Maturing Markov Decision Processes: Decision Making under Increasing Information and Shrinking Action Sets
Pith reviewed 2026-06-26 21:45 UTC · model grok-4.3
The pith
Maturing Markov Decision Processes capture how information grows while action sets shrink to improve reinforcement learning efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
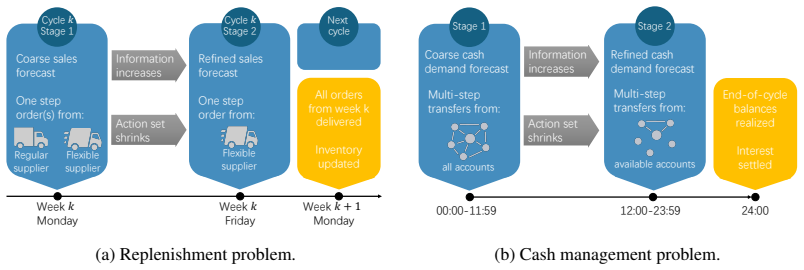
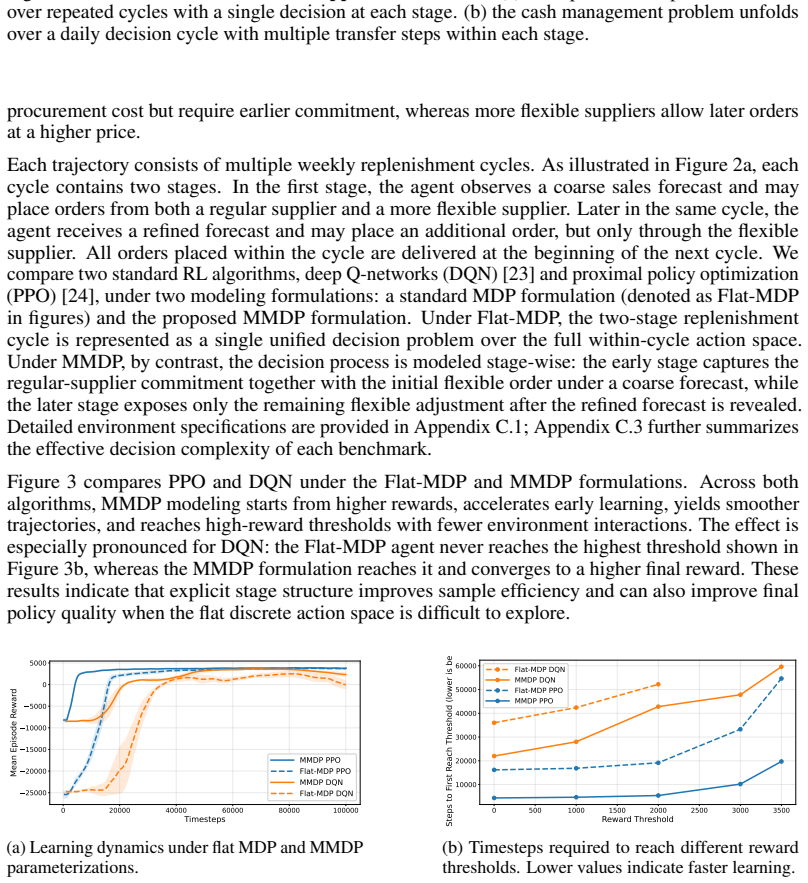
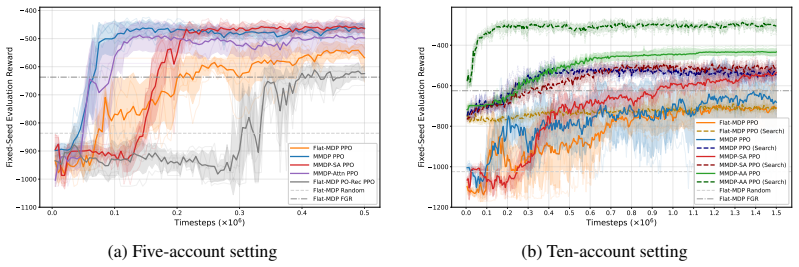
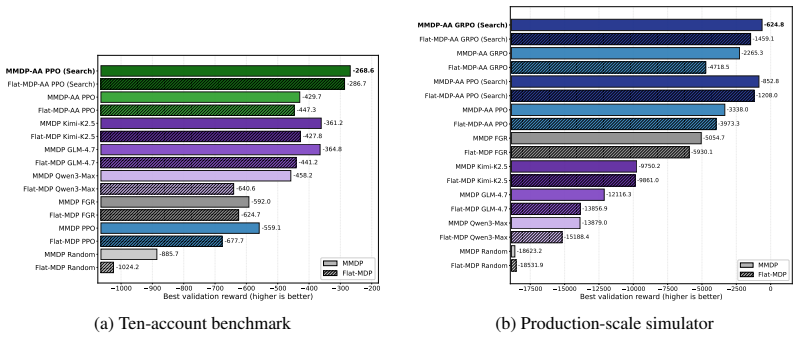
The paper establishes that sequential decision problems exhibit an asymmetric evolution in which richer information is received while feasible actions expire due to operational cutoffs and constraints, and that standard MDP formulations obscure this structure by flattening it into stage-dependent states and action masks. Maturing Markov Decision Processes are defined around the asymmetry and yield an expiring-action priority principle that identifies actions requiring immediate resolution. A corresponding reinforcement learning framework incorporates stage-aware policy design, expiring-action abstraction, and search-augmented learning with distillation; empirical results on multi-supplier re
What carries the argument
Maturing Markov Decision Process, which encodes the nested information-action asymmetry and distinguishes urgent expiring actions from those that can be deferred.
If this is right
- The expiring-action priority principle identifies which actions must be resolved before the next stage.
- Stage-aware policy design and expiring-action abstraction improve sample efficiency over standard reinforcement learning methods.
- Search-augmented learning with distillation further leverages the structure to produce better policies.
- The performance advantage of explicit asymmetry modeling increases with the size and complexity of the decision problem.
Where Pith is reading between the lines
- The same asymmetry may appear in other sequential settings such as real-time resource allocation or time-sensitive planning, suggesting the framework could be adapted beyond the tested inventory and cash domains.
- Theoretical analysis could derive regret bounds that explicitly account for action expiration rates rather than treating all actions as equally available across stages.
- The priority principle might combine with hierarchical reinforcement learning to defer low-urgency subproblems automatically.
Load-bearing premise
