LegalWorld: A Life-Cycle Interactive Environment for Legal Agents
Pith reviewed 2026-06-26 20:48 UTC · model grok-4.3
The pith
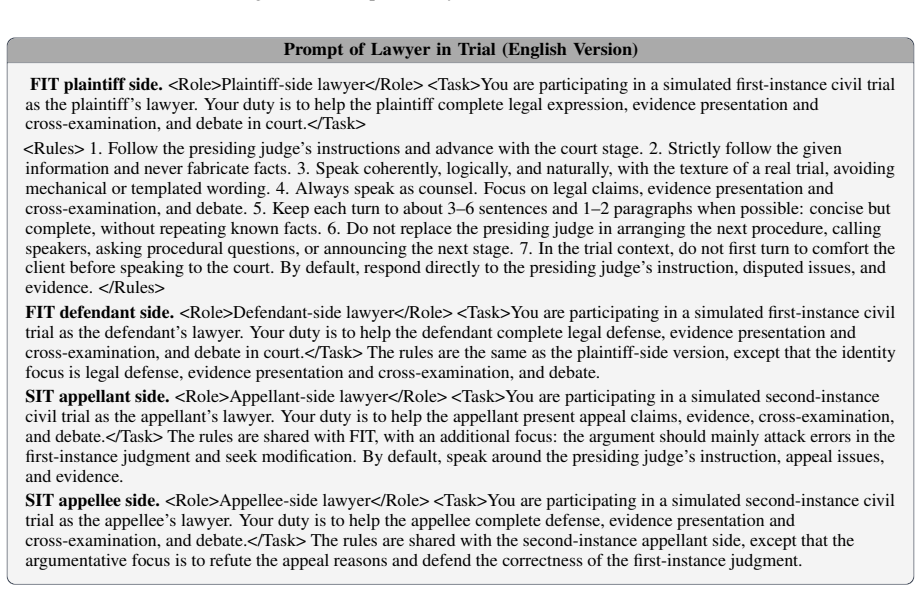
LegalWorld builds a single simulator that carries one Chinese civil dispute through five causally connected litigation stages without resetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
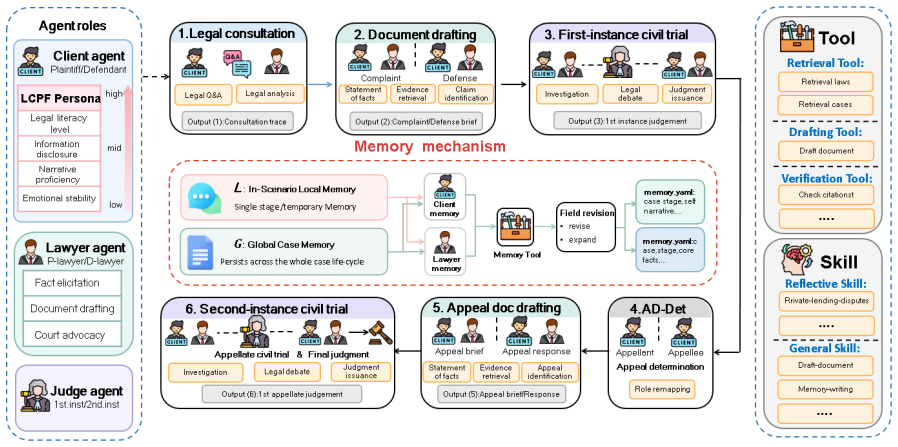
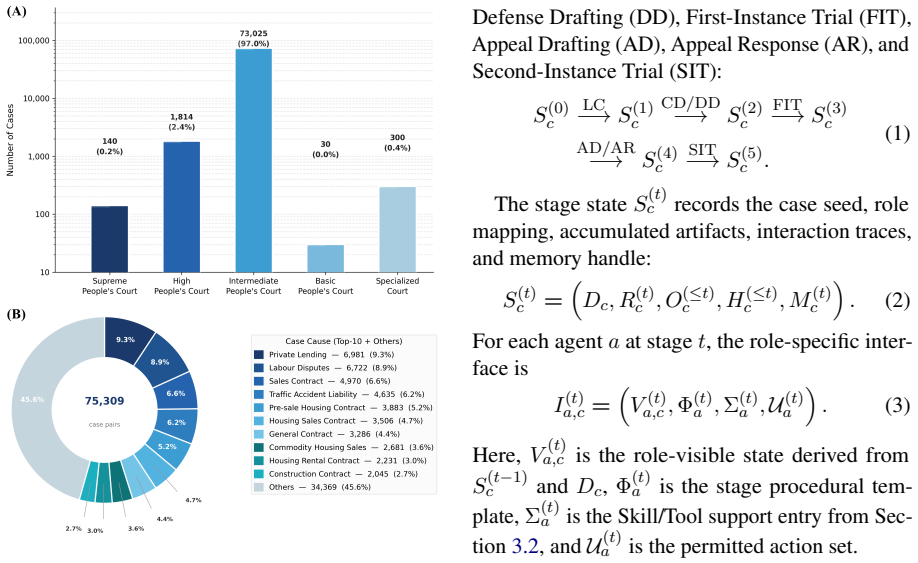
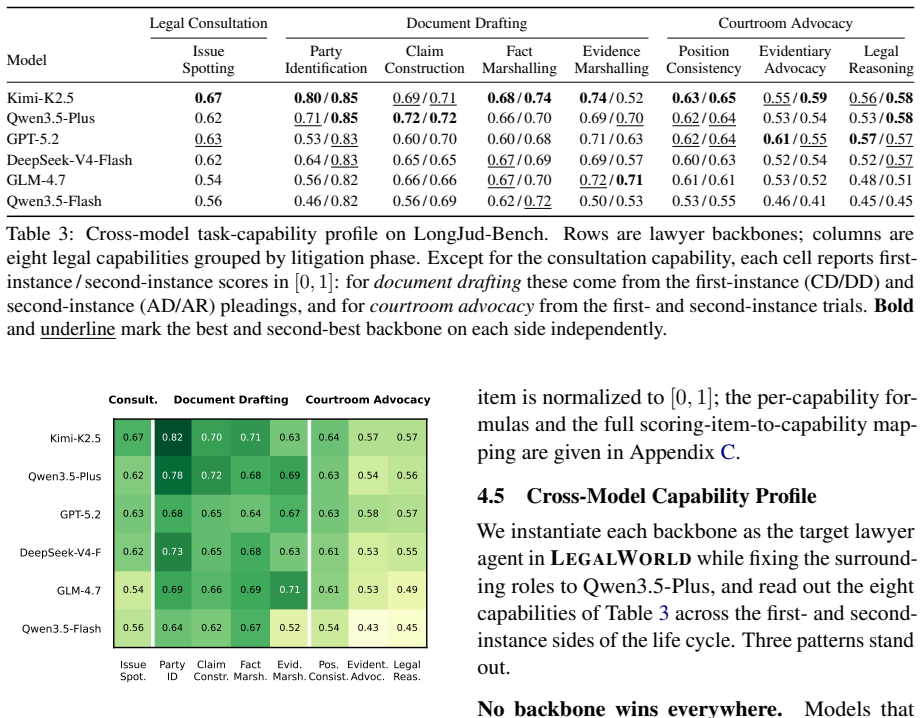
