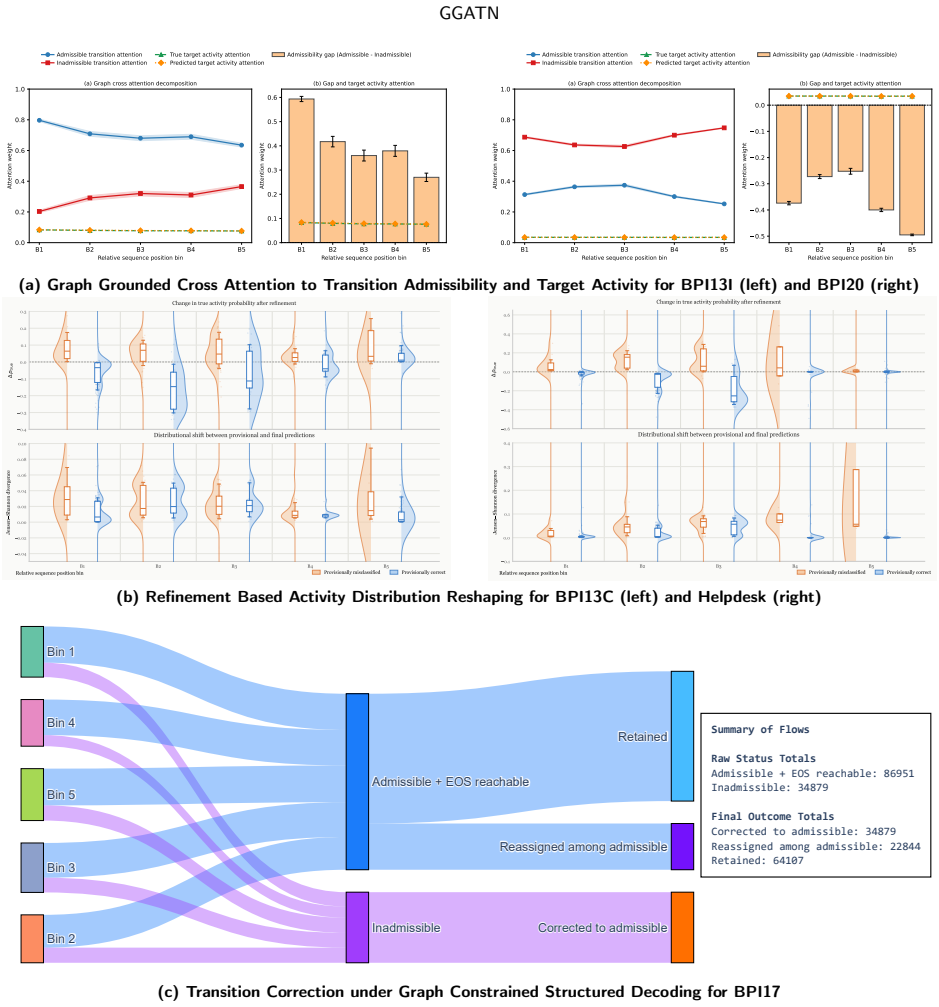
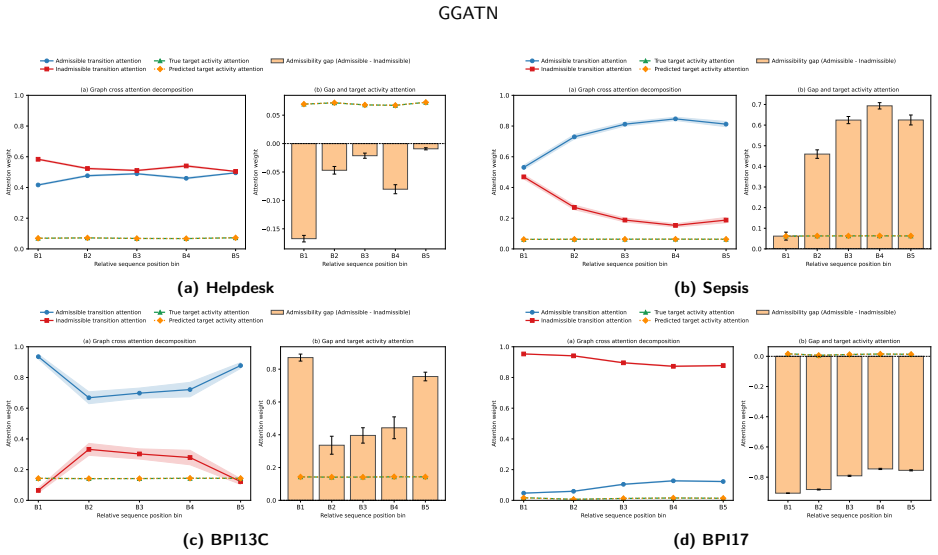
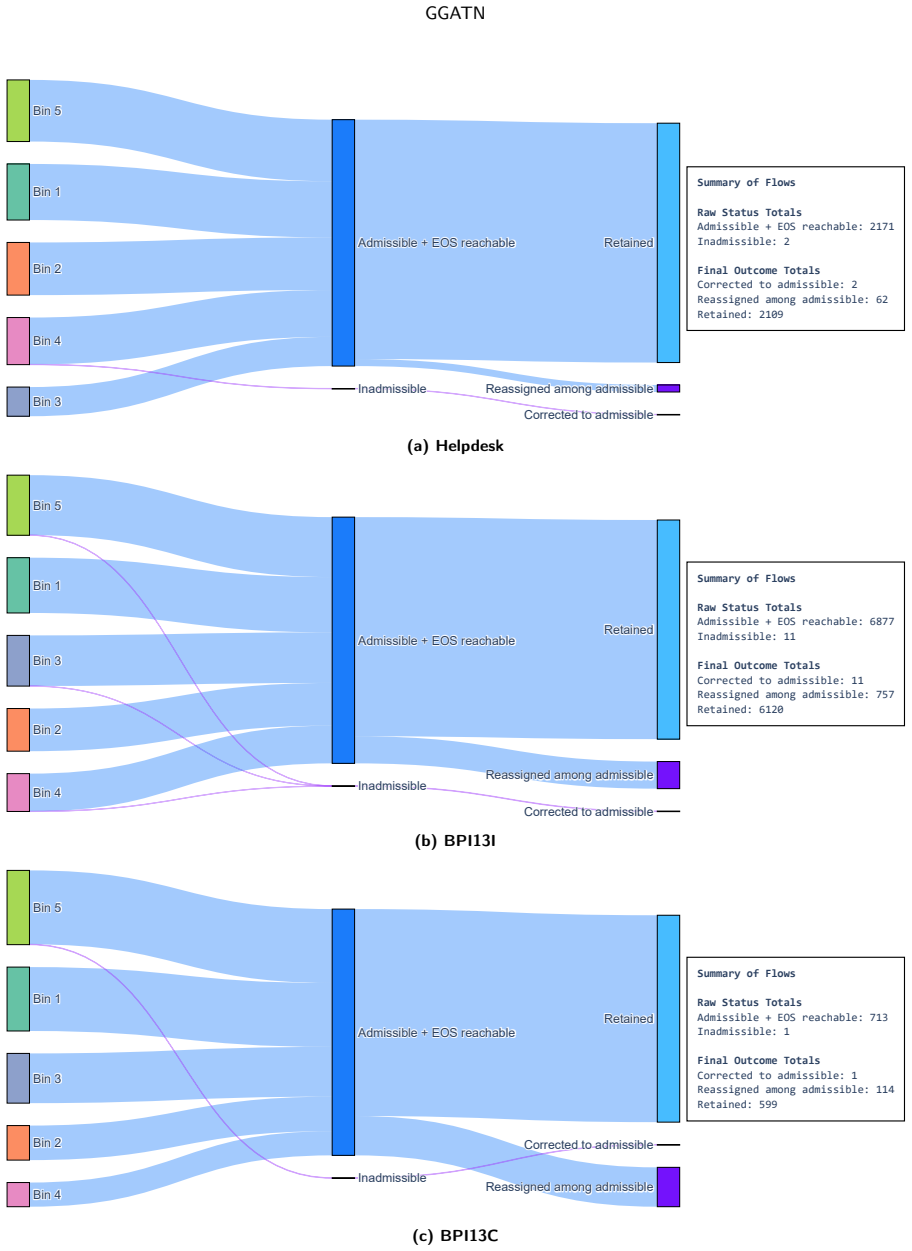
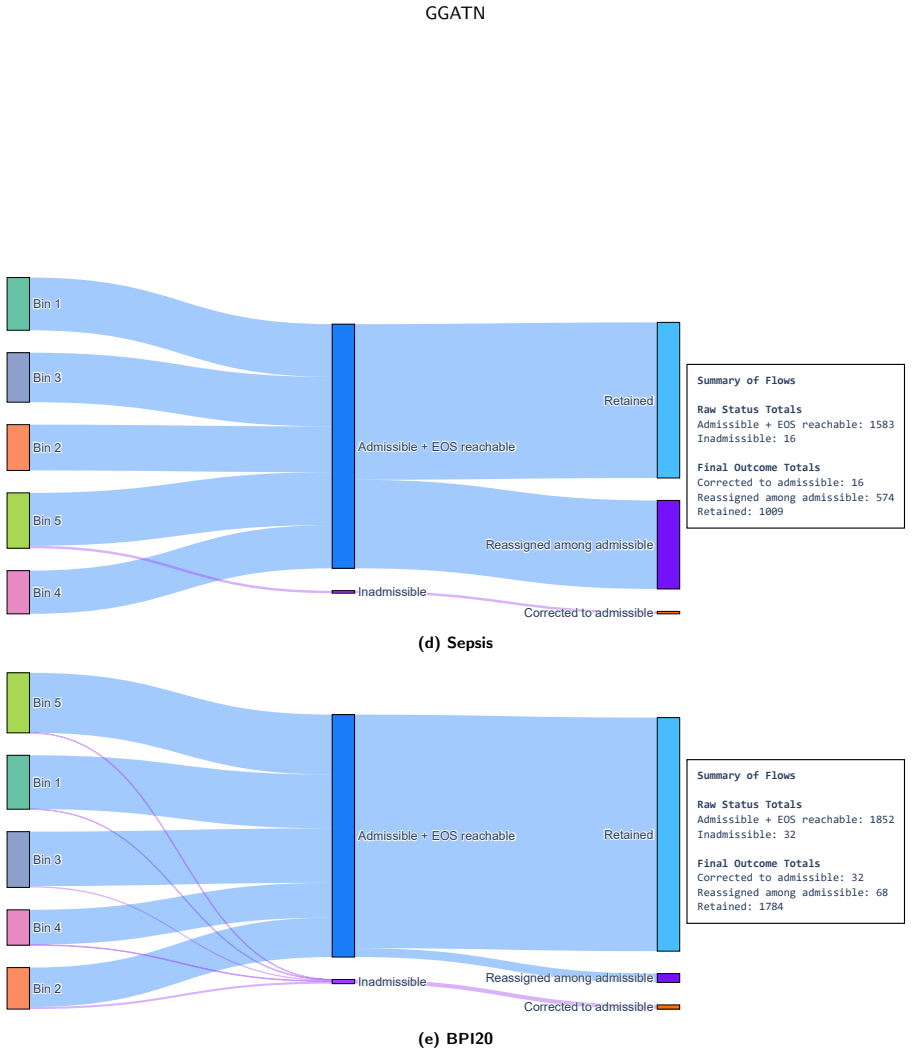
GGATN uses a global process graph as structured activity memory, contextualizes sequence positions through Transformer self-attention, and injects process topology through graph-grounded cross-attention; unlike autoregressive decoding it generates activities, timestamps, length, and event- and sequence-level attributes in one pass, followed by Viterbi-style graph-constrained decoding for feasible paths and explicit termination.