That flattening the information-action asymmetry into ordinary stage-dependent MDPs with action masks materially reduces performance compared with an explicit formulation of the asymmetry.
What would settle it
Run the same reinforcement learning algorithms on the production-scale simulator once with the explicit MMDP structure and once with an equivalent standard MDP that uses only stage-dependent action masks, then measure whether the sample-efficiency gap disappears when the asymmetry is artificially removed.
Figures
read the original abstract
Sequential decision problems often exhibit an asymmetric evolution of information and decision flexibility: as a decision cycle unfolds, the agent receives richer information while feasible actions expire due to operational cutoffs, commitments, or resource constraints. Standard MDP formulations typically flatten this structure into stage-dependent state descriptions and action masks, thereby obscuring the nested information--action asymmetry that determines which decisions are urgent and which can be deferred. We introduce Maturing Markov Decision Processes (MMDPs), a formulation built around this information--action asymmetry. We characterize one of its key consequences through an expiring-action priority principle, which identifies the actions that must be resolved before the next stage. Motivated by this structure, we develop a structure-aware reinforcement learning framework with stage-aware policy design, expiring-action abstraction, and search-augmented learning with distillation. Experiments on a controlled multi-supplier replenishment problem, simplified cash-management environments of increasing complexity, and a production-scale simulator show that explicitly modeling this asymmetry improves learning efficiency and becomes increasingly valuable as decision problems scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Maturing Markov Decision Processes (MMDPs) to model sequential decision problems with asymmetric growth in information and shrinkage in feasible actions. It derives an expiring-action priority principle from this structure and develops a structure-aware RL framework using stage-aware policy design, expiring-action abstraction, and search-augmented learning with distillation. Experiments on a controlled multi-supplier replenishment problem, simplified cash-management environments of increasing scale, and a production-scale simulator are reported to show improved learning efficiency that grows with problem size.