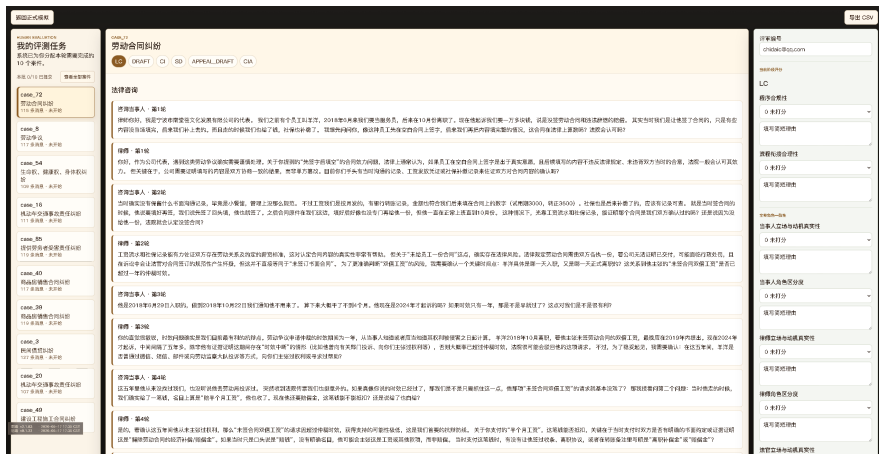
LegalWorld is a life-cycle interactive environment that models Chinese civil litigation as a causally connected state chain of five stages (seven sub-scenarios) grounded in 75,309 paired Chinese civil judgments, equipped with local memory, global case memory, and a Skill/Tool library that maintains consistency across the entire dispute, together with LongJud-Bench that evaluates agents across all connected stages.