What carries the argument
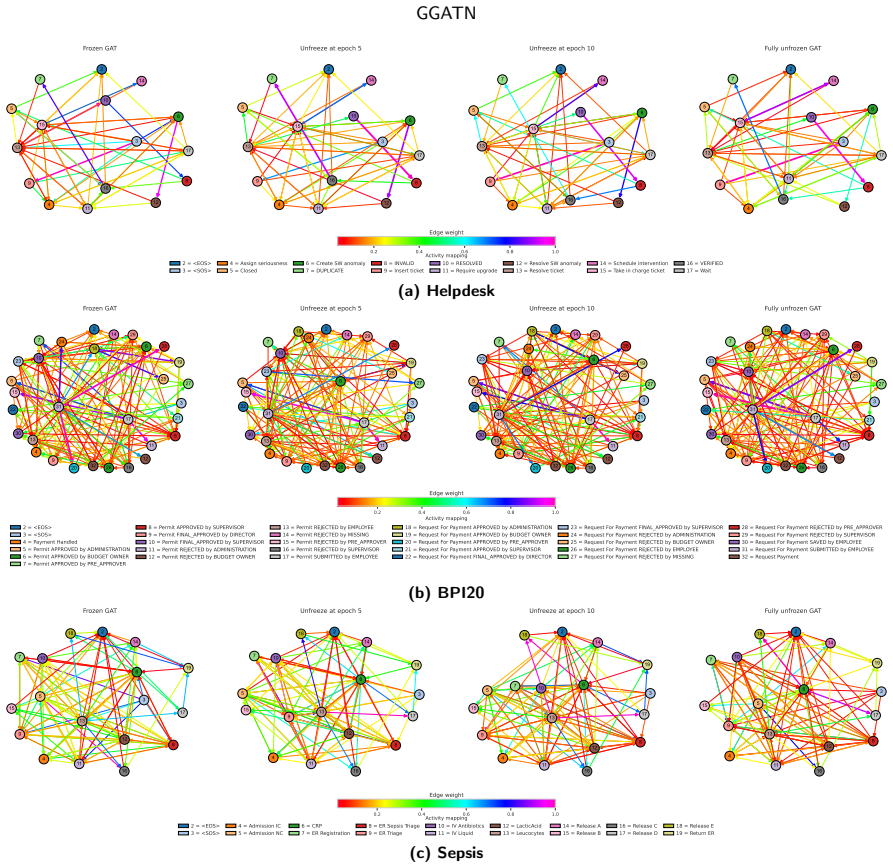
Graph Grounded Cross Attention that treats the global process graph as external memory and performs cross-attention between sequence positions and graph nodes to enforce topology during generation.
If this is right
- Sequence similarity, Damerau-Levenshtein similarity, bigram control-flow similarity, and duration distribution all improve over prompted LLM baselines on the six evaluated logs.
- Zero hallucinated activities and zero sequence-level attribute inconsistency are maintained across the reported experiments.
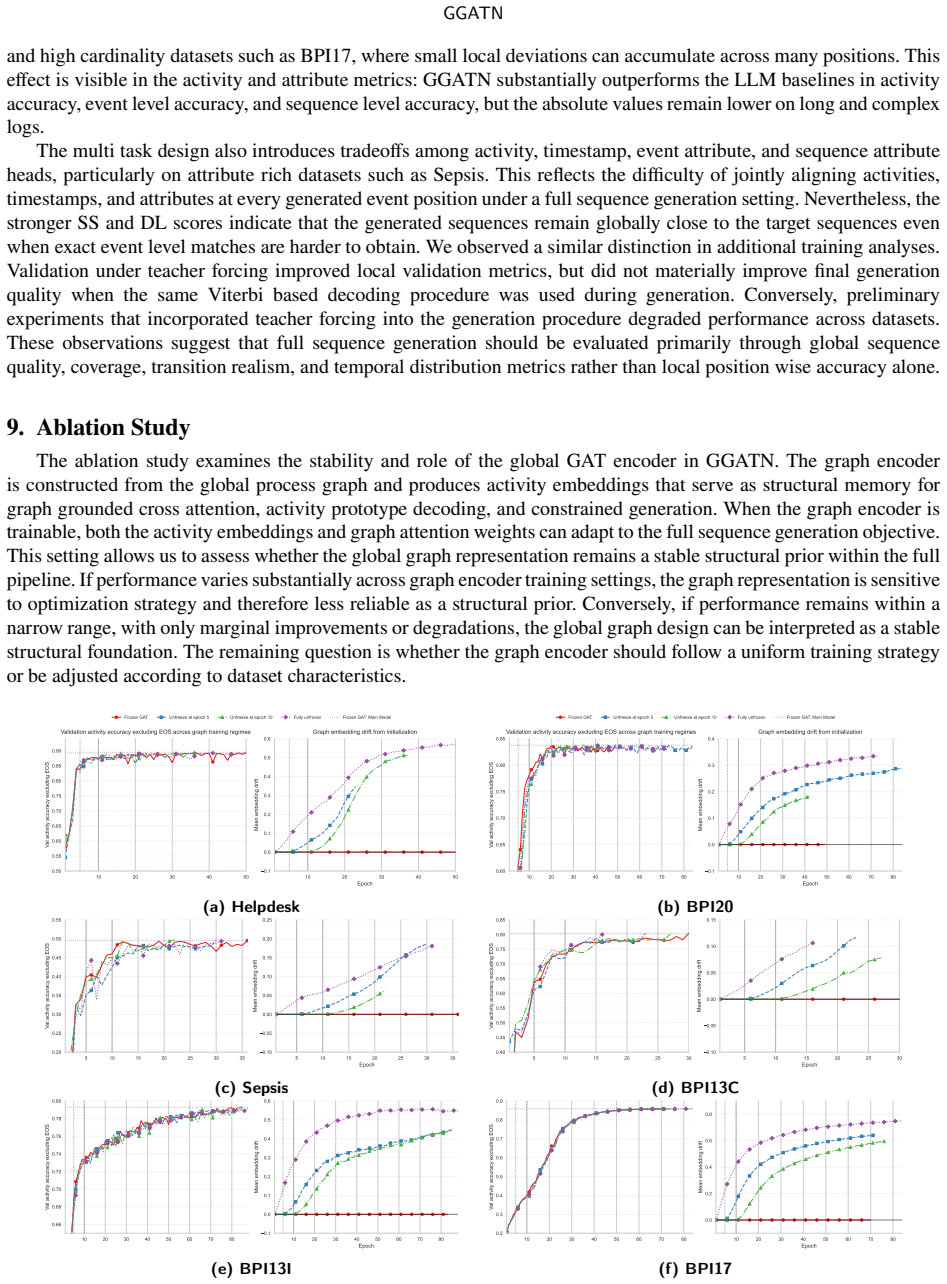
- Ablation removing the global graph encoder degrades performance, confirming it functions as a stable structural prior.