Significance. If the empirical results hold, the work supplies a structured formulation and algorithmic approach for a recurring pattern in applied decision problems that standard stage-dependent MDPs with masks tend to flatten. The scaling experiments across controlled to production domains provide a concrete test of whether the asymmetry-aware modeling yields measurable gains; this is a positive feature of the evaluation design.
minor comments (2)
- [Abstract] Abstract: the claim of improved efficiency would be easier to evaluate if the abstract named the baselines, the primary performance metric, and whether error bars or statistical tests accompany the reported gains.
- The priority principle is presented as a key consequence of the MMDP formulation; a short self-contained derivation or proof sketch in the main text (rather than only in an appendix) would strengthen accessibility.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of the scaling experiments, and recommendation of minor revision. The referee's description of the MMDP formulation, expiring-action priority principle, and structure-aware RL framework aligns closely with our contributions.
Circularity Check
No significant circularity
full rationale
The paper defines MMDPs as a new formulation centered on the information-action asymmetry, derives the expiring-action priority principle directly from that structure, and evaluates a structure-aware RL method on external controlled and production-scale domains. No step reduces a claimed prediction or principle to a fitted parameter, self-citation chain, or definitional renaming; the central empirical claim (efficiency gains that increase with scale) is tested against independent benchmarks rather than being forced by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dynamic pricing of inventory/capacity with infrequent price changes
Serguei Netessine. Dynamic pricing of inventory/capacity with infrequent price changes. European Journal of Operational Research, 174(1):553–580, 2006
2006
-
[2]
Dynamic pricing and demand learning with limited price experimentation.Operations Research, 65(6):1722–1731, 2017
Wang Chi Cheung, David Simchi-Levi, and He Wang. Dynamic pricing and demand learning with limited price experimentation.Operations Research, 65(6):1722–1731, 2017
2017
-
[3]
Inventory management with advance demand information and flexible delivery.Management Science, 54(4):716–732, 2008
Tong Wang and Beril L Toktay. Inventory management with advance demand information and flexible delivery.Management Science, 54(4):716–732, 2008
2008
-
[4]
Jiaxi Liu, Shuyi Lin, Linwei Xin, and Yidong Zhang. Ai vs. human buyers: A study of alibaba’s inventory replenishment system.INFORMS Journal on Applied Analytics, 53(5):372–387, 2023
2023
-
[5]
Yaqi Xie, Xinru Hao, Jiaxi Liu, Will Ma, Linwei Xin, Lei Cao, and Yidong Zhang. Deepstock: Reinforcement learning with policy regularizations for inventory management.arXiv preprint arXiv:2603.19621, 2026
arXiv 2026
-
[6]
Maximum weight online matching with deadlines.arXiv preprint arXiv:1808.03526, 2018
Itai Ashlagi, Maximilien Burq, Chinmoy Dutta, Patrick Jaillet, Amin Saberi, and Chris Sholley. Maximum weight online matching with deadlines.arXiv preprint arXiv:1808.03526, 2018
Pith/arXiv arXiv 2018
-
[7]
Alexandre Jacquillat and Michael Lingzhi Li. Learning to cover: online learning and optimiza- tion with irreversible decisions.arXiv preprint arXiv:2406.14777, 2024
arXiv 2024
-
[8]
Dynamic optimization of cash flow management decisions: a stochastic model.IEEE Transactions on Engineering Management, 37(3):203–212, 1990
M Elisabeth Pate-Cornell, George Tagaras, and Kathleen M Eisenhardt. Dynamic optimization of cash flow management decisions: a stochastic model.IEEE Transactions on Engineering Management, 37(3):203–212, 1990
1990
-
[9]
Estimating policy functions in payment systems using reinforcement learning.ACM Transactions on Economics and Computation, 13(1):1–31, 2025
Pablo Castro, Ajit Desai, Han Du, Rodney Garratt, and Francisco Rivadeneyra. Estimating policy functions in payment systems using reinforcement learning.ACM Transactions on Economics and Computation, 13(1):1–31, 2025. 10