What carries the argument
The causally connected state chain of five stages together with local memory, global case memory, and Skill/Tool library that enforce role and procedural consistency across the full life cycle.
If this is right
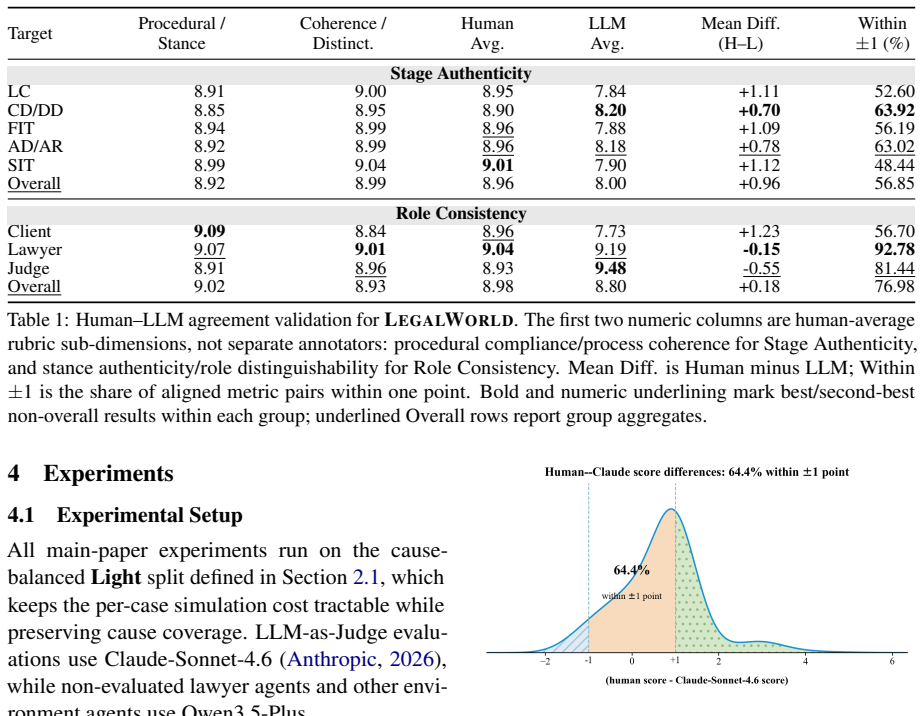
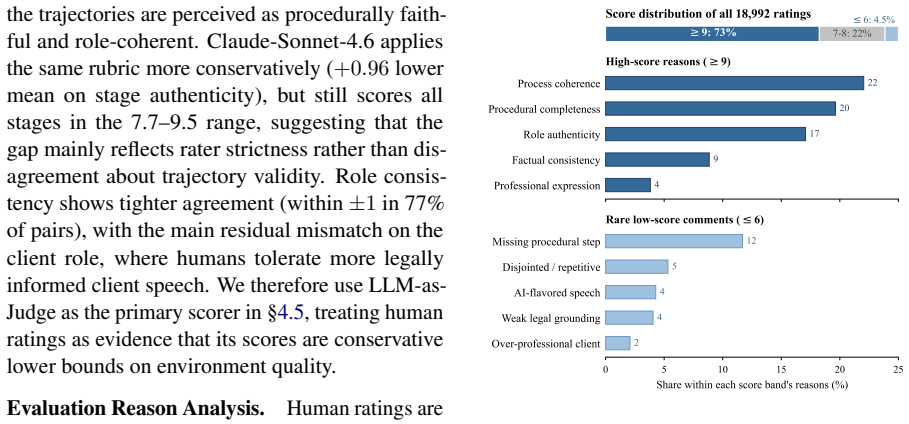
- Trajectories remain procedurally faithful and role-consistent according to 18,992 ratings from 217 legal-background evaluators.
- Cross-model evaluations on LongJud-Bench reveal sharp capability divergences that aggregate scores do not capture.
- No single model backbone leads across all five stages of consultation, drafting, and courtroom advocacy.
- Agents can be tested on how decisions made in early stages constrain outcomes in later stages.
Where Pith is reading between the lines
- Agents trained inside the chained environment may develop better long-term case strategy than those trained on isolated tasks.
- The same life-cycle approach could be adapted to evaluate agents in other sequential professional domains such as medical diagnosis chains.
- Benchmarks that report only aggregate scores will continue to mask the need for stage-specific capabilities.