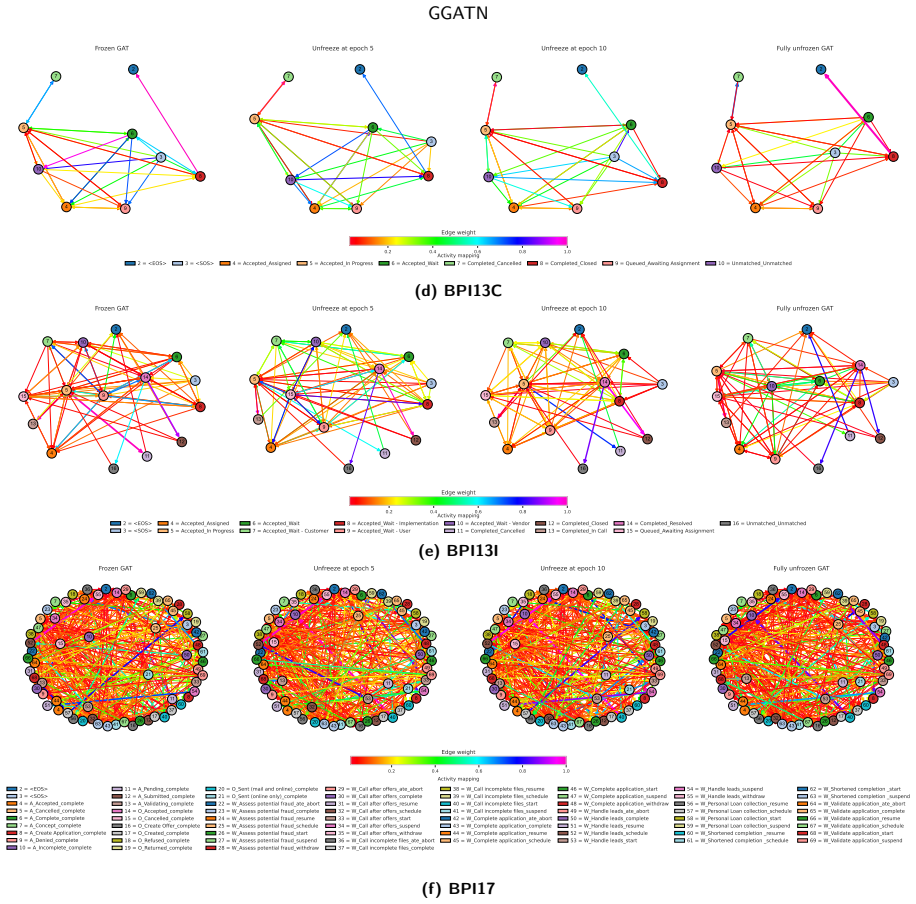
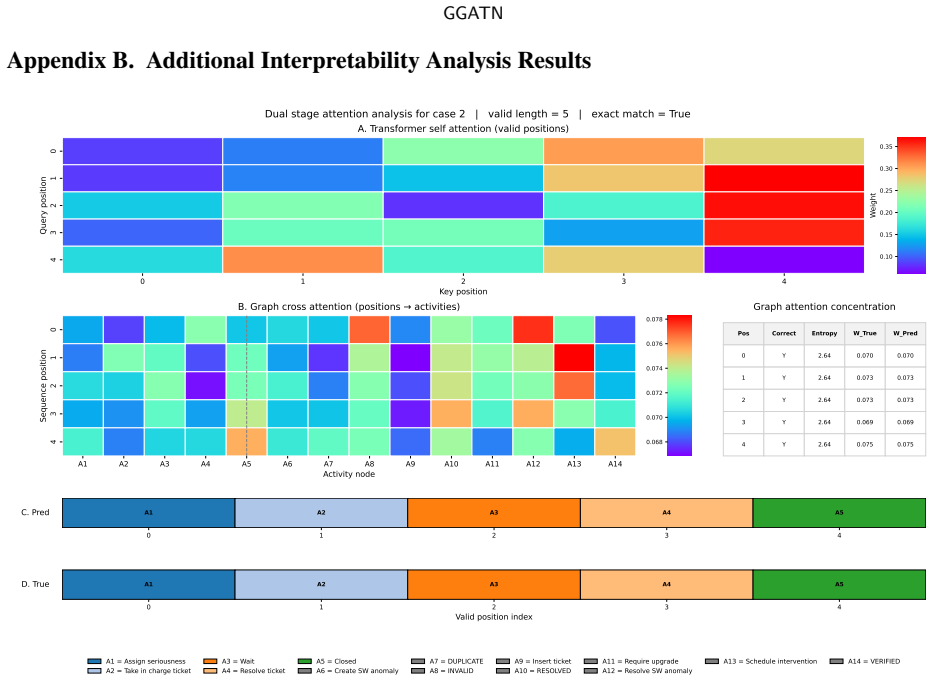
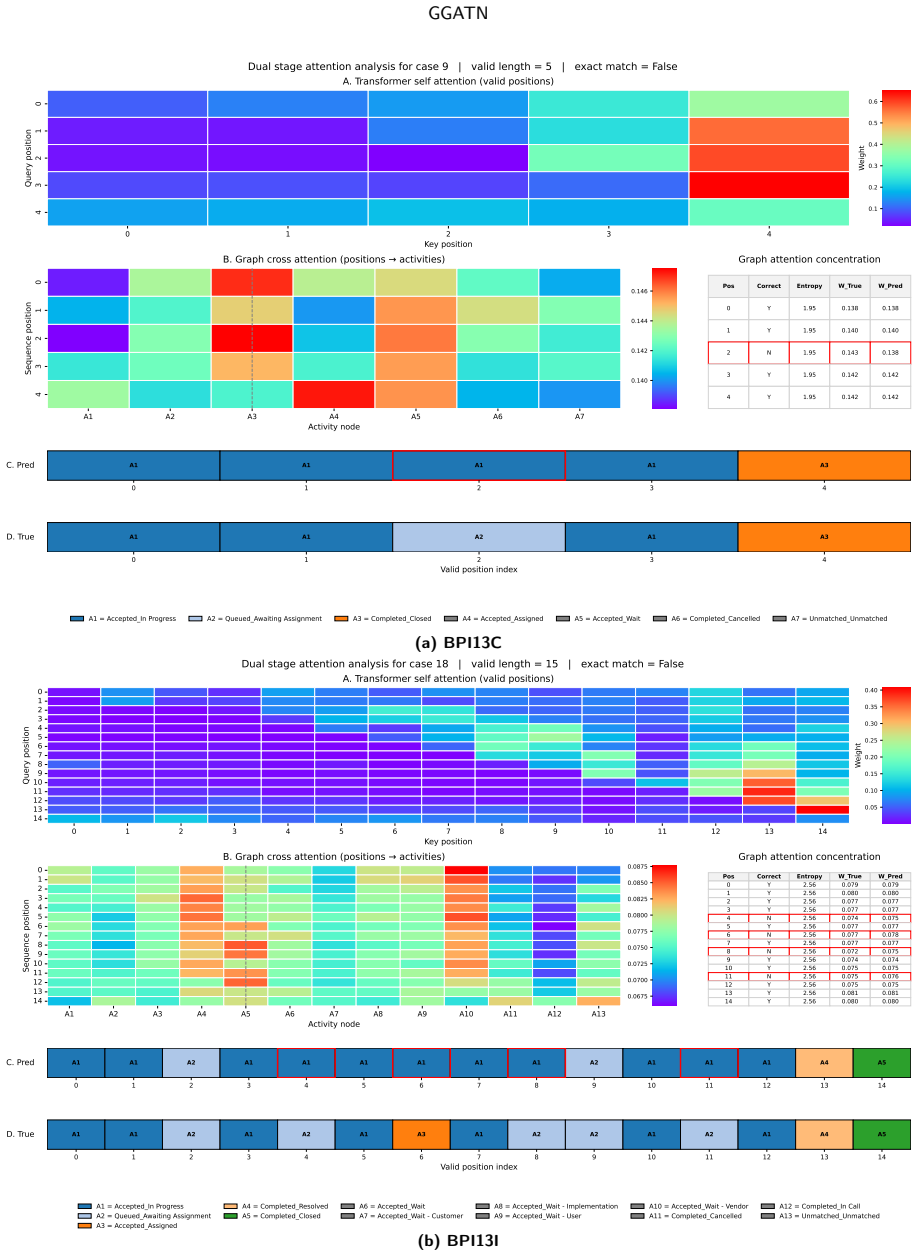
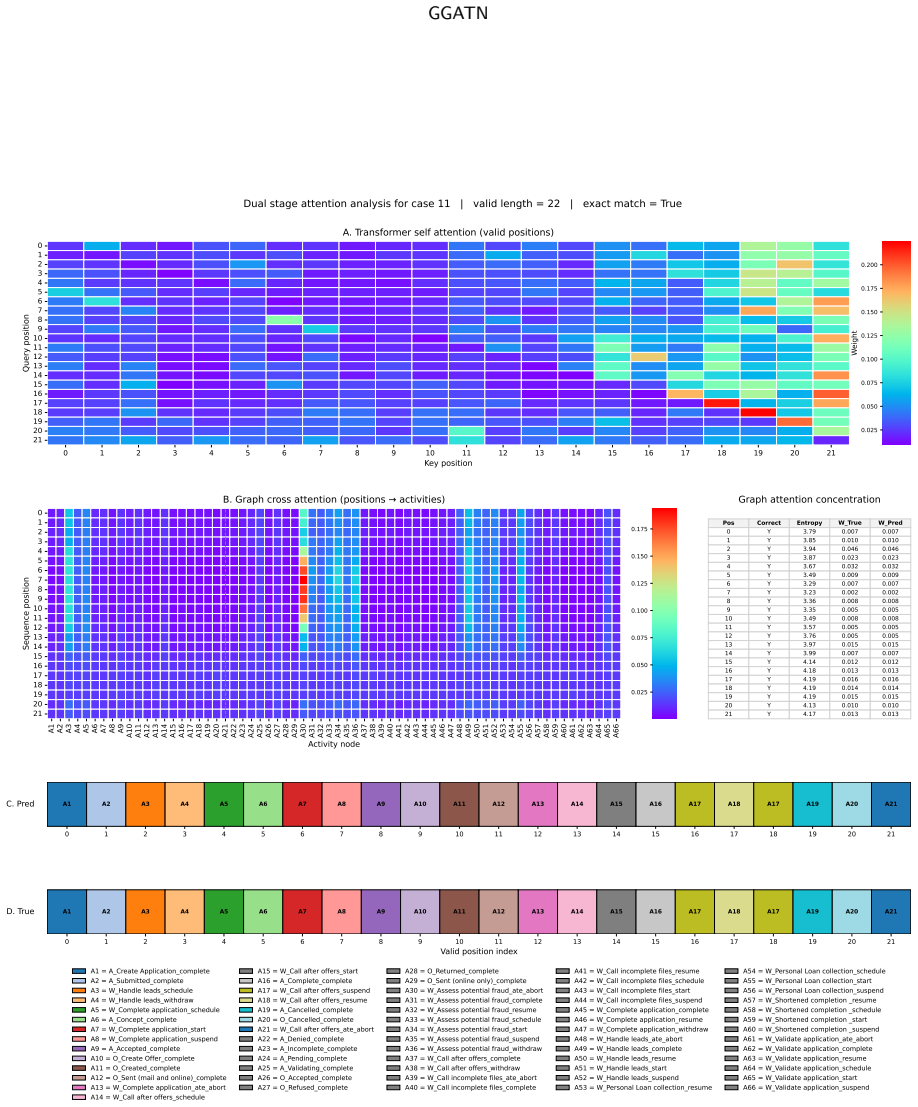