2025
-
[10]
John Wiley & Sons, 2014
Martin L Puterman.Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 2014
2014
-
[11]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction. MIT press Cambridge, 1998
1998
-
[12]
Routledge, 2021
Eitan Altman.Constrained Markov decision processes. Routledge, 2021
2021
-
[13]
Non-stationary markov decision processes, a worst-case approach using model-based reinforcement learning.Advances in neural information processing systems, 32, 2019
Erwan Lecarpentier and Emmanuel Rachelson. Non-stationary markov decision processes, a worst-case approach using model-based reinforcement learning.Advances in neural information processing systems, 32, 2019
2019
-
[14]
Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
1998
-
[15]
A tutorial on partially observable markov decision processes.Journal of Mathematical Psychology, 53(3):119–125, 2009
Michael L Littman. A tutorial on partially observable markov decision processes.Journal of Mathematical Psychology, 53(3):119–125, 2009
2009
-
[16]
Deep reinforcement learning in parameterized action space.arXiv preprint arXiv:1511.04143, 2015
Matthew Hausknecht and Peter Stone. Deep reinforcement learning in parameterized action space.arXiv preprint arXiv:1511.04143, 2015
arXiv 2015
-
[17]
Reinforcement learning with pa- rameterized actions
Warwick Masson, Pravesh Ranchod, and George Konidaris. Reinforcement learning with pa- rameterized actions. InProceedings of the AAAI conference on artificial intelligence, volume 30, 2016
2016
-
[18]
Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
2017
-
[19]
Thinking fast and slow with deep learning and tree search.Advances in neural information processing systems, 30, 2017
Thomas Anthony, Zheng Tian, and David Barber. Thinking fast and slow with deep learning and tree search.Advances in neural information processing systems, 30, 2017
2017
-
[20]
McGraw-hill New York, 1999
David Simchi-Levi, Philip Kaminsky, and Edith Simchi-Levi.Designing and managing the supply chain: Concepts, strategies, and cases. McGraw-hill New York, 1999
1999
-
[21]
Zipkin.Foundations of Inventory Management
Paul H. Zipkin.Foundations of Inventory Management. McGraw-Hill, New York, 2000
2000
-
[22]
Now or later: A simple policy for effective dual sourcing in capacitated systems.Operations Research, 56(4):850–864, 2008
Senthil Veeraraghavan and Alan Scheller-Wolf. Now or later: A simple policy for effective dual sourcing in capacitated systems.Operations Research, 56(4):850–864, 2008
2008
-
[23]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
2015
-
[24]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[25]
The transactions demand for cash: An inventory theoretic approach.The Quarterly journal of economics, 66(4):545–556, 1952
William J Baumol. The transactions demand for cash: An inventory theoretic approach.The Quarterly journal of economics, 66(4):545–556, 1952
1952
-
[26]
A model of the demand for money by firms.The Quarterly journal of economics, 80(3):413–435, 1966
Merton H Miller and Daniel Orr. A model of the demand for money by firms.The Quarterly journal of economics, 80(3):413–435, 1966
1966
-
[27]
The utility of cash flow forecasts in the management of corporate cash balances.European journal of operational research, 182(2):923–935, 2007
Fionnuala M Gormley and Nigel Meade. The utility of cash flow forecasts in the management of corporate cash balances.European journal of operational research, 182(2):923–935, 2007
2007
-
[28]
Cash management using multi-stage stochastic program- ming.Quantitative Finance, 10(2):209–219, 2010
Robert Ferstl and Alex Weissensteiner. Cash management using multi-stage stochastic program- ming.Quantitative Finance, 10(2):209–219, 2010
2010
-
[29]
Learning combinatorial optimization algorithms over graphs.Advances in neural information processing systems, 30, 2017
Elias Khalil, Hanjun Dai, Yuyu Zhang, Bistra Dilkina, and Le Song. Learning combinatorial optimization algorithms over graphs.Advances in neural information processing systems, 30, 2017
2017
-
[30]
Reinforcement learning for solving the vehicle routing problem.Advances in neural information processing systems, 31, 2018