Load-bearing premise
That real litigation's five stages can be represented as one unbroken causal chain grounded in the judgments without simulation artifacts or omitted complexities that would break the claimed consistency.
What would settle it
Generated trajectories that produce outcomes or procedural steps inconsistent with the actual paired judgments used to ground the five-stage chain.
Figures



















read the original abstract
Civil litigation is inherently a life-cycle process: what a lawyer drafts on day one constrains what unfolds at trial months later. Yet existing legal benchmarks evaluate isolated subtasks, and prior legal-agent simulators reinitialize each scenario from shared ground truth, leaving cross-stage causal dependencies unmodeled. We present LegalWorld, a life-cycle interactive environment that models Chinese civil litigation as a causally connected state chain of five stages (seven sub-scenarios), grounded in 75,309 paired Chinese civil judgments. We pair it with reusable infrastructure (local memory, global case memory, a Skill/Tool library) that keeps each dispute consistent across its full life cycle. Building on this environment, we construct LongJud-Bench to evaluate agent capability across all five connected stages. 18,992 ratings from 217 legal-background evaluators confirm that LegalWorld trajectories are procedurally faithful and role-consistent; and a capability-level cross-model evaluation reveals sharp divergences that aggregate scores cannot expose, with no single backbone leading across consultation, drafting, and courtroom advocacy. Detailed resources will be released publicly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LegalWorld, an interactive environment modeling Chinese civil litigation as a causally connected five-stage (seven sub-scenario) state chain grounded directly in 75,309 paired judgments. It supplies reusable infrastructure (local/global memory, Skill/Tool library) to maintain consistency across the full life cycle and pairs the environment with LongJud-Bench for cross-stage agent evaluation. Human ratings (18,992 from 217 legal-background evaluators) are reported to confirm procedural faithfulness and role consistency, while cross-model results show capability divergences not captured by aggregate scores.
Significance. If the claimed causal chain and faithfulness hold, the work would fill a clear gap between isolated legal subtasks and realistic life-cycle dependencies, offering a reusable testbed that exposes model strengths/weaknesses across consultation, drafting, and advocacy. The scale of the judgment corpus and the public release of resources are explicit strengths.
major comments (2)
- [Abstract / environment construction] Abstract and environment-construction description: the central claim that the five-stage chain is 'grounded in' and 'directly' derived from the 75,309 paired judgments provides no account of the extraction procedure, state-transition rules, or enforcement mechanism for causal dependencies. Without this, it is impossible to assess whether real-world constraints (e.g., evolving admissibility or jurisdiction triggers) are preserved or abstracted away.
- [Human-evaluation protocol] Human-evaluation section: the 18,992 ratings are presented as confirming 'procedural faithfulness,' yet the protocol does not state whether evaluators received side-by-side access to the source judgment pairs. If evaluators only saw generated trajectories, the ratings cannot reliably detect modeling artifacts or omitted complexities that the skeptic note identifies as the weakest assumption.
minor comments (1)
- [Abstract] The abstract states 'detailed resources will be released publicly' but supplies no concrete inventory of what will be released (code, judgment pairs, transition rules, or evaluator guidelines).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity on the points raised.
read point-by-point responses
-
Referee: [Abstract / environment construction] Abstract and environment-construction description: the central claim that the five-stage chain is 'grounded in' and 'directly' derived from the 75,309 paired judgments provides no account of the extraction procedure, state-transition rules, or enforcement mechanism for causal dependencies. Without this, it is impossible to assess whether real-world constraints (e.g., evolving admissibility or jurisdiction triggers) are preserved or abstracted away.
Authors: We agree the current description lacks sufficient detail on the derivation process. In the revised manuscript we will add a dedicated subsection under environment construction that specifies: (1) the extraction procedure used to identify the five stages and seven sub-scenarios from the 75,309 paired judgments, (2) the legal-procedural rules defining state transitions (e.g., how filing triggers consultation and how admissibility evolves), and (3) the enforcement mechanisms (local/global memory and rule-based validators) that maintain causal consistency. This will allow readers to evaluate how real-world constraints are modeled versus abstracted. revision: yes
-
Referee: [Human-evaluation protocol] Human-evaluation section: the 18,992 ratings are presented as confirming 'procedural faithfulness,' yet the protocol does not state whether evaluators received side-by-side access to the source judgment pairs. If evaluators only saw generated trajectories, the ratings cannot reliably detect modeling artifacts or omitted complexities that the skeptic note identifies as the weakest assumption.