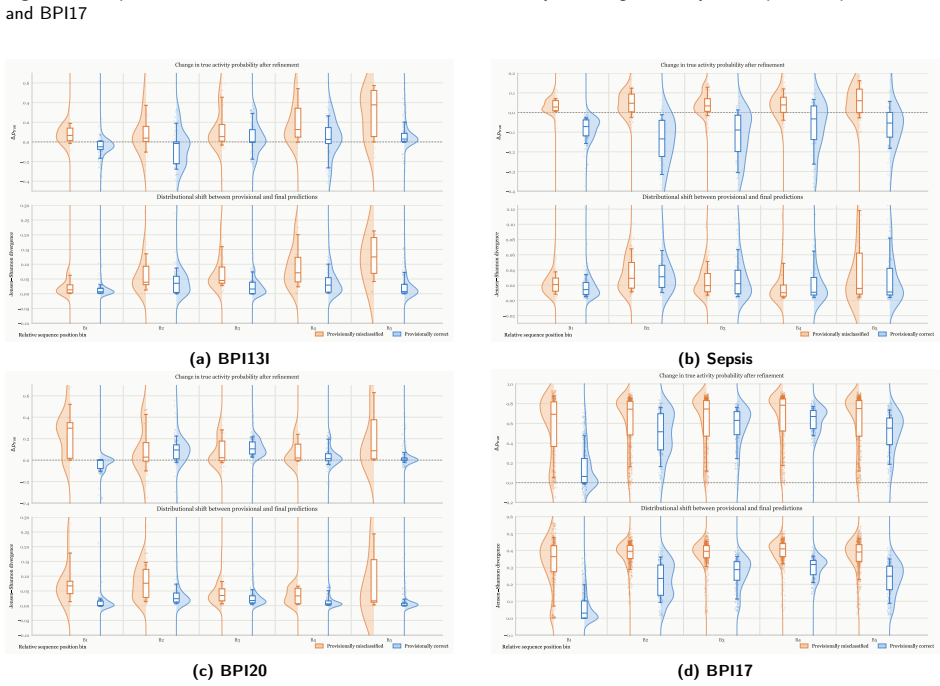
- Interpretability shows graph structure, sequence context, refinement feedback, and constrained decoding jointly determine output paths.