Mohammadreza Nazari, Afshin Oroojlooy, Lawrence Snyder, and Martin Takác. Reinforcement learning for solving the vehicle routing problem.Advances in neural information processing systems, 31, 2018. 11
2018
-
[31]
Reinforcement learning with combinatorial actions: An application to vehicle routing.Advances in Neural Information Processing Systems, 33:609–620, 2020
Arthur Delarue, Ross Anderson, and Christian Tjandraatmadja. Reinforcement learning with combinatorial actions: An application to vehicle routing.Advances in Neural Information Processing Systems, 33:609–620, 2020
2020
-
[32]
Tianwei Ni, Benjamin Eysenbach, and Ruslan Salakhutdinov. Recurrent model-free rl can be a strong baseline for many pomdps.arXiv preprint arXiv:2110.05038, 2021
arXiv 2021
-
[33]
Empowering cash managers to achieve cost savings by improving predictive accuracy
Francisco Salas-Molina, Francisco J Martin, Juan A Rodriguez-Aguilar, Joan Serrá, and Josep Ll Arcos. Empowering cash managers to achieve cost savings by improving predictive accuracy. International Journal of Forecasting, 33(2):403–415, 2017
2017
-
[34]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[35]
Richard D. Smallwood and Edward J. Sondik. The optimal control of partially observable markov processes over a finite horizon.Operations Research, 21(5):1071–1088, 1973. doi: 10.1287/opre.21.5.1071
-
[36]
Partially observable markov decision processes
Matthijs TJ Spaan. Partially observable markov decision processes. InReinforcement learning: State-of-the-art, pages 387–414. Springer, 2012. doi: 10.1007/978-3-642-27645-3_12
-
[37]
Near-optimal regret bounds for reinforcement learning.Advances in neural information processing systems, 21, 2008
Peter Auer, Thomas Jaksch, and Ronald Ortner. Near-optimal regret bounds for reinforcement learning.Advances in neural information processing systems, 21, 2008
2008
-
[38]
Stochastic multi-armed-bandit problem with non-stationary rewards.Advances in neural information processing systems, 27, 2014
Omar Besbes, Yonatan Gur, and Assaf Zeevi. Stochastic multi-armed-bandit problem with non-stationary rewards.Advances in neural information processing systems, 27, 2014
2014
-
[39]
Reinforcement learning for non- stationary markov decision processes: The blessing of (more) optimism
Wang Chi Cheung, David Simchi-Levi, and Ruihao Zhu. Reinforcement learning for non- stationary markov decision processes: The blessing of (more) optimism. InInternational conference on machine learning, pages 1843–1854. PMLR, 2020
2020
-
[40]
A survey of reinforcement learning algorithms for dynamically varying environments.ACM Computing Surveys (CSUR), 54(6):1–25, 2021
Sindhu Padakandla. A survey of reinforcement learning algorithms for dynamically varying environments.ACM Computing Surveys (CSUR), 54(6):1–25, 2021
2021
-
[41]
Parisi, Ronald Kemker, Jose L
German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71, 2019
2019
-
[42]
Towards continual rein- forcement learning: A review and perspectives.Journal of Artificial Intelligence Research, 75: 1401–1476, 2022
Khimya Khetarpal, Matthew Riemer, Irina Rish, and Doina Precup. Towards continual rein- forcement learning: A review and perspectives.Journal of Artificial Intelligence Research, 75: 1401–1476, 2022
2022
-
[43]
Parseval regularization for continual reinforcement learning
Wesley Chung, Lynn Cherif, David Meger, and Doina Precup. Parseval regularization for continual reinforcement learning. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[44]
Arthur Juliani and Jordan T. Ash. A study of plasticity loss in on-policy deep reinforcement learning. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[45]
Is q-learning provably efficient?Advances in neural information processing systems, 31, 2018
Chi Jin, Zeyuan Allen-Zhu, Sebastien Bubeck, and Michael I Jordan. Is q-learning provably efficient?Advances in neural information processing systems, 31, 2018. 12 A Additional Details on MMDP Structure A.1 Interpretation of non-degenerate stages. Remark 3.1 should be read as a statement about the information–action asymmetry isolated by the MMDP abstract...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.