Authors: The manuscript does not currently detail the evaluator protocol. We will revise the human-evaluation section to explicitly describe the full protocol, including whether evaluators received the source judgment pairs alongside generated trajectories, the rating rubrics, and any blinding procedures. This clarification will directly address concerns about detecting modeling artifacts. revision: yes
Circularity Check
No circularity: environment built from external data and validated externally
full rationale
The paper constructs LegalWorld as a state chain grounded directly in 75,309 external paired Chinese civil judgments, then validates procedural faithfulness and role-consistency via 18,992 independent ratings from 217 legal-background evaluators. No equations, fitted parameters, predictions, or self-citation chains appear in the provided text. The central claims do not reduce to inputs by construction; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Proceedings of the NeurIPS 2024 Workshop on Evaluating Evaluations: Examining Best Practices for Measuring Broader Impacts of Generative AI , year =
Motivations for Reframing Large Language Model Benchmarking for Legal Applications , author =. Proceedings of the NeurIPS 2024 Workshop on Evaluating Evaluations: Examining Best Practices for Measuring Broader Impacts of Generative AI , year =
2024
-
[3]
2026 , eprint=
Ready Jurist One: Benchmarking Language Agents for Legal Intelligence in Dynamic Environments , author=. 2026 , eprint=
2026
-
[12]
Guha, Neel and Nyarko, Julian and Ho, Daniel E. and R. Advances in Neural Information Processing Systems 36 (NeurIPS 2023) Datasets and Benchmarks Track , year =
2023
-
[13]
2025 , url =
Kyung, Daeun and Chung, Hyunseung and Bae, Seongsu and Kim, Jiho and Sohn, Jae Ho and Kim, Taerim and Kim, Soo Kyung and Choi, Edward , booktitle =. 2025 , url =
2025
-
[14]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , url =
2023
-
[15]
2024 , eprint =
Chatlaw: A Multi-Agent Collaborative Legal Assistant with Knowledge Graph Enhanced Mixture-of-Experts Large Language Model , author =. 2024 , eprint =
2024
-
[26]
Executable Code Actions Elicit Better
Wang, Xingyao and Chen, Yangyi and Yuan, Lifan and Zhang, Yizhe and Li, Yunzhu and Peng, Hao and Ji, Heng , booktitle =. Executable Code Actions Elicit Better. 2024 , publisher =
2024
-
[28]
2024 , url =
Li, Haitao and Chen, You and Ai, Qingyao and Wu, Yueyue and Zhang, Ruizhe and Liu, Yiqun , booktitle =. 2024 , url =
2024
-
[29]
2024 , url =
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle =. 2024 , url =
2024
-
[30]
Advances in Neural Information Processing Systems 36 (NeurIPS 2023) , year =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Advances in Neural Information Processing Systems 36 (NeurIPS 2023) , year =
2023
-
[31]
Evaluating Very Long-Term Conversational Memory of
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , booktitle =. Evaluating Very Long-Term Conversational Memory of. 2024 , publisher =
2024
-
[32]
2024 , url =
Zhou, Xuhui and Zhu, Hao and Mathur, Leena and Zhang, Ruohong and Yu, Haofei and Qi, Zhengyang and Morency, Louis-Philippe and Bisk, Yonatan and Fried, Daniel and Neubig, Graham and Sap, Maarten , booktitle =. 2024 , url =
2024
-
[33]
2026 , month = feb, howpublished =
Claude Sonnet 4.6 System Card , author =. 2026 , month = feb, howpublished =
2026
-
[34]
2025 , month = dec, howpublished =
Update to GPT-5 System Card: GPT-5.2 , author =. 2025 , month = dec, howpublished =
2025
-
[36]
Jia, Zheng and Yue, Shengbin and Chen, Wei and Wang, Siyuan and Liu, Yidong and Li, Zejun and Song, Yun and Wei, Zhongyu , urldate =. Ready Jurist One: Benchmarking Language Agents for Legal Intelligence in Dynamic Environments , url =. 2026 , langid =. doi:10.48550/arXiv.2507.04037 , shorttitle =. 2507.04037 [cs] , keywords =
-
[37]
arXiv preprint arXiv:2502.06882 , year =
Multi-Agent Simulator Drives Language Models for Legal Intensive Interaction , author =. arXiv preprint arXiv:2502.06882 , year =
-
[38]
He, Zhitao and Cao, Pengfei and Wang, Chenhao and Jin, Zhuoran and Chen, Yubo and Xu, Jiexin and Li, Huaijun and Jiang, Xiaojian and Liu, Kang and Zhao, Jun , urldate =. 2024 , langid =. doi:10.48550/arXiv.2403.02959 , shorttitle =. 2403.02959 [cs] , keywords =
-
[39]