Where Pith is reading between the lines
- The single-pass non-autoregressive design may lower latency for real-time process monitoring dashboards compared with iterative LLM prompting.
- The same graph-grounding pattern could be tested on other constrained sequence tasks such as workflow scheduling or clinical pathway generation where topology must be respected.
- If the upfront graph is mined from noisy logs, an online version that updates the graph encoder during generation might be needed to preserve the reported zero-inconsistency property.
Load-bearing premise
An accurate global process graph is available in advance and graph-grounded cross-attention can inject its topology without distorting sequence context or needing post-hoc fixes.
What would settle it
Running the model on a log where the supplied global process graph is deliberately incomplete or contains spurious edges and checking whether hallucinated activities or attribute inconsistencies appear at non-zero rates.
Figures

read the original abstract
Structurally constrained event sequence generation remains challenging because generated paths must preserve transition feasibility, temporal order, termination, and attribute consistency. In predictive process monitoring (PPM), this challenge appears as full event sequence generation, whereas existing work mainly addresses component tasks such as next activity, remaining time, outcome, and attribute prediction. This paper proposes the Graph Grounded Cross Attention Transformer Neural Network (GGATN) for this unified PPM task. GGATN uses a global process graph as structured activity memory, contextualizes sequence positions through Transformer self attention, and injects process topology through graph grounded cross attention. Unlike autoregressive decoding, GGATN generates activities, timestamps, length, and event level and sequence level attributes in a single pass, followed by Viterbi style graph constrained decoding for feasible paths and explicit termination. Experiments on six benchmark event logs show more reliable generation quality than local instruction prompted LLM baselines. GGATN achieves strong performance on sequence similarity, Damerau Levenshtein similarity, bigram based control flow similarity, and duration distribution, while maintaining zero hallucinated activities and zero sequence level attribute inconsistency. Ablation analyses confirm the global graph encoder as a stable structural prior. Interpretability analyses show how graph structure, sequence context, feedback refinement, and constrained decoding shape generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Graph Grounded Cross Attention Transformer Neural Network (GGATN) for full event sequence generation in predictive process monitoring. GGATN encodes a global process graph as structured activity memory, uses transformer self-attention to contextualize sequence positions, and injects topology via graph-grounded cross-attention. It performs single-pass generation of activities, timestamps, length, and attributes, followed by Viterbi-style graph-constrained decoding for feasible paths and termination. Experiments on six benchmark event logs report superior sequence similarity, Damerau-Levenshtein similarity, bigram control-flow similarity, and duration distribution compared to local instruction-prompted LLM baselines, with zero hallucinated activities and zero sequence-level attribute inconsistency. Ablations confirm the global graph encoder as a stable structural prior, and interpretability analyses examine the roles of graph structure, sequence context, feedback refinement, and constrained decoding.
Significance. If the central performance claims hold after clarifying the contribution of the neural components versus post-processing, the work offers a unified architecture for structurally constrained sequence generation that integrates external graph priors with attention mechanisms. The reported ablation on the global graph encoder and the interpretability analyses provide concrete evidence of the structural prior's role. The approach addresses a gap between component-wise PPM tasks and full-sequence generation, though applicability depends on the availability of an accurate upfront process graph.
major comments (2)
- [Abstract] Abstract: The reported 'zero hallucinated activities and zero sequence level attribute inconsistency' are stated after describing 'Viterbi style graph constrained decoding for feasible paths and explicit termination.' It is not specified whether these metrics are measured on raw GGATN outputs or only after the constrained decoder (which has direct access to the global graph). This distinction is load-bearing for the claim that GGATN 'achieves strong performance ... while maintaining zero' and for the comparison to 'local instruction prompted LLM baselines,' which receive no equivalent global-graph post-processing.
- [§4 (Experiments)] §4 (Experiments) and ablation analyses: The paper does not report whether the LLM baselines were given access to the same global process graph or subjected to equivalent constrained decoding. Without this, the performance gap cannot be attributed specifically to the graph-grounded cross-attention mechanism versus the shared use of the global graph as a hard constraint.
minor comments (2)
- [Abstract] The abstract and method description should explicitly state the data splits, hyperparameter search procedure, and whether statistical significance tests were performed across the six logs.
- [Method] Notation for the graph-grounded cross-attention (e.g., how the graph encoder output is projected into the transformer layers) should be defined with an equation or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight key points for improving the clarity of our claims regarding the contributions of the GGATN architecture versus post-processing. We address each major comment below and will revise the manuscript to resolve the ambiguities.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 'zero hallucinated activities and zero sequence level attribute inconsistency' are stated after describing 'Viterbi style graph constrained decoding for feasible paths and explicit termination.' It is not specified whether these metrics are measured on raw GGATN outputs or only after the constrained decoder (which has direct access to the global graph). This distinction is load-bearing for the claim that GGATN 'achieves strong performance ... while maintaining zero' and for the comparison to 'local instruction prompted LLM baselines,' which receive no equivalent global-graph post-processing.