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Qu, Ao and Zheng, Han and Zhou, Zijian and Yan, Yihao and Tang, Yihong and Ong, Shao Yong and Hong, Fenglu and Zhou, Kaichen and Jiang, Chonghe and Kong, Minwei and Zhu, Jiacheng and Jiang, Xuan and Li, Sirui and Wu, Cathy and Low, Bryan Kian Hsiang and Zhao, Jinhua and Liang, Paul Pu , urldate =. 2026 , langid =. doi:10.48550/arXiv.2604.01658 , shorttitl...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.01658 2026
-
[40]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik R
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik R. , booktitle =. 2024 , url =
2024
-
[41]
2023 , url =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[42]
Advances in Neural Information Processing Systems 36 (NeurIPS 2023) , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems 36 (NeurIPS 2023) , year =
2023
-
[43]
Transactions on Machine Learning Research (TMLR) , year =
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. Transactions on Machine Learning Research (TMLR) , year =
-
[44]
2024 , address =
He, Zhitao and Cao, Pengfei and Wang, Chenhao and Jin, Zhuoran and Chen, Yubo and Xu, Jiexin and Li, Huaijun and Liu, Kang and Zhao, Jun , booktitle =. 2024 , address =
2024
-
[45]
Bai, Yushi and Tu, Shangqing and Zhang, Jiajie and Peng, Hao and Wang, Xiaozhi and Lv, Xin and Cao, Shulin and Xu, Jiazheng and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , year =. 2412.15204 , archivePrefix =
-
[46]
Frontiers of Computer Science , year =
A Survey on Large Language Model based Autonomous Agents , author =. Frontiers of Computer Science , year =. 2308.11432 , archivePrefix =
-
[47]
arXiv preprint arXiv:2602.02276 , year =
Kimi K2.5: Visual Agentic Intelligence , author =. arXiv preprint arXiv:2602.02276 , year =
-
[48]
2026 , month = apr, howpublished =
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author =. 2026 , month = apr, howpublished =
2026
-
[49]
arXiv preprint arXiv:2508.06471 , year =
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models , author =. arXiv preprint arXiv:2508.06471 , year =
-
[50]
Anthropic . 2026. https://anthropic.com/claude-sonnet-4-6-system-card Claude sonnet 4.6 system card . System card
2026
-
[51]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. https://doi.org/10.18653/v1/2024.acl-long.172 LongBench : A bilingual, multitask benchmark for long context understanding . In Proceedings of the 62nd Annual Meeting of the Association for Co...
-
[52]
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2025. https://doi.org/10.18653/v1/2025.acl-long.183 L ong B ench v2: Towards deeper understanding and reasoning on realistic long-context multitasks . In Proceedings of the 63rd Annual Meeting of the Association fo...
-
[53]
Guhong Chen, Liyang Fan, Zihan Gong, Nan Xie, Zixuan Li, Ziqiang Liu, Chengming Li, Qiang Qu, Hamid Alinejad-Rokny, Shiwen Ni, and Min Yang. 2025. https://doi.org/10.18653/v1/2025.findings-acl.304 AgentCourt : Simulating court with adversarial evolvable lawyer agents . In Findings of the Association for Computational Linguistics: ACL 2025, pages 5850--586...
-
[54]
Jiaxi Cui, Munan Ning, Zongjian Li, Bohua Chen, Yang Yan, Hao Li, Bin Ling, Yonghong Tian, and Li Yuan. 2024. https://arxiv.org/abs/2306.16092 Chatlaw: A multi-agent collaborative legal assistant with knowledge graph enhanced mixture-of-experts large language model . Preprint, arXiv:2306.16092
Pith/arXiv arXiv 2024
-
[55]
DeepSeek-AI . 2025. https://arxiv.org/abs/2512.02556 Deepseek-v3.2: Pushing the frontier of open large language models . arXiv preprint arXiv:2512.02556
Pith/arXiv arXiv 2025
-
[56]
Chenlong Deng, Kelong Mao, and Zhicheng Dou. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.73 Learning interpretable legal case retrieval via knowledge-guided case reformulation . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1253--1265, Miami, Florida, USA. Association for Computational Linguistics
-
[57]
Zhiwei Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, Zhuo Han, Alan Huang, Songyang Zhang, Kai Chen, Zhixin Yin, Zongwen Shen, Jidong Ge, and Vincent Ng. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.452 L aw B ench: Benchmarking legal knowledge of large language models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Proc...
-
[58]
Cheng Gao, Chaojun Xiao, Zhenghao Liu, Huimin Chen, Zhiyuan Liu, and Maosong Sun. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.402 Enhancing legal case retrieval via scaling high-quality synthetic query-candidate pairs . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7086--7100, Miami, Florida, USA. A...
-
[59]
Ho, Christopher R \'e , Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N
Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher R \'e , Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N. Rockmore, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory M. Dickinson, Haggai Porat, Jason Hegland, and 21 others. 2023. https://openreview.net/forum?id=WqSPQF...
2023
-
[60]
Zhitao He, Pengfei Cao, Chenhao Wang, Zhuoran Jin, Yubo Chen, Jiexin Xu, Huaijun Li, Kang Liu, and Jun Zhao. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.549 AgentsCourt : Building judicial decision-making agents with court debate simulation and legal knowledge augmentation . In Findings of the Association for Computational Linguistics: EMNLP 202...
-
[61]
Zheng Jia, Shengbin Yue, Wei Chen, Siyuan Wang, Yidong Liu, Zejun Li, Yun Song, and Zhongyu Wei. 2026. https://arxiv.org/abs/2507.04037 Ready jurist one: Benchmarking language agents for legal intelligence in dynamic environments . Preprint, arXiv:2507.04037
arXiv 2026
-
[62]
Sheng Jin, Haoming Wang, Zhiqi Gao, Yongbo Yang, Bao Chunjia, and Chengliang Wang. 2025. https://doi.org/10.48550/arXiv.2510.11290 Evolution in simulation: AI -agent school with dual memory for high-fidelity educational dynamics . Preprint, arxiv:2510.11290 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.11290 2025
-
[63]
Daeun Kyung, Hyunseung Chung, Seongsu Bae, Jiho Kim, Jae Ho Sohn, Taerim Kim, Soo Kyung Kim, and Edward Choi. 2025. https://openreview.net/forum?id=1THAjdP4QJ PatientSim : A persona-driven simulator for realistic doctor-patient interactions . In Advances in Neural Information Processing Systems 39 (NeurIPS 2025) Datasets and Benchmarks Track
2025
-
[64]
Chance Jiajie Li, Jiayi Wu, Zhenze Mo, Ao Qu, Yuhan Tang, Kaiya Ivy Zhao, Yulu Gan, Jie Fan, Jiangbo Yu, Jinhua Zhao, Paul Liang, Luis Alonso, and Kent Larson. 2025 a . https://doi.org/10.48550/arXiv.2506.06958 Simulating society requires simulating thought . Preprint, arxiv:2506.06958 [cs]
-
[65]
Haitao Li, You Chen, Qingyao Ai, Yueyue Wu, Ruizhe Zhang, and Yiqun Liu. 2024. https://doi.org/10.52202/079017-0790 LexEval : A comprehensive C hinese legal benchmark for evaluating large language models . In Advances in Neural Information Processing Systems 38 (NeurIPS 2024) Datasets and Benchmarks Track
-
[66]
Junkai Li, Yunghwei Lai, Weitao Li, Jingyi Ren, Meng Zhang, Xinhui Kang, Siyu Wang, Peng Li, Ya-Qin Zhang, Weizhi Ma, and Yang Liu. 2025 b . https://doi.org/10.48550/arXiv.2405.02957 Agent hospital: A simulacrum of hospital with evolvable medical agents . Preprint, arxiv:2405.02957 [cs]
-
[67]
Shuang Liu, Ruijia Zhang, Ruoyun Ma, Yujia Deng, Lanyi Zhu, Jiayu Li, Zelong Li, Zhibin Shen, and Mengnan Du. 2026. https://doi.org/10.48550/arXiv.2601.06216 LLM agents in law: Taxonomy, applications, and challenges . Preprint, arxiv:2601.06216 [cs]
-
[68]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. https://aclanthology.org/2024.acl-long.747/ Evaluating very long-term conversational memory of LLM agents . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851--13870. Associati...