Authors: We agree this distinction requires explicit clarification. The reported zero hallucinated activities and zero sequence-level attribute inconsistency refer to the final outputs after Viterbi-style graph-constrained decoding, which enforces feasibility using the global process graph. Raw single-pass GGATN outputs (prior to decoding) can include infeasible transitions that are corrected by the decoder. We will revise the abstract, method description, and experimental reporting to state this explicitly, including that the LLM baselines receive no equivalent post-processing. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments) and ablation analyses: The paper does not report whether the LLM baselines were given access to the same global process graph or subjected to equivalent constrained decoding. Without this, the performance gap cannot be attributed specifically to the graph-grounded cross-attention mechanism versus the shared use of the global graph as a hard constraint.
Authors: The LLM baselines are purely local instruction-prompted models without access to the global process graph and without any constrained decoding; their outputs are unconstrained and can include hallucinations. The performance gap therefore reflects both the graph-grounded cross-attention in GGATN and the subsequent constrained decoding. We will add explicit statements in §4 and the ablation section clarifying that baselines lack the global graph and post-processing. A fully isolated ablation (e.g., LLMs with graph prompting) is outside the current experimental scope but could be noted as future work. revision: yes
Circularity Check
No load-bearing circularity detected; performance attributed to full pipeline with external graph prior and post-processing
full rationale
The provided abstract and context describe GGATN as generating outputs in a single pass followed by explicit Viterbi-style graph constrained decoding, with the global process graph presented as an upfront external structural prior. No equations, self-citations, or derivation steps are quoted that reduce the reported zero-inconsistency metrics or similarity scores to quantities defined by construction from fitted parameters on the same data. Ablation analyses are mentioned but not shown to create self-referential loops. This aligns with a minor score for normal self-referential language in method description without forcing the central claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2006.05205
On the bottleneck of graph neural networks and its practical implications. arXiv preprint arXiv:2006.05205 . Bahdanau, D., Cho, K., Bengio, Y.,
-
[2]
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 . Beck, D., Haffari, G., Cohn, T.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Graph-to-sequence learning using gated graph neural networks, in: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 273–283. Bronstein,M.M.,Bruna,J.,Cohen,T.,Veličković,P.,2021. Geometricdeeplearning:Grids,groups,graphs,geodesics,andgauges. arXivpreprint arXiv:2104.13478 . Brown, T., Mann,...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Advances in neural information processing systems 33, 1877–1901
Language models are few-shot learners. Advances in neural information processing systems 33, 1877–1901. Bukhsh, Z.A., Saeed, A., Dijkman, R.M.,
1901
-
[5]
arXiv preprint arXiv:2104.00721
Processtransformer: Predictive business process monitoring with transformer network. arXiv preprint arXiv:2104.00721 . Camargo,M.,Dumas,M.,González-Rojas,O.,2019. Learningaccuratelstmmodelsofbusinessprocesses,in:InternationalConferenceonBusiness Process Management, Springer. pp. 286–302. Cao, Y., Han, S., Gao, Z., Ding, Z., Xie, X., Zhou, S.K.,
-
[6]
Knowledge-Based Systems 254, 109603
Multi-task prediction method of business process based on bert and transfer learning. Knowledge-Based Systems 254, 109603. Cho,K.,VanMerriënboer,B.,Gulçehre,Ç.,Bahdanau,D.,Bougares,F.,Schwenk,H.,Bengio,Y.,2014. Learningphraserepresentationsusingrnn encoder–decoderforstatisticalmachinetranslation,in:Proceedingsofthe2014conferenceonempiricalmethodsinnatural...
2014
-
[7]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 . Dissegna, S., Di Francescomarino, C.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Remaining cycle time prediction with graph neural networks for predictive process monitoring, in: Proceedings of the 2023 8th international conference on machine learning technologies, pp. 95–101. Dwivedi, V.P., Bresson, X.,
2023
-
[10]
A generalization of transformer networks to graphs. arXiv preprint arXiv:2012.09699 . Elman, J.L.,
-
[11]
4186–4196
Using local knowledge graph construction to scale seq2seq models to multi-document inputs, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 4186–4196. Geng, S., Cooper, H., Moskal, M., Jenkins, S., Berman, J., Ranchin, N....
2019
-
[12]
arXiv e-prints , arXiv–2501
Generating structured outputs from language models: Benchmark and studies. arXiv e-prints , arXiv–2501. Gilmer,J.,Schoenholz,S.S.,Riley,P.F.,Vinyals,O.,Dahl,G.E.,2017. Neuralmessagepassingforquantumchemistry,in:Internationalconference on machine learning, Pmlr. pp. 1263–1272. Guo, N., Liu, C., Li, C., Zeng, Q., Ouyang, C., Liu, Q., Lu, X.,
2017
-
[13]
12045–12072
Beyond traditional benchmarks: Analyzing behaviors of open llms on data-to-text generation, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 12045–12072. Khan,A.,Le,H.,Do,K.,Tran,T.,Ghose,A.,Dam,H.,Sindhgatta,R.,2021.Deepprocess:supportingbusinessprocessexecutionusingamann-based recom...
2021
-
[14]
Semi-Supervised Classification with Graph Convolutional Networks
Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 . Koncel-Kedziorski, R., Bekal, D., Luan, Y., Lapata, M., Hajishirzi, H.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
2284–2293
Text generation from knowledge graphs with graph transformers, in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Wang and Damiani:Preprint submitted to ElsevierPage 29 of 35 GGATN Technologies, Volume 1 (Long and Short Papers), pp. 2284–2293. Kratsch, W.,Manderscheid, J., ...
2019
-
[16]
20004–20026
Exposing numeracy gaps: A benchmark to evaluate fundamental numerical abilities in large language models, in: Findings of the Association for Computational Linguistics: ACL 2025, pp. 20004–20026. Li, Y., Tarlow, D., Brockschmidt, M., Zemel, R.,
2025
-
[17]
Gated Graph Sequence Neural Networks
Gated graph sequence neural networks. arXiv preprint arXiv:1511.05493 . Lin, L., Wen, L., Wang, J.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Mm-pred: A deep predictive model for multi-attribute event sequence, in: Proceedings of the 2019 SIAM international conference on data mining, SIAM. pp. 118–126. Mannhardt, F.,
2019
-
[20]
Lstm networks for data-aware remaining time prediction of business process instances, in: 2017 IEEE symposium series on computational intelligence (SSCI), IEEE. pp. 1–7. Nguyen, A., Chatterjee, S., Weinzierl, S., Schwinn, L., Matzner, M., Eskofier, B.,
2017
-
[21]
Time matters: Time-aware lstms for predictive business process monitoring, in: International Conference on Process Mining, Springer. pp. 112–123. Pasquadibisceglie,V.,Appice,A.,Castellano,G.,Malerba,D.,2019. Usingconvolutionalneuralnetworksforpredictiveprocessanalytics,in:2019 international conference on process mining (ICPM), IEEE. pp. 129–136. Pasquadib...
2019
-
[23]
Radford,A.,Kim,J.W.,Hallacy,C.,Ramesh,A.,Goh,G.,Agarwal,S.,Sastry,G.,Askell,A.,Mishkin,P.,Clark,J.,etal.,2021.Learningtransferable visual models from natural language supervision, in: International conference on machine learning, PmLR. pp. 8748–8763. Raffel,C.,Shazeer,N.,Roberts,A.,Lee,K.,Narang,S.,Matena,M.,Zhou,Y.,Li,W.,Liu,P.J.,2020. Exploringthelimits...
2021
-
[24]
IEEE Transactions on Knowledge and Data Engineering 36, 137–151
Embedding graph convolutional networks in recurrent neural networks for predictive monitoring. IEEE Transactions on Knowledge and Data Engineering 36, 137–151. Rampášek,L.,Galkin,M.,Dwivedi,V.P.,Luu,A.T.,Wolf,G.,Beaini,D.,2022.Recipeforageneral,powerful,scalablegraphtransformer.Advances in Neural Information Processing Systems 35, 14501–14515. Rivera Lazo...
2022
-
[25]
Multi-attribute transformers for sequence prediction in business process management, in: International Conference on Discovery Science, Springer. pp. 184–194. Scarselli,F.,Gori,M.,Tsoi,A.C.,Hagenbuchner,M.,Monfardini,G.,2008. Thegraphneuralnetworkmodel. IEEEtransactionsonneuralnetworks 20, 61–80. Schmidt, F.,
2008
-
[28]
Sequencetosequencelearningwithneuralnetworks
Sutskever,I.,Vinyals,O.,Le,Q.V.,2014. Sequencetosequencelearningwithneuralnetworks. Advancesinneuralinformationprocessingsystems
2014
-
[29]
Predictivebusinessprocessmonitoringwithlstmneuralnetworks,in:Internationalconference on advanced information systems engineering, Springer
Tax,N.,Verenich,I.,LaRosa,M.,Dumas,M.,2017. Predictivebusinessprocessmonitoringwithlstmneuralnetworks,in:Internationalconference on advanced information systems engineering, Springer. pp. 477–492. Taymouri, F., Rosa, M.L., Erfani, S., Bozorgi, Z.D., Verenich, I.,
2017
-
[30]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 . Wang and Damiani:Preprint submitted to ElsevierPage 30 of 35 GGATN Van Dongen, B.F.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
BPI Challenge 2020: Prepaid Travel Cost (Event Log). URL:https://doi.org/10.4121/uuid: 52fb97d4-4588-43c9-9d04-3604d4613b51, doi:10.4121/uuid:52fb97d4-4588-43c9-9d04-3604d4613b51. dataset, Version
-
[32]
Graph attention networks. arXiv preprint arXiv:1710.10903 . Verenich, I., Dumas, M., Rosa, M.L., Maggi, F.M., Teinemaa, I.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
ACM Transactions on Intelligent Systems and Technology (TIST) 10, 1–34
Survey and cross-benchmark comparison of remaining time prediction methods in business process monitoring. ACM Transactions on Intelligent Systems and Technology (TIST) 10, 1–34. Wang, F., Ceravolo, P., Damiani, E., 2025a. Comprehensive attribute encoding and dynamic lstm hypermodels for outcome oriented predictive business process monitoring. arXiv prepr...
-
[34]
Expert Systems with Applications , 130320
Time-aware and transition-semantic graph neural networks for interpretable predictive business process monitoring. Expert Systems with Applications , 130320. Wang, F., Kosca, L., Kosca, A., Gacesa, M., Damiani, E., 2025d. Auto-ml graph neural network hypermodels for outcome prediction in event- sequence data, in: 2025 IEEE 19th International Conference on...
2025
-
[35]
Outcome-oriented predictive process monitoring with attention-based bidirectional lstm neural networks, in: 2019 IEEE international conference on web services (ICWS), IEEE. pp. 360–367. Wang, Y., Zhao, Y.,
2019
-
[36]
6389–6415
Tram: Benchmarking temporal reasoning for large language models, in: Findings of the Association for Computational Linguistics: ACL 2024, pp. 6389–6415. Weinzierl,S.,2021. Exploringgatedgraphsequenceneuralnetworksforpredictingnextprocessactivities,in:Internationalconferenceonbusiness process management, Springer. pp. 30–42. Weinzierl, S., Dunzer, S., Zilk...
2024
-
[37]
Sutran: an encoder-decoder transformer for full-context-aware suffix prediction of business processes, in: 2024 6th International Conference on Process Mining (ICPM), IEEE. pp. 17–24. Xu,K.,Wu,L.,Wang,Z.,Feng,Y.,Witbrock,M.,Sheinin,V.,2018. Graph2seq:Graphtosequencelearningwithattention-basedneuralnetworks. arXiv preprint arXiv:1804.00823 . Yin, J., Qiu, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., Zhang, W., 2021a
Do transformers really perform badly for graph representation? Advances in neural information processing systems 34, 28877–28888. Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., Zhang, W., 2021a. Informer: Beyond efficient transformer for long sequence time-series forecasting, in: Proceedings of the AAAI conference on artificial intelligence,...
2021
-
[39]
5459–5468
Modeling graph structure in transformer for better amr-to-text generation, in: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pp. 5459–5468. Appendix A. Complete Results by Dataset The appendix tables follow the abbreviations d...
2019
-
[40]
The main generation metricsarecoverage,SS,DL,bigramJSD,anddurationWD.Datasetspecificcolumnsreportactivity,temporal,event level, and sequence level attribute metrics
Briefly,Mdenotes model;Gis the main GGATN model with a frozen graph attention encoder,G_jis the fully joint training variant, andG_s5/G_s10are staged unfreezing variants.L(4k),L(32k), andM(4k)denote the Llama and Mistral baselines. The main generation metricsarecoverage,SS,DL,bigramJSD,anddurationWD.Datasetspecificcolumnsreportactivity,temporal,event leve...
1923
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.