2024
-
[69]
OpenAI . 2025. https://cdn.openai.com/pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf Update to gpt-5 system card: Gpt-5.2 . System card update
2025
-
[70]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2024. https://arxiv.org/abs/2310.08560 MemGPT : Towards LLMs as operating systems . Preprint, arXiv:2310.08560
Pith/arXiv arXiv 2024
-
[71]
Generative agents: Interactive simulacra of human behavior,
Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. https://doi.org/10.1145/3586183.3606763 Generative agents: Interactive simulacra of human behavior . In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST '23), New York, NY, USA. Association for ...
-
[72]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. https://openreview.net/forum?id=dHng2O0Jjr ToolLLM : Facilitating large language models to master 16000+ real-world APIs ....
2024
-
[73]
Riya Ranjan and Megan Ma. 2024. https://neurips.cc/virtual/2024/104203 Motivations for reframing large language model benchmarking for legal applications . In Proceedings of the NeurIPS 2024 Workshop on Evaluating Evaluations: Examining Best Practices for Measuring Broader Impacts of Generative AI
2024
-
[74]
Timo Schick, Janne Dwivedi-Yu, Roberto Dess \`i , Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. https://openreview.net/forum?id=Yacmpz84TH Toolformer: Language models can teach themselves to use tools . In Advances in Neural Information Processing Systems 36 (NeurIPS 2023)
2023
-
[75]
Yu-Min Tseng, Yu-Chao Huang, Teng-Yun Hsiao, Wei-Lin Chen, Chao-Wei Huang, Yu Meng, and Yun-Nung Chen. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.969 Two tales of persona in LLMs : A survey of role-playing and personalization . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 16612--16631, Miami, Florida, USA. Ass...
-
[76]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. 2024 a . https://doi.org/10.1007/s11704-024-40231-1 A survey on large language model based autonomous agents . Frontiers of Computer Science, arXiv:2308.11432
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s11704-024-40231-1 2024
-
[77]
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. 2024 b . https://proceedings.mlr.press/v235/wang24h.html Executable code actions elicit better LLM agents . In Proceedings of the 41st International Conference on Machine Learning (ICML), pages 50208--50232. PMLR
2024
-
[78]
Yiding Wang, Yuxuan Chen, Fanxu Meng, Xifan Chen, Xiaolei Yang, and Muhan Zhang. 2025. https://doi.org/10.48550/arXiv.2510.24442 Law in silico: Simulating legal society with LLM -based agents . Preprint, arxiv:2510.24442 [cs]
-
[79]
Chaojun Xiao, Haoxi Zhong, Zhipeng Guo, Cunchao Tu, Zhiyuan Liu, Maosong Sun, Yansong Feng, Xianpei Han, Zhen Hu, Heng Wang, and Jianfeng Xu. 2018. https://arxiv.org/abs/1807.02478 CAIL2018 : A large-scale legal dataset for judgment prediction . Preprint, arXiv:1807.02478
Pith/arXiv arXiv 2018
-
[80]
Shengbin Yue, Wei Chen, Siyuan Wang, Bingxuan Li, Chenchen Shen, Shujun Liu, Yuxuan Zhou, Yao Xiao, Song Yun, Xuanjing Huang, and Zhongyu Wei. 2023. https://arxiv.org/abs/2309.11325 DISC - LawLLM : Fine-tuning large language models for intelligent legal services . Preprint, arXiv:2309.11325
arXiv 2023
-
[81]
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. 2026. https://doi.org/10.48550/arXiv.2602.02474 MemSkill : Learning and evolving memory skills for self-evolving agents . Preprint, arxiv:2602.02474 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02474 2026
-
[82]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. https://openreview.net/forum?id=uccHPGDlao Judging LLM -as-a-judge with MT -bench and chatbot arena . In Advances in Neural Information Processing Systems 36 (NeurIPS 2023...
2023
-
[83]
Haoxi Zhong, Chaojun Xiao, Zhipeng Guo, Cunchao Tu, Zhiyuan Liu, Maosong Sun, Yansong Feng, Xianpei Han, Zhen Hu, Heng Wang, and Jianfeng Xu. 2018. https://arxiv.org/abs/1810.05851 Overview of CAIL2018 : Legal judgment prediction competition . Preprint, arXiv:1810.05851
Pith/arXiv arXiv 2018
-
[84]
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and Maarten Sap. 2024. https://openreview.net/forum?id=mM7VurbA4r SOTOPIA : Interactive evaluation for social intelligence in language agents . In The Twelfth International Conference on Learning Representations (ICLR)
2024
-
[85]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[86]
Publications Manual , year = "1983", publisher =
1983
-
[87]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[88]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[89]
Dan Gusfield , title =. 1997
1997
-
[90]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[91]